
Hugging Face Transformers
Hugging Face Transformers is een toonaangevende open-source Python-bibliotheek die het eenvoudig maakt om Transformer-modellen te implementeren voor machine lea...
4 min lezen
AI
Machine Learning
+4
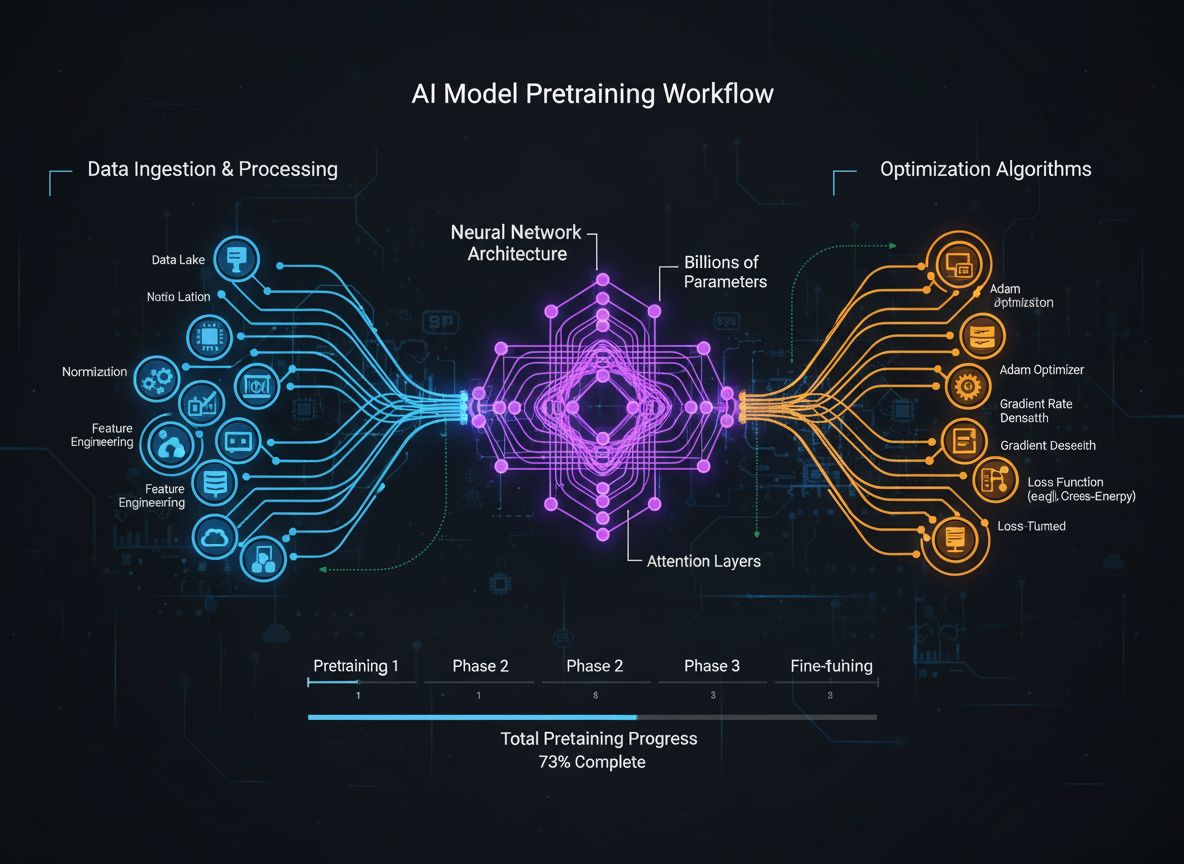
Een uitgebreide gids over moderne strategieën voor pretraining van taalmodellen, technieken voor datacuratie en optimalisatiemethoden die HuggingFace gebruikt om efficiënte, hoogwaardige open-source modellen te bouwen.
Het landschap van de ontwikkeling van taalmodellen is de afgelopen jaren fundamenteel veranderd. Terwijl grote technologiebedrijven blijven inzetten op schaalvergroting, heeft de open-source gemeenschap ontdekt dat uitzonderlijke prestaties niet afhankelijk zijn van modellen met biljoenen parameters. Deze uitgebreide gids verkent de meest geavanceerde technieken en strategieën die door HuggingFace-onderzoekers worden gebruikt om efficiënte, krachtige taalmodellen te bouwen via rigoureuze pretraining-methodologieën. We bekijken hoe SmolLM 3, FineWeb en FinePDF een nieuw paradigma vertegenwoordigen in modelontwikkeling—gericht op maximale prestaties binnen praktische computationale beperkingen, met behoud van wetenschappelijke nauwkeurigheid en reproduceerbaarheid. De inzichten die hier gedeeld worden zijn het resultaat van maandenlang onderzoek en experimentatie en bieden een masterclass in het benaderen van modelpretraining in het moderne tijdperk.

Pretraining van taalmodellen is geëvolueerd van een relatief eenvoudig proces—het voeden van ruwe tekstdata aan neurale netwerken—naar een verfijnde discipline met meerdere onderling verbonden optimalisatiedoelen. In de kern houdt pretraining in dat een model wordt blootgesteld aan enorme hoeveelheden tekstdata, zodat het statistische patronen in taal leert via zelf-lerend leren. De moderne benadering erkent echter dat het simpelweg vergroten van data en rekenkracht niet voldoende is. Onderzoekers moeten verschillende dimensies van het trainingsproces zorgvuldig orkestreren—van data selectie en curatie tot architecturale keuzes en optimalisatie-algoritmen. Het veld is dusdanig volwassen geworden dat begrip van deze nuances het verschil maakt tussen state-of-the-art modellen en middelmatige varianten. Deze evolutie weerspiegelt een dieper inzicht: modelprestaties worden bepaald door de zorgvuldige afstemming van meerdere, deels orthogonale doelen die parallel geoptimaliseerd kunnen worden. De onderzoeksgemeenschap erkent steeds meer dat het ‘geheime ingrediënt’ van succesvolle modelontwikkeling niet brute schaalvergroting is, maar intelligente ontwerpkeuzes in elke laag van de trainingspijplijn.
Start vandaag uw gratis proefperiode en zie binnen enkele dagen resultaten.
Een van de belangrijkste lessen uit recent onderzoek is dat de kwaliteit en diversiteit van trainingsdata de modelprestaties fundamenteler bepalen dan de hoeveelheid data. Dit principe—vaak samengevat als ‘garbage in, garbage out’—wordt steeds meer bevestigd door empirisch onderzoek en praktijkervaring. Modellen die getraind zijn op slecht geselecteerde, gedupliceerde of lage kwaliteit data leren onbetrouwbare patronen en generaliseren slecht naar nieuwe taken. Daarentegen maken zorgvuldig geselecteerde, gededupliceerde en gefilterde datasets het mogelijk om efficiënter te leren en betere prestaties te behalen met minder trainingsstappen. De gevolgen van dit inzicht zijn diepgaand: organisaties en onderzoekers zouden moeten investeren in datacuratie en kwaliteitscontrole, in plaats van simpelweg meer ruwe data te verzamelen. Deze verschuiving heeft geleid tot het ontstaan van gespecialiseerde teams en tools die zich volledig richten op datasetcreatie en -verbetering. De FineWeb dataset, met meer dan 18,5 biljoen tokens aan opgeschoonde en gededupliceerde Engelse webdata, is hiervan een goed voorbeeld. In plaats van ruwe CommonCrawl-data te gebruiken, heeft het FineWeb-team geavanceerde filtering, deduplicatie en kwaliteitsbeoordeling toegepast om een dataset te creëren die systematisch beter presteert dan grotere, ongefilterde alternatieven. Dit besef vormt een fundamentele omwenteling in het veld: de weg naar betere modellen loopt via betere data, niet noodzakelijk via méér data.
Moderne modelpretraining kan worden begrepen aan de hand van vijf onderling samenhangende maar deels orthogonale doelen die onderzoekers gelijktijdig moeten optimaliseren. Inzicht in deze pijlers biedt een kader voor het overzien van het hele trainingsproces en het identificeren van verbeterpunten. De eerste pijler draait om het maximaliseren van de relevantie en kwaliteit van de ruwe informatie in de trainingsdata. Dit betreft zowel de kwaliteit van individuele datapunten als de diversiteit van de dataset als geheel. Een model dat getraind is op kwalitatief hoogwaardige, diverse data zal algemenere patronen leren dan een model dat getraind is op smalle of lage kwaliteit data, ongeacht andere optimalisaties. De tweede pijler richt zich op het ontwerp van de modelarchitectuur, wat bepaalt hoe efficiënt een model informatie verwerkt en welke computationale beperkingen gelden. Architectuurkeuzes beïnvloeden inferentiesnelheid, geheugengebruik, KV-cachebehoefte en de mogelijkheid om op specifieke hardware te draaien. De derde pijler is het maximaliseren van de informatie die bij elke stap uit de trainingsdata wordt gehaald. Hieronder vallen technieken als knowledge distillation, waarbij kleinere modellen leren van grotere modellen, en multi-token prediction, waarbij modellen meerdere toekomstige tokens tegelijk voorspellen. De vierde pijler betreft gradiëntkwaliteit en optimalisatiedynamiek, waaronder de keuze voor optimizer, learning rate schedules en technieken voor stabiele training. De vijfde pijler omvat hyperparameterafstemming en schaalstrategieën om te zorgen dat training stabiel blijft naarmate modellen groter worden en om problemen als gradiëntenexplosie of activatiedivergentie te voorkomen. Deze vijf pijlers zijn niet onafhankelijk—ze beïnvloeden elkaar op complexe wijze—maar afzonderlijk nadenken over deze aspecten helpt onderzoekers te bepalen waar de meeste winst te behalen valt.
Ontvang gratis de nieuwste tips, trends en aanbiedingen.
FineWeb vormt een mijlpaal in datasetcreatie voor pretraining van taalmodellen. In plaats van de ruwe output van webcrawlers zoals CommonCrawl te accepteren, heeft het HuggingFace-team een uitgebreide pijplijn geïmplementeerd voor het opschonen, filteren en dedupliceren van webdata op enorme schaal. De resulterende dataset bevat meer dan 18,5 biljoen tokens aan hoogwaardige Engelse tekst, waarmee het een van de grootste gecureerde datasets is die beschikbaar is voor de open-source gemeenschap. Het creëren van FineWeb bestond uit meerdere verwerkingsstappen, elk bedoeld om lage kwaliteit content te verwijderen en waardevolle informatie te behouden. Het team implementeerde geavanceerde deduplicatie-algoritmes, kwaliteitsfilters om spam en lage kwaliteit pagina’s te verwijderen, en taaldetectie om ervoor te zorgen dat de dataset voornamelijk uit Engelse tekst bestaat. Wat FineWeb vooral waardevol maakt is niet alleen de omvang, maar ook de empirische onderbouwing dat het betere modelprestaties oplevert dan grotere, ongefilterde alternatieven. In combinatie met andere datasets presteert FineWeb systematisch beter dan veel grotere ruwe datasets, wat aantoont dat kwaliteit echt belangrijker is dan kwantiteit. Prestatielijnen tonen aan dat modellen getraind op FineWeb betere resultaten halen op standaard benchmarks dan modellen getraind op datasets van vergelijkbare omvang uit andere bronnen. Dit succes heeft de bredere onderzoeksgemeenschap geïnspireerd om meer te investeren in datacuratie, met het besef dat daar aanzienlijke prestatieverbeteringen te behalen zijn. De FineWeb-dataset is vrij beschikbaar voor onderzoekers, waardoor toegang tot hoogwaardige trainingsdata wordt gedemocratiseerd en kleinere organisaties en academische teams competitieve modellen kunnen trainen.
Terwijl FineWeb zich richtte op webdata, realiseerde het HuggingFace-team zich dat een andere enorme bron van kwalitatieve tekst grotendeels was genegeerd: PDF-documenten. PDF’s bevatten grote hoeveelheden gestructureerde, kwalitatieve informatie, waaronder wetenschappelijke artikelen, technische documentatie, boeken en professionele rapporten. Het extraheren van tekst uit PDF’s is echter technisch uitdagend, en eerdere benaderingen hadden deze bron niet systematisch op schaal benut. FinePDF is de eerste uitgebreide poging om PDF-data te extraheren, opschonen en cureren voor pretraining van taalmodellen. Het team heeft een geavanceerde pijplijn gebouwd die de unieke uitdagingen van PDF-verwerking aanpakt, zoals het omgaan met complexe lay-outs, het correct extraheren van tekst uit documenten met meerdere kolommen, en het verwerken van ingesloten afbeeldingen en tabellen. Een bijzonder innovatieve stap in de FinePDF-pijplijn is het “opnieuw ophalen van internet”, waarmee een kritisch probleem wordt aangepakt: PDF’s opgeslagen in CommonCrawl zijn vaak slecht geëxtraheerd of verouderd. Door PDF’s opnieuw van hun oorspronkelijke bron op internet te halen, verzekert het team zich van de hoogste kwaliteit versies van documenten. De prestaties zijn indrukwekkend—in combinatie met andere datasets laat FinePDF zeer sterke resultaten zien ten opzichte van recente baselines zoals NeoTron B2. De dataset biedt een nieuwe bron van hoogwaardige trainingsdata die webdata aanvult en modellen in staat stelt te leren van meer diverse, gestructureerde informatie. Dit werk opent nieuwe perspectieven voor datasetcreatie en suggereert dat andere, onderbenutte databronnen vergelijkbare voordelen kunnen opleveren. De FinePDF-pijplijn wordt in detail gedocumenteerd via blogposts en technische documentatie, zodat andere onderzoekers hierop kunnen voortbouwen en soortgelijke technieken kunnen toepassen op andere databronnen.
SmolLM 3 is het resultaat van het toepassen van deze datacuratie en trainingsoptimalisatietechnieken om een zeer efficiënt taalmodel te creëren. Met 3 miljard parameters is SmolLM 3 aanzienlijk kleiner dan veel hedendaagse modellen, maar door zorgvuldige optimalisatie over alle vijf pijlers van modeltraining presteert het toch competitief. Het model ondersteunt duale redeneerstand, meertaligheid over zes talen en begrijpt lange contexten, wat het opvallend veelzijdig maakt ondanks het bescheiden formaat. De ontwikkeling van SmolLM 3 omvatte zorgvuldige architecturale keuzes om efficiëntie te maximaliseren. Het team koos voor een transformer-architectuur die rekenkracht en modelcapaciteit in balans brengt, met technieken als grouped query attention om geheugengebruik en inferentietijd te verminderen. Het model werd getraind met een driestaps pretraining-aanpak die prestaties over verschillende domeinen geleidelijk verbetert, zodat per fase gericht geoptimaliseerd kon worden. Wat SmolLM 3 bijzonder maakt, is dat het aantoont dat de open-source gemeenschap nu modellen kan bouwen die op veel taken rivaliseren met veel grotere, propriëtaire modellen. Dit daagt de aanname uit dat groter altijd beter is, en suggereert dat het veld een plateau nadert wat betreft de voordelen van pure schaalvergroting. De focus verschuift nu naar efficiëntie, verklaarbaarheid en praktische inzetbaarheid. SmolLM 3 kan draaien op consumentenhardware, edge devices en omgevingen met beperkte middelen, waardoor geavanceerde AI-capaciteiten beschikbaar komen voor een veel breder publiek. De meertalige en lang-context mogelijkheden laten zien dat efficiëntie niet ten koste hoeft te gaan van belangrijke functies.
