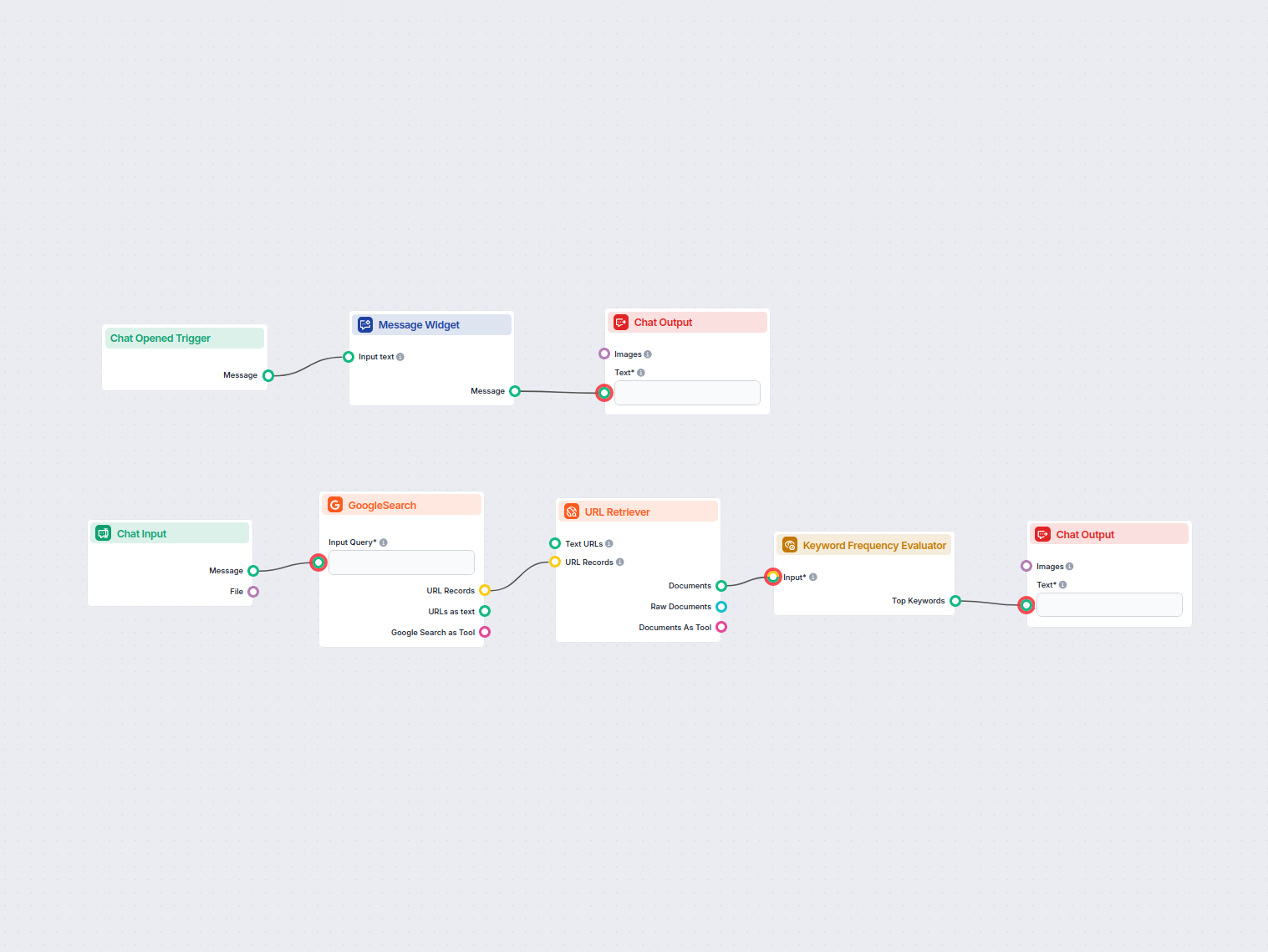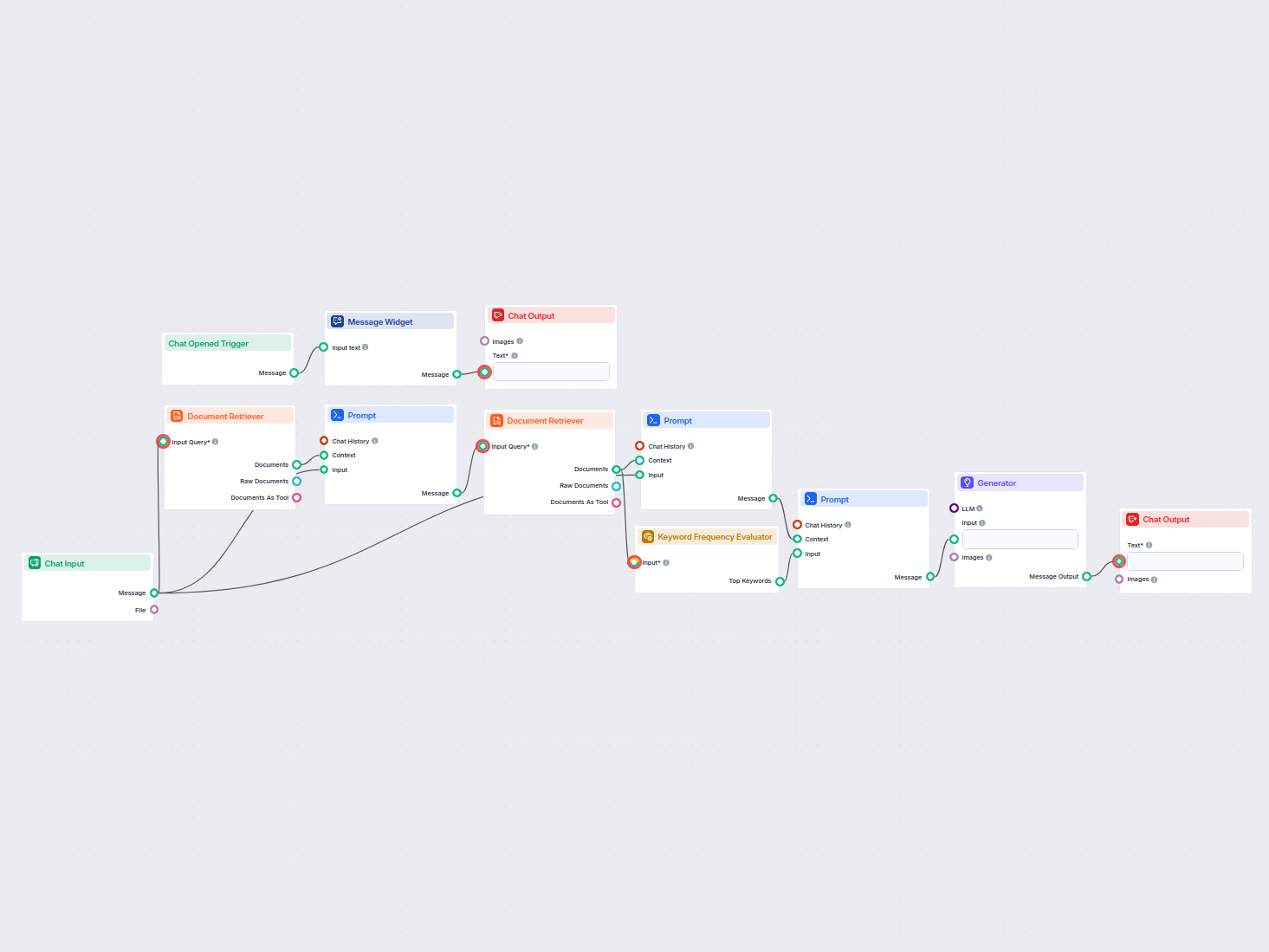