Hoe Test je een AI-Chatbot
Leer alles over uitgebreide AI-chatbot teststrategieën, waaronder functioneel, prestatie-, beveiligings- en gebruikerstesten. Ontdek best practices, tools en fr...
11 min lezen
Ontdek uitgebreide methoden om de nauwkeurigheid van AI-helpdeskchatbots in 2025 te meten. Leer alles over precisie, recall, F1-scores, gebruikersxadtevredenheidsxadmetingen en geavanceerde evaluatiexadtechnieken met FlowHunt.
Meet de nauwkeurigheid van een AI-helpdeskchatbot met meerdere statistieken, waaronder precisie- en recall-berekeningen, verwarringsmatrices, gebruikersxadtevredenheidsscores, oplossingspercentages en geavanceerde LLM-gebaseerde evaluatiexadmethoden. FlowHunt biedt uitgebreide tools voor automatische nauwkeurigheidsxadbeoordeling en prestatiexadmonitoring.
Het meten van de nauwkeurigheid van een AI-helpdeskchatbot is essentieel om te garanderen dat deze betrouwbare en behulpzame antwoorden geeft op klantvragen. In tegenstelling tot eenvoudige classificatietaken omvat de nauwkeurigheid van chatbots meerdere dimensies die samen geëvalueerd moeten worden om een compleet beeld van de prestaties te krijgen. Het proces bestaat uit het analyseren van hoe goed de chatbot gebruikersvragen begrijpt, correcte informatie verschaft, problemen effectief oplost en de tevredenheid van gebruikers gedurende het hele gesprek waarborgt. Een uitgebreide meetstrategie combineert kwantitatieve statistieken met kwalitatieve feedback om sterke punten en verbeterpunten te identificeren.
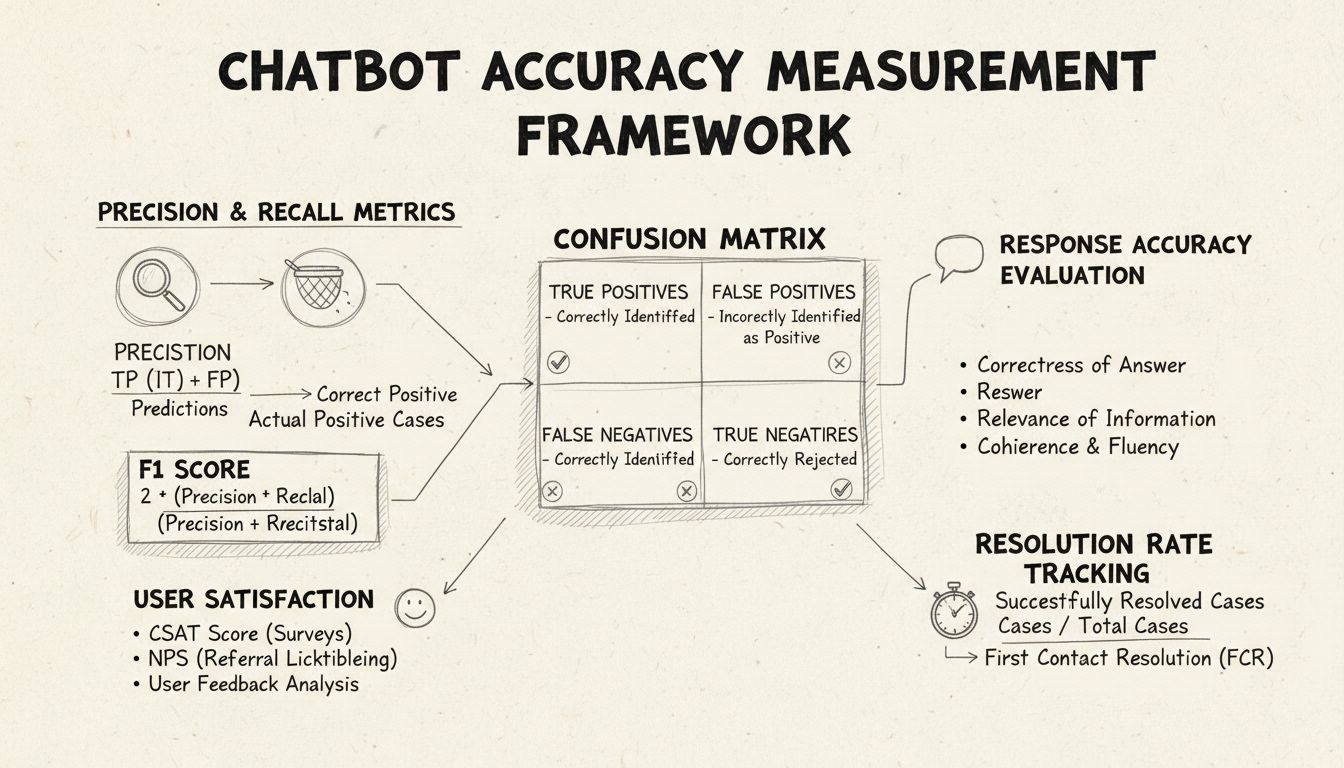
Precisie en recall zijn fundamentele statistieken afkomstig uit de verwarringsmatrix die verschillende aspecten van de prestaties van de chatbot meten. Precisie geeft het aandeel correcte antwoorden weer van alle antwoorden die de chatbot heeft gegeven, berekend met de formule: Precisie = True Positives / (True Positives + False Positives). Deze statistiek beantwoordt de vraag: “Hoe vaak is het antwoord van de chatbot correct?” Een hoge precisie betekent dat de chatbot zelden onjuiste informatie geeft, wat cruciaal is voor het behouden van gebruikersvertrouwen in helpdeskscenario’s.
Recall, ook wel sensitiviteit genoemd, meet het aandeel correcte antwoorden van alle antwoorden die de chatbot eigenlijk had moeten geven, met de formule: Recall = True Positives / (True Positives + False Negatives). Deze statistiek laat zien of de chatbot erin slaagt om alle legitieme klantproblemen te herkennen en beantwoorden. In helpdeskomgevingen zorgt een hoge recall ervoor dat klanten daadwerkelijk geholpen worden en niet te horen krijgen dat de chatbot niet kan helpen, terwijl dat eigenlijk wel mogelijk is. Tussen precisie en recall bestaat een natuurlijke afweging: optimaliseren voor de ene gaat vaak ten koste van de andere, wat een zorgvuldige balans vereist op basis van je zakelijke prioriteiten.
De F1-score biedt één statistiek die zowel precisie als recall in balans brengt, berekend als het harmonisch gemiddelde: F1 = 2 × (Precisie × Recall) / (Precisie + Recall). Deze score is met name waardevol wanneer je één prestatie-indicator nodig hebt of wanneer je werkt met scheve datasets waarin één klasse veel vaker voorkomt dan de andere. Bijvoorbeeld: als je chatbot 1.000 routinematige vragen afhandelt, maar slechts 50 complexe escalaties, voorkomt de F1-score dat de statistiek wordt scheefgetrokken door de grootste klasse. De F1-score loopt van 0 tot 1, waarbij 1 perfecte precisie en recall betekent, wat het voor stakeholders eenvoudig maakt om de algemene prestaties van de chatbot in één oogopslag te begrijpen.
De verwarringsmatrix is een essentieel instrument dat de prestaties van de chatbot opsplitst in vier categorieën: True Positives (juiste antwoorden op geldige vragen), True Negatives (terecht geen antwoord geven op irrelevante vragen), False Positives (onjuiste antwoorden) en False Negatives (gemiste kansen om te helpen). Deze matrix laat specifieke patronen van fouten zien, waardoor je gericht kunt verbeteren. Als de matrix bijvoorbeeld veel false negatives toont bij factureringsvragen, kun je vaststellen dat de trainingsdata van de chatbot te weinig voorbeelden van facturering bevat en dat dit domein moet worden versterkt.
