
Generowanie tekstu
Generowanie tekstu za pomocą dużych modeli językowych (LLM) odnosi się do zaawansowanego wykorzystania modeli uczenia maszynowego do tworzenia tekstu podobnego ...
6 min czytania
AI
Text Generation
+5

FlowHunt testuje i ocenia wiodące LLM-y – w tym GPT-4, Claude 3, Llama 3 i Grok – pod kątem pisania treści, analizując czytelność, ton, oryginalność i użycie słów kluczowych, aby pomóc Ci wybrać najlepszy model do Twoich potrzeb.
Duże modele językowe (LLM-y) to nowoczesne narzędzia AI, które zmieniają sposób tworzenia i konsumowania treści. Zanim przejdziemy do różnic między poszczególnymi LLM-ami, warto wiedzieć, co sprawia, że te modele tak łatwo generują tekst zbliżony do ludzkiego.
LLM-y są trenowane na ogromnych zbiorach danych, co pozwala im zrozumieć kontekst, semantykę i składnię. Dzięki ilości danych potrafią poprawnie przewidywać kolejne słowa w zdaniu, układając je w spójną całość. Jednym z kluczowych elementów skuteczności jest architektura transformer. Ten mechanizm samo-uwagi wykorzystuje sieci neuronowe do przetwarzania składni i znaczenia tekstu. Dzięki temu LLM-y radzą sobie z szerokim zakresem złożonych zadań.
Duże modele językowe (LLM-y) zrewolucjonizowały podejście firm do tworzenia treści. Dzięki zdolności do generowania spersonalizowanych i zoptymalizowanych tekstów, LLM-y tworzą takie materiały jak e-maile, strony docelowe czy posty w mediach społecznościowych na podstawie poleceń napisanych ludzkim językiem.
Oto jak LLM-y mogą pomóc autorom treści:
Co więcej, przyszłość LLM-ów rysuje się obiecująco. Postęp technologiczny prawdopodobnie poprawi ich precyzję i możliwości multimodalne. Rozszerzenie zastosowań znacząco wpłynie na wiele branż.
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Oto szybki przegląd popularnych LLM-ów, które będziemy testować:
| Model | Unikalne mocne strony |
|---|---|
| GPT-4 | Uniwersalny w różnych stylach pisania |
| Claude 3 | Świetny w kreatywnych i kontekstowych zadaniach |
| Llama 3.2 | Znany z efektywnego podsumowywania tekstu |
| Grok | Znany z luźnego i humorystycznego tonu |
Wybierając LLM, należy wziąć pod uwagę swoje potrzeby w zakresie tworzenia treści. Każdy model oferuje coś wyjątkowego – od obsługi złożonych zadań po generowanie kreatywnych pomysłów AI. Zanim je przetestujemy, podsumujmy krótko każdy z nich, aby zobaczyć, jak może wesprzeć Twój proces tworzenia treści.
Kluczowe cechy:
Wydajność:
Mocne strony:
Wyzwania:
Podsumowując, GPT-4 to potężne narzędzie dla firm chcących ulepszyć strategie tworzenia treści i analizy danych.
Kluczowe cechy:
Mocne strony:
Wyzwania:
Kluczowe cechy:
Mocne strony:
Wyzwania:
Llama 3 wyróżnia się jako solidny i wszechstronny open-source’owy LLM, zapowiadając postęp w możliwościach AI, ale stawia też przed użytkownikami pewne wyzwania.
Kluczowe cechy:
Mocne strony:
Wyzwania:
Podsumowując, choć xAI Grok oferuje ciekawe funkcje i medialną rozpoznawalność, mierzy się z dużą konkurencją i wyzwaniami na rynku modeli językowych.
Przechodzimy do testów! Oceńