Hoe maak je aangepaste kennisbankpagina's in Hugo van LiveAgent-tickets
Leer hoe je het aanmaken van kennisbankartikelen in Hugo automatiseert, direct vanuit klantenservicetickets met behulp van AI-agents en GitHub-integratie.
Automation
Knowledge Base
Hugo
GitHub
AI Agents
Customer Support
Klantenserviceteams genereren elke dag waardevolle inzichten via hun interacties met klanten. Deze vragen, zorgen en oplossingen vormen een goudmijn aan informatie waar je hele gebruikersbestand van kan profiteren als het goed wordt vastgelegd. Handmatig supporttickets omzetten in verzorgde kennisbankartikelen kost echter veel tijd, is repetitief en krijgt vaak een lagere prioriteit dan directe supportverzoeken. Wat als je dit hele proces zou kunnen automatiseren, zodat ruwe klantvragen worden omgezet in professioneel opgemaakte, SEO-geoptimaliseerde kennisbankpagina’s die direct op je website verschijnen? Dit is precies wat moderne automatiseringsworkflows nu mogelijk maken. Door je LiveAgent-ticketsysteem te koppelen aan Hugo (voor statische sites) en GitHub-versiebeheer, kun je een gestroomlijnde pijplijn creëren waarmee klantvragen automatisch worden omgezet in doorzoekbare en vindbare kennisbankcontent. In deze uitgebreide gids laten we zien hoe je dit krachtige automatiseringssysteem bouwt, welke technische architectuur erachter zit en welke praktische stappen je kunt nemen om het in jouw organisatie te implementeren.
Inzicht in kennisbankautomatisering
Een kennisbank is een centraal informatiepunt waar gebruikers antwoorden kunnen vinden op veelvoorkomende vragen, zonder dat ze direct hulp hoeven in te schakelen. Traditionele kennisbanken worden handmatig opgebouwd: supportteams schrijven artikelen, formatteren ze, optimaliseren voor zoekmachines en publiceren ze via een contentmanagementsysteem. Dit proces vraagt veel mankracht en vormt een flinke bottleneck, vooral voor groeiende bedrijven die dagelijks honderden supportvragen ontvangen. Automatisering van de kennisbank verandert dit paradigma door kunstmatige intelligentie te gebruiken om relevante informatie uit supporttickets te halen, deze te structureren volgens vooraf ingestelde sjablonen en direct te publiceren op je website. Het automatiseringssysteem fungeert als een slimme schakel tussen je supportteam en je website, bepaalt welke tickets algemene kennis bevatten die voor andere gebruikers nuttig is, en transformeert de ruwe supportconversatie in professionele documentatie. Deze aanpak bespaart niet alleen tijd, maar zorgt ook voor consistentie in opmaak, structuur en SEO-optimalisatie van alle kennisbankartikelen. Het systeem kan worden afgestemd op jouw bedrijfssituatie, voorkomt dubbele content en zorgt voor een samenhangende kennisbank die organisch meegroeit met het aantal supportvragen.
Klaar om uw bedrijf te laten groeien?
Start vandaag uw gratis proefperiode en zie binnen enkele dagen resultaten.
Waarom kennisbankautomatisering belangrijk is voor jouw bedrijf
De zakelijke voordelen van kennisbankautomatisering zijn overtuigend en veelzijdig. Ten eerste vermindert het drastisch het aantal supportvragen door klanten in staat te stellen zelf antwoorden te vinden. Onderzoeken tonen consistent aan dat klanten de voorkeur geven aan selfservice als die goed werkt. Een goed onderhouden kennisbank kan het aantal supporttickets met 20-30% verminderen. Ten tweede verhoogt het de klanttevredenheid door direct antwoord te geven op veelvoorkomende vragen, zonder wachttijd. Ten derde levert het aanzienlijke SEO-voordelen op: kennisbankartikelen worden geïndexeerd door zoekmachines en trekken organisch verkeer naar je website, waardoor je zichtbaarheid toeneemt en je nieuwe klanten aantrekt via zoekopdrachten. Ten vierde leg je bedrijfskennis vast die anders verloren zou gaan bij vertrek van teamleden. Elke supportinteractie bevat waardevolle context en oplossingen die, eenmaal gedocumenteerd, onderdeel worden van het permanente kennisbestand van je bedrijf. Ten vijfde kan je supportteam zich richten op complexe, waardevolle kwesties in plaats van telkens dezelfde vragen te beantwoorden. Door kennisbankcontent uit supporttickets te automatiseren, creëer je in feite een krachtvermenigvuldiger voor je supportorganisatie. De tijd die je team besteedt aan het beantwoorden van vragen, wordt vastgelegde kennis die duizenden toekomstige klanten helpt. Tot slot levert het waardevolle data op over waar je klanten mee worstelen, wat weer input geeft voor productontwikkeling, marketing en klanteducatie.
De architectuur van geautomatiseerde kennisbankgeneratie
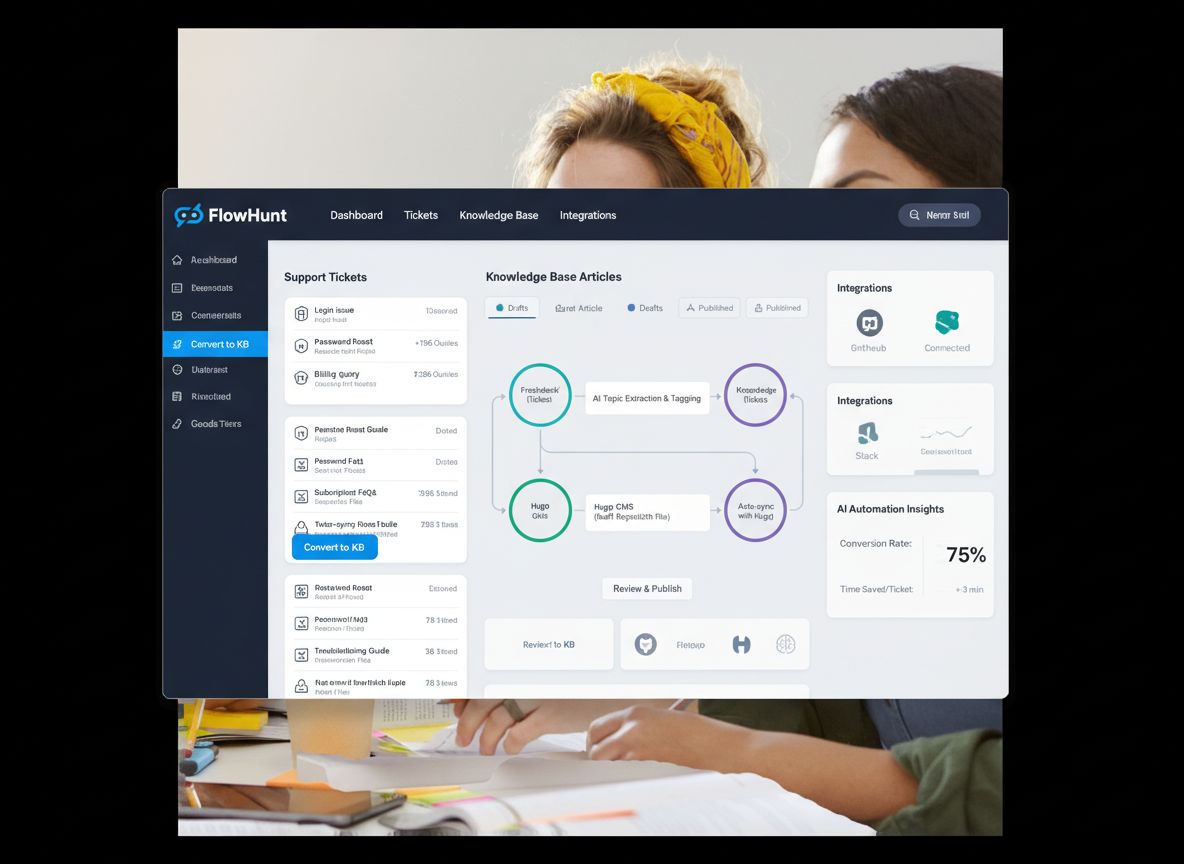
Voor het bouwen van een geautomatiseerd kennisbanksysteem moeten verschillende tools en platformen in een samenhangende workflow geïntegreerd worden. Het systeem bestaat meestal uit vier hoofdcomponenten: een ticketsysteem (LiveAgent), een AI-agent die tickets verwerkt, een versiebeheersysteem (GitHub) en een statische site generator (Hugo). LiveAgent is de bron van alle klantvragen en slaat alle supportgesprekken op met metadata zoals tags, categorieën en tijdstempels. De AI-agent is de regisseur van het hele proces: die ontvangt een ticket-ID, haalt de volledige ticketinhoud en gespreksgeschiedenis op, analyseert of het ticket geschikt is voor de kennisbank, controleert bestaande kennis om duplicaten te voorkomen, genereert SEO-geoptimaliseerde content in het juiste format en beheert de GitHub-workflow. GitHub fungeert als contentmanagement- en versiebeheerslaag waarmee je wijzigingen kunt reviewen, goedkeuren en volgen. Hugo, de statische site generator, zet de markdown-bestanden uit GitHub om in een snelle, veilige en SEO-vriendelijke website. Deze architectuur zorgt voor een duidelijke taakverdeling: LiveAgent regelt support, de AI-agent zorgt voor intelligentie en besluitvorming, GitHub voor versiebeheer en samenwerking, en Hugo voor presentatie. Het mooie is dat elke component los onderhouden en geüpdatet kan worden zonder de rest te verstoren.
Schrijf u in voor onze nieuwsbrief
Ontvang gratis de nieuwste tips, trends en aanbiedingen.
Hoe FlowHunt kennisbankautomatisering mogelijk maakt
FlowHunt zorgt voor de orkestratielaag die al deze systemen samenbrengt in één gestroomlijnde workflow. In plaats van maatwerkontwikkeling of complexe integraties kun je met FlowHunt visueel de automatiseringsflow ontwerpen en LiveAgent, GitHub en Hugo eenvoudig koppelen via een intuïtieve interface. Het platform regelt authenticatie, foutafhandeling, herhaalpogingen en alle technische complexiteit die anders veel ontwikkelwerk zou vergen. Met FlowHunt kun je geavanceerde automatiseringsworkflows maken zonder te programmeren, waardoor kennisbankautomatisering toegankelijk wordt voor teams zonder eigen ontwikkelaars. Het platform biedt ook geheugen- en contextbeheer, zodat je automatisering leert van eerdere uitvoeringen en slimme beslissingen neemt over het creëren of bijwerken van artikelen. Dankzij de integratie met GitHub worden pull requests automatisch aangemaakt, zodat je team gegenereerde content kan beoordelen vóór publicatie. Deze menselijke controle waarborgt de kwaliteit, terwijl je toch profiteert van de efficiëntie van automatisering.
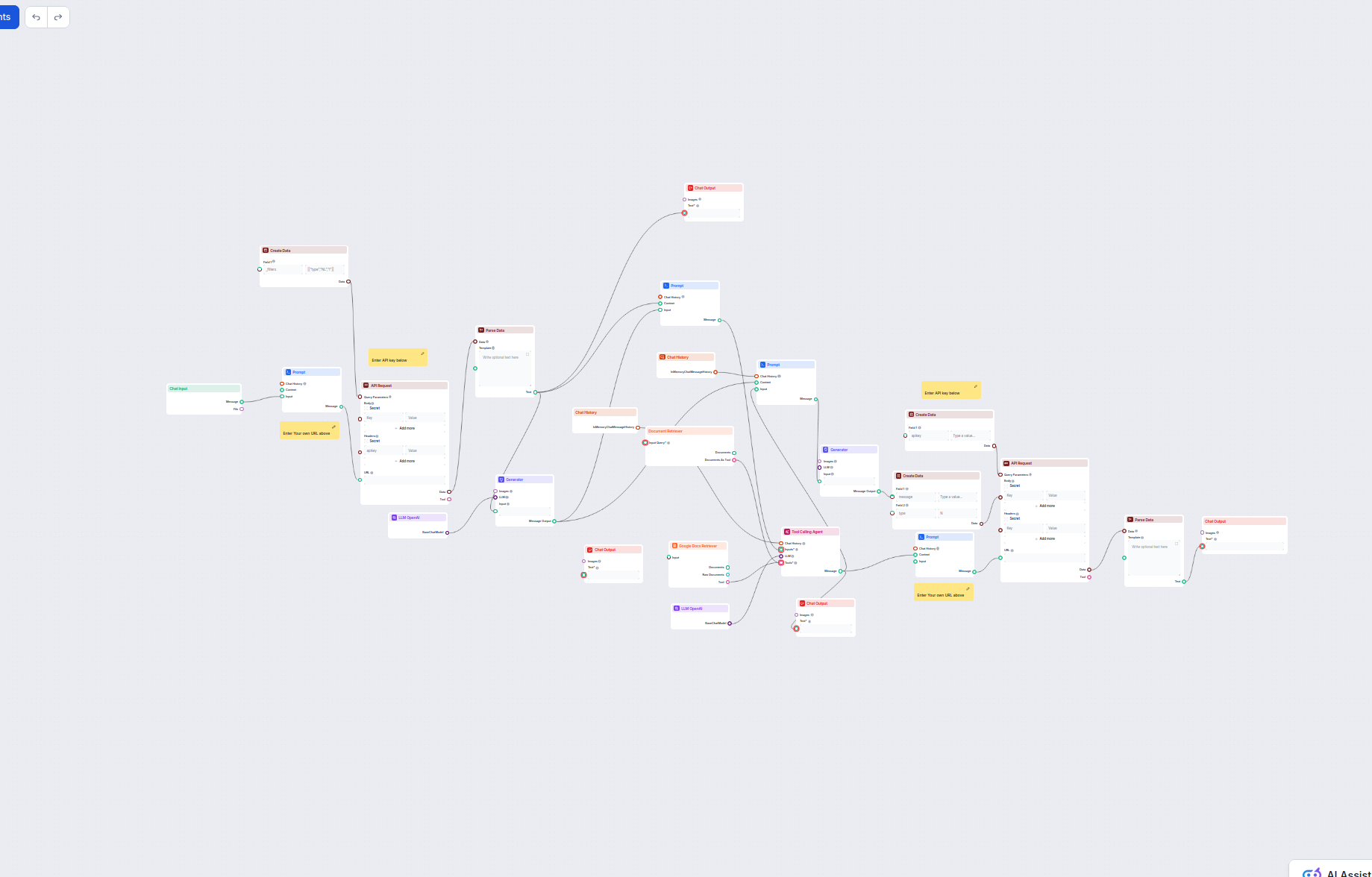
De volledige workflow: stap-voor-stap proces
De workflow voor het automatisch genereren van kennisbankartikelen volgt een zorgvuldig uitgedachte reeks stappen, die samen zorgen voor een volledig, productieklaar kennisbankartikel. Het begrijpen van dit proces is essentieel voor een succesvolle implementatie.
Stap één: Ticket ophalen en valideren
De workflow start zodra je een ticket-ID uit je LiveAgent-systeem invoert. De AI-agent haalt direct de volledige ticketinhoud op, inclusief onderwerpregel, tekst, alle tags en de complete gespreksgeschiedenis tussen klant en supportteam. Deze volledige context is belangrijk om accurate en relevante content te genereren. De agent controleert ook of het ticket voldoende informatie bevat en geschikt is voor publicatie in de kennisbank. Ontvang je bijvoorbeeld veel verzoeken voor demo-afspraken, dan kun je het systeem zo instellen dat deze automatisch worden overgeslagen, omdat ze geen algemene kennis bevatten die voor andere gebruikers nuttig is. Dankzij deze filtering raakt je kennisbank niet vervuild met administratieve of transactionele content die geen waarde toevoegt.
Stap twee: Duplicatendetectie met geheugen
Voordat er nieuwe content wordt gegenereerd, controleert het systeem in het geheugen of er al een soortgelijk kennisbankartikel bestaat. Dit geheugen is één van de belangrijkste functies van de automatisering, omdat het voorkomt dat er dubbele of bijna-dubbele artikelen worden aangemaakt, wat verwarring en SEO-verwatering zou veroorzaken. De AI-agent zoekt in eerdere tickets en artikelen naar vergelijkbare onderwerpen. Vindt hij een match, dan kan het bestaande artikel worden bijgewerkt of het aanmaken worden overgeslagen, afhankelijk van je instellingen. Bestaat er nog geen vergelijkbaar artikel, dan wordt dit ticket toegevoegd aan het geheugen als referentie voor toekomstige tickets. Dankzij dit geheugen wordt het systeem steeds slimmer: hoe meer tickets je verwerkt, hoe beter het systeem de structuur van je kennisbank leert kennen en intelligentere beslissingen neemt over contentcreatie en -updates.
Stap drie: Analyse van kennisbankstructuur
Het systeem bekijkt vervolgens je bestaande kennisbankrepository om te begrijpen hoe de content is gestructureerd, opgemaakt en georganiseerd. Deze stap is cruciaal voor consistentie over alle artikelen heen. De AI-agent analyseert bestaande markdownbestanden, frontmatterindelingen, kopjesstructuren en contentpatronen om de conventies van je kennisbank te leren. Hij kijkt naar hoe artikelen zijn gecategoriseerd, welke metadata wordt gebruikt, hoe afbeeldingen worden verwezen en welke SEO-elementen aanwezig zijn. Door je bestaande content te analyseren, leert het systeem jouw specifieke stijl en structuureisen, zodat nieuw gegenereerde artikelen naadloos aansluiten bij je bestaande kennisbank en niet opvallen als geautomatiseerde content.
Stap vier: GitHub-branchbeheer
Om overzichtelijk versiebeheer en goede review-workflows te garanderen, maakt het systeem een nieuwe of gebruikt een bestaande GitHub-branch voor de kennisbankupdate. In plaats van voor elk ticket een nieuwe branch te maken, beheert het systeem branches op een slimme manier, zodat je repository georganiseerd blijft. Bestaat er al een branch voor kennisbankupdates, dan wordt deze gebruikt en het nieuwe bestand eraan toegevoegd. Zo voorkom je een wildgroei aan branches, terwijl je meerdere updates in één pull request kunt bundelen. De branchnamen zijn meestal duidelijk, zoals “knowledge-base-updates” of “kb-automation”, zodat teamleden direct weten waarvoor de branch bedoeld is.
Stap vijf: Contentgeneratie en opmaak
Met alle context verzameld, genereert de AI-agent het kennisbankartikel. De gegenereerde content bevat een correct opgemaakte frontmatter met metadata zoals titel, beschrijving, keywords, tags, categorieën, publicatiedatum en call-to-action-elementen. De artikeltekst volgt een gestructureerd format, geoptimaliseerd voor zowel leesbaarheid als zoekmachines. Dit bestaat doorgaans uit een hoofdheadline, enkele H2-secties met vraaggerichte koppen (zoals “Wat is dit?”, “Waarom doen we dit?” en “Hoe doen we dit?”), en gedetailleerde antwoorden als paragrafen en bulletpoints. Deze structuur is geoptimaliseerd voor featured snippets en andere zoekmachinefuncties die duidelijke vraag-en-antwoordopbouw belonen. De tekst wordt in markdown geschreven, de standaard voor Hugo en de meeste static site generators, zodat bewerken en compatibiliteit eenvoudig zijn.
Stap zes: Bestand aanmaken en committen
Het systeem maakt een nieuw markdownbestand aan in je kennisbankmap met een bestandsnaam gebaseerd op het artikelonderwerp. De bestandsnaam is meestal ‘slugified’ (kleine letters, koppeltekens i.p.v. spaties), zodat deze aan webstandaarden voldoet. Het bestand bevat de volledige frontmatter en bodytekst uit de vorige stap. Daarna commit het systeem de wijzigingen naar de GitHub-branch met een duidelijke commit message waarin het originele ticket-ID wordt vermeld. Zo wordt een permanente koppeling gemaakt tussen het kennisbankartikel en het oorspronkelijke klantverzoek, wat traceerbaarheid en context biedt voor de toekomst.
Stap zeven: Pull request en review
Tot slot maakt het systeem een pull request van de kennisbankbranch naar je main branch. Deze pull request bevat een beschrijving van de wijzigingen, het ticket-ID dat aan de basis lag en eventuele relevante context. De pull request is het moment waarop je team de gegenereerde content kan beoordelen, waar nodig aanpassingen kan doen, kan controleren of het artikel aan de kwaliteitseisen voldoet en past binnen de kennisbankstrategie. Deze menselijke review is essentieel: hoewel AI-content over het algemeen van hoge kwaliteit is, zorgt menselijke controle voor nauwkeurigheid, merkconsistentie en geschiktheid. Na goedkeuring kan de pull request gemerged worden in de hoofdbranch, waarna Hugo je website opnieuw bouwt en het nieuwe artikel publiceert.
Praktische implementatie: vinden en gebruiken van ticket-ID’s
Om deze automatiseringsworkflow te gebruiken, moet je het juiste ticket-ID uit je LiveAgent-systeem ophalen. LiveAgent toont ticket-ID’s op twee handige plekken. Ten eerste zie je in de LiveAgent-interface zelf een label ‘Ticket’ met het ID duidelijk zichtbaar. Je kunt deze ID direct kopiëren. Ten tweede, en vaak nog makkelijker, vind je de ticket-ID in de URL van de ticketpagina. Open je een ticket in LiveAgent, dan zie je aan het eind van de URL een parameter als “ID=12345”. Deze ID heb je nodig voor de automatiseringsworkflow. Zodra je het ticket-ID hebt, voer je het in in de FlowHunt-workflow en start het hele proces automatisch. Het systeem haalt het ticket op, analyseert het, controleert op duplicaten, genereert het artikel, maakt de GitHub-branch en pull request en waarschuwt je team voor review. Het hele proces is meestal in enkele seconden tot minuten afgerond, afhankelijk van de complexiteit van het ticket en de omvang van je kennisbank.
Versnel je workflow met FlowHunt
Ontdek hoe FlowHunt je kennisbank automatisch aanmaakt vanuit supporttickets — van ticketanalyse en contentgeneratie tot GitHub-integratie en Hugo-publicatie — alles in één soepele workflow.
Als de basisworkflow staat, zijn er verschillende geavanceerde instellingen waarmee je het systeem kunt optimaliseren voor jouw situatie. Je kunt het systeem instellen om bepaalde tickettypes over te slaan op basis van tags, categorieën of keywords. Zo kun je bijvoorbeeld alle tickets met de tag “billing” of “account-specifiek” negeren, omdat deze zelden algemene kennis opleveren. Ook kun je drempels instellen voor de kwaliteit of lengte van een artikel: is een ticket te kort of bevat het te weinig details, dan slaat het systeem het over en wacht op betere informatie. Het geheugensysteem kun je instellen met verschillende matching-algoritmen, van eenvoudige keywordmatching tot geavanceerde semantische vergelijkingen. Ook de frontmatter en contentstructuur kun je helemaal aanpassen aan je wensen, zoals het toevoegen van extra velden of het wijzigen van de artikelopmaak. Sommige organisaties voegen metadata toe als moeilijkheidsgraad, doelgroep of gerelateerde artikelen. Je kunt het systeem ook zo instellen dat automatisch afbeeldingen worden toegevoegd — gegenereerd door AI of uit je assetbibliotheek gehaald. Het systeem kan artikelen genereren in meerdere talen als je een internationaal publiek bedient. Verder kun je notificaties en approvals instellen, bijvoorbeeld dat specifieke teamleden artikelen uit bepaalde categorieën moeten goedkeuren voordat ze gepubliceerd worden.
Praktijkvoorbeeld: WordPress-integratiefout
Kijk naar een praktisch voorbeeld uit de workflow. Een klant dient een supportticket in over een WordPress-integratiefout. Het ticket bevat foutmeldingen, screenshots en een uitgebreide omschrijving van wat geprobeerd is. Het supportteam reageert met stappen voor probleemoplossing en lost het probleem uiteindelijk op. Dit ticket is een perfect voorbeeld voor kennisbankautomatisering. Zodra het ticket-ID aan de workflow wordt doorgegeven, haalt het systeem het volledige gesprek op, analyseert het en raadpleegt het geheugen. Omdat er nog geen artikel over WordPress-integratiefouten bestaat, wordt dit onderwerp toegevoegd aan het geheugen en gaat het systeem verder met artikelgeneratie. Het systeem bekijkt je bestaande kennisbank en ontdekt dat je voor technische troubleshooting-artikelen een specifiek format hanteert, met secties voor symptomen, oorzaken, oplossingen en preventie. Het gegenereerde artikel volgt deze indeling en vormt een uitgebreide gids voor WordPress-integratiefouten, zodat toekomstige klanten het probleem zelfstandig kunnen oplossen. Het artikel wordt in een GitHub-branch aangemaakt, er wordt een pull request gegenereerd, je team beoordeelt het, past het zo nodig aan en merge’t het. Binnen enkele minuten staat het live op je website, wordt het geïndexeerd door zoekmachines en is het beschikbaar voor klanten. De volgende keer dat iemand zoekt op “WordPress integratiefout” of hetzelfde probleem ervaart, vinden ze je kennisbankartikel en lossen ze hun probleem zelf op, zonder contact op te nemen met support.
Succes meten en ROI bepalen
Om de investering in kennisbankautomatisering te verantwoorden, is het belangrijk het effect te meten. Belangrijke metrics zijn: de afname van het aantal supporttickets over onderwerpen die in de kennisbank staan, de toename van organisch zoekverkeer, de tijdwinst voor je supportteam en de stijging van klanttevredenheidsscores. Je kunt meten hoeveel klanten kennisbankartikelen bezoeken voordat ze support inschakelen, hoeveel tickets verwijzen naar kennisbankartikelen en hoeveel klanten aangeven dat ze het antwoord in de kennisbank hebben gevonden. Ook kun je de kwaliteit van artikelen meten via gebruikersstatistieken als tijd op pagina, scroll-diepte en bounce-percentage. Waardevolle artikelen kennen hogere engagement. Je kunt eveneens het aantal gegenereerde artikelen, de bespaarde tijd ten opzichte van handmatige creatie en de kostenbesparing door minder support meten. De meeste organisaties zien dat kennisbankautomatisering zich binnen enkele maanden terugverdient door lagere supportkosten en hogere klanttevredenheid.
Conclusie
Het automatiseren van kennisbankcreatie op basis van LiveAgent-tickets biedt een enorme kans om je klantenservice efficiënter te maken, de SEO-prestaties van je website te verhogen en een waardevolle bron te bouwen die klanten nog lang na de initiële supportinteractie helpt. Door LiveAgent, GitHub, Hugo en AI-gedreven automatisering via FlowHunt te koppelen, krijg je een systeem dat ruwe klantvragen automatisch omzet in verzorgde, professionele kennisbankartikelen. De workflow is eenvoudig: geef een ticket-ID op en het systeem regelt alles van contentgeneratie tot GitHub-integratie en pull requests. Het geheugensysteem voorkomt dubbele content, terwijl de menselijke review de kwaliteit en merkconsistentie bewaakt. Naarmate je kennisbank groeit, wordt het een steeds waardevoller bezit dat supportkosten verlaagt, klanttevredenheid verhoogt en organisch verkeer naar je website brengt. De implementatie is toegankelijk voor teams zonder diepgaande technische kennis, waardoor deze krachtige automatisering beschikbaar is voor organisaties van elke omvang.
Veelgestelde vragen
Wat is een LiveAgent-ticket?
Een LiveAgent-ticket is een klantenserviceverzoek of -vraag die wordt geregistreerd in het LiveAgent-ticketsysteem. Elk ticket bevat een onderwerp, inhoud, tags en de volledige gespreksgeschiedenis, die gebruikt kunnen worden om kennisbankcontent te genereren.
Hoe vind ik mijn ticket-ID in LiveAgent?
Je kunt je ticket-ID op twee manieren vinden: (1) Zoek naar het label 'Ticket' met het ID zichtbaar in de LiveAgent-interface, of (2) Kijk aan het einde van de URL waar 'ID=je-ticket-id' staat. Kopieer deze ID om te gebruiken in de automatiseringsflow.
Kan de flow bepaalde typen tickets negeren?
Ja, de flow kan geconfigureerd worden om specifieke tickettypes te negeren. Je kunt hem bijvoorbeeld instellen om verzoeken voor demo-afspraken over te slaan, zodat er geen dubbele kennisbankpagina's worden aangemaakt over vergelijkbare onderwerpen.
Wat gebeurt er als er al een soortgelijk kennisbankartikel bestaat?
De flow gebruikt geheugen om te controleren of een soortgelijk onderwerp al eerder is verwerkt. Als er een match wordt gevonden, wordt het bestaande artikel zo nodig bijgewerkt, of wordt het aanmaken overgeslagen om duplicaten te voorkomen.
Hoe integreert de flow met GitHub?
De flow maakt of gebruikt een bestaande GitHub-branch, genereert een markdownbestand met de juiste frontmatter, commit de wijzigingen en maakt een pull request aan voor review voordat het wordt samengevoegd met de hoofdbranch.
Arshia is een AI Workflow Engineer bij FlowHunt. Met een achtergrond in computerwetenschappen en een passie voor AI, specialiseert zij zich in het creëren van efficiënte workflows die AI-tools integreren in dagelijkse taken, waardoor productiviteit en creativiteit worden verhoogd.
Arshia Kahani
AI Workflow Engineer
Automatiseer het aanmaken van je kennisbank
Transformeer klantenservicetickets automatisch in SEO-geoptimaliseerde kennisbankartikelen met de AI-workflows van FlowHunt.
Hoe ticketantwoorden automatiseren in LiveAgent met FlowHunt
Leer hoe je FlowHunt AI-flows integreert met LiveAgent om automatisch te reageren op klanttickets met behulp van intelligente automatiseringsregels en API-integ...
Een Automatische AI Ticket-Responder Bouwen met Spamdetectie
Leer hoe je een volledig geautomatiseerd klantenservicessysteem bouwt met AI-gestuurde ticketantwoorden en intelligente spamdetectie dankzij FlowHunt en LiveAge...
AI Klantenservice Agent met Kennisbank en API-verrijking
Deze door AI aangedreven workflow automatiseert klantenservice door interne kennisbankzoekopdrachten, kennisophaling uit Google Docs, API-integratie en geavance...
5 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.