
Large Language Model Meta AI (LLaMA)
Large Language Model Meta AI (LLaMA) to najnowocześniejszy model przetwarzania języka naturalnego opracowany przez firmę Meta. Dzięki aż 65 miliardom parametrów...
2 min czytania
AI
Language Model
+6

Ekstrakcja danych wspierana przez AI automatyzuje przetwarzanie danych, redukuje błędy i sprawnie obsługuje duże zbiory danych. Poznaj najlepsze narzędzia, metody oraz przyszłe trendy.
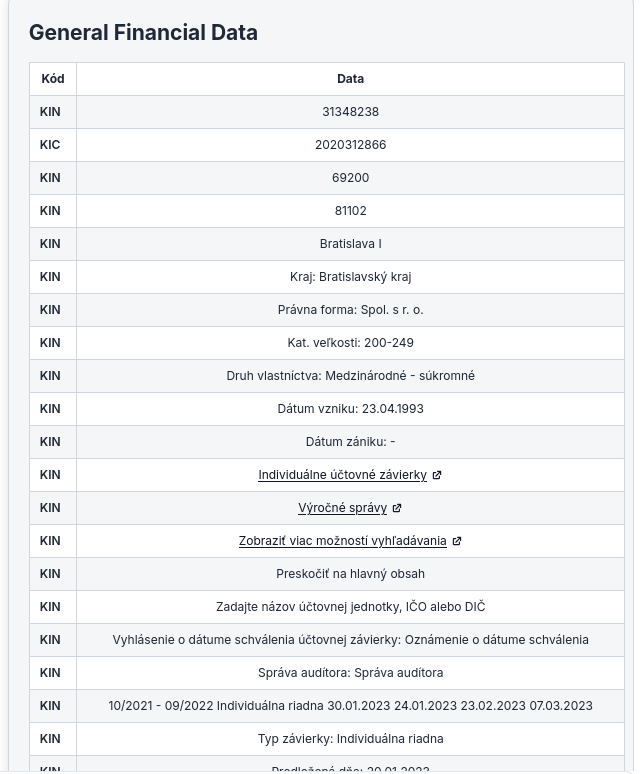
Oto modele, które testowaliśmy pod kątem ekstrakcji danych ze stron internetowych w HTML. Poniżej przedstawiamy wydajność kilku modeli, które sprawdziliśmy podczas wyodrębniania konkretnych danych do uporządkowanych formatów, takich jak tabele markdown, ze stron HTML.
To jest prompt, którego użyliśmy do oceny różnych modeli; pobieraliśmy niestrukturalne dane z HTML i prezentowaliśmy je jako tabelę Markdown.
Ten model, choć innowacyjny pod względem architektury, wykazał ograniczenia w ścisłym przestrzeganiu poleceń dotyczących ekstrakcji danych. W naszym zadaniu model wyodrębnił wszystkie dane, a nie tylko te określone w poleceniu.
Model Haiku od Anthropic AI wyróżnił się w naszej ocenie. Wykazał solidną zdolność nie tylko do zrozumienia promptu, ale także do wykonania zadania ekstrakcji z dużą dokładnością. Doskonale radził sobie z parsowaniem treści HTML i formatowaniem wyodrębnionych danych w przejrzyste tabele markdown. Umiejętność modelu do utrzymania kontekstu i podążania za szczegółowymi instrukcjami sprawiła, że był szczególnie skuteczny przy tym zastosowaniu.
Choć model Haiku jest najmniejszym modelem Anthropic, wypadł lepiej niż jakikolwiek inny model w naszej ewaluacji.
Chociaż modele OpenAI są znane ze swojej wszechstronności i rozumienia języka, nie wyróżniły się w naszym konkretnym zadaniu konwersji HTML na tabele markdown. Głównym problemem było formatowanie tabel markdown — model czasem generował tabele z nierównymi kolumnami lub niespójną składnią, co wymagało ręcznej korekty po ekstrakcji. Wygenerowane wyniki OpenAI zawierały też wiele pól zastępczych.
