Hoe train je een AI-chatbot met een aangepaste kennisbank
Volledige gids voor het trainen van AI-chatbots met aangepaste kennisbanken. Leer data voorbereiding, integratiemethoden, semantisch zoeken en best practices voor nauwkeurige antwoorden.
Hoe train je een AI-chatbot met een aangepaste kennisbank?
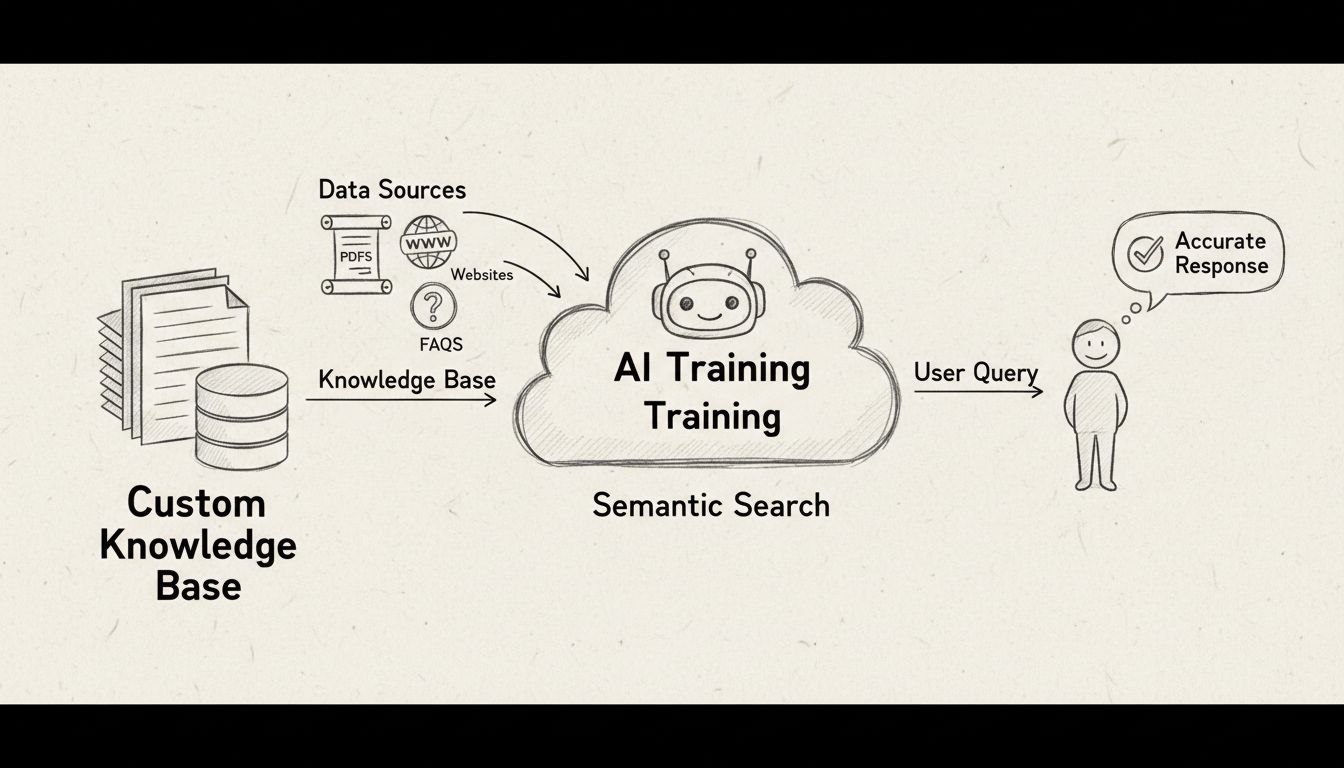
Het trainen van een AI-chatbot met een aangepaste kennisbank houdt in dat je je data voorbereidt, geschikte tools selecteert, kennisbronnen integreert en de antwoorden voortdurend verfijnt. In tegenstelling tot traditionele training leren moderne AI-chatbots direct van gestructureerde kennisbanken zonder uitgebreide handmatige training—je koppelt simpelweg je databronnen en de chatbot begint direct met het leveren van nauwkeurige, contextbewuste antwoorden.
AI-chatbot trainen met aangepaste kennisbanken begrijpen
Het trainen van een AI-chatbot met een aangepaste kennisbank betekent een fundamentele verschuiving ten opzichte van traditionele machine learning-methodes. In plaats van grote gelabelde datasets en iteratieve trainingscycli, maken moderne AI-chatbots gebruik van semantisch zoeken en retrieval-augmented generation (RAG) technologie om direct toegang te krijgen tot en gebruik te maken van jouw eigen informatie. Het proces draait om datavoorbereiding, bronintegratie en voortdurende optimalisatie in plaats van klassieke computationele training.
Het verschil tussen traditionele AI-training en kennisbank-integratie is essentieel om te begrijpen. Traditionele machine learning vereist dat je modellen opnieuw traint met nieuwe data, wat tijdrovend en kostbaar is. Kennisbank-chatbots werken daarentegen op basis van een retrievalmodel, waarbij het AI-systeem jouw kennisbank doorzoekt naar relevante informatie en antwoorden genereert op basis van wat het vindt. Deze aanpak elimineert de noodzaak om te hertrainen en zorgt ervoor dat je chatbot automatisch up-to-date blijft met de laatste informatie. De semantische begrijplaag zorgt ervoor dat de chatbot, zelfs wanneer klanten vragen anders formuleren, hun intentie kan koppelen aan de juiste kennisbankartikelen en accurate, contextuele antwoorden kan geven.
Stap 1: Bereid je aangepaste kennisbank voor en structureer deze
De basis van een effectieve AI-chatbot ligt in hoe goed je je kennisbank organiseert. Datavoorbereiding is geen eenmalige taak, maar een continu proces dat direct invloed heeft op de nauwkeurigheid van de chatbot en de tevredenheid van de gebruiker. Je kennisbank moet alle informatie bevatten die je chatbot nodig heeft om klantvragen te beantwoorden, zoals veelgestelde vragen, productdocumentatie, handleidingen, beleid en procedures. Zonder goede organisatie zal zelfs het meest geavanceerde AI-systeem moeite hebben om relevante informatie te vinden en correcte antwoorden te geven.
Begin met een grondige audit van je bestaande content. Identificeer veelgestelde vragen uit supporttickets, analyseer veelvoorkomende vraagpatronen en bepaal waar informatie ontbreekt in je huidige documentatie. Deze audit laat zien welke content je chatbot nodig heeft en waar extra documentatie vereist is. Veel organisaties ontdekken dat hun kennisbank verouderde informatie, dubbele content of inconsistenties bevat die zowel gebruikers als AI-systemen verwarren. Door je content systematisch te beoordelen, leg je een fundament voor succes.
Datacleaning en normalisatie zijn essentiële voorbereidingsstappen die direct invloed hebben op de prestaties van de chatbot. Verwijder overbodige informatie, standaardiseer terminologie in alle documenten en elimineer dubbelzinnige formuleringen die het semantisch begrip van de chatbot kunnen verstoren. Als dezelfde functionaliteit bijvoorbeeld beschreven wordt als zowel “account sluiten” als “profiel verwijderen”, kies dan één term en gebruik deze consequent. Zorg daarnaast voor duidelijke, beknopte taal zonder overbodig jargon, wat zowel de leesbaarheid voor mensen als AI-begrip bevordert. Gebruik entity recognition-technieken om belangrijke concepten te taggen, zodat de chatbot relaties tussen verschillende stukken informatie beter begrijpt.
Element van kennisbank
Doel
Best Practice
Veelgestelde vragen
Beantwoorden van standaard klantvragen
Ordenen op onderwerp, duidelijke Q&A-formaat met verschillende bewoordingen
Gebruik van koppen, opsommingen, visuele ondersteuning, kruisverwijzingen
Kennisgrafen
Relaties tussen entiteiten in kaart brengen
Definieer connecties tussen concepten en gerelateerde onderwerpen
Implementeer een duidelijke taxonomie en tagsysteem dat weerspiegelt hoe klanten over je producten of diensten denken. Deze structuur helpt de chatbot om gebruikersintentie te begrijpen en relevante informatie te vinden. Verkoop je bijvoorbeeld via e-commerce, organiseer content dan op productcategorie, klantreis of soort probleem. Tags moeten beschrijvend en consistent zijn, zodat de chatbot gerelateerde informatie kan koppelen en volledige antwoorden kan geven. Een goed ontworpen taxonomie vermindert ambiguïteit en zorgt ervoor dat de semantische zoekmachine klantvragen accuraat koppelt aan de juiste content.
Stap 2: Kies het juiste AI-chatbotplatform en architectuur
De juiste platformkeuze bepaalt in grote mate de mogelijkheden en het onderhoudsgemak van je chatbot. Er zijn grofweg drie opties: een volledig eigen systeem bouwen, een generiek large language model API inzetten, of een gespecialiseerd kennisbank-chatbotplatform gebruiken. Elke aanpak heeft unieke voordelen en afwegingen, afhankelijk van je middelen, technische expertise en zakelijke eisen.
