Context Engineering: De Definitieve Gids 2025 voor het Meesteren van AI Systeemontwerp
Duik diep in context engineering voor AI. Deze gids behandelt kernprincipes, van prompt vs. context tot geavanceerde strategieën zoals geheugensystemen, context rot en multi-agent ontwerp.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Het landschap van AI-ontwikkeling heeft een diepgaande transformatie ondergaan. Waar we ons vroeger focusten op het schrijven van de perfecte prompt, staan we nu voor een veel complexere uitdaging: het bouwen van volledige informatie-architecturen rondom en ter ondersteuning van onze taalmodellen.
Deze verschuiving markeert de evolutie van prompt engineering naar context engineering—en vertegenwoordigt niets minder dan de toekomst van praktische AI-ontwikkeling. De systemen die vandaag de dag echte waarde leveren, hangen niet af van magische prompts. Ze slagen omdat hun architecten geleerd hebben om uitgebreide informatie-ecosystemen te orkestreren.
Andrej Karpathy vatte deze evolutie perfect samen toen hij context engineering omschreef als de zorgvuldige praktijk van het vullen van het contextvenster met precies de juiste informatie op exact het juiste moment. Deze schijnbaar eenvoudige uitspraak onthult een fundamentele waarheid: de LLM is niet langer de ster van de show. Het is een cruciaal onderdeel binnen een zorgvuldig ontworpen systeem waarin elk stukje informatie—elk fragment van geheugen, elke toolbeschrijving, elk opgehaald document—bewust is gepositioneerd om de resultaten te maximaliseren.
Wat is Context Engineering?
Een Historisch Perspectief
De wortels van context engineering reiken dieper dan menigeen beseft. Terwijl discussies over prompt engineering rond 2022-2023 een vlucht namen, ontstonden de fundamentele concepten van context engineering al meer dan twintig jaar geleden vanuit onderzoek naar ubiquitous computing en mens-computer interactie.
In 2001 formuleerde Anind K. Dey een definitie die opmerkelijk voorspellend zou blijken: context omvat alle informatie die helpt om de situatie van een entiteit te karakteriseren. Dit vroege kader legde de basis voor hoe we denken over machinebegrip van omgevingen.
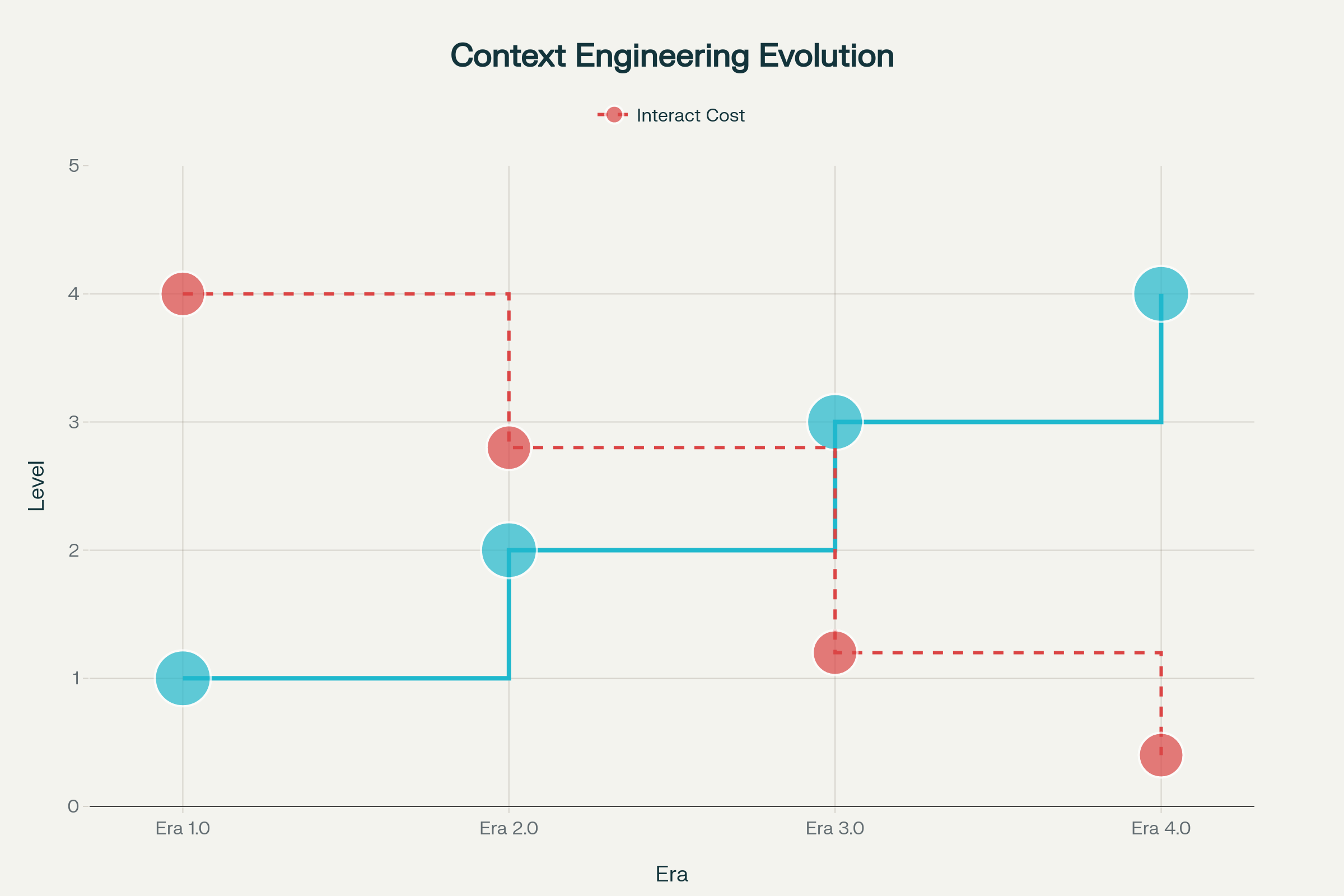
De evolutie van context engineering voltrok zich in verschillende fasen, elk gevormd door vooruitgang in machine-intelligentie:
Era 1.0: Primitieve Computatie (jaren 90–2020) — Gedurende deze lange periode konden machines alleen gestructureerde input en basisomgevingssignalen verwerken. Mensen droegen de volledige last om context om te zetten naar door machines verwerkbare formaten. Denk aan desktopapplicaties, mobiele apps met sensorinput en vroege chatbots met rigide responstrees.
Era 2.0: Agentgerichte Intelligentie (2020–heden) — De release van GPT-3 in 2020 zorgde voor een paradigmaverschuiving. Grote taalmodellen brachten echte natuurlijke taalbegrip en het vermogen om met impliciete intenties te werken. Dit tijdperk maakte authentieke samenwerking tussen mens en agent mogelijk, waarbij ambiguïteit en onvolledige informatie beheersbaar werden dankzij geavanceerd taalbegrip en in-context leren.
Era 3.0 & 4.0: Menselijke en Supermenselijke Intelligentie (toekomst) — De volgende golven beloven systemen die informatie met hoge entropie kunnen waarnemen en verwerken met een mensachtige soepelheid, om uiteindelijk verder te gaan dan reactieve responsen en proactief context te construeren en behoeften te signaleren die gebruikers nog niet eens hebben uitgesproken.
Evolutie van Context Engineering over Vier Era’s: Van Primitieve Computatie tot Supermenselijke Intelligentie
Een Formele Definitie
In de kern vertegenwoordigt context engineering de systematische discipline van het ontwerpen en optimaliseren van hoe contextuele informatie door AI-systemen stroomt—van de initiële verzameling tot opslag, beheer en uiteindelijk gebruik om machinebegrip en taakuitvoering te verbeteren.
We kunnen dit wiskundig uitdrukken als een transformatiefunctie:
$CE: (C, T) \rightarrow f_{context}$
Waarbij:
C ruwe contextuele informatie voorstelt (entiteiten en hun kenmerken)
T het doeltakenveld of toepassingsdomein aanduidt
f_{context} de resulterende contextverwerkingsfunctie oplevert
In praktische termen zijn er vier fundamentele operaties:
Verzamelen van relevante contextsignalen via diverse sensoren en informatiekanalen
Opslaan van deze informatie efficiënt over lokale systemen, netwerkinfrastructuur en cloudplatforms
Beheren van complexiteit door intelligente verwerking van tekst, multimodale input en complexe relaties
Gebruik van context door filtering op relevantie, cross-systeem sharing en aanpassing aan gebruikersbehoefte
Waarom Context Engineering Belangrijk Is: Het Entropie-reductie Kader
Context engineering adresseert een fundamentele asymmetrie in mens-machine communicatie. Wanneer mensen communiceren, vullen we moeiteloos gaten op dankzij gedeelde kennis, emotionele intelligentie en situationeel bewustzijn. Machines ontberen al deze capaciteiten.
Deze kloof manifesteert zich als informatie-entropie. Menselijke communicatie is efficiënt omdat we veel gedeelde context kunnen aannemen. Machines vereisen dat alles expliciet wordt weergegeven. Context engineering draait fundamenteel om het voorbewerken van contexten voor machines—het comprimeren van de hoge entropie van menselijke intenties en situaties tot laag-entropie representaties die machines kunnen verwerken.
Naarmate machine-intelligentie vordert, wordt deze entropiereductie steeds meer geautomatiseerd. Vandaag, in Era 2.0, moeten engineers veel van deze reductie nog handmatig orkestreren. In Era 3.0 en verder zullen machines steeds meer van deze last zelfstandig dragen. Maar de kernuitdaging blijft: de kloof tussen menselijke complexiteit en machinebegrip overbruggen.
Prompt Engineering vs. Context Engineering: Essentiële Verschillen
Een veelgemaakte fout is deze twee disciplines gelijkstellen. In werkelijkheid vertegenwoordigen ze fundamenteel verschillende benaderingen van AI-systeemarchitectuur.
Prompt engineering draait om het formuleren van individuele instructies of queries om modelgedrag te sturen. Het gaat om het optimaliseren van de taalkundige structuur van wat je communiceert met het model—de formulering, voorbeelden en redeneerlijnen binnen één interactie.
Context engineering is een uitgebreide systeemdiscipline die alles beheert wat het model tijdens inferentie tegenkomt—inclusief prompts, maar ook opgehaalde documenten, geheugensystemen, toolbeschrijvingen, statusinformatie, en meer.
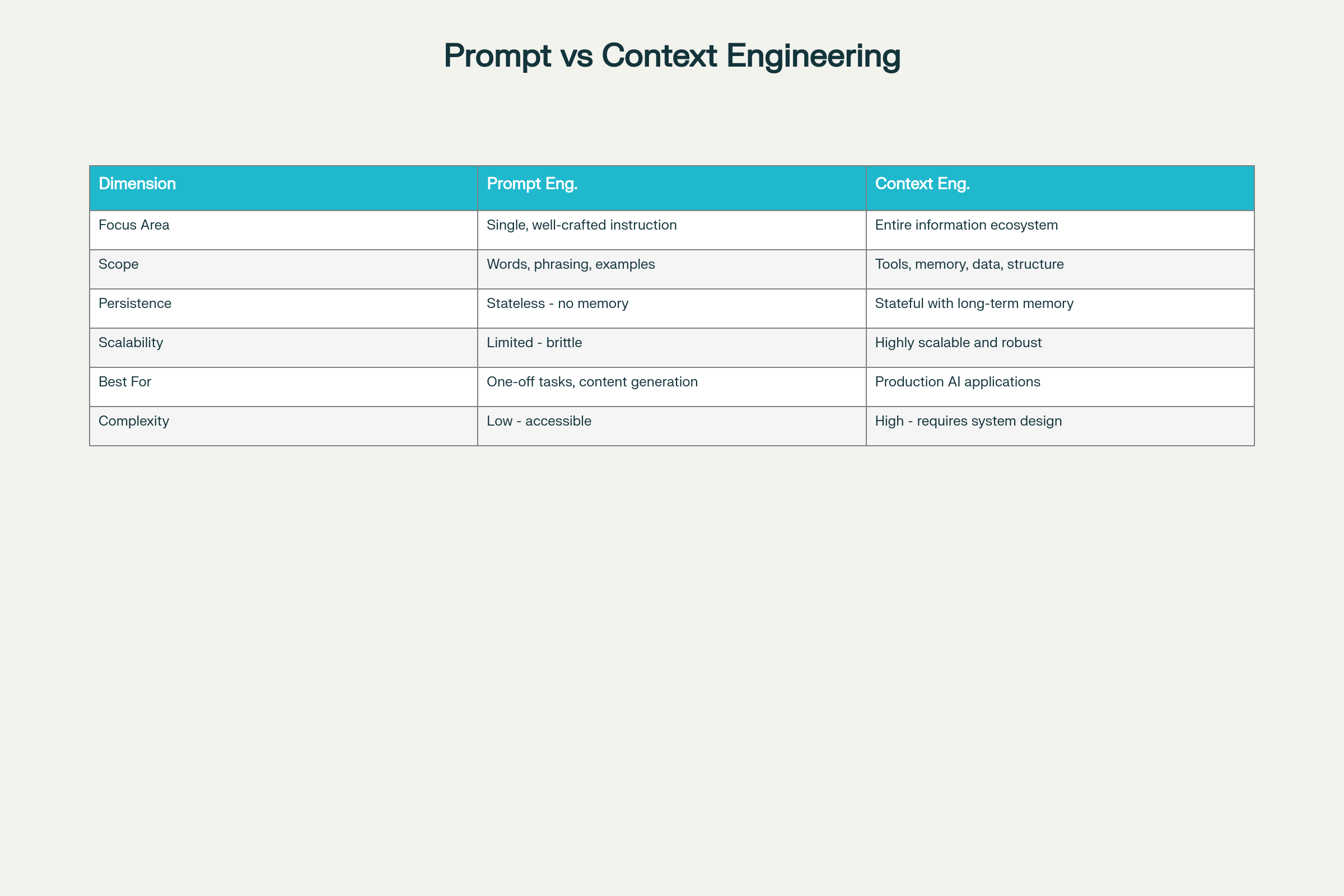
Prompt Engineering vs Context Engineering: Belangrijkste Verschillen en Afwegingen
Beschouw dit onderscheid: ChatGPT vragen een professioneel e-mail te schrijven is prompt engineering. Een klantenserviceplatform bouwen dat gespreksgeschiedenis over meerdere sessies bewaart, gebruikersgegevens ophaalt en eerdere supporttickets onthoudt—dat is context engineering.
Belangrijkste Verschillen over Acht Dimensies:
Dimensie
Prompt Engineering
Context Engineering
Focusgebied
Individuele instructie-optimalisatie
Uitgebreid informatie-ecosysteem
Scope
Woorden, formulering, voorbeelden
Tools, geheugen, data-architectuur, structuur
Persistentie
Stateless—geen geheugenbehoud
Stateful met langetermijngeheugen
Schaalbaarheid
Beperkt en kwetsbaar op schaal
Zeer schaalbaar en robuust
Beste Voor
Eenmalige taken, contentgeneratie
Productieklare AI-applicaties
Complexiteit
Lage instapdrempel
Hoog—vereist systeemontwerp-kennis
Betrouwbaarheid
Onvoorspelbaar op schaal
Consistent en betrouwbaar
Onderhoud
Kwetsbaar voor wijzigende eisen
Modulair en onderhoudbaar
Het cruciale inzicht: Productieklare LLM-applicaties vereisen vrijwel altijd context engineering in plaats van enkel slimme prompts. Zoals Cognition AI opmerkte, is context engineering feitelijk de kerntaak geworden van engineers die AI-agenten bouwen.
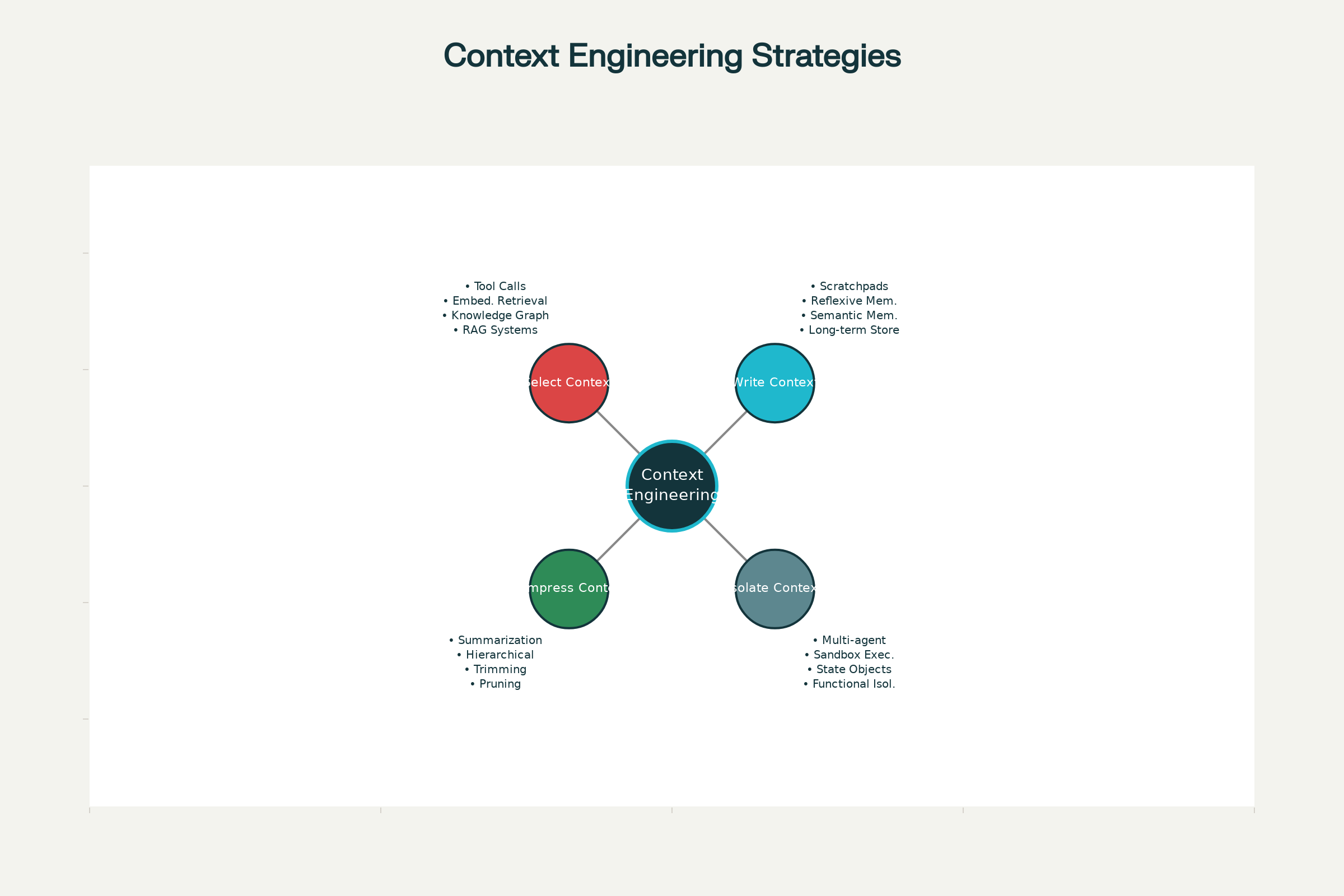
De Vier Kernstrategieën voor Context Engineering
Bij vooraanstaande AI-systemen—van Claude en ChatGPT tot gespecialiseerde agenten bij Anthropic en andere frontier labs—zijn vier kernstrategieën voor effectief contextbeheer uitgekristalliseerd. Deze kunnen onafhankelijk of gecombineerd worden ingezet.
1. Write Context: Informatie Buiten het Contextvenster Opslaan
Het fundamentele principe is elegant eenvoudig: dwing het model niet alles te onthouden. Sla cruciale informatie op buiten het contextvenster, zodat deze betrouwbaar opvraagbaar is wanneer nodig.
Kladblokken zijn de meest intuïtieve implementatie. Zoals mensen aantekeningen maken bij complexe problemen, gebruiken AI-agenten kladblokken om informatie te bewaren voor toekomstig gebruik. Implementatie kan zo simpel zijn als een tool die de agent oproept om notities op te slaan, of zo geavanceerd als velden in een runtime state-object dat over executiestappen heen behoudt.
De multi-agent researcher van Anthropic illustreert dit prachtig: de LeadResearcher formuleert een aanpak en slaat het plan op in Memory voor persistentie, erkennend dat bij overschrijding van het contextvenster (200.000 tokens) truncatie optreedt en het plan behouden moet blijven.
Memories breiden het kladblokconcept uit over sessies heen. In plaats van alleen informatie vast te leggen binnen één taak (sessiegeheugen), kunnen systemen langetermijngeheugens opbouwen die evolueren over vele interacties tussen gebruiker en agent. Dit patroon is standaard geworden in producten als ChatGPT, Claude Code, Cursor en Windsurf.
Onderzoeksinitiatieven zoals Reflexion introduceerden reflectieve memories—waarbij de agent na elke beurt reflecteert en geheugen aanmaakt voor toekomstig gebruik. Generative Agents breidden deze aanpak uit door periodiek memories te synthetiseren uit verzamelingen van eerdere feedback.
Drie Types Memories:
Episodisch: Concrete voorbeelden van eerder gedrag of interacties (onmisbaar voor few-shot learning)
Procedureel: Instructies of regels die gedrag sturen (voor consistente werking)
Semantisch: Feiten en relaties over de wereld (voor gefundeerde kennis)
2. Select Context: De Juiste Informatie Ophalen
Zodra informatie bewaard is, moet de agent alleen relevante informatie ophalen voor de huidige taak. Slechte selectie kan even schadelijk zijn als geen geheugen—irrelevante informatie kan het model verwarren of hallucinaties uitlokken.
Mechanismen voor geheugenselectie:
Eenvoudige benaderingen gebruiken smalle, altijd-ingesloten bestanden. Claude Code gebruikt een CLAUDE.md-bestand voor procedurele memories, terwijl Cursor en Windsurf rules-bestanden gebruiken. Deze aanpak schiet echter tekort bij honderden feiten en relaties.
Voor grotere geheugencollecties worden embedding-gebaseerde retrieval en kennisgraafstructuren veel gebruikt. Het systeem zet zowel memories als de huidige query om naar vectorrepresentaties en haalt de meest semantisch vergelijkbare memories op.
Toch, zoals Simon Willison op het AIEngineer World’s Fair demonstreerde, kan deze aanpak spectaculair falen. ChatGPT voegde onverwacht zijn locatie uit memories toe aan een gegenereerde afbeelding—zelfs geavanceerde systemen kunnen dus memories ongepast ophalen. Dit benadrukt het belang van nauwgezette engineering.
Toolselectie is een eigen uitdaging. Wanneer agenten tientallen of honderden tools tot hun beschikking hebben, kan simpelweg opsommen voor verwarring zorgen—overlappende beschrijvingen leiden tot verkeerde toolselectie. Een effectieve oplossing: pas RAG-principes toe op toolbeschrijvingen. Door enkel semantisch relevante tools op te halen, is de accuraatheid van toolselectie tot driemaal verbeterd.
Kennisophaling is wellicht de rijkste probleemruimte. Codeagenten illustreren deze uitdaging op productieschaal. Zoals een Windsurf-engineer opmerkte: code indexeren is niet hetzelfde als effectieve contextophaling. Ze doen indexering en embedding search met AST-parsing en chunking op semantisch zinvolle grenzen. Maar embedding search wordt onbetrouwbaar bij groeiende codebases. Succes vereist een combinatie van grep/bestandzoek, kennisgraaf-gebaseerde retrieval en een re-ranking stap waarbij context op relevantie wordt gerangschikt.
3. Compress Context: Alleen Het Nodige Behouden
Bij langlopende taken groeit de context natuurlijk aan. Kladbloknotities, tooloutputs en interactiegeschiedenis kunnen snel het contextvenster overschrijden. Compressiestrategieën pakken deze uitdaging aan door informatie intelligent te destilleren, terwijl essentiële inhoud behouden blijft.
Samenvatten is de primaire techniek. Claude Code implementeert “auto-compact”—wanneer het contextvenster 95% vol raakt, wordt de hele interactietraject samengevat. Dit kan via verschillende strategieën:
Recursieve samenvatting: Samenvattingen van samenvattingen om compacte hiërarchieën te bouwen
Hiërarchische samenvatting: Genereren van samenvattingen op verschillende abstractieniveaus
Gerichte samenvatting: Alleen specifieke componenten samenvatten (zoals token-intensieve zoekresultaten) in plaats van de volledige context
Cognition AI onthulde dat zij fijn-afgestelde modellen gebruiken voor samenvatten bij agent-agent grenzen om tokengebruik tijdens kennisoverdracht te beperken—wat de diepte van deze engineeringstap toont.
Context inkorten biedt een aanvullende methode. In plaats van een LLM intelligent te laten samenvatten, knipt trimming de context met harde heuristieken—oude berichten verwijderen, op belangrijkheid filteren, of getrainde pruners zoals Provence gebruiken voor vraag-en-antwoord taken.
Het belangrijkste inzicht: Wat je verwijdert, kan even belangrijk zijn als wat je behoudt. Een gefocust contextvenster van 300 tokens presteert vaak beter dan een ongerichte van 113.000 tokens bij conversatietaken.
4. Isolate Context: Informatie Verdelen over Systemen
Ten slotte erkennen isolatiestrategieën dat verschillende taken andere informatie vereisen. In plaats van alle context in het venster van één model te stoppen, verdelen isolatietechnieken context over gespecialiseerde systemen.
Multi-agent Architecturen zijn de meest gebruikte aanpak. De OpenAI Swarm-bibliotheek is expliciet ontworpen rond “scheiding der taken”—waar gespecialiseerde subagenten specifieke taken afhandelen met eigen tools, instructies en contextvensters.
Anthropic’s onderzoek toont de kracht van deze aanpak: veel agenten met geïsoleerde contexten presteerden beter dan enkele-agent implementaties, vooral omdat elk subagent-contextvenster toegewezen kon worden aan een smallere subtaak. Subagenten werken parallel met eigen contextvensters, waarbij verschillende aspecten van de vraag gelijktijdig worden onderzocht.
Toch zijn er afwegingen bij multi-agentsystemen. Anthropic rapporteerde tot vijftien keer hoger tokengebruik vergeleken met enkele-agent chat. Dit vereist zorgvuldige orkestratie, prompt engineering voor planning en geavanceerde coördinatiemechanismen.
Sandbox Omgevingen bieden een andere isolatiestrategie. HuggingFace’s CodeAgent demonstreert dit: in plaats van JSON terug te sturen waar het model over moet redeneren, genereert de agent code die wordt uitgevoerd in een sandbox. Geselecteerde outputs (return values) worden teruggegeven aan de LLM, zodat tokenzware objecten geïsoleerd blijven in de uitvoeringsomgeving. Dit is vooral effectief voor visuele en audiodata.
State Object Isolatie is wellicht de meest ondergewaardeerde techniek. De runtime state van een agent kan ontworpen worden als een gestructureerd schema (zoals een Pydantic-model) met meerdere velden. Eén veld (zoals messages) wordt bij elke stap aan de LLM getoond, terwijl andere velden geïsoleerd blijven voor selectief gebruik. Dit biedt fijnmazige controle zonder architecturale complexiteit.
Vier Kernstrategieën voor Effectieve Context Engineering in AI-agenten
Het Context Rot Probleem: Een Kritische Uitdaging
Hoewel de vooruitgang in contextlengte in de industrie werd gevierd, toont recent onderzoek een zorgwekkende realiteit: langere context leidt niet automatisch tot betere prestaties.
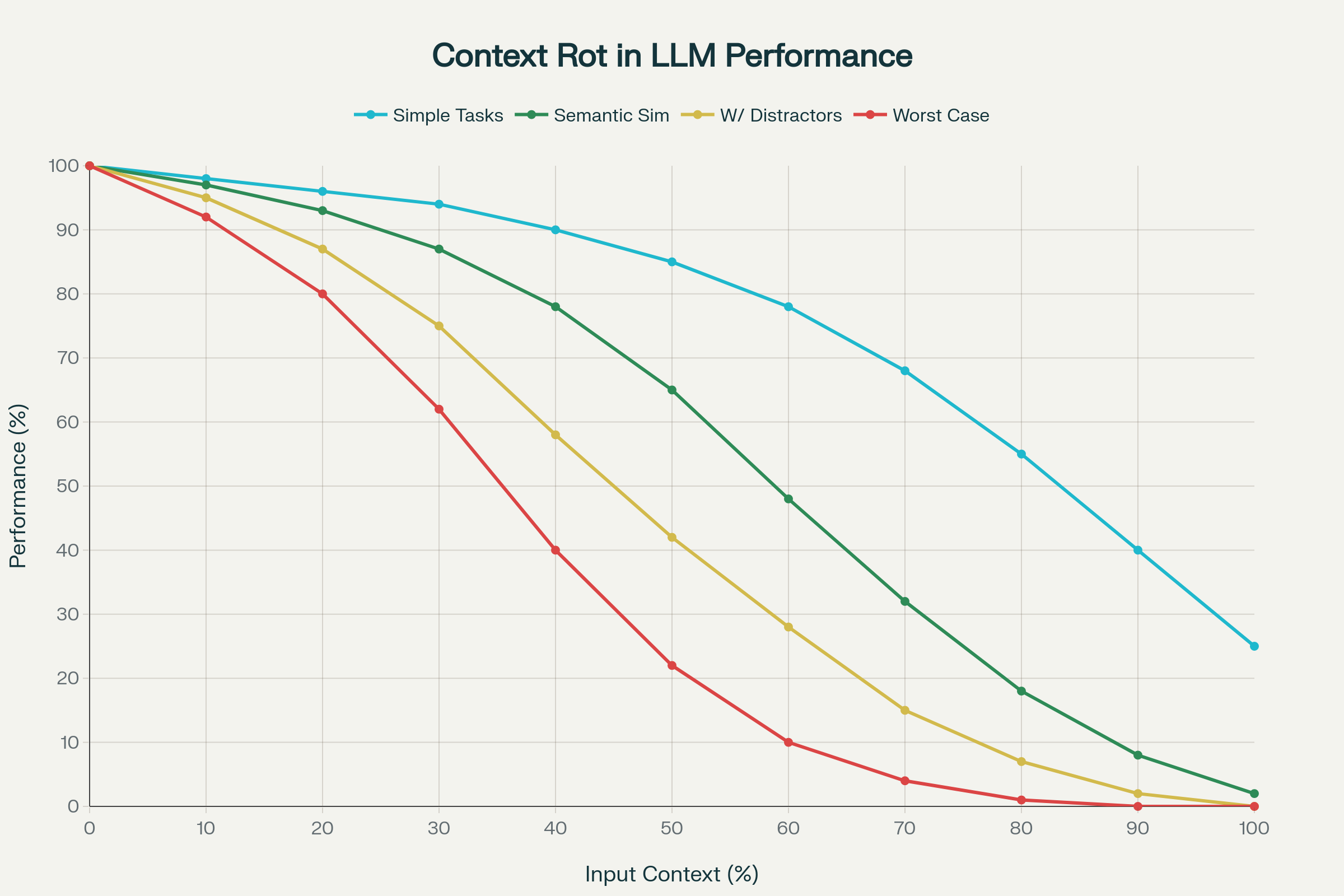
Een baanbrekende studie van 18 toonaangevende LLM’s—waaronder GPT-4.1, Claude 4, Gemini 2.5 en Qwen 3—onthulde het verschijnsel context rot: de onvoorspelbare en vaak ernstige achteruitgang van prestaties naarmate de inputcontext groeit.
Belangrijkste Bevindingen over Context Rot
1. Niet-uniforme Prestatieafname
Prestaties dalen niet lineair of voorspelbaar. Modellen vertonen scherpe, idiosyncratische dalingen afhankelijk van het specifieke model en de taak. Een model kan tot een bepaalde contextlengte 95% nauwkeurig blijven, om daarna plots te dalen naar 60%. Deze kliffen zijn onvoorspelbaar per model.
2. Semantische Complexiteit Verergert Context Rot
Eenvoudige taken (zoals herhaalde woorden kopiëren of exacte semantische retrieval) tonen gematigde achteruitgang. Maar als “naalden in de hooiberg” gevonden moeten worden op basis van semantische gelijkenis, daalt de prestatie sterk. Het toevoegen van plausibele afleiders—informatie die lijkt op wat nodig is, maar net niet—verergert de nauwkeurigheid dramatisch.
3. Positiebias en Aandachtscollapse
Transformer-aandacht schaalt niet lineair over lange contexten. Tokens aan het begin (primacy bias) en einde (recency bias) krijgen onevenredig veel aandacht. In extreme gevallen stort de aandacht volledig in en negeert het model grote delen van de input.
4. Modelspecifieke Faalpatronen
Verschillende LLM’s vertonen unieke gedragingen op schaal:
GPT-4.1: Neigt tot hallucinatie, herhaalt foutieve tokens
Gemini 2.5: Voegt niet-gerelateerde fragmenten of interpunctie toe
Claude Opus 4: Kan taken weigeren of te voorzichtig worden
5. Impact in Praktijksituaties
Misschien wel het meest veelzeggend: in de LongMemEval-benchmark presteerden modellen met toegang tot een volledig gesprek (ongeveer 113k tokens) aanzienlijk beter wanneer alleen het relevante segment van 300 tokens werd gegeven. Dit toont aan dat context rot zowel retrieval als redeneren in echte dialogen aantast.
Context Rot: Prestatieafname naarmate de inputtokenlengte toeneemt bij 18 LLM’s
Gevolgen: Kwaliteit Boven Kwantiteit
De belangrijkste conclusie uit context rot-onderzoek is scherp: het aantal inputtokens is niet de enige bepalende factor voor kwaliteit. Hoe de context wordt opgebouwd, gefilterd en gepresenteerd is minstens zo belangrijk.
Deze bevinding bevestigt het bestaansrecht van context engineering. In plaats van lange contextvensters te zien als een wondermiddel, erkennen geavanceerde teams dat zorgvuldige context engineering—door compressie, selectie en isolatie—essentieel is om prestaties te behouden bij grote input.
Context Engineering in de Praktijk: Toepassingen
Casus 1: Multi-Turn Agent Systemen (Claude Code, Cursor)
Claude Code en Cursor vertegenwoordigen state-of-the-art context engineering voor code-assistentie:
Verzameling: Deze systemen halen context uit meerdere bronnen—open bestanden, projectstructuur, bewerkgeschiedenis, terminaloutput en gebruikerscommentaar.
Beheer: In plaats van alle bestanden in de prompt te dumpen, comprimeren ze intelligent. Claude Code gebruikt hiërarchische samenvattingen. Context wordt getagd op functie (bv. “actueel bewerkt bestand”, “gerefereerde dependency”, “foutmelding”).
Gebruik: Elke beurt selecteert het systeem relevante bestanden en contextelementen, toont ze gestructureerd en houdt aparte sporen bij voor redeneren en zichtbare output.
Compressie: Bij het naderen van limieten activeert auto-compact, waarmee het interactietraject wordt samengevat terwijl belangrijke beslissingen behouden blijven.
Resultaat: Deze tools blijven bruikbaar bij grote projecten (duizenden bestanden) zonder prestatieverlies, ondanks beperkingen in het contextvenster.
Casus 2: Tongyi DeepResearch (Open-Source Deep Research Agent)
Tongyi DeepResearch toont hoe context engineering complexe onderzoekstaken mogelijk maakt:
Data Synthese Pipeline: In plaats van te vertrouwen op beperkte menselijk geannoteerde data, gebruikt Tongyi een geavanceerde datasynthesemethode om PhD-niveau onderzoeksvragen te genereren via iteratieve complexiteitsverhoging. Elke iteratie verdiept kennisgrenzen en bouwt complexere redeneertaken.
Contextbeheer: Het systeem gebruikt het IterResearch-paradigma—elke ronde wordt een gestroomlijnde workspace opgebouwd met alleen essentiële output uit de vorige ronde. Zo wordt “cognitieve verstikking” door informatiestapeling voorkomen.
Parallelle Verkenning: Meerdere onderzoeksagenten werken parallel met gescheiden contexten, elk op een ander aspect. Een syntheseagent integreert hun bevindingen tot een volledig antwoord.
Resultaten: Tongyi DeepResearch presteert op gelijke voet met propriëtaire systemen als OpenAI’s DeepResearch, met scores van 32,9 op Humanity’s Last Exam en 75 op gebruikersgerichte benchmarks.
Casus 3: Anthropic’s Multi-Agent Researcher
Anthropic’s onderzoek toont hoe isolatie en specialisatie de prestaties verbeteren:
Architectuur: Gespecialiseerde subagenten nemen specifieke onderzoekstaken (literatuurstudie, synthese, verificatie) op zich met aparte contextvensters.
Voordelen: Deze aanpak presteerde beter dan single-agent systemen, met voor elke subagent geoptimaliseerde context.
Afweging: Hoewel de kwaliteit superieur was, steeg het tokengebruik tot vijftien keer ten opzichte van single-agent chat.
Dit onderstreept een belangrijk inzicht: context engineering draait vaak om afwegingen tussen kwaliteit, snelheid en kosten. De juiste balans hangt af van de toepassingsvereisten.
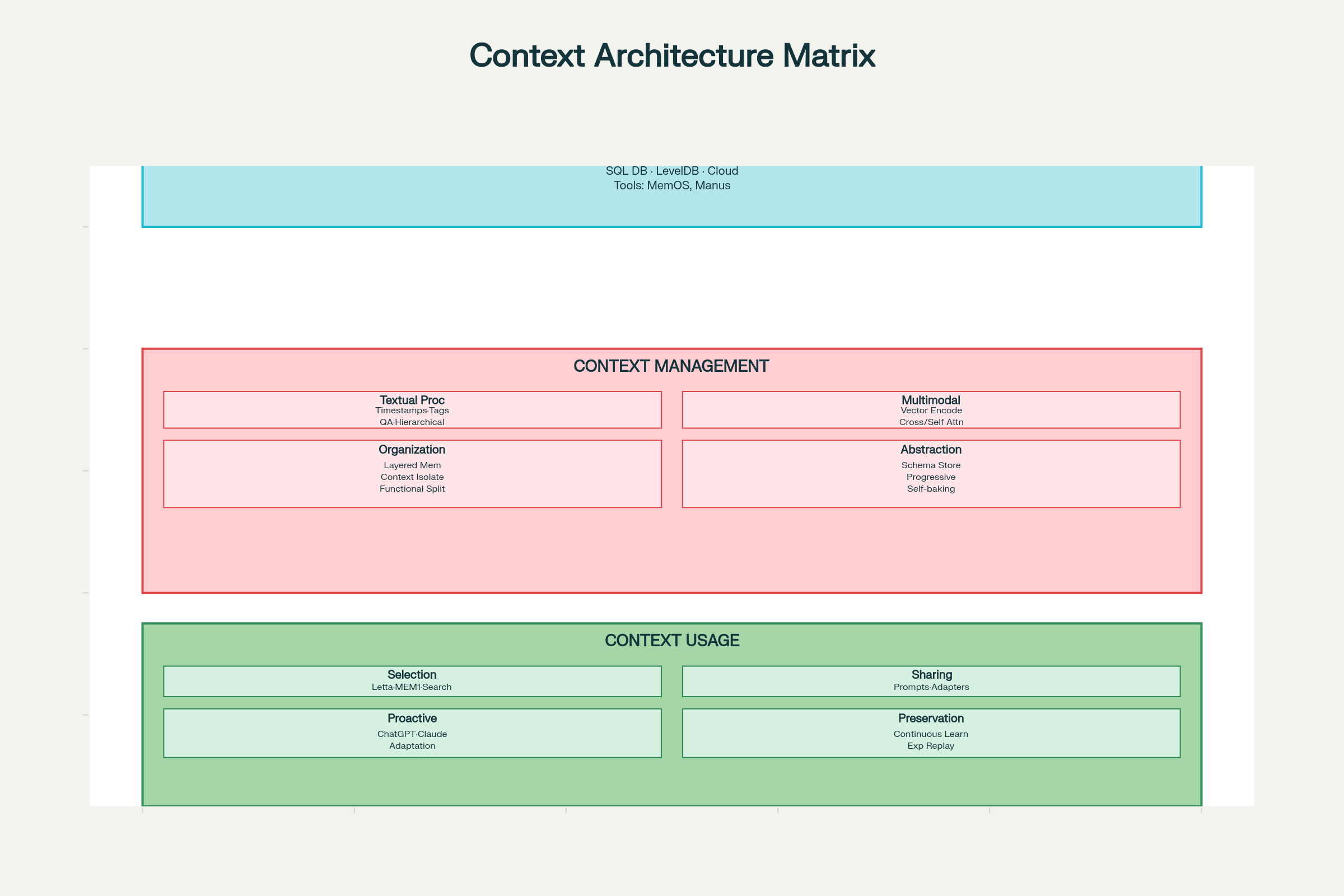
Het Design Considerations Framework
Effectieve context engineering vereist systematisch denken over drie dimensies: verzameling & opslag, beheer en gebruik.
Context Engineering Ontwerpkeuzes: Volledige Systeemarchitectuur en Componenten
Verzameling & Opslag Ontwerpkeuzes
Opslagtechnologieën:
Lokale opslag (SQLite, LevelDB): Snel, lage latency, geschikt voor agents aan de clientzijde
Gedistrubeerde systemen: Voor enorme schaal met redundantie en fouttolerantie
Ontwerppatronen:
MemOS: Memory operating system voor uniform geheugenbeheer
Manus: Gestructureerd geheugen met rolgebaseerde toegang
Belangrijk principe: Ontwerp voor efficiënte retrieval, niet alleen opslag. Het optimale opslagsysteem is dat waarin je snel vindt wat je nodig hebt.
Beheer Ontwerpkeuzes
Tekstuele contextverwerking:
Timestamp-markering: Simpel maar beperkt. Behoudt chronologie maar geen semantische structuur, leidt tot schaalproblemen bij veel interacties.
Rol/Functie-tagging: Tag elk contextelement met zijn functie—“doel”, “beslissing”, “actie”, “fout”, enzovoorts. Ondersteunt multi-dimensionale tagging (prioriteit, bron, vertrouwen). Recente systemen als LLM4Tag maken dit schaalbaar.
Compressie met QA-paren: Interacties omzetten naar gecomprimeerde vraag-antwoord paren, behoudt essentiële info en reduceert tokens.
Hiërarchische notities: Progressieve compressie tot betekenisvectoren, zoals in H-MEM-systemen, vangt semantische essentie op verschillende abstractieniveaus.
Multimodale contextverwerking:
Vergelijkbare vectorruimtes: Alle modaliteiten (tekst, beeld, audio) coderen naar vergelijkbare vectorruimtes via gedeelde embeddingmodellen (zoals bij ChatGPT en Claude).
Cross-attention: Eén modaliteit gebruiken om aandacht naar een andere te leiden (zoals bij Qwen2-VL).
Onafhankelijke codering met self-attention: Modaliteiten afzonderlijk coderen, dan combineren via unified attention-mechanismen.
Sleutelfeiten extraheren via vaste schema’s (ChatSchema-aanpak)
Progressief comprimeren tot betekenisvectoren (H-MEM-systemen)
Gebruik Ontwerpkeuzes
Contextselectie:
Embedding-gebaseerde retrieval (meest gangbaar)
Traverseren van kennisgraaf (voor complexe relaties)
Semantische gelijkenisscore
Recency/prioriteitsweging
Contextdeling:
Binnen een systeem:
Geselecteerde context embedden in prompts (AutoGPT, ChatDev-aanpak)
Gestructureerde berichtuitwisseling tussen agenten (Letta, MemOS)
Gedeeld geheugen via indirecte communicatie (A-MEM-systemen)
Over systemen heen:
Adapters die contextformaat converteren (Langroid)
Gedeelde representaties over platforms (Sharedrop)
Proactieve gebruikersinference:
ChatGPT en Claude analyseren interactiepatronen om gebruikersbehoeften te voorspellen
Contextsystemen leren informatie te presenteren vóórdat die expliciet wordt gevraagd
Balans tussen behulpzaamheid en privacy blijft een belangrijk ontwerpuitdaging
Context Engineering Skills en Wat Teams Moeten Beheersen
Nu context engineering steeds centraler wordt in AI-ontwikkeling, onderscheiden bepaalde vaardigheden effectieve teams van teams die moeite hebben op te schalen.
1. Strategische Contextopbouw
Teams moeten begrijpen welke informatie elke taak dient. Dit gaat verder dan data verzamelen—het vereist dieper inzicht in taakvereisten om te bepalen wat echt nodig is versus wat ruis oplevert.
In de Praktijk:
Analyseer faalpatronen van taken om ontbrekende context te identificeren
A/B-test verschillende contextcombinaties om impact te meten
Bouw observability om te volgen welke contextelementen prestaties sturen
2. Geheugensysteemarchitectuur
Effectieve geheugensystemen ontwerpen vereist inzicht in verschillende geheugentypes en wanneer die toe te passen:
Wanneer hoort informatie in kortetermijn- versus langetermijngeheugen?
Hoe moeten verschillende geheugentypes samenwerken?
Welke compressiestrategieën behouden voldoende detail bij tokenreductie?
3. Semantisch Zoeken en Retrieval
Teams moeten verder kunnen dan simpele keyword matching:
Embeddingmodellen en hun beperkingen
Vector-gelijkenismetrics en hun afwegingen
Herordening en filterstrategieën
Omgaan met ambigue queries
4. Token-economie en Kostenanalyse
Elke byte context kent afwegingen:
Monitor tokengebruik bij verschillende contextcomposities
Begrijp modelspecifieke kosten voor tokenverwerking
Balans tussen kwaliteit, kosten en latency
5. Systeemorkestratie
Met meerdere agenten, tools en geheugensystemen is zorgvuldige orkestratie essentieel:
Coördinatie tussen subagenten
Afhandeling en herstel bij faalpatronen
Statemanagement bij langlopende taken
6. Evaluatie en Meting
Context engineering is in essentie een optimalisatiediscipline:
Definieer metrics die prestaties vangen
A/B-test context engineering benaderingen
Meet impact op eindgebruikerservaring, niet alleen modelnauwkeurigheid
Zoals een senior engineer opmerkte: de snelste weg naar kwaliteits-AI-software voor klanten is het opnemen van kleine, modulaire agentconcepten in bestaande producten.
Best Practices voor Context Engineering
1. Begin Simpel, Breid Bewust Uit
Start met basis prompt engineering plus kladblokachtig geheugen. Voeg pas complexiteit toe (multi-agent isolatie, geavanceerde retrieval) bij duidelijke noodzaak.
2. Meet Alles
Gebruik tools als LangSmith voor observability. Houd bij:
Scheiding van verantwoordelijkheden tussen contextcomponenten
5. Bouw Context-First, Niet LLM-First
Begin niet met “welke LLM moeten we gebruiken,” maar met “welke context vereist deze taak?” De LLM is slechts een component in een groter contextgedreven systeem.
6. Omarm Gelaagde Architecturen
Splits:
Werkgeheugen (actueel contextvenster)
Kortetermijngeheugen (recente interacties)
Langetermijngeheugen (permanente feiten)
Elke laag heeft een eigen doel en kan afzonderlijk geoptimaliseerd worden.
Uitdagingen en Toekomstige Richtingen
Huidige Uitdagingen
1. Context Rot en Schaling
Hoewel technieken bestaan om context rot te beperken, blijft het fundamentele probleem onopgelost. Naarmate inputs groter worden, zijn geavanceerde selectie- en compressiemechanismen onmisbaar.
2. Geheugenconsistentie en Coherentie
Consistentie behouden tussen verschillende geheugentypes en tijdschalen is lastig. Conflicterende memories of verouderde informatie kunnen prestaties verminderen.
3. Privacy en Selectieve Openbaarheid
Naarmate systemen rijkere context over gebruikers behouden, wordt de balans tussen personalisatie en privacy kritiek. Het probleem “het contextvenster is niet meer van hen” ontstaat als onverwachte informatie opduikt.
4. Computationele Overhead
Geavanceerde context engineering kost rekenkracht. Selectie-, compressie- en retrievalmechanismen vragen allemaal resources. De juiste balans vinden is een open uitdaging.
Veelbelovende Toekomstige Richtingen
1. Lerende Context Engineers
In plaats van handmatig contextbeheer kunnen systemen via meta-leren of reinforcement learning zelf optimale contextselectiestrategieën leren.
2. Opkomst van Symbolische Mechanismes
Recent onderzoek suggereert dat LLM’s emergente symbolische verwerkingsmechanismen ontwikkelen. Deze benutten kan geavanceerdere contextabstractie en redeneren mogelijk maken.
3. Cognitieve Tools en Prompt Programming
Frameworks zoals IBM’s “Cognitive Tools” vatten redeneermodules op als herbruikbare componenten. Zo wordt context engineering meer als composable software—kleine, herbruikbare stukjes die samenwerken.
4. Neural Field Theory voor Context
In plaats van discrete contextelementen, kan het modelleren van context als een continu neuraal veld soepelere, adaptievere contextmanagement mogelijk maken.
5. Quantum Semantiek en Superpositie
Vroeg onderzoek onderzoekt of context quantum superpositie-concepten kan benutten—informatie die in meerdere toestanden bestaat tot het nodig is. Dit kan de opslag en retrieval van context radicaal veranderen.
Conclusie: Waarom Context Engineering Nu Telt
We staan op een kantelpunt in AI-ontwikkeling. Jarenlang lag de focus op het vergroten en verbeteren van modellen. De vraag was: “Hoe verbeteren we de LLM?”
De frontier-vraag van vandaag is anders: “Hoe ontwerpen we systemen rond LLM’s om hun volledige potentieel te benutten?”
Context engineering beantwoordt die vraag. Het is geen beperkte technische hack—het is een fund
Veelgestelde vragen
Prompt engineering richt zich op het opstellen van een enkele instructie voor een LLM. Context engineering is een bredere systeemdiscipline die het volledige informatie-ecosysteem voor een AI-model beheert, inclusief geheugen, tools en opgehaalde data, om prestaties op complexe, stateful taken te optimaliseren.
Context rot is de onvoorspelbare achteruitgang van de prestaties van een LLM naarmate de inputcontext langer wordt. Modellen kunnen scherpe dalingen in nauwkeurigheid vertonen, delen van de context negeren of hallucineren, wat de noodzaak aantoont van kwaliteitsvolle en zorgvuldige contextmanagement boven pure kwantiteit.
De vier kernstrategieën zijn: 1. Write Context (informatie buiten het contextvenster opslaan, zoals kladblokken of geheugen), 2. Select Context (alleen relevante informatie ophalen), 3. Compress Context (samenvatten of inkorten om ruimte te besparen), en 4. Isolate Context (gebruik maken van multi-agent systemen of sandboxes om taken te scheiden).
Arshia is een AI Workflow Engineer bij FlowHunt. Met een achtergrond in computerwetenschappen en een passie voor AI, specialiseert zij zich in het creëren van efficiënte workflows die AI-tools integreren in dagelijkse taken, waardoor productiviteit en creativiteit worden verhoogd.
Arshia Kahani
AI Workflow Engineer
Beheers Context Engineering
Klaar om de volgende generatie AI-systemen te bouwen? Verken onze bronnen en tools om geavanceerde context engineering toe te passen in jouw projecten.
Lang leve Context Engineering: Productieklare AI-systemen bouwen met moderne vectordatabases
Ontdek hoe context engineering AI-ontwikkeling hervormt, de evolutie van RAG naar productieklare systemen, en waarom moderne vectordatabases zoals Chroma essent...
De Toekomst Is Gevormd door Prompts: Waarom Prompt Engineering de Nieuwe Kernvaardigheid Is
Ontdek waarom prompt engineering snel een essentiële vaardigheid wordt voor iedere professional, hoe het de productiviteit op de werkvloer verandert en hoe je e...
Context Engineering voor AI Agents: De Kunst van het Voeden van LLMs met de Juiste Informatie
Leer hoe je context voor AI agents ontwerpt door tool-feedback te beheren, tokengebruik te optimaliseren en strategieën als offloading, compressie en isolatie t...
19 min lezen
AI Agents
LLM
+3
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.