Human-in-the-loop Middleware in Python: Veilige AI Agents Bouwen met Goedkeuringsworkflows
Leer hoe je human-in-the-loop middleware in Python implementeert met LangChain om goedkeurings-, bewerkings- en afwijsfunctionaliteit toe te voegen aan AI agents vóór tooluitvoering.
Het bouwen van AI agents die zelfstandig tools kunnen uitvoeren en acties kunnen ondernemen is krachtig, maar brengt inherente risico’s met zich mee. Wat gebeurt er als een agent besluit een e-mail te sturen met verkeerde informatie, een grote financiële transactie goedkeurt of kritieke databasegegevens aanpast? Zonder de juiste waarborgen kunnen autonome agents aanzienlijke schade veroorzaken voordat iemand doorheeft wat er is gebeurd. Hier wordt human-in-the-loop middleware essentieel. In deze uitgebreide gids laten we zien hoe je human-in-the-loop middleware in Python implementeert met LangChain, zodat je AI agents kunt bouwen die pauzeren voor menselijke goedkeuring voordat ze gevoelige operaties uitvoeren. Je leert hoe je goedkeuringsworkflows toevoegt, bewerkingsmogelijkheden implementeert en afwijzingen verwerkt—terwijl je de efficiëntie en intelligentie van je autonome systemen behoudt.
De Agentloop van AI en Tooluitvoering Begrijpen
Voordat we in human-in-the-loop middleware duiken, is het cruciaal te begrijpen hoe AI agents fundamenteel werken. Een AI agent werkt via een continue lus die herhaalt totdat de agent besluit dat de taak voltooid is. De kern van de agentloop bestaat uit drie primaire componenten: een taalmodel dat redeneert over de volgende stap, een set tools die de agent kan aanroepen om actie te ondernemen, en een systeem voor statusbeheer dat de gespreksgeschiedenis en relevante context bijhoudt. De agent ontvangt een inputbericht van een gebruiker, waarna het taalmodel deze input samen met de beschikbare tools analyseert en beslist of er een tool moet worden aangeroepen of een definitief antwoord moet worden gegeven. Als het model besluit een tool aan te roepen, wordt die tool uitgevoerd en worden de resultaten toegevoegd aan de gespreksgeschiedenis. Deze cyclus gaat door—modelredenering, toolselectie, toolexecutie, resultaatintegratie—totdat het model bepaalt dat er geen verdere toolaanroepen nodig zijn en een eindantwoord geeft aan de gebruiker.
Dit eenvoudige maar krachtige patroon is de basis geworden voor honderden AI agent frameworks in de afgelopen jaren. De elegantie van de agentloop zit in de flexibiliteit: door de tools die een agent ter beschikking heeft te veranderen, kun je hem totaal verschillende taken laten uitvoeren. Een agent met e-mailtools kan communicatie beheren, een agent met databasetools kan records opvragen en bijwerken, en een agent met financiële tools kan transacties verwerken. Maar deze flexibiliteit brengt ook risico met zich mee. Omdat de agentloop autonoom werkt, is er geen ingebouwd mechanisme om te pauzeren en een mens te vragen of een bepaalde actie daadwerkelijk moet worden genomen. Het model kan besluiten een e-mail te versturen, een databasequery uit te voeren of een financiële transactie goed te keuren, en tegen de tijd dat een mens het doorheeft, is de actie al uitgevoerd. Hier worden de beperkingen van de basale agentloop duidelijk in productieomgevingen.
Klaar om uw bedrijf te laten groeien?
Start vandaag uw gratis proefperiode en zie binnen enkele dagen resultaten.
Waarom Menselijk Toezicht van Belang is in Productie AI-Systemen
Naarmate AI agents capabeler worden en in echte bedrijfsomgevingen worden ingezet, wordt de behoefte aan menselijk toezicht steeds belangrijker. De impact van autonome agentacties verschilt sterk per context. Sommige toolaanroepen zijn laag-risico en kunnen direct zonder menselijke beoordeling worden uitgevoerd—bijvoorbeeld het lezen van een e-mail of het ophalen van informatie uit een database. Andere toolaanroepen zijn hoog-risico en mogelijk onomkeerbaar, zoals het versturen van communicatie namens een gebruiker, het overboeken van geld, het verwijderen van gegevens of het aangaan van verplichtingen namens een organisatie. In productiesystemen kunnen fouten van een agent tijdens hoog-risico operaties enorme gevolgen hebben. Een verkeerd geformuleerde e-mail naar de verkeerde ontvanger kan zakelijke relaties schaden. Een onjuist goedgekeurd budget kan financiële verliezen veroorzaken. Een foutieve databaseverwijdering kan leiden tot dataverlies dat uren of dagen kost om te herstellen.