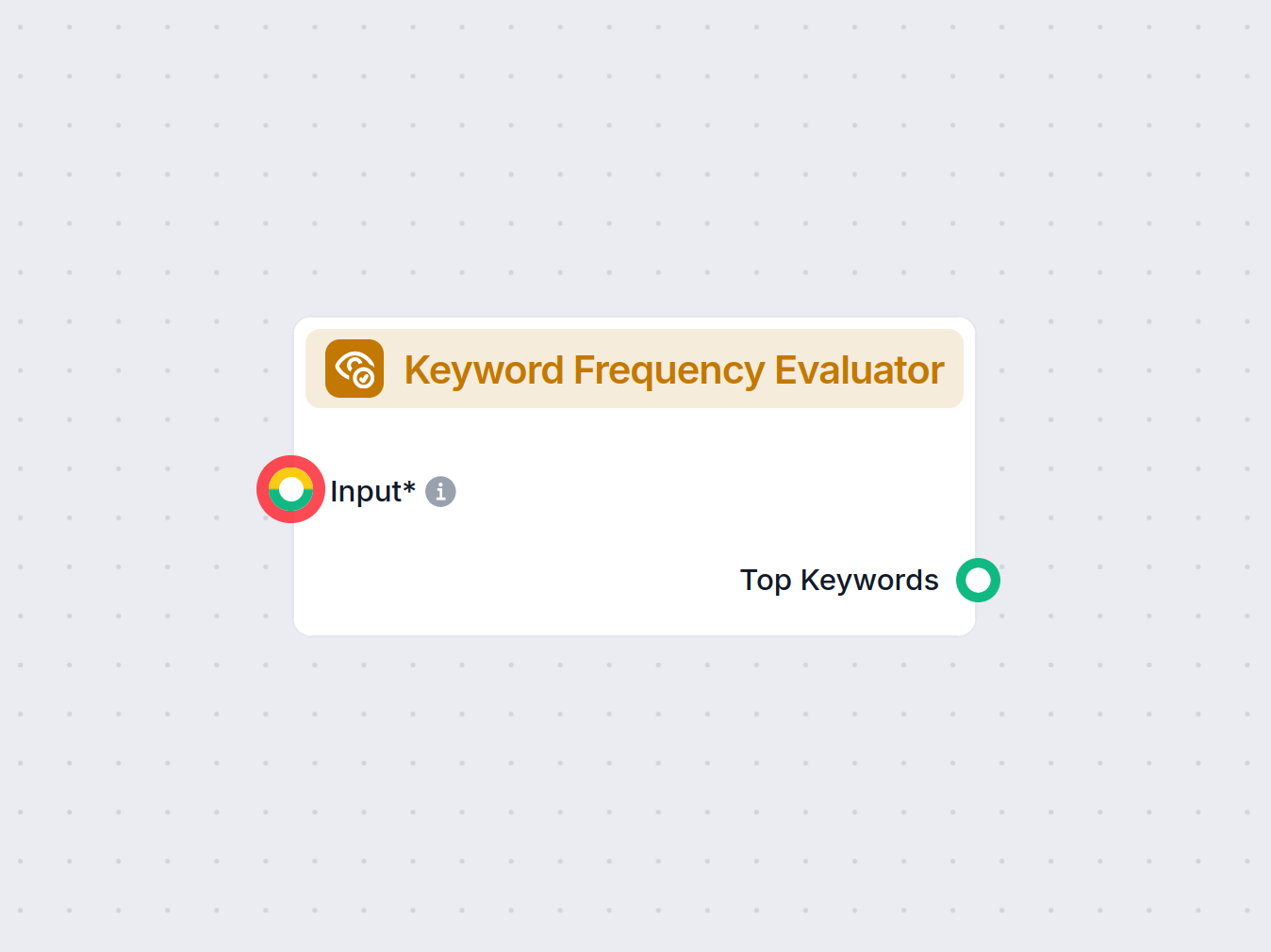
키워드 빈도 평가기는 하나 이상의 텍스트를 분석하여 빈도 및 다양한 설정 기준에 따라 가장 중요한 키워드를 식별하는 컴포넌트입니다. 이를 통해 핵심 주제 추출, 콘텐츠 분석, 요약, 클러스터링, 검색 등 AI 후처리 작업을 위한 데이터 준비에 특히 유용하게 활용할 수 있습니다.