Maatwerk-systemen geven maximale controle, maar vereisen veel ontwikkelcapaciteit en doorlopend onderhoud. Banken en grote bedrijven kiezen hier vaak voor, maar het vraagt om toegewijde teams voor updates, beveiliging en performance-optimalisatie. Deze systemen kun je exact afstemmen op je behoeften, maar het vraagt een flinke investering en voortdurende technische aandacht. Generieke LLM-API’s zoals OpenAI’s GPT-4 bieden krachtige mogelijkheden, maar brengen uitdagingen met zich mee rond gegevensprivacy, hallucinatie-risico’s en afhankelijkheid van derde partijen. Zulke systemen kunnen zelfverzekerd onjuiste informatie geven, wat constante monitoring en menselijke controle vereist om accuratesse te waarborgen.
Gespecialiseerde kennisbank-chatbotplatformen zoals FlowHunt bieden voor de meeste organisaties de optimale balans. Met de AI-chatbot builder van FlowHunt kun je zonder programmeerkennis intelligente chatbots maken en direct je kennisbronnen koppelen. De visuele builder maakt het eenvoudig, en de AI-agents voeren echte taken uit met nauwkeurigheid dankzij geïntegreerd semantisch zoeken. FlowHunt voorkomt hallucinaties door antwoorden altijd te baseren op jouw kennisbank, zodat klanten altijd correcte informatie ontvangen. Het platform ondersteunt real-time data, multichannel deployment en naadloze integratie met bestaande bedrijfssoftware, en is daarmee leidend voor organisaties die snel willen uitrollen zonder concessies aan kwaliteit of veiligheid.
Technisch moet de architectuur semantische embeddings ondersteunen, die essentieel zijn voor het begrijpen van gebruikersintentie voorbij simpele zoekwoorden. Semantische embeddings representeren woorden en zinnen als vectoren, waardoor het systeem begrijpt dat “Hoe reset ik mijn wachtwoord?” semantisch lijkt op “Ik ben mijn inloggegevens vergeten”, ondanks andere bewoording. Dit verhoogt de kans dat de chatbot relevante kennisbankartikelen vindt. Geavanceerde embeddings zoals BERT bieden dieper begrip tegen hogere rekenkosten, terwijl lichtere opties als Word2Vec sneller zijn maar iets minder nauwkeurig.
Stap 3: Integreer kennisbronnen en configureer data-toegang
Integratie maakt je kennisbank bruikbaar voor de chatbot. Moderne platformen ondersteunen meerdere typen databronnen zoals PDF’s, websites, databases, help-artikelen en zelfs live datafeeds. Integreren doe je meestal door documenten te uploaden, URLs voor webscraping te geven of API’s te koppelen aan live databronnen. Een goede integratie zorgt ervoor dat je chatbot altijd toegang heeft tot actuele informatie en snel relevante content kan ophalen.
Stel bij het integreren van kennisbronnen duidelijke databeleid op. Bepaal welke informatie de chatbot mag zien, implementeer toegangscontrole voor gevoelige data en zorg voor naleving van privacywetgeving zoals de AVG. Dynamische datamapping binnen middleware zorgt voor soepele uitwisseling tussen systemen door zich in real time aan te passen aan verschillende datastructuren en formaten. Dit minimaliseert integratiefouten, omdat inkomende data wordt genormaliseerd vóór het bij de chatbot terechtkomt. Schaalbare infrastructuur zorgt voor goede prestaties en veiligheid, ook bij groeiend gebruik.
De Knowledge Sources-functie van FlowHunt is een goed voorbeeld van moderne integratiemogelijkheden. Je kunt specifieke URLs of hele websites scannen om automatisch relevante content te extraheren, Q&A’s importeren via CSV-bestanden en zelfs live-chatdata gebruiken om je kennisbank continu uit te breiden. De mogelijkheid om waardevolle informatie uit opgeloste klantgesprekken te halen, betekent dat je chatbot leert van echte interacties en zichzelf voortdurend verbetert. Zo blijft je chatbot afgestemd op de werkelijke klantbehoeften en veranderende bedrijfsprocessen.