| Statistiek | Definitie | Berekening | Zakelijke impact |
|---|---|---|---|
| True Positives (TP) | Juiste antwoorden op geldige vragen | Direct geteld | Bouwt klantvertrouwen op |
| True Negatives (TN) | Terecht geen antwoord op irrelevante vragen | Direct geteld | Voorkomt misinformatie |
| False Positives (FP) | Onjuiste antwoorden gegeven | Direct geteld | Schaadt geloofwaardigheid |
| False Negatives (FN) | Gemiste kansen om te helpen | Direct geteld | Vermindert tevredenheid |
| Precisie | Kwaliteit van positieve voorspellingen | TP / (TP + FP) | Betrouwbaarheidsstatistiek |
| Recall | Dekking van daadwerkelijke positieven | TP / (TP + FN) | Volledigheidsstatistiek |
| Nauwkeurigheid | Algehele correctheid | (TP + TN) / Totaal | Algemene prestatie |
Antwoordnauwkeurigheid meet hoe vaak de chatbot feitelijk correcte informatie geeft die direct aansluit bij de gebruikersvraag. Dit gaat verder dan eenvoudige patroonherkenning en evalueert of de inhoud juist, actueel en passend is voor de context. Handmatige review-processen omvatten het laten beoordelen van een aselecte steekproef van gesprekken door menselijke beoordelaars, waarbij chatbot-antwoorden worden vergeleken met een vooraf gedefinieerde kennisbank van correcte antwoorden. Geautomatiseerde vergelijkingsmethoden zijn mogelijk met NLP-technieken die antwoorden matchen met verwachte antwoorden in het systeem, maar vragen om zorgvuldige kalibratie om false negatives te voorkomen als de chatbot correcte informatie geeft in andere bewoordingen dan het referentieantwoord.
Antwoordrelevantie beoordeelt of het antwoord van de chatbot daadwerkelijk ingaat op wat de gebruiker vroeg, ook als het niet helemaal juist is. Deze dimensie omvat situaties waarin de chatbot nuttige informatie verschaft die, hoewel niet het exacte antwoord, het gesprek wel richting een oplossing brengt. NLP-methoden zoals cosine similarity meten semantische overeenkomst tussen de gebruikersvraag en het antwoord van de chatbot, wat een geautomatiseerde relevantiescore oplevert. Gebruikersfeedback, zoals duim-omhoog/omlaag na elk gesprek, biedt directe relevantiebeoordeling door de mensen die het meest tellen: je klanten. Deze feedback moet continu worden verzameld en geanalyseerd om patronen te ontdekken in welke types vragen de chatbot goed of juist slecht afhandelt.
De Customer Satisfaction Score (CSAT) meet de tevredenheid van gebruikers over chatbot-interacties met directe enquêtes, meestal op een schaal van 1-5 of met eenvoudige tevredenheidsscores. Na elk gesprek wordt gebruikers gevraagd hun tevredenheid te beoordelen, wat directe feedback geeft over of de chatbot aan hun behoeften voldeed. CSAT-scores boven de 80% duiden op sterke prestaties, scores onder de 60% wijzen op problemen die nader onderzocht moeten worden. Het voordeel van CSAT is de eenvoud en directheid—gebruikers geven direct aan of ze tevreden zijn—maar het kan ook beïnvloed worden door andere factoren, zoals de complexiteit van het probleem of de verwachtingen van de gebruiker.
Net Promoter Score meet de kans dat gebruikers de chatbot aanbevelen aan anderen, door te vragen: “Hoe waarschijnlijk is het dat je deze chatbot aan een collega aanbeveelt?” op een schaal van 0-10. Respondenten met een score van 9-10 zijn promoters, 7-8 zijn passief, en 0-6 zijn detractors. NPS = (Promoters - Detractors) / Totaal aantal respondenten × 100. Deze statistiek correleert sterk met langdurige klantloyaliteit en geeft inzicht in of de chatbot positieve ervaringen creëert die gebruikers willen delen. Een NPS boven 50 wordt als uitstekend beschouwd, een negatieve NPS duidt op serieuze prestatieproblemen.
Sentimentanalyse onderzoekt de emotionele toon van gebruikersberichten voor en na chatbot-interacties om tevredenheid te meten. Geavanceerde NLP-technieken classificeren berichten als positief, neutraal of negatief en laten zien of gebruikers tijdens gesprekken meer tevreden raken of juist gefrustreerd. Een positieve sentimentverschuiving betekent dat de chatbot zorgen succesvol heeft weggenomen, een negatieve verschuiving suggereert dat de chatbot gebruikers heeft gefrustreerd of hun behoeften niet heeft vervuld. Deze statistiek onthult emotionele dimensies die traditionele nauwkeurigheidsstatistieken missen en biedt waardevolle context voor het begrijpen van gebruikerservaringen.
First Contact Resolution meet het percentage klantproblemen dat door de chatbot direct wordt opgelost, zonder doorverwijzing naar een menselijke medewerker. Deze statistiek heeft direct invloed op operationele efficiëntie en klanttevredenheid, omdat klanten graag direct geholpen willen worden in plaats van te worden doorverbonden. FCR-percentages boven 70% geven sterke chatbot-prestaties aan, percentages onder 50% wijzen erop dat de chatbot onvoldoende kennis of mogelijkheden heeft om veelvoorkomende vragen zelfstandig af te handelen. Door FCR per probleemcategorie te meten, ontdek je welke problemen de chatbot goed oppakt en waar juist menselijke tussenkomst nodig is—een basis voor gerichte training en kennisbankverbetering.
De escalatiegraad meet hoe vaak de chatbot gesprekken overdraagt aan menselijke medewerkers, terwijl fallback-frequentie bijhoudt hoe vaak de chatbot terugvalt op generieke antwoorden zoals “Ik begrijp u niet” of “Kunt u uw vraag anders formuleren?”. Hoge escalatiepercentages (boven de 30%) betekenen dat de chatbot in veel situaties kennis of vertrouwen mist, hoge fallbackpercentages wijzen op slechte intentieherkenning of onvoldoende trainingsdata. Deze statistieken tonen specifieke gaten in de capaciteiten van de chatbot die kunnen worden aangepakt door kennisbankuitbreiding, modelhertraining of verbeterde natuurlijke taalverwerking.
Responstijd meet hoe snel de chatbot reageert op gebruikersberichten, doorgaans in milliseconden tot seconden. Gebruikers verwachten vrijwel directe antwoorden; vertragingen boven de 3-5 seconden schaden de tevredenheid aanzienlijk. Afhandeltijd meet de totale tijd van het eerste contact tot aan probleemoplossing of escalatie, en geeft inzicht in de efficiëntie van de chatbot. Kortere afhandeltijden betekenen dat de chatbot snel begrijpt en oplost, langere tijden wijzen op meerdere verduidelijkingsrondes of moeite met complexe vragen. Meet deze statistieken afzonderlijk per probleemcategorie; technische problemen duren immers langer dan eenvoudige FAQ-vragen.
LLM als beoordelaar is een geavanceerde evaluatieaanpak waarbij één large language model de kwaliteit van de antwoorden van een ander AI-systeem beoordeelt. Deze methode is bijzonder effectief voor het tegelijk beoordelen van meerdere kwaliteitsdimensies van chatbot-antwoorden, zoals nauwkeurigheid, relevantie, samenhang, vloeiendheid, veiligheid, volledigheid en toon. Onderzoek toont aan dat LLM-beoordelaars tot 85% overeenkomen met menselijke beoordelingen, waardoor ze een schaalbaar alternatief zijn voor handmatige review. De aanpak omvat het definiëren van specifieke evaluatiecriteria, het opstellen van gedetailleerde beoordelaarsprompts met voorbeelden, het geven van de originele gebruikersvraag en het chatbot-antwoord aan de beoordelaar, en het ontvangen van gestructureerde scores of feedback.
Het LLM als beoordelaar-proces kent doorgaans twee evaluatievormen: beoordeling van één antwoord (met of zonder referentieantwoord) en pairwise vergelijking, waarbij de beoordelaar twee antwoorden vergelijkt en de beste aanwijst. Deze flexibiliteit maakt zowel absolute prestatiebeoordeling als vergelijking van verschillende chatbot-versies mogelijk. Het FlowHunt-platform ondersteunt LLM als beoordelaar via de visuele interface, integratie met toonaangevende LLM’s zoals ChatGPT en Claude, en een CLI-toolkit voor geavanceerde rapportage en automatische evaluaties.
Naast basisnauwkeurigheid onthult een gedetailleerde verwarringsmatrix-analyse specifieke patronen in chatbot-fouten. Door te onderzoeken welke types vragen tot false positives of false negatives leiden, kun je systematische zwaktes ontdekken. Als de matrix bijvoorbeeld toont dat de chatbot factureringsvragen vaak als technische support markeert, wijst dit op een disbalans in de trainingsdata of een intentieherkenningsprobleem binnen dat domein. Door aparte verwarringsmatrices per probleemcategorie te maken, kun je gerichter verbeteren in plaats van generiek te retrainen.