Naast de directe operationele risico’s zijn er ook nalevings- en regelgevingsaspecten. Veel sectoren stellen strikte eisen dat bepaalde besluiten menselijke beoordeling en goedkeuring vereisen. Financiële instellingen moeten menselijk toezicht houden op transacties boven bepaalde drempels. Zorgsystemen vereisen menselijke beoordeling van bepaalde geautomatiseerde beslissingen. Advocatenkantoren moeten ervoor zorgen dat communicatie wordt gecontroleerd voordat deze namens cliënten wordt verzonden. Deze vereisten zijn niet alleen bureaucratische ballast—ze bestaan omdat de gevolgen van volledig autonome besluitvorming in deze domeinen ernstig kunnen zijn. Bovendien biedt menselijk toezicht een feedbackmechanisme waarmee de agent in de loop der tijd verbetert. Wanneer een mens een voorgestelde actie van een agent beoordeelt en goedkeurt of aanpast, kan deze feedback worden gebruikt om de prompts van de agent te verfijnen, de toolselectielogica aan te passen of het onderliggende model bij te trainen. Dit zorgt voor een positieve spiraal waarin de agent betrouwbaarder en beter afgestemd raakt op de specifieke behoeften en risicotolerantie van de organisatie.
Wat is Human-in-the-loop Middleware?
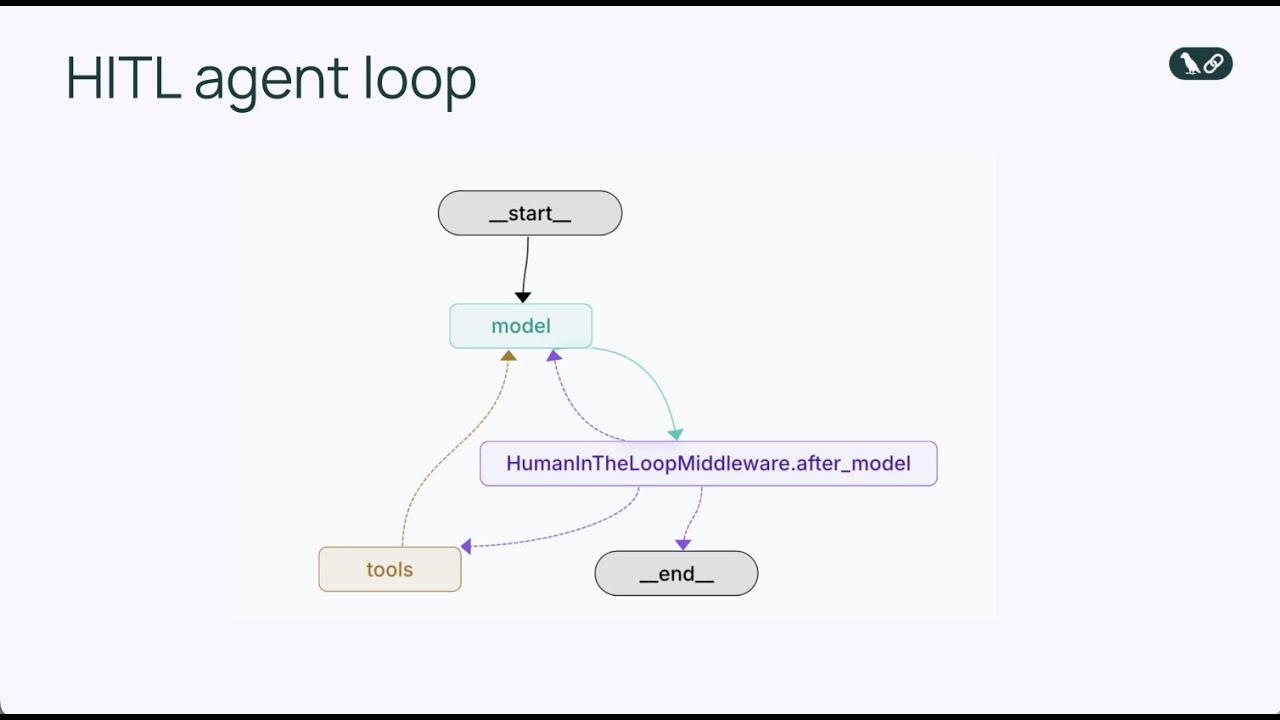
Human-in-the-loop middleware is een gespecialiseerd component dat de agentloop op een cruciaal moment onderschept: vlak voordat een tool wordt uitgevoerd. In plaats van de agent direct een toolaanroep te laten uitvoeren, pauzeert de middleware de uitvoering en presenteert de voorgestelde actie aan een mens voor beoordeling. De mens heeft vervolgens verschillende opties om te reageren. Ze kunnen de actie goedkeuren, waardoor deze exact zoals voorgesteld doorgaat. Ze kunnen de actie bewerken, bijvoorbeeld door parameters aan te passen (zoals het wijzigen van de e-mailontvanger of de inhoud van het bericht) voordat deze wordt uitgevoerd. Of ze kunnen de actie volledig afwijzen en feedback terugsturen naar de agent met uitleg waarom de actie ongepast was en vragen om een alternatieve aanpak. Dit drieledige beslissingsmechanisme—goedkeuren, bewerken, afwijzen—biedt een flexibel kader voor verschillende vormen van menselijk toezicht.