Stap 4: Implementeer semantisch zoeken en retrievalmechanismen
Semantisch zoeken is de motor achter nauwkeurige chatbotantwoorden. In tegenstelling tot traditioneel zoeken op trefwoorden, begrijpt semantisch zoeken de betekenis en context van een vraag en koppelt deze aan relevante kennisbankcontent, zelfs als exacte zoekwoorden ontbreken. Deze technologie gebruikt vector-embeddings om zowel gebruikersvragen als kennisbankartikelen te representeren in dezelfde semantische ruimte, waardoor overeenkomst op betekenis mogelijk wordt. Hierdoor begrijpt de chatbot klantintentie en geeft relevante antwoorden, ongeacht hoe de vraag geformuleerd is.
Het retrievalproces werkt in meerdere stappen. Eerst wordt de gebruikersvraag omgezet in een semantische embedding. Vervolgens zoekt het systeem in de kennisbank naar content met vergelijkbare embeddings. Daarna worden de meest relevante documenten opgehaald en gerangschikt op relevantiescore. Tot slot genereert het taalmodel een antwoord op basis van de opgehaalde context. Deze retrieval-augmented generation (RAG) aanpak zorgt ervoor dat antwoorden altijd gebaseerd zijn op jouw eigen kennisbank, niet op de trainingsdata van het model. Door antwoorden te beperken tot informatie uit je kennisbank, voorkom je hallucinaties en waarborg je accuratesse.
Effectief semantisch zoeken vereist schone, goed gestructureerde content. Artikelen moeten duidelijke koppen, samenvattingen en relevante trefwoorden bevatten, zodat het embeddingmodel de inhoud goed begrijpt. Vermijd dubbelzinnige formuleringen en zorg dat verwante concepten aan elkaar gelinkt worden. Bespreekt je kennisbank bijvoorbeeld zowel “abonnement opzeggen” als “account beëindigen”, koppel deze artikelen dan zodat de chatbot begrijpt dat het verwante onderwerpen zijn. Gebruik normalisatietechnieken voor termen, verwijder dubbele content en zorg voor consistente opmaak in alle artikelen.
Stap 5: Test, implementeer en blijf verbeteren
Testen vóór livegang is essentieel om hiaten te ontdekken en nauwkeurigheid te waarborgen. Stel een uitgebreide testsuite samen met veel voorkomende klantvragen, randgevallen en verschillende formuleringen. Test met vereenvoudigde taal, slang en verschillende bewoordingen om te zien of de chatbot uiteenlopende communicatiestijlen aankan. Meet prestaties zoals antwoordnauwkeurigheid, afhandelingspercentages en klanttevredenheidsscores. Een grondig testproces voorkomt problemen bij echte klanten en geeft vertrouwen in de betrouwbaarheid van je chatbot.
De uitrolstrategie hangt af van je gebruikssituatie. Je kunt de chatbot als widget op je website plaatsen, integreren met messagingplatforms zoals WhatsApp of Facebook Messenger, of inzetten binnen je eigen klantservicesysteem. FlowHunt ondersteunt multichannel deployment, zodat je klanten bereikt via het kanaal van hun voorkeur. Met de visuele builder kun je eenvoudig het uiterlijk en gedrag van de chatbot per kanaal aanpassen. Of je nu op web, mobiel of messaging-apps inzet, FlowHunt garandeert consistente prestaties en gebruikerservaring.
Doorlopende verbetering is waar je chatbot echt waarde oplevert. Monitor gebruikersinteracties om te zien waar de chatbot moeite mee heeft, volg afhandelingspercentages en verzamel klantfeedback. Gebruik deze data om je kennisbank uit te breiden, artikelen te verbeteren en het gedrag van de chatbot aan te passen. Analytics-dashboards moeten KPI’s tonen zoals first contact resolution, klanttevredenheid, deflectieratio (percentage issues opgelost zonder menselijke tussenkomst) en gemiddelde responstijd. Regelmatige analyse hiervan laat verbeterkansen zien en bewijst de meerwaarde van je chatbot.
Best practices voor het behouden van chatbot-nauwkeurigheid
Hoge nauwkeurigheid vergt voortdurende aandacht voor zowel je kennisbank als de systeemprestaties. Plan minimaal elk kwartaal een review om de kennisbank te controleren op juistheid, relevantie en volledigheid. Zodra producten en diensten veranderen, pas je de kennisbank direct aan om te voorkomen dat de chatbot verouderde informatie verstrekt. Zo blijft je chatbot een betrouwbare bron voor klanten en medewerkers.
Implementeer een feedbackloop waarbij klantinteracties leiden tot verbeteringen van de kennisbank. Wanneer de chatbot een vraag niet kan beantwoorden, markeer deze dan voor je team om toe te voegen aan de kennisbank. Veel moderne platformen, waaronder FlowHunt, halen automatisch bruikbare info uit opgeloste gesprekken en maken hier nieuwe Q&A’s van. Zo groeit je kennisbank organisch mee met de echte klantbehoeften. Door elke klantinteractie te zien als leermoment, creëer je een positieve spiraal waarin de chatbot steeds beter wordt.