A/B-testen vergelijkt verschillende versies van de chatbot om te bepalen welke beter presteert op belangrijke statistieken. Dit kan verschillende antwoordtemplates, kennisbankconfiguraties of taalmodellen betreffen. Door een deel van het verkeer naar elke versie te sturen en statistieken zoals FCR, CSAT en antwoordnauwkeurigheid te vergelijken, kun je datagedreven beslissen welke verbeteringen worden doorgevoerd. Laat A/B-testen lang genoeg lopen om natuurlijke variatie in gebruikersvragen te vangen en statistische significantie te borgen.
FlowHunt biedt een geïntegreerd platform voor het bouwen, implementeren en evalueren van AI-helpdeskchatbots met geavanceerde nauwkeurigheidsmeetmogelijkheden. De visuele builder stelt niet-technische gebruikers in staat om geavanceerde chatbotflows te maken, terwijl de AI-componenten integreren met toonaangevende taalmodellen als ChatGPT en Claude. De evaluatietoolkit van FlowHunt ondersteunt de implementatie van de LLM als beoordelaar-methodiek, zodat je eigen evaluatiecriteria kunt instellen en chatbotprestaties automatisch over je gehele conversatiedataset kunt beoordelen.
Om uitgebreide nauwkeurigheidsmeting met FlowHunt te implementeren, begin je met het definiëren van je specifieke evaluatiecriteria die passen bij je bedrijfsdoelen—of je nu prioriteit geeft aan nauwkeurigheid, snelheid, gebruikerstevredenheid of oplossingspercentages. Stel de beoordelende LLM in met gedetailleerde prompts, inclusief voorbeelden van goede en slechte antwoorden. Upload je conversatiedataset of koppel live verkeer, voer de evaluaties uit en genereer gedetailleerde rapporten over alle statistieken. Het FlowHunt-dashboard biedt realtime inzicht in chatbotprestaties, zodat je snel problemen detecteert en verbeteringen valideert.
Stel een nulmeting vast vóór je verbeteringen doorvoert, zodat je het effect van wijzigingen goed kunt beoordelen. Verzamel continu metingen in plaats van periodiek, zodat je vroegtijdig prestatieverlies door datadrift of modelveroudering detecteert. Implementeer feedbackloops waarbij gebruikersbeoordelingen en correcties automatisch terugstromen in het trainingsproces, zodat de chatbot continu verbetert. Segmenteer statistieken op probleemcategorie, gebruikerstype en tijdsperiode, zodat je gerichter kunt verbeteren in plaats van alleen op totaalcijfers te sturen.
Zorg ervoor dat je evaluatiedataset echte gebruikersvragen en verwachte antwoorden bevat, en geen kunstmatige testcases die niet overeenkomen met het daadwerkelijke gebruik. Valideer geautomatiseerde statistieken regelmatig tegen menselijke beoordeling door handmatige beoordeling van een steekproef, zodat je meetsysteem geijkt blijft op echte kwaliteit. Documenteer je meetmethodiek en definities van statistieken duidelijk, zodat je consistent kunt meten en resultaten helder kunt communiceren naar stakeholders. Stel tenslotte duidelijke prestatiedoelen voor elke statistiek, afgestemd op de bedrijfsdoelstellingen, om verantwoording en continue verbetering te waarborgen en optimalisatie-inspanningen richting te geven.
Het geavanceerde AI-automatiseringsxadplatform van FlowHunt helpt je bij het creëren, implementeren en evalueren van high-performance helpdeskchatbots met ingebouwde nauwkeurigheidsxadmeetxadtools en LLM-gebaseerde evaluatiexadmogelijkheden.
Leer alles over uitgebreide AI-chatbot teststrategieën, waaronder functioneel, prestatie-, beveiligings- en gebruikerstesten. Ontdek best practices, tools en fr...
Ontdek bewezen methoden om in 2025 de echtheid van AI-chatbots te verifiëren. Leer technische verificatiexadtechnieken, beveiligingscontroles en best practices ...
Leer hoe AI-chatbots kunnen worden misleid via prompt engineering, adversariële invoer en contextverwarring. Begrijp de kwetsbaarheden en beperkingen van chatbo...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.