De middleware werkt door de standaard agentloop uit te breiden met een extra beslispunt. In de basisagentloop is de volgorde: model roept tools aan → tools worden uitgevoerd → resultaten terug naar het model. Met human-in-the-loop middleware wordt het: model roept tools aan → middleware onderschept → mens beoordeelt → mens beslist (goedkeuren/bewerken/afwijzen) → bij goedkeuring of bewerking, tool wordt uitgevoerd → resultaten terug naar het model. Deze invoeging van een menselijk beslismoment onderbreekt de agentloop niet, maar verrijkt deze juist met een veiligheidsventiel. De middleware is configureerbaar, zodat je precies kunt aangeven bij welke tools menselijk toezicht vereist is en welke tools automatisch mogen worden uitgevoerd. Je kunt bijvoorbeeld alle e-mailtools laten onderbreken, maar read-only databasequeries automatisch laten uitvoeren. Deze gedetailleerde controle zorgt ervoor dat je toezicht toevoegt waar nodig, zonder onnodige knelpunten bij laag-risico operaties te veroorzaken.
Schrijf u in voor onze nieuwsbrief
Ontvang gratis de nieuwste tips, trends en aanbiedingen.
De Drie Responstypes: Goedkeuren, Bewerken en Afwijzen
Wanneer human-in-the-loop middleware de uitvoering van een tool door een agent onderbreekt, heeft de menselijke beoordelaar drie primaire manieren om te reageren, elk met een eigen rol in de goedkeuringsworkflow. Het begrijpen van deze drie responstypes is essentieel voor het ontwerpen van effectieve human-in-the-loop systemen.
Goedkeuren is het eenvoudigste responstype. Wanneer een mens een voorgestelde toolaanroep beoordeelt en besluit dat deze gepast is en exact zo moet doorgaan, geeft hij of zij een goedkeuringsbeslissing. Dit geeft aan de middleware door dat de tool uitgevoerd moet worden met exact de parameters die de agent heeft opgegeven. In het geval van een e-mailassistent betekent goedkeuren dat het e-mailconcept in orde is en verzonden kan worden naar de gespecificeerde ontvanger met het opgegeven onderwerp en bericht. Goedkeuren is het pad van de minste weerstand—de voorgestelde actie van de agent gaat zonder wijziging door. Dit is gepast als de agent zijn werk goed heeft gedaan en de beoordelaar het ermee eens is. Goedgekeurde beslissingen zijn doorgaans snel te nemen, wat belangrijk is omdat je niet wilt dat menselijke beoordeling een knelpunt wordt in je workflow.
Bewerken is een genuanceerder responstype dat erkent dat de algemene aanpak van de agent correct is, maar dat enkele details moeten worden aangepast voordat uitvoering plaatsvindt. Als een mens een bewerkingsbeslissing geeft, wijst dit niet het besluit tot actie van de agent af, maar wordt de manier waarop deze actie wordt uitgevoerd verfijnd. In een e-mailscenario kan bewerken inhouden dat het e-mailadres van de ontvanger wordt gewijzigd, het onderwerp professioneler wordt gemaakt of de tekst wordt aangepast voor meer context of om potentieel problematische taal te verwijderen. Het kenmerk van een bewerkingsreactie is dat het de parameters van de tool wijzigt, maar de toolaanroep verder hetzelfde blijft. De agent besloot een e-mail te sturen, en de mens is het daar mee eens, maar wil de inhoud of ontvanger aanpassen. Na de doorgevoerde bewerking wordt de tool uitgevoerd met de aangepaste parameters en gaan de resultaten terug naar de agent. Dit is vooral waardevol omdat de agent acties kan voorstellen terwijl mensen deze kunnen verfijnen op basis van hun expertise of kennis van de organisatiecontext die de agent misschien niet heeft.
