Overzicht
De RIG (Retrieval Interleaved Generator) Wikipedia Assistent is een geautomatiseerde workflow die is ontworpen om gebruikersvragen te beantwoorden door initiële antwoorden te genereren, benodigde feitelijke data te identificeren, informatie van Wikipedia op te halen en de antwoorden te verfijnen met nauwkeurige bronvermeldingen per sectie. Het belangrijkste doel is om antwoorden te geven die zijn onderbouwd met verifieerbare bronnen en exact te specificeren welke secties en bronnen zijn gebruikt. Dit maakt het systeem bijzonder nuttig voor onderzoek, factchecking en educatieve doeleinden.
Hoe de workflow werkt
Chatinitiatie & Welkomstbericht
- Wanneer een chatsessie wordt geopend, wordt de gebruiker begroet met een welkomstbericht dat het doel van de flow uitlegt: het geven van betrouwbare, onderbouwde antwoorden. Dit helpt om de verwachtingen te scheppen met betrekking tot de kwaliteit en transparantie van de antwoorden.
Gebruikersvraag ontvangen
- De gebruiker dient een vraag in via de chatinput. Deze input wordt vastgelegd en doorgegeven voor verdere verwerking.
Promptgeneratie
- De workflow bevat een Prompt Template die de gebruikersvraag omzet in een gedetailleerde prompt. Deze prompt instrueert het systeem om:
- Een conceptantwoord te genereren, zelfs als hiervoor tijdelijke data wordt gebruikt.
- Voor elke sectie in het antwoord aan te geven welke externe bron (zoals Wikipedia) of interne kennisbank gebruikt moet worden om die sectie te controleren en te verfijnen.
- Zoekopdrachten voor Wikipedia op te nemen om de juiste informatie voor elke sectie op te halen.
Voorbeeld:
Gebruikersinput: Welke landen behoren tot de top qua hernieuwbare energie?
Conceptuitvoer: De toplanden zijn Noorwegen, Zweden, Portugal [Zoek in Wikipedia: "Top Countries in renewable Energy"]...
Initiële antwoordgeneratie
- Met behulp van een language model generator maakt het systeem een conceptantwoord op basis van de prompt, waarin wordt aangegeven waar feitelijke data moet worden ingevoegd en welke bronnen gebruikt moeten worden ter verificatie.
Data ophalen & antwoord verfijnen
- Een AI Agent ontvangt het conceptantwoord en gebruikt de Wikipedia Tool om Wikipedia te doorzoeken met de gespecificeerde zoekopdrachten.
- Voor elke sectie van het antwoord haalt de agent de relevante feitelijke data van Wikipedia op en vervangt deze de concept- of tijdelijke inhoud.
- Elke sectie wordt verfijnd met een directe link naar het exacte Wikipedia-artikel of de gebruikte sectie, zodat transparantie en eenvoudige verificatie gewaarborgd zijn.
De agent wordt geïnstrueerd om generieke of opvulzinnen te vermijden en zich uitsluitend te richten op beknopte, feitelijke informatie.