Knowledge distillation is een krachtige techniek waarmee kleinere modellen kunnen profiteren van de kennis die geleerd is door grotere modellen. In plaats van een klein model vanaf nul te trainen op ruwe data, wordt het kleine model getraind om de outputs van een groter, capabeler model na te bootsen. Deze aanpak is vooral waardevol tijdens pretraining, omdat het kleinere model zo patronen kan leren die het grote model al heeft ontdekt, wat het leerproces versnelt en de uiteindelijke prestaties verbetert. Bij knowledge distillation wordt het studentmodel (de kleinere variant) getraind om de waarschijnlijkheidsverdelingen van het teachermodel (de grotere variant) te benaderen. Dit gebeurt meestal door de divergentie tussen de outputverdelingen van student en teacher te minimaliseren, vaak met technieken zoals KL-divergentie. De temperatuurparameter bepaalt hoe “zacht” de waarschijnlijkheidsverdelingen zijn—hogere temperaturen maken de verdelingen vloeiender en geven meer informatie over de relatieve zekerheid van verschillende voorspellingen. Knowledge distillation is bijzonder effectief gebleken bij pretraining van taalmodellen, omdat hiermee de kennis van grote modellen kan worden overgedragen op kleinere, efficiëntere modellen. Dit is vooral waardevol voor organisaties die modellen willen inzetten op edge devices of in beperkte omgevingen, maar toch gebruik willen maken van de mogelijkheden van grotere modellen. De techniek is steeds geavanceerder geworden, met onderzoek naar methoden als attention transfer, waarbij het studentmodel ook de aandachtspatronen van het teachermodel leert, en feature-based distillation, waarbij representaties van tussenlagen worden overgenomen.
Traditionele training van taalmodellen richt zich op voorspelling van het volgende token—het model leert het volgende token te voorspellen op basis van alle voorgaande tokens. Recente studies laten echter zien dat modellen trainen om meerdere toekomstige tokens tegelijk te voorspellen, de prestaties aanzienlijk kan verbeteren, vooral bij programmeertaken en complexe redeneerproblemen. Multi-token prediction dwingt het model langere afhankelijkheden te leren en een dieper begrip van onderliggende patronen te ontwikkelen. De aanpak houdt in dat meerdere prediction heads aan het model worden toegevoegd, elk verantwoordelijk voor het voorspellen van een token meerdere posities verderop. Tijdens training ontvangt het model verlies-signalen van al deze heads tegelijk, wat het model stimuleert representaties te leren die nuttig zijn voor voorspellingen over meerdere stappen. Dit is uitdagender dan next-token prediction, maar resulteert in betere representaties. De voordelen van multi-token prediction gaan verder dan alleen betere prestaties op de trainingsdoelstelling. Modellen die hiermee getraind zijn, presteren vaak beter op neventaken, generaliseren beter naar nieuwe domeinen en hebben verbeterde redeneercapaciteiten. De techniek is met name effectief voor codegeneratie, waar begrip van lange afhankelijkheden cruciaal is voor het genereren van syntactisch en semantisch correcte code. Onderzoek laat zien dat multi-token prediction de modelprestaties met 5-15% kan verbeteren op verschillende benchmarks, waardoor het een van de meest impactvolle trainingstechnieken van de laatste jaren is. De aanpak is relatief eenvoudig te implementeren, maar vereist zorgvuldige afstemming van het aantal heads en de weging van verliezen van verschillende heads.