Afwijzen is het meest ingrijpende responstype omdat het niet alleen de voorgestelde actie stopt, maar ook feedback terugstuurt naar de agent waarin wordt uitgelegd waarom de actie ongepast is. Wanneer een mens een toolaanroep afwijst, geeft hij of zij aan dat de voorgestelde actie niet moet worden uitgevoerd, en geeft hij richting aan hoe de agent het anders moet aanpakken. In het e-mailvoorbeeld kan afwijzen voorkomen als de agent voorstelt een e-mail te sturen waarin een groot budgetverzoek zonder voldoende detail wordt goedgekeurd. De beoordelaar wijst deze actie af en stuurt een bericht terug aan de agent dat meer details nodig zijn voor goedkeuring. Dit afwijsbericht wordt onderdeel van de context van de agent, waarna deze kan redeneren over deze feedback en een alternatieve aanpak kan voorstellen. Zo kan de agent bijvoorbeeld een nieuwe e-mail voorstellen waarin om meer informatie wordt gevraagd over het budgetvoorstel voordat goedkeuring wordt gegeven. Afwijsreacties zijn cruciaal om te voorkomen dat de agent steeds dezelfde ongepaste actie blijft voorstellen. Door duidelijke feedback te geven help je de agent om te leren en zijn besluitvorming te verbeteren.
Human-in-the-loop Middleware Implementeren: Een Praktisch Voorbeeld
Laten we een concrete implementatie van human-in-the-loop middleware doorlopen met LangChain en Python. Het voorbeeld is een e-mailassistent—een praktisch scenario dat het nut van menselijk toezicht laat zien en makkelijk te begrijpen is. De e-mailassistent kan e-mails versturen namens een gebruiker, en we voegen human-in-the-loop middleware toe zodat alle e-mails eerst worden beoordeeld voordat ze worden verstuurd.
Allereerst definiëren we de e-mailtool die onze agent zal gebruiken. Deze tool neemt drie parameters: een e-mailadres van de ontvanger, een onderwerpregel en de e-mailtekst. De tool is eenvoudig—hij stelt het verzenden van een e-mail voor. In een echte implementatie zou deze gekoppeld zijn aan een e-maildienst zoals Gmail of Outlook, maar voor het voorbeeld houden we het simpel. De basisstructuur:
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Stuur een e-mail naar de opgegeven ontvanger."""returnf"E-mail gestuurd naar {recipient} met onderwerp '{subject}'"
Vervolgens maken we een agent die deze e-mailtool gebruikt. We gebruiken GPT-4 als taalmodel en geven een systeemprompt die aangeeft dat de agent een behulpzame e-mailassistent is. De agent wordt geïnitialiseerd met de e-mailtool en is klaar om op gebruikersverzoeken te reageren:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Je bent een behulpzame e-mailassistent voor Sydney. Je mag e-mails versturen namens de gebruiker.")
Op dit punt hebben we een eenvoudige agent die e-mails kan versturen. Maar er is nog geen menselijk toezicht—de agent kan e-mails versturen zonder enige beoordeling. Nu voegen we de human-in-the-loop middleware toe. De implementatie is opvallend eenvoudig en vereist slechts twee regels extra code:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Je bent een behulpzame e-mailassistent voor Sydney. Je mag e-mails versturen namens de gebruiker.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
Door de HumanInTheLoopMiddleware toe te voegen en interrupt_on={"send_email": True} te specificeren, geven we aan dat de agent moet pauzeren vóór elke send_email toolaanroep en moet wachten op menselijke goedkeuring. De waarde True betekent dat alle send_email-aanroepen een interrupt veroorzaken met de standaardconfiguratie. Wil je meer gedetailleerde controle, dan kun je aangeven welke beslissingen zijn toegestaan (goedkeuren, bewerken, afwijzen) of een aangepaste beschrijving voor de interrupt meegeven.
De Middleware Testen met Laag-risico Scenario’s
Als de middleware actief is, testen we deze met een laag-risico e-mailscenario. Stel, een gebruiker vraagt de agent om te reageren op een informele e-mail van collega Alice die voorstelt volgende week koffie te drinken. De agent verwerkt dit verzoek en besluit een vriendelijke e-mail terug te sturen. Zo verloopt het proces:
De gebruiker stuurt: “Reageer op Alice haar e-mail over koffie drinken volgende week.”