Gebruik natuurlijke taalvariaties en synoniemen in je kennisbank om query-matching te verbeteren. Als klanten je product op verschillende manieren noemen of voor hetzelfde concept andere termen gebruiken, neem deze variaties dan op in je artikelen. Dit vergroot de kans dat de chatbot uiteenlopende communicatievormen begrijpt en relevante antwoorden geeft. Maak eventueel een synoniemenlijst die verschillende klanttermen koppelt aan gestandaardiseerde begrippen, zodat het semantisch zoekmodel intentie snapt, zelfs als termen verschillen.
Monitor hallucinatie-risico’s door chatbotantwoorden regelmatig te beoordelen. Ook al zijn antwoorden gebaseerd op je eigen kennisbank, er kunnen randgevallen zijn waarin het systeem aannemelijk klinkende maar onjuiste antwoorden geeft. Implementeer daarom menselijke controle bij kritieke klantcases en gebruik feedback om snel te corrigeren. Regelmatige audits van gesprekken onthullen patronen, zodat je structureel kunt verbeteren in plaats van reactief.
Kennisbank-chatbotoplossingen vergelijken
Let bij het vergelijken van platforms op factoren als installatiegemak, nauwkeurigheidsgaranties, integratiemogelijkheden en support. FlowHunt onderscheidt zich als het toonaangevende platform voor organisaties die intelligente chatbots met eigen kennisbank willen bouwen. Het biedt superieure nauwkeurigheid via geavanceerd semantisch zoeken, een no-code visuele builder en naadloze integratie met bestaande bedrijfssoftware. De focus op accuratesse, gebruiksgemak en enterprise-functies maakt FlowHunt de beste keuze voor bedrijven van elk formaat.
De AI-agents van het platform voeren echte taken uit zoals dataverzameling, formulierinvoer en workflowautomatisering. Zo transformeer je chatbots van passieve informatieverstrekkers tot actieve deelnemers aan bedrijfsprocessen. De knowledge sources-functie van FlowHunt ondersteunt real-time data, zodat je chatbot altijd actuele info geeft uit databases, websites en API’s. Dankzij ondersteuning van meerdere dataformaten (PDF, website, database, live feeds) biedt FlowHunt ongeëvenaarde flexibiliteit in kennisbank-integratie.
Conclusie
Het trainen van een AI-chatbot met een aangepaste kennisbank is geen ingewikkeld ontwikkeltraject meer. Door een gestructureerde aanpak—data voorbereiden, het juiste platform kiezen, kennisbronnen integreren, semantisch zoeken implementeren en voortdurend verbeteren op basis van gebruikersinteracties—kun je snel een chatbot inzetten die nauwkeurige, contextbewuste antwoorden geeft, afgestemd op jouw bedrijfsbehoeften. Het belangrijkste inzicht: moderne chatbot-“training” draait om data en integratie, niet om complexe computationele training. Zo kun je snel effectieve oplossingen lanceren en schalen. Met platforms als FlowHunt bouw, implementeer en optimaliseer je intelligente chatbots die klantondersteuning transformeren, operationele kosten verlagen en klanttevredenheid verhogen. Start vandaag nog met jouw chatbot en ervaar het verschil dat intelligente automatisering voor jouw organisatie kan maken.
Klaar om je AI-chatbot te bouwen?
Stop met tijd verspillen aan herhaalde klantvragen. Met de AI-chatbot builder van FlowHunt maak je slimme chatbots met aangepaste kennisbanken in enkele minuten—zonder code. Zet ze uit op meerdere kanalen en zie je support-efficiëntie stijgen.
Hoe houd je de kennisbank van je AI-chatbot up-to-date met nieuwe documenten en website-inhoud
Leer bewezen strategieën en automatiseringstechnieken om de kennisbank van je AI-chatbot continu te updaten met nieuwe documenten, website-inhoud en realtime in...
Hoe gebruik je een AI Chatbot: Complete Gids voor Effectieve Prompting & Best Practices
Beheers het gebruik van AI-chatbots met onze uitgebreide gids. Leer effectieve prompting-technieken, best practices en hoe je het meeste uit AI-chatbots haalt i...
Ontdek de beste manieren om AI-chatbotassistenten in 2025 aan te spreken. Leer over formele, informele en speelse communicatiestijlen, naamgevingsconventies en ...
10 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.