Jarenlang was de AdamW optimizer de standaardkeuze voor het trainen van grote taalmodellen. AdamW combineert momentum-gebaseerde updates met weight decay, wat zorgt voor stabiele training en goede convergentie. Recent onderzoek wijst echter uit dat AdamW niet optimaal is voor alle trainingsscenario’s, zeker bij het opschalen naar zeer grote modellen. Nieuwe optimizers zoals Muon en King K2 onderzoeken alternatieve benaderingen die betere trainingsdynamiek en prestaties kunnen bieden. De kerninzicht achter deze nieuwe optimizers is dat de Hessiaan-matrix—die informatie bevat over de kromming van het verlieslandschap—beter benaderd kan worden met technieken zoals Newton-Schulz-methoden. Door een betere benadering van de Hessiaan te onderhouden, kunnen deze optimizers informatiefere gradiëntupdates geven, wat leidt tot snellere convergentie en betere eindresultaten. Muon gebruikt bijvoorbeeld Newton-Schulz-iteratie om de gradiëntmatrix te orthogonaliseren, waardoor het leren over meer dimensies wordt verspreid dan bij traditionele momentum-methodes. Dit resulteert in stabielere training en stimuleert het model om nieuwe regio’s in de parameter-ruimte te verkennen. King K2 pakt het anders aan en houdt onder meer de maximale log per head bij om hiermee adaptief learning rates en gradiëntclipping aan te passen. De gevolgen van innovatie in optimizers zijn groot. Veel gebruikers blijven AdamW gebruiken met hyperparameters die geoptimaliseerd zijn voor veel kleinere modellen, zelfs als ze werken met modellen die vele malen groter zijn. Dit suggereert dat aanzienlijke prestatieverbeteringen te behalen zijn door simpelweg de keuze van optimizer en hyperparameters bij te werken voor moderne, grootschalige modellen. De onderzoeksgemeenschap erkent steeds meer dat de keuze van optimizer nog geen opgelost probleem is en dat verdere innovatie hier aanzienlijke efficiëntie- en prestatiewinst kan opleveren.
Het behouden van hoge kwaliteit gradiënten gedurende de training is essentieel voor goede modelprestaties. Naarmate modellen groeien tot miljarden of zelfs biljoenen parameters, wordt training steeds instabieler, met gradiënten die de neiging hebben te exploderen of te verdwijnen. Het aanpakken van deze problemen vereist aandacht voor gradiëntkwaliteit en het toepassen van technieken die trainingsstabiliteit waarborgen gedurende het hele traject. Een manier om gradiëntkwaliteit te verbeteren is het gebruik van technieken zoals gradiëntclipping, waarmee wordt voorkomen dat gradiënten te groot worden en de training destabiliseren. Echter, naïef gradiëntclipping kan ook waardevolle informatie verliezen. Geavanceerdere benaderingen normaliseren gradiënten op een manier die informatie behoudt maar instabiliteit voorkomt. Een andere belangrijke overweging is de keuze van activatiefuncties en normalisatietechnieken. Verschillende activatiefuncties hebben verschillende eigenschappen wat betreft gradiëntdoorvoer, en zorgvuldige selectie hiervan kan de trainingsstabiliteit sterk beïnvloeden. Layer normalization—het normaliseren van activaties over de feature-dimensie—is standaard geworden in transformer-modellen omdat het betere gradiëntdoorvoer oplevert dan batch normalisatie. Het learning rate schedule speelt ook een cruciale rol in het behouden van gradiëntkwaliteit. Een te hoge learning rate kan gradiënten doen exploderen, terwijl een te lage learning rate leidt tot trage convergentie of vastlopen in lokale minima. Moderne training gebruikt vaak schedules met een warm-up fase, waarbij de learning rate langzaam toeneemt zodat het model in een gunstig gebied van de parameter-ruimte terechtkomt, gevolgd door een afbouwende fase. Inzicht in en optimalisatie van deze aspecten is cruciaal voor succesvolle training van grote modellen, en er wordt nog volop onderzoek naar gedaan.
De complexiteit van moderne modelpretraining—met meerdere optimalisatiedoelen, geavanceerde datapijplijnen en nauwkeurige hyperparameterafstemming—vormt een grote uitdaging voor teams die deze technieken willen toepassen. FlowHunt biedt hiervoor een oplossing door een platform te bieden waarmee complexe modeltraining workflows kunnen worden geautomatiseerd en georkestreerd. In plaats van handmatig dataverwerking, modeltraining en evaluatie te beheren, kunnen teams met FlowHunt workflows definiëren die deze taken automatisch uitvoeren, waardoor fouten worden verminderd en reproduceerbaarheid wordt verbeterd. De automatiseringsmogelijkheden van FlowHunt zijn vooral waardevol bij datacuratie en -verwerking, die zo cruciaal zijn voor de modelprestaties. Het platform kan automatisch geavanceerde datapijplijnen implementeren zoals gebruikt bij FineWeb en FinePDF, inclusief deduplicatie, kwaliteitsfiltering en formaatconversie. Zo kunnen teams zich richten op de belangrijke keuzes over welke data te gebruiken en hoe te verwerken, zonder te verzanden in implementatiedetails. FlowHunt helpt daarnaast bij hyperparameterafstemming en experimentatie die nodig zijn voor optimale modeltraining. Door het proces van meerdere trainingsexperimenten met verschillende hyperparameters uit te voeren en resultaten te verzamelen te automatiseren, kunnen teams de parameter-ruimte efficiënter verkennen en sneller optimale configuraties vinden. Het platform biedt ook tools om de voortgang van training te monitoren, problemen zoals gradiëntenexplosie of divergentie te detecteren en trainingsparameters automatisch aan te passen voor stabiliteit. Voor organisaties die eigen taalmodellen bouwen of bestaande modellen finetunen, kan FlowHunt de benodigde tijd en moeite aanzienlijk verminderen en de kwaliteit van de resultaten verbeteren.