Het taalmodel van de agent verwerkt dit en besluit de send_email tool aan te roepen met bijvoorbeeld recipient=“alice@example.com
”, subject=“Koffie volgende week?”, body=“Ik heb zin om volgende week koffie te drinken!”
Voordat de e-mail daadwerkelijk wordt verstuurd, onderschept de middleware de toolaanroep en veroorzaakt een interrupt.
De menselijke beoordelaar bekijkt de voorgestelde e-mail. Deze ziet er goed uit—vriendelijk, professioneel en passend bij het verzoek.
De mens keurt de actie goed.
De middleware laat de tool uitvoeren en de e-mail wordt verstuurd.
Deze workflow laat het basispad van goedkeuring zien. De menselijke beoordeling voegt een veiligheidslaag toe zonder het proces significant te vertragen. Voor laag-risico operaties zoals deze gebeurt goedkeuring doorgaans snel, omdat het voorstel van de agent logisch is en geen aanpassing behoeft.
De Middleware Testen bij Hoog-risico Scenario’s: De Bewerken-Reactie
Nu bekijken we een meer impactvol scenario waarbij bewerken waardevol wordt. Stel, de agent krijgt het verzoek te reageren op een e-mail van een startup-partner die vraagt om een handtekening onder een ingenieursbudget van 1 miljoen dollar voor Q1. Dit is een besluit met grote impact dat zorgvuldige afweging vereist. De agent kan bijvoorbeeld voorstellen: “Ik heb het voorstel voor het ingenieursbudget van $1 miljoen voor Q1 goedgekeurd.”
Wanneer deze voorgestelde e-mail via de middleware bij de menselijke beoordelaar komt, realiseert deze zich dat dit een grote financiële toezegging is die niet zonder meer goedgekeurd moet worden. De beoordelaar wil niet het hele idee van antwoorden op de e-mail afwijzen, maar wil de reactie voorzichtiger maken. De mens geeft een bewerkingsreactie en past de tekst aan naar bijvoorbeeld: “Bedankt voor het voorstel. Ik wil de details graag eerst zorgvuldig bekijken voordat ik goedkeuring geef. Kun je een overzicht sturen van de budgetverdeling?”
Een bewerkingsreactie in code:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Q1 Ingenieursbudget Voorstel",
"body": "Bedankt voor het voorstel. Ik wil de details graag eerst zorgvuldig bekijken voordat ik goedkeuring geef. Kun je een overzicht sturen van de verdeling van het budget?" }
}
}
Wanneer de middleware deze bewerkingsbeslissing ontvangt, voert ze de tool uit met de aangepaste parameters. De e-mail wordt verzonden met de door de mens aangepaste inhoud, wat geschikter is voor een financieel besluit met grote impact. Dit toont de kracht van de bewerken-reactie: het stelt mensen in staat de voorstellen van de agent te benutten, maar het eindresultaat aan te passen aan hun oordeel en de normen van de organisatie.
De Middleware Testen met Afwijzing en Feedback
Het afwijzen-responstype is bijzonder krachtig omdat het niet alleen een ongepaste actie stopt, maar ook feedback geeft waardoor de agent zijn redenering kan verbeteren. Stel, weer hetzelfde budgetscenario. De agent stelt een e-mail voor: “Ik heb het ingenieursbudget van $1 miljoen voor Q1 goedgekeurd.”
De beoordelaar ziet dit en beseft dat dit veel te snel is. Een toezegging van $1 miljoen vereist grondige beoordeling, overleg met stakeholders en inzicht in de details. De beoordelaar wil niet alleen de e-mail aanpassen, maar deze hele aanpak afwijzen en de agent vragen het opnieuw te proberen. De mens geeft een afwijsreactie met feedback:
reject_decision = {
"type": "reject",
"message": "Ik kan dit budget niet goedkeuren zonder meer informatie. Stel een e-mail op waarin je vraagt om een gedetailleerd overzicht van het voorstel, inclusief de verdeling van de middelen over de verschillende teams en welke concrete resultaten verwacht worden."}
Wanneer de middleware deze afwijzing ontvangt, voert ze de tool niet uit. In plaats daarvan stuurt ze de afwijsboodschap terug naar de agent als onderdeel van de gesprekscontext. De agent ziet nu dat zijn voorstel is afgewezen en begrijpt waarom. Vervolgens kan de agent redeneren over deze feedback en een andere aanpak voorstellen. Hier kan de agent bijvoorbeeld een nieuwe e-mail voorstellen waarin om meer details wordt gevraagd over het budgetvoorstel, wat een passendere reactie is op een financiële aanvraag met grote impact. De mens kan dit nieuwe voorstel beoordelen en opnieuw goedkeuren, bewerken of afwijzen.