이 컴포넌트는 무엇을 하나요?
이 컴포넌트는 문서, 메시지, URL 레코드 등 텍스트 입력 리스트를 받아 처리한 뒤, 입력 데이터 전반에서 가장 빈번하고 관련성 높은 키워드를 순위별로 제공합니다. 불용어 제외, 여러 텍스트에 중복 등장하는 키워드 집중, 추출할 키워드의 크기와 길이 조정 등 다양한 설정이 가능합니다.
입력값
이 컴포넌트는 다음과 같은 설정 가능한 입력값을 제공합니다:
| 입력명 | 타입 | 기본값 | 설명 |
|---|---|---|---|
| Input | 텍스트 리스트 | - | 분석할 주요 텍스트입니다. UrlRecord, Message, Document 타입을 지원합니다. |
| Exclude Stopwords | 불리언 | true | 활성화 시 “the”, “and” 등 일반 불용어를 결과에서 제외합니다. |
| Just Intersecting | 불리언 | true | 활성화 시 여러 입력 텍스트에 모두 등장하는 키워드만 반환합니다. |
| Max Keywords | 정수 | 50 | 최종 결과로 반환할 최대 키워드 개수입니다. |
| Min Frequency | 정수 | 3 | 키워드로 간주되기 위한 최소 등장 횟수입니다. |
| Min Word Length | 정수 | 3 | 키워드로 인정받기 위한 최소 문자 길이입니다. |
| Qgrams | 멀티셀렉트 (1-6) | 2, 3, 4 | 키워드 추출 시 고려할 단어 시퀀스(엔그램)의 크기입니다. |
주요 특징
- 유연한 입력: 다양한 텍스트 레코드 타입과 배치 처리를 지원합니다.
- 고급 필터링: 불용어 제외, 최소 단어 길이 및 빈도 기준 등으로 결과를 세밀하게 조정할 수 있습니다.
- 출력 크기 제어: 상위 키워드 수를 제한해 주요 용어에 집중할 수 있습니다.
- N-그램 지원: 단일 키워드뿐 아니라 복합어(Q-그램) 추출로 더 풍부한 의미 파악이 가능합니다.
- 교집합 키워드: 여러 문서에 공통적으로 등장하는 키워드에 집중해 비교 분석이 가능합니다.
출력값
이 컴포넌트의 출력값은 다음과 같습니다:
- 상위 키워드:
추출 논리와 설정값에 따라 선정된 가장 중요한 키워드 리스트(Message타입)입니다. 이 결과는 AI 워크플로우 내 추가 처리나 시각화에 활용할 수 있습니다.
활용 예시
- 문서 요약: 여러 문서에서 주요 주제를 빠르게 파악
- 콘텐츠 클러스터링: 추출된 키워드로 유사 문서나 메시지 그룹화
- 검색 및 인덱싱: 정보 시스템에서 효율적인 검색을 위한 색인어 생성
- 트렌드 분석: 커뮤니케이션 로그나 데이터셋에서 반복되는 주제 추적
왜 유용한가요?
키워드 빈도 평가기는 대량 또는 여러 텍스트에서 의미 있는 용어를 효율적으로 추출할 수 있도록 도와줍니다. 세밀한 설정으로 단순 키워드 추출부터 고급 비교 분석까지 다양한 니즈에 맞게 적용할 수 있습니다. AI 워크플로우에서 요약된 정보 중심의 텍스트 데이터로 후처리 컴포넌트의 효율성과 해석력을 높여줍니다.