Een van de grootste uitdagingen bij modeltraining is begrijpen hoe je kunt opschalen van kleine naar grote modellen zonder trainingsstabiliteit en prestaties te verliezen. De relatie tussen modelgrootte en optimale hyperparameters is niet eenvoudig—hyperparameters die goed werken voor kleine modellen moeten vaak worden aangepast voor grotere modellen. Dit geldt vooral voor learning rates, die meestal moeten worden verlaagd bij het opschalen. Inzicht in schaalwetten is essentieel om te voorspellen hoe modellen zich op verschillende schaalniveaus gedragen en om beslissingen te nemen over resource-allocatie. Onderzoek toont aan dat modelprestaties voorspelbare schaalwetten volgen, waarbij prestaties toenemen als een machtsfunctie van modelgrootte, datasetgrootte en rekencapaciteit. Deze wetten maken het mogelijk te voorspellen hoeveel prestatieverbetering te verwachten is bij vergroting van model- of datasetgrootte, zodat investeringen beter kunnen worden afgewogen. Schaalwetten zijn echter niet universeel—ze hangen af van de specifieke architectuur, trainingsprocedure en dataset. Teams moeten daarom hun eigen schaalexperimenten uitvoeren om te begrijpen hoe hun setup schaalt. Het opschalen van kleine naar grote modellen vraagt ook om aandacht voor trainingsstabiliteit. Grote modellen zijn gevoeliger voor instabiliteit zoals gradiëntenexplosie of divergentie. Dit vraagt om technieken zoals gradiëntclipping, zorgvuldige learning rate schedules en soms aanpassingen aan de modelarchitectuur of optimizer. De onderzoeksgemeenschap erkent steeds meer dat schalen niet alleen draait om grotere modellen maken, maar om het zorgvuldig beheersen van het trainingsproces zodat grotere modellen effectief getraind kunnen worden.
Feature learning verwijst naar het proces waarbij modellen tijdens training nuttige eigenschappen uit ruwe data leren halen. In de context van pretraining van taalmodellen houdt feature learning in dat het model leert linguïstische concepten, semantische relaties en syntactische patronen te representeren in zijn interne representaties. Het maximaliseren van feature learning—zorgen dat het model zoveel mogelijk nuttige informatie uit de trainingsdata haalt bij iedere stap—is een van de belangrijkste doelen in moderne modeltraining. Een manier om over feature learning na te denken is te kijken hoeveel de representaties van het model veranderen als gevolg van gradiëntupdates. Als het model effectief leert, leiden gradiëntupdates tot betekenisvolle veranderingen die het voorspellingsvermogen verbeteren. Als het model niet effectief leert, zijn de updates beperkt of dragen ze niet bij aan betere prestaties. Technieken om feature learning te verbeteren zijn onder andere zorgvuldige initiatie van modelgewichten, wat sterke invloed heeft op de snelheid waarmee het model in het begin nuttige features leert. Een andere belangrijke techniek is het gebruik van learning rate schedules die snel leren in het begin mogelijk maken als fundamentele features worden geleerd, en vertragen naarmate training vordert en het model subtielere patronen oppikt. Het concept feature learning hangt nauw samen met ‘feature collapse’, waarbij modellen bepaalde features of dimensies negeren. Dit gebeurt als het model een shortcut vindt waarmee het goed presteert zonder alle relevante features te leren. Technieken als regularisatie en zorgvuldige loss-functie-ontwerpen helpen feature collapse te voorkomen en zorgen dat modellen diverse, nuttige features leren.
{{ cta-dark-panel heading=“Versnel Uw Workflow met FlowHunt” description=“Ervaar hoe FlowHunt uw AI content en SEO workflows automatiseert—van research en contentcreatie tot publicatie en analytics—alles op één plek.” ctaPrimaryText=“Plan een Demo” ctaPrimaryURL=“https://calendly.com/liveagentsession/flowhunt-chatbot-demo" ctaSecondaryText=“Probeer FlowHunt Gratis” ctaSecondaryURL=“https://app.flowhunt.io/sign-in" gradientStartColor="#123456” gradientEndColor="#654321” gradientId=“827591b1-ce8c-4110-b064-7cb85a0b1217” }}
Jarenlang overheerste het idee in AI-onderzoek dat grotere modellen betere modellen zijn. Dit leidde tot een wedloop om steeds grotere modellen te bouwen, met bedrijven die modellen met steeds meer parameters aankondigden. Recente ontwikkelingen wijzen er echter op dat dit verhaal verandert. Het succes van SmolLM 3 en andere efficiënte modellen laat zien dat uitzonderlijke prestaties mogelijk zijn met modellen die orders van grootte kleiner zijn dan de grootste modellen. Deze verschuiving weerspiegelt een dieper inzicht dat modelprestaties door meerdere factoren worden bepaald, niet alleen door het aantal parameters. Een model met 3 miljard parameters dat getraind is op hoogwaardige data met geavanceerde optimalisatietechnieken kan beter presteren dan een veel groter model dat getraind is op data van mindere kwaliteit en met minder zorgvuldige optimalisatie. Dit inzicht heeft grote gevolgen voor het veld. Het suggereert dat de meeste vooruitgang niet behaald wordt door grotere modellen te bouwen, maar door data van hogere kwaliteit, betere trainingstechnieken en efficiëntere architecturen. Het democratiseert AI-ontwikkeling, zodat ook kleinere organisaties en academische teams competitieve modellen kunnen bouwen zonder toegang tot de enorme rekenkracht die biljoenen-parameter modellen vereisen. De verschuiving weg van pure schaal heeft ook praktische voordelen voor implementatie. Kleinere modellen kunnen draaien op edge devices, in beperkte omgevingen, en met lagere latency en energieverbruik. Hierdoor worden geavanceerde AI-mogelijkheden beschikbaar voor een veel breder scala aan toepassingen en gebruikers. De onderzoeksgemeenschap erkent dat de toekomst van AI-ontwikkeling waarschijnlijk bestaat uit een portfolio van modellen op verschillende schaalniveaus, elk geoptimaliseerd voor specifieke use cases en scenario’s, in plaats van één focus op het bouwen van de grootste modellen mogelijk.