Dit iteratieve proces—voorstellen, beoordelen, afwijzen met feedback, opnieuw voorstellen—is een van de meest waardevolle aspecten van human-in-the-loop middleware. Het creëert een samenwerking waarin de snelheid en redenering van de agent worden gecombineerd met menselijk oordeel en domeinexpertise.
Versnel Je Workflow met FlowHunt
Ervaar hoe FlowHunt je AI content- en SEO-workflows automatiseert—van onderzoek en contentgeneratie tot publicatie en analyse—alles op één plek.
Geavanceerde Configuratie: Gedetailleerde Controle over Interrupts
Hoewel de basisimplementatie van human-in-the-loop middleware eenvoudig is, biedt LangChain meer geavanceerde configuratieopties waarmee je precies kunt bepalen hoe en wanneer interrupts plaatsvinden. Een belangrijke optie is het specificeren welke beslissingen per tool zijn toegestaan. Zo kun je bijvoorbeeld goedkeuren en bewerken toestaan voor e-mails, maar geen afwijzen. Of alle drie de typen beslissingen voor financiële transacties, maar alleen goedkeuren voor read-only databasequeries.
Voorbeeld van gedetailleerdere configuratie:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Automatisch goedkeuren, geen interrupt"delete_record": {
"allowed_decisions": ["approve", "reject"] # Niet bewerken bij verwijderen }
}
)
]
)
In deze configuratie worden e-mails onderbroken en zijn alle drie de beslissingsopties toegestaan. Leesoperaties worden automatisch uitgevoerd zonder onderbreking. Verwijderoperaties worden onderbroken, maar kunnen alleen goedgekeurd of afgewezen worden—niet bewerkt. Deze gedetailleerde controle zorgt ervoor dat je menselijk toezicht toevoegt waar nodig, zonder onnodige knelpunten bij laag-risico taken.
Een andere geavanceerde functie is het kunnen geven van aangepaste beschrijvingen voor interrupts. Standaard geeft de middleware een algemene melding zoals “Tooluitvoering vereist goedkeuring.” Je kunt dit aanpassen voor meer context:
Belangrijke Implementatieaspecten: Checkpointers en Statusbeheer
Een cruciaal, maar vaak over het hoofd gezien aspect van het implementeren van human-in-the-loop middleware is de noodzaak van een checkpointer. Een checkpointer is een mechanisme dat de status van de agent opslaat op het moment van onderbreking, zodat het workflow later hervat kan worden. Dit is essentieel omdat menselijke beoordeling niet direct gebeurt—er kan tijd zitten tussen het ontstaan van de interrupt en de beslissing van de mens. Zonder checkpointer zou de status van de agent tijdens deze vertraging verloren gaan, en kun je het workflow niet goed hervatten.
LangChain biedt diverse checkpointer-opties. Voor ontwikkeling en testen kun je een in-memory checkpointer gebruiken:
Voor productiesystemen wil je doorgaans een persistente checkpointer die de status opslaat in een database of bestandssysteem, zodat interrupts hervat kunnen worden, zelfs als de applicatie opnieuw wordt opgestart. De checkpointer houdt een compleet overzicht bij van de agentstatus op elk moment, inclusief de gespreksgeschiedenis, alle toolaanroepen en hun resultaten. Wanneer een mens beslist (goedkeuren, bewerken of afwijzen), gebruikt de middleware de checkpointer om de opgeslagen status op te halen, de beslissing toe te passen en de agentloop vanaf dat punt te hervatten.
Toepassingen en Gebruiksscenario’s in de Praktijk
Human-in-the-loop middleware is toepasbaar in allerlei praktijkgevallen waarbij autonome agents acties moeten uitvoeren die menselijk toezicht vereisen. In de financiële sector kunnen agents die transacties verwerken, leningen goedkeuren of investeringen beheren, middleware gebruiken om te zorgen dat belangrijke besluiten worden beoordeeld door gekwalificeerde mensen. In de zorg kunnen agents die behandelingen aanbevelen of patiëntgegevens raadplegen middleware gebruiken om te voldoen aan privacyregels en klinische protocollen. In de juridische sector kunnen agents die communicatie opstellen of vertrouwelijke documenten raadplegen middleware inzetten om toezicht van advocaten te waarborgen. In de klantenservice kunnen agents die restituties uitgeven, toezeggingen doen of issues escaleren middleware gebruiken om te zorgen dat deze acties passen binnen het bedrijfsbeleid.
Ook buiten deze sectoren is human-in-the-loop middleware waardevol in elke situatie waarin de gevolgen van een foute agentactie groot zijn. Denk aan contentmoderatie-systemen waar agents gebruikerscontent verwijderen, HR-systemen waar agents personeelsbesluiten nemen of supply chain-systemen waar agents bestellingen plaatsen of voorraad aanpassen. De rode draad: de voorgestelde acties van de agent hebben echte gevolgen, en die gevolgen zijn belangrijk genoeg om menselijke beoordeling vooraf te vereisen.
Vergelijking met Alternatieven
Het is de moeite waard te overwegen hoe human-in-the-loop middleware zich verhoudt tot alternatieve benaderingen voor menselijk toezicht in agentsystemen. Een alternatief is om mensen alle agentuitvoer achteraf te laten beoordelen, maar dan is de actie al uitgevoerd en terugdraaien vaak lastig of onmogelijk. Een e-mail is al verstuurd, een record is al verwijderd, of een transactie is al verwerkt. Human-in-the-loop middleware voorkomt deze onomkeerbare acties vooraf.
Een ander alternatief is om mensen handmatig alle taken te laten uitvoeren die agents ook zouden kunnen doen, maar daarmee gaat het voordeel van agents verloren. Agents zijn juist waardevol omdat ze routinetaken snel en efficiënt afhandelen, zodat mensen zich kunnen richten op belangrijker werk. Het doel van human-in-the-loop middleware is de juiste balans: agents doen het routinewerk, maar pauzeren bij hoge inzet voor menselijke beoordeling.
Een derde alternatief is guardrails of validatieregels die agents beperken in ongepaste acties. Bijvoorbeeld een regel die voorkomt dat een agent e-mails buiten de organisatie verstuurt, of records verwijdert zonder expliciete bevestiging. Guardrails zijn nuttig en moeten samen met human-in-the-loop worden ingezet, maar zijn vaak regelgebaseerd en kunnen niet elk ongepast scenario afdekken. Menselijk oordeel is flexibeler en contextgevoeliger dan regels, en daarom is human-in-the-loop middleware zo waardevol.
Best Practices voor Human-in-the-loop Workflows
Bij het implementeren van human-in-the-loop middleware kunnen enkele best practices helpen om je systeem effectief en efficiënt te maken. Ten eerste: wees strategisch in welke tools interrupts vereisen. Als je bij elke tool onderbreekt, krijg je knelpunten en wordt je workflow traag. Focus op tools die duur, risicovol of gevolg-gevoelig zijn. Leesoperaties hoeven meestal niet onderbroken te worden; schrijfoperaties of externe acties meestal wel.
Ten tweede: geef duidelijke context aan beoordelaars. Bij een interrupt moet de mens begrijpen wat de agent voorstelt en waarom. Maak de interruptbeschrijvingen helder en contextvol. Laat bij e-mails de volledige inhoud zien, bij verwijderingen welke data verwijderd worden en waarom. Hoe meer context, hoe sneller en beter de beslissing.
Ten derde: maak het goedkeuringsproces zo frictieloos mogelijk. Mensen keuren sneller goed als het proces simpel is en weinig handelingen vraagt. Voorzie duidelijke knoppen of opties voor goedkeuren, bewerken en afwijzen. Als bewerken mogelijk is, maak het eenvoudig om relevante parameters te wijzigen zonder technische details.
Ten vierde: gebruik afwijsfeedback strategisch. Geef bij afwijzing duidelijke feedback waarom de actie ongepast was en wat de agent in plaats daarvan moet doen. Zo leert de agent en verbetert zijn besluitvorming. Na verloop van tijd wordt de agent steeds beter afgestemd op de normen en risicotolerantie van jouw organisatie.
Ten vijfde: monitor en analyseer interruptpatronen. Houd bij welke tools het meest worden onderbroken, welke beslissingen het vaakst voorkomen, en hoe lang het goedkeuringsproces duurt. Met deze data kun je knelpunten identificeren, je configuratie verfijnen en mogelijk de prompts of toolselectielogica van de agent verbeteren.
Human-in-the-loop Middleware Integreren met FlowHunt
Voor organisaties die human-in-the-loop workflows op schaal willen implementeren, biedt FlowHunt een compleet platform dat naadloos integreert met de middleware van LangChain. FlowHunt maakt het eenvoudig om AI agents te bouwen, uit te rollen en te beheren met ingebouwde goedkeuringsworkflows, zodat je menselijk toezicht toevoegt aan je automatiseringsprocessen. Je configureert eenvoudig welke tools menselijke goedkeuring vereisen, past de goedkeuringsinterface aan je wensen aan en houdt alle goedkeuringen en afwijzingen bij voor compliance en audits. Het platform regelt het complexe statusbeheer, checkpointing en workflow-orkestratie, zodat jij je kunt richten op effectieve agents en goedkeuringsbeleid. Dankzij de integratie met LangChain benut je de kracht van human-in-the-loop middleware met een gebruiksvriendelijke interface en enterprise-kwaliteit betrouwbaarheid.
Conclusie
Human-in-the-loop middleware vormt een essentiële brug tussen de efficiëntie van autonome AI agents en de noodzaak van menselijk toezicht in productiesystemen. Door goedkeuringsworkflows, bewerkingsmogelijkheden en afwijsfeedback te implementeren, bouw je agents die krachtig én veilig zijn. Het drieledige beslismodel—goedkeuren, bewerken, afwijzen—biedt flexibiliteit voor verschillende soorten toezicht, van laag-risico operaties tot hoog-risico besluiten die zorgvuldige beoordeling vereisen. De implementatie is eenvoudig en vraagt slechts enkele regels code toe te voegen aan je bestaande LangChain agents, terwijl het effect op betrouwbaarheid en veiligheid groot is. Naarmate AI agents steeds capabeler worden en in kritieke bedrijfsprocessen terechtkomen, wordt human-in-the-loop middleware een onmisbaar onderdeel van verantwoordelijke AI-toepassing. Of je nu e-mailassistenten, financiële systemen, zorgapplicaties of andere toepassingen bouwt waar agentacties echte gevolgen hebben, human-in-the-loop middleware biedt het kader om menselijk oordeel centraal te houden in je automatiseringsworkflows.
Veelgestelde vragen
Human-in-the-loop middleware is een component die de uitvoering van een AI agent pauzeert vóór het uitvoeren van specifieke tools, zodat mensen de voorgestelde actie kunnen goedkeuren, bewerken of afwijzen. Dit voegt een veiligheidslaag toe voor dure of risicovolle operaties.
Gebruik het voor operaties met hoge inzet, zoals het versturen van e-mails, financiële transacties, database-schrijfacties of elke tooluitvoering die naleving vereist of grote gevolgen kan hebben als het verkeerd wordt uitgevoerd.
De drie hoofdresponstypes zijn: Goedkeuren (voer de tool uit zoals voorgesteld), Bewerken (pas de toolparameters vóór uitvoering aan) en Afwijzen (weiger uitvoering en stuur feedback naar het model voor herziening).
Importeer HumanInTheLoopMiddleware uit langchain.agents.middleware, configureer deze met de tools waarop je wilt onderbreken, en geef hem mee aan je agent aanmaakfunctie. Je hebt ook een checkpointer nodig om de status over onderbrekingen heen te bewaren.
Arshia is een AI Workflow Engineer bij FlowHunt. Met een achtergrond in computerwetenschappen en een passie voor AI, specialiseert zij zich in het creëren van efficiënte workflows die AI-tools integreren in dagelijkse taken, waardoor productiviteit en creativiteit worden verhoogd.
Arshia Kahani
AI Workflow Engineer
Automatiseer Je AI Workflows Veilig met FlowHunt
Bouw intelligente agents met ingebouwde goedkeuringsworkflows en menselijk toezicht. Met FlowHunt implementeer je eenvoudig human-in-the-loop automatisering voor je bedrijfsprocessen.
Extensible AI-agenten bouwen: Een diepgaande blik op middleware-architectuur
Ontdek hoe de middleware-architectuur van LangChain 1.0 een revolutie teweegbrengt in agentontwikkeling, waardoor ontwikkelaars krachtige, uitbreidbare deep age...
Human-in-the-Loop (HITL) is een AI- en machine learning-benadering die menselijke expertise integreert in het trainen, afstemmen en toepassen van AI-systemen, w...
Het begrijpen van Human in the Loop voor chatbots: AI verbeteren met menselijke expertise
Ontdek het belang en de toepassingen van Human in the Loop (HITL) in AI-chatbots, waarbij menselijke expertise AI-systemen verbetert voor meer nauwkeurigheid, e...
7 min lezen
AI
Chatbots
+5
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.