Metody ekstrakcji danych są kluczowe dla firm, które chcą maksymalnie wykorzystać swoje dane. Metody te mają różne poziomy złożoności i są dostosowane do różnych typów danych oraz potrzeb biznesowych.
Web scraping to popularny sposób pozyskiwania danych bezpośrednio ze stron internetowych. Polega na użyciu automatycznych narzędzi lub skryptów do gromadzenia dużych ilości danych z witryn. Jest szczególnie pomocny w zbieraniu publicznie dostępnych informacji, takich jak ceny, szczegóły produktów czy opinie klientów. Narzędzia takie jak BeautifulSoup i Cheerio są znane z wydobywania treści ze statycznych stron. Co więcej, scrapery oparte na AI mogą zautomatyzować i usprawnić ten proces, oszczędzając czas i wysiłek.
Ekstrakcja tekstu polega na wydobywaniu konkretnych informacji ze źródeł, w których dominuje tekst. Metoda ta jest istotna przy pracy z dokumentami, e-mailami i innymi formatami tekstowymi. Zaawansowane techniki ekstrakcji potrafią odnajdywać i wyodrębniać wzorce lub jednostki, takie jak imiona, daty czy kwoty finansowe z niestrukturalnego tekstu. Często proces ten wspierają modele uczenia maszynowego, które z czasem stają się coraz dokładniejsze i wydajniejsze.
Narzędzia API ułatwiają ekstrakcję danych, oferując uporządkowany sposób dostępu do danych z zewnętrznych źródeł. Dzięki API firmy mogą pobierać dane z różnych usług, takich jak platformy społecznościowe, bazy danych czy aplikacje chmurowe — bezpiecznie i wydajnie. Podejście to idealnie nadaje się do integracji danych w czasie rzeczywistym z aplikacjami biznesowymi, zapewniając płynny przepływ informacji i ich aktualność.
Data mining to analiza dużych zbiorów danych w celu odkrycia wzorców, korelacji i wniosków, które nie są od razu oczywiste. Metoda ta jest nieoceniona dla firm chcących optymalizować procesy, przewidywać trendy lub lepiej rozumieć zachowania klientów. Techniki data mining można stosować zarówno do danych strukturalnych, jak i niestrukturalnych, czyniąc je wszechstronnymi narzędziami wspierającymi decyzje strategiczne.
Technologia OCR zamienia tekst pisany odręcznie lub wydrukowany na dane cyfrowe, które można edytować i przeszukiwać. Metoda ta jest szczególnie przydatna do digitalizacji informacji papierowych, usprawniając zarządzanie dokumentacją i poprawiając dostęp do danych. Silniki OCR są coraz bardziej zaawansowane, oferując dużą dokładność i szybkość przy konwertowaniu dokumentów do postaci cyfrowej.
Włączenie tych metod ekstrakcji danych do planu biznesowego może znacząco zwiększyć możliwości przetwarzania danych, prowadząc do lepszych decyzji i wyższej efektywności operacyjnej. Wybierając odpowiednią metodę lub ich kombinację, firmy mogą mieć pewność, że maksymalnie wykorzystują swoje dane.
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Docsumo to narzędzie do przetwarzania dokumentów i ekstrakcji danych zaprojektowane w celu automatyzacji procesu wprowadzania danych poprzez wydobywanie informacji z różnych rodzajów dokumentów. Dzięki inteligentnej technologii OCR znacząco skraca czas i wysiłek potrzebny na ręczne wprowadzanie danych, co czyni go cennym narzędziem w wielu branżach, takich jak finanse, opieka zdrowotna czy ubezpieczenia.
Zalety:
Wady:
Grupa docelowa: Idealni użytkownicy Docsumo to:
Rekomendacje:
Polecamy Docsumo firmom obsługującym duże ilości dokumentów, które potrzebują niezawodnej ekstrakcji danych. Funkcje automatyzacji zwiększają efektywność i dokładność, czyniąc to narzędzie niezbędnym w różnych sektorach.
Hevo Data to kompleksowa platforma integracji danych, umożliwiająca firmom konsolidację i integrację danych z wielu źródeł w jeden, spójny widok. Platforma została zaprojektowana z myślą o przyjaznym interfejsie, pozwalającym użytkownikom tworzyć przepływy danych bez konieczności programowania. Ta dostępność czyni ją idealnym rozwiązaniem dla firm chcących wykorzystać dane do analiz i raportowania. Hevo Data obsługuje różnorodne źródła danych — od baz danych, przez przechowywanie w chmurze, po aplikacje SaaS — umożliwiając usprawnienie przepływów danych i poprawę decyzyjności.
Hevo Data otrzymało pozytywne recenzje za łatwość obsługi, możliwości pracy w czasie rzeczywistym i szerokie opcje integracji. Wielu użytkowników docenia prostotę obsługi bez kodu, która pozwala szybko uruchomić przepływy danych, nawet bez zaawansowanej wiedzy technicznej. Funkcja replikacji danych w czasie rzeczywistym została wyróżniona jako ogromna zaleta dla firm bazujących na aktualnych informacjach. Niektórzy użytkownicy wskazują jednak na krzywą uczenia przy bardziej zaawansowanych funkcjach.
Hevo Data zdecydowanie polecamy małym i średnim firmom, które chcą usprawnić integrację danych bez angażowania dużych zasobów technicznych. Platforma szczególnie dobrze sprawdzi się w zespołach wymagających analiz i raportowania w czasie rzeczywistym. Firmy z branż e-commerce, finansów i marketingu mogą znacząco skorzystać z konsolidacji danych przy podejmowaniu decyzji. Ogólnie rzecz biorąc, Hevo Data to doskonały wybór dla firm poszukujących niezawodnego i przyjaznego narzędzia do integracji danych.

Airbyte to platforma open-source do integracji danych, zaprojektowana, by umożliwić firmom efektywną synchronizację danych pomiędzy różnymi systemami. Ułatwia budowę przepływów danych ELT (Extract, Load, Transform), które łączą różne źródła i miejsca docelowe, umożliwiając płynny transfer i raportowanie. Założony w styczniu 2020 r. Airbyte ma na celu uproszczenie integracji danych poprzez narzędzie bez kodowania, umożliwiające łączenie systemów bez rozbudowanych zasobów inżynierskich. Z ponad 400 dostępnymi konektorami Airbyte szybko zdobył popularność, pozyskując znaczące finansowanie od początku swojego istnienia.
Pozytywne: Użytkownicy chwalą łatwość obsługi, szeroką integrację, open source oraz wsparcie klienta. Wielu uważa platformę za przyjazną, umożliwiającą szybkie uruchomienie przepływów danych.
Negatywne: Część użytkowników zgłasza problemy z wydajnością przy dużych wolumenach danych oraz potrzebę lepszej dokumentacji. Inni uważają, że zaawansowane funkcje są niewystarczające.
Airbyte jest szczególnie odpowiedni dla:
Podsumowując, Airbyte to solidne rozwiązanie dla szerokiego grona użytkowników chcących usprawnić integrację danych. Model open source, bogate funkcje i wsparcie społeczności czynią go atrakcyjnym wyborem dla firm chcących efektywnie wykorzystywać swoje dane.
Import.io to platforma integracji danych z internetu, umożliwiająca użytkownikom ekstrakcję, transformację i ładowanie danych z sieci do użytecznych formatów. Produkt pomaga firmom zbierać dane z różnych źródeł online do analiz i podejmowania decyzji. Import.io oferuje rozwiązanie SaaS, które przekształca złożone dane internetowe w struktury takie jak JSON, CSV czy Google Sheets. Funkcjonalność ta jest kluczowa dla firm opierających się na danych w zakresie wywiadu konkurencyjnego, analiz rynkowych i planowania strategicznego. Platforma radzi sobie z wyzwaniami ekstrakcji danych z internetu, takimi jak CAPTCHAs, logowania czy różnorodność struktury stron.
Pozytywne recenzje:
Negatywne recenzje:
Import.io to znakomity wybór dla zespołów marketingowych, firm e-commerce, analityków danych i badaczy, którzy chcą usprawnić zbieranie danych bez specjalistycznej wiedzy technicznej. Przyjazny interfejs i bogate funkcje sprawiają, że nadaje się do wielu zastosowań — od analiz konkurencji, przez badania rynkowe, po monitoring mediów społecznościowych. Import.io wyróżnia się możliwością dostarczania łatwo dostępnych, użytecznych danych internetowych, przy jednoczesnej oszczędności czasu i kosztów operacyjnych.
Ten kompleksowy raport powinien dostarczyć potencjalnym użytkownikom wszystkich niezbędnych informacji do oceny Import.io jako rozwiązania do ekstrakcji danych z internetu.
Patrząc w przyszłość, ekstrakcja danych zmieni się znacząco za sprawą nowych trendów. Modele wykorzystujące AI wytyczają kierunek, zwiększając dokładność i efektywność dzięki uczeniu maszynowemu. Pojawia się także analityka brzegowa, pozwalająca przetwarzać dane tam, gdzie są generowane, co redukuje opóźnienia i ilość przesyłanych danych. Kolejnym trendem jest zwiększanie dostępności danych — AI pomaga przełamywać bariery i umożliwia większej liczbie osób w organizacji dostęp do kluczowych wniosków. Rośnie też nacisk na etyczne praktyki — ekstrakcja danych ma być przejrzysta i szanująca prywatność. W miarę rozwoju tych trendów, kluczowe będzie pozostawanie na bieżąco i elastyczne podejście, aby wykorzystać ekstrakcję danych jako przewagę strategiczną.
Ekstrakcja danych wspierana przez AI zwiększa efektywność dzięki automatyzacji przetwarzania danych, ogranicza błędy ręczne i pozwala obsługiwać duże zbiory danych, umożliwiając firmom lepsze wykorzystanie zasobów do bardziej strategicznych zadań.
Wiodące modele to Haiku od Anthropic AI, który wyróżnia się ekstrakcją danych strukturalnych z HTML, a także modele OpenAI i Llama 3.2, choć model Anthropic najlepiej przestrzegał poleceń dotyczących ekstrakcji strukturalnej.
Najpopularniejsze metody to web scraping, ekstrakcja tekstu, integracja przez API, data mining oraz OCR (optyczne rozpoznawanie znaków), każda dostosowana do określonych typów danych i potrzeb biznesowych.
Najlepsze narzędzia to Docsumo do przetwarzania dokumentów z OCR, Hevo Data i Airbyte do integracji danych bez kodowania oraz Import.io do ekstrakcji i transformacji danych z internetu.
Kluczowe trendy to wzrost wykorzystania AI i uczenia maszynowego dla lepszej dokładności, analityka brzegowa dla szybszego przetwarzania, większa dostępność danych w organizacjach oraz nacisk na etyczne i świadome prywatności praktyki danych.
Inteligentne chatboty i narzędzia AI pod jednym dachem. Połącz intuicyjne bloki, aby zamienić swoje pomysły w zautomatyzowane Flows.
Large Language Model Meta AI (LLaMA) to najnowocześniejszy model przetwarzania języka naturalnego opracowany przez firmę Meta. Dzięki aż 65 miliardom parametrów...

Automatycznie przekształć sitemapę swojej strony (sitemap.xml) w format dokumentacji przyjazny dla LLM. Ten konwerter oparty na AI wyodrębnia, przetwarza i stru...

Poznaj najlepsze modele dużych języków (LLM) do kodowania w czerwcu 2025 roku. Ten kompletny przewodnik edukacyjny dostarcza wiedzy, porównań i praktycznych wsk...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.