Hyperparameterafstemming is het kiezen van de waarden van parameters die het trainingsproces sturen, zoals learning rate, batch size en weight decay. Deze parameters hebben grote invloed op de modelprestaties; optimale waarden vinden is cruciaal voor goede resultaten. Hyperparameterafstemming wordt echter vaak als een kunst gezien in plaats van als wetenschap, waarbij men vertrouwt op intuïtie en trial-and-error. Moderne benaderingen zijn systematischer. Technieken als Bayesian optimization kunnen efficiënt de hyperparameter-ruimte verkennen en veelbelovende regio’s identificeren. Grid search en random search zijn eenvoudiger alternatieven die, zeker met parallelle evaluatie, ook effectief kunnen zijn. Een belangrijk inzicht uit recent onderzoek is dat optimale hyperparameters vaak afhangen van het specifieke model, de dataset en de trainingssetup. Dat betekent dat hyperparameters die goed werken voor het ene model, niet per se geschikt zijn voor een ander, zelfs als de modellen vergelijkbaar zijn qua grootte en architectuur. Dit leidt ertoe dat voor elk nieuw model of dataset vaak een aparte hyperparameter sweep nodig is, wat rekenintensief kan zijn maar noodzakelijk voor optimale prestaties. Inzicht in de relatie tussen hyperparameters en prestaties is ook van belang bij het oplossen van trainingsproblemen. Als training instabiel is of langzaam convergeert, kan het probleem liggen bij suboptimale hyperparameters in plaats van bij het model of de data. Door de hyperparameter-ruimte systematisch te verkennen, kunnen deze problemen vaak worden herkend en opgelost.
De inzichten uit modern onderzoek naar modelpretraining hebben grote praktische gevolgen voor organisaties die eigen taalmodellen ontwikkelen of bestaande modellen finetunen. Allereerst zouden organisaties zwaar moeten investeren in datacuratie en kwaliteitscontrole. Het bewijs is duidelijk: hoogwaardige data is waardevoller dan grote hoeveelheden lage kwaliteit data. Dit betekent het implementeren van geavanceerde datapijplijnen met deduplicatie, kwaliteitsfiltering en formaatstandaardisatie. Ten tweede moeten organisaties hun optimalisatiedoelen zorgvuldig bepalen en zorgen dat ze optimaliseren voor de juiste meetwaarden. Verschillende toepassingen vereisen verschillende afwegingen tussen modelgrootte, inferentiesnelheid en nauwkeurigheid. Door deze afwegingen vooraf duidelijk te maken, kunnen organisaties betere beslissingen nemen over architectuurkeuzes en trainingsprocedures. Ten derde is het belangrijk op de hoogte te blijven van de nieuwste trainingstechnieken en optimizer-ontwerpen. Het veld ontwikkelt zich snel, en technieken die vorig jaar state-of-the-art waren, kunnen inmiddels zijn ingehaald. Regelmatig recente papers lezen en nieuwe technieken uitproberen helpt organisaties concurrerend te blijven. Ten vierde is investeren in tools en infrastructuur die het makkelijker maken om geavanceerde trainingsprocedures te implementeren essentieel. Dit kan het gebruik van platforms als FlowHunt omvatten om dataverwerking en training te automatiseren, of het bouwen van eigen infrastructuur voor efficiënte experimentatie en hyperparameterafstemming. Tot slot moeten organisaties beseffen dat modelontwikkeling niet alleen draait om training—het gaat ook om zorgvuldige evaluatie, debugging en iteratie. Goede modellen bouwen vereist een systematische aanpak met regelmatige evaluatie op diverse benchmarks, analyse van faalgevallen en iteratieve verbetering op basis van de geleerde lessen.