Definitieve output
- Het volledig verfijnde antwoord, waarbij elke sectie is onderbouwd met een specifieke Wikipedia-bron (en links worden direct in de tekst weergegeven), wordt aan de gebruiker getoond in de chatinterface.
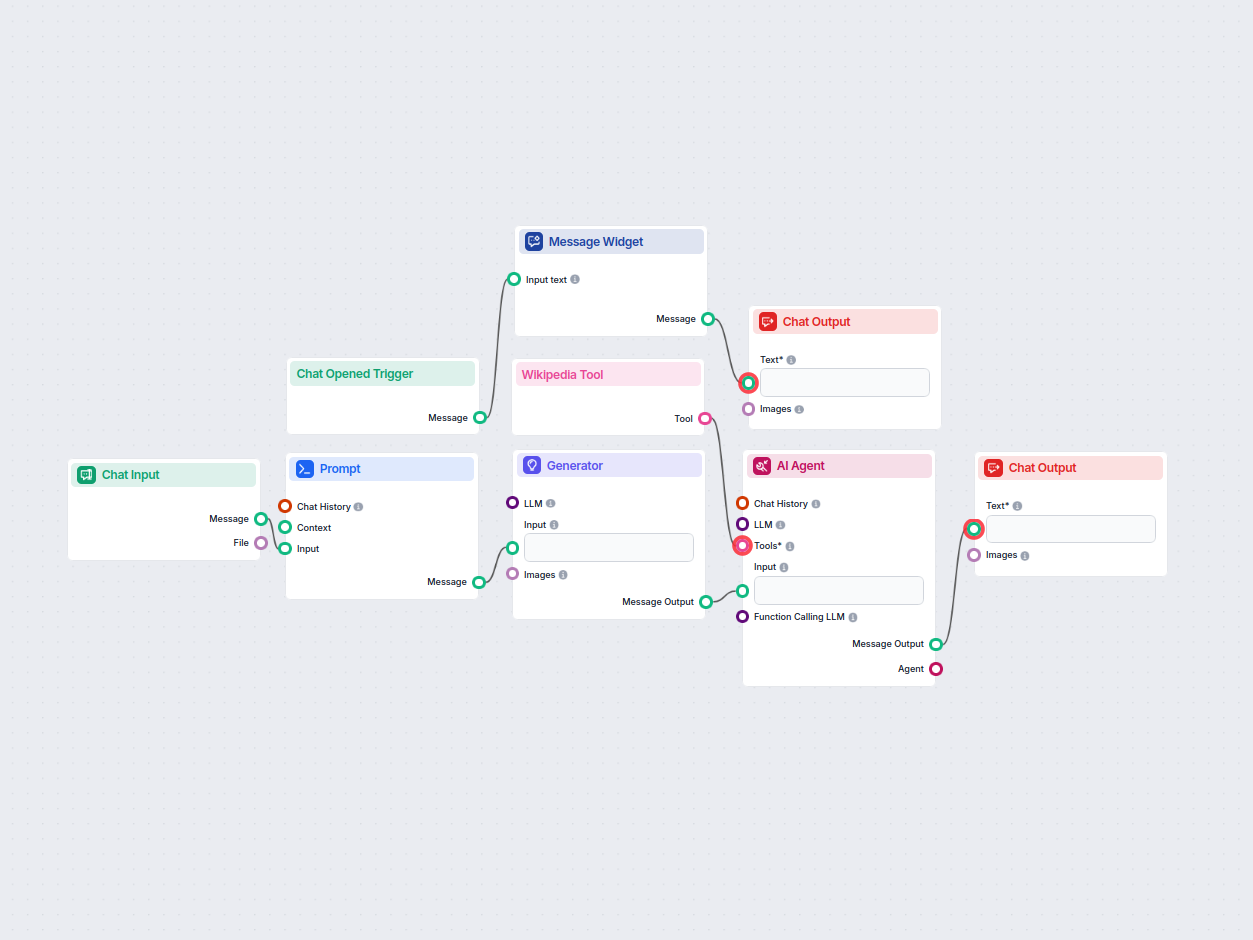
Workflowstructuur
| Stap | Component | Doel |
|---|
| 1 | Chat Opened Trigger | Detecteert nieuwe chatsessie en triggert het welkomstbericht |
| 2 | Message Widget | Toont de eerste begroeting en instructies |
| 3 | Chat Input | Ontvangt de vraag van de gebruiker |
| 4 | Prompt Template | Format de prompt met instructies voor conceptantwoord + bronverwijzingen |
| 5 | Generator | Produceert het initiële conceptantwoord (met tijdelijke aanduidingen) |
| 6 | Wikipedia Tool | Maakt het mogelijk om data op te halen uit Wikipedia |
| 7 | AI Agent | Verfijnt het concept, haalt feiten op, voegt bronvermeldingen/links toe |
| 8 | Chat Output | Presenteert het definitieve, onderbouwde antwoord aan de gebruiker |
Belangrijkste kenmerken en voordelen
- Brontransparantie: Elke sectie van het antwoord specificeert duidelijk welke Wikipedia-pagina of -sectie is gebruikt, met directe links voor gebruikersverificatie.
- Automatisering & schaalbaarheid: De workflow automatiseert het proces van opstellen, factchecken en verfijnen van antwoorden, waardoor veel vragen efficiënt kunnen worden verwerkt.
- Onderzoekswaardige output: Door elke bewering te onderbouwen met een verifieerbare externe bron, levert het systeem antwoorden die geschikt zijn voor academische, zakelijke en professionele toepassingen.
- Aanpasbaarheid: Indien gewenst kunnen interne kennisbronnen naast Wikipedia worden gebruikt, waardoor het systeem aanpasbaar is voor bedrijfsspecifieke data-opvraging.
Toepassingen
- Educatieve assistenten: Bied studenten altijd antwoorden met bronvermelding.
- Factchecking-bots: Verifieer informatie direct en presenteer bronnen zonder handmatig onderzoek.
- Klantenservice: Lever bedrijfs- of productinformatie met duidelijke herkomst van data.
- Contentcreatie: Schrijvers en journalisten ontvangen conceptinhoud met ingesloten referenties voor verdere uitwerking.
Samenvatting
Deze workflow stelt gebruikers in staat om betrouwbare, goed onderbouwde antwoorden te krijgen door generatie- en opvraagstappen te combineren. Het is vooral nuttig waar feitelijke juistheid, transparantie en bronvermelding van cruciaal belang zijn. Dankzij het modulaire, geautomatiseerde ontwerp is de workflow uitstekend schaalbaar voor organisaties die onderzoek en Q&A-taken op grote schaal willen automatiseren.