Het veld van modelpretraining ontwikkelt zich razendsnel, met regelmatige nieuwe technieken en inzichten. Verschillende trends wijzen op de richting waarin het veld zich beweegt. Ten eerste zal de focus op datakwaliteit en curatie waarschijnlijk verder toenemen. Nu erkend wordt dat kwaliteit belangrijker is dan kwantiteit, verwachten we meer geavanceerde datapijplijnen en meer onderzoek naar wat data geschikt maakt voor modeltraining. Ten tweede zal innovatie in optimizer-ontwerp en trainingsdynamiek doorzetten. Het succes van nieuwe optimizers als Muon en King K2 wijst erop dat er nog veel te winnen valt in optimalisatie. Ten derde komt er meer nadruk op efficiëntie en praktische inzetbaarheid. Nu modellen krachtiger worden, groeit de interesse in het kleiner, sneller en efficiënter maken ervan—denk aan onderzoek naar modelcompressie, kwantisatie en distillatietechnieken. Ten vierde zal er meer onderzoek komen naar het begrijpen en verbeteren van modelverklaarbaarheid. Naarmate modellen krachtiger worden, wordt inzicht in hun werking en beslissingen steeds belangrijker. Tot slot zal de democratisering van modelontwikkeling toenemen, met meer tools en technieken die het voor kleinere organisaties en academische teams mogelijk maken competitieve modellen te bouwen.
De moderne benadering van pretraining van taalmodellen betekent een grote sprong ten opzichte van eerdere, simpelere methoden. In plaats van alleen maar data en rekencapaciteit op te schalen, vereist succesvolle modelontwikkeling nu een zorgvuldige orkestratie van meerdere optimalisatiedoelen, geavanceerde datacuratie en voortdurende innovatie in trainingstechnieken en optimizer-ontwerp. SmolLM 3, FineWeb en FinePDF zijn voorbeelden van dit nieuwe paradigma en tonen aan dat uitzonderlijke modelprestaties mogelijk zijn door strikte focus op datakwaliteit, architecturale efficiëntie en trainingsoptimalisatie. De verschuiving van pure schaal naar efficiëntie en kwaliteit markeert de volwassenwording van het veld en opent nieuwe kansen om AI-ontwikkeling te democratiseren. Organisaties die deze principes begrijpen en toepassen, zullen beter in staat zijn competitieve modellen te bouwen, of ze nu nieuwe modellen ontwikkelen of bestaande finetunen. De onderzoeksgemeenschap blijft de grenzen verleggen, met regelmatige nieuwe technieken en inzichten. Door deze ontwikkelingen te volgen en te investeren in de juiste tools en infrastructuur, kunnen organisaties ervoor zorgen dat hun modellen state-of-the-art blijven.
SmolLM 3 is een model met 3 miljard parameters, ontworpen om maximale efficiëntie te bieden met behoud van sterke prestaties over meerdere talen en taken met lange context. In tegenstelling tot grotere modellen richt SmolLM 3 zich op optimale prestaties binnen computationale beperkingen, waardoor het ideaal is voor inzet op edge devices en omgevingen met beperkte middelen.
Het principe 'garbage in, garbage out' is fundamenteel voor machine learning. Kwalitatieve, diverse data heeft direct meer impact op de modelprestaties dan simpelweg meer data. FineWeb en FinePDF tonen aan dat zorgvuldige selectie, deduplicatie en filtering van trainingsdata aanzienlijk betere resultaten oplevert dan ruwe, ongefilterde datasets.
Knowledge distillation is een techniek waarbij een kleiner model leert van een groter, capabeler model. Tijdens pretraining maakt deze aanpak het mogelijk voor kleinere modellen om maximale informatie uit de trainingsdata te halen door patronen te leren die grotere modellen al hebben ontdekt, wat resulteert in betere prestaties met minder parameters.
Multi-token prediction traint modellen om meerdere toekomstige tokens tegelijk te voorspellen in plaats van alleen de volgende. Deze aanpak is met name effectief voor programmeertaken en verbetert het vermogen van het model om afhankelijkheden op langere termijn te begrijpen, wat leidt tot betere prestaties op complexe redeneertaken.
Moderne optimizers zoals Muon gaan verder dan traditionele AdamW door technieken te gebruiken zoals Newton-Schulz-methoden om de Hessiaan-matrix beter te benaderen. Dit resulteert in stabielere training, betere kwaliteit van gradiënten en verbeterde leerprocessen, vooral bij het opschalen naar modellen met meer parameters.
Arshia is een AI Workflow Engineer bij FlowHunt. Met een achtergrond in computerwetenschappen en een passie voor AI, specialiseert zij zich in het creëren van efficiënte workflows die AI-tools integreren in dagelijkse taken, waardoor productiviteit en creativiteit worden verhoogd.

FlowHunt helpt teams modelpretraining, dataverwerking en optimalisatieprocessen te stroomlijnen met intelligente automatisering.
Hugging Face Transformers is een toonaangevende open-source Python-bibliotheek die het eenvoudig maakt om Transformer-modellen te implementeren voor machine lea...

Ontdek hoe MIT-onderzoekers grote taalmodellen (LLM's) verder ontwikkelen met nieuwe inzichten in menselijke overtuigingen, innovatieve anomaliedetectietools en...

Ontdek hoe Jamba 3B van AI21 transformer-attentie combineert met state space modellen om ongeëvenaarde efficiëntie en lange contextmogelijkheden op edge-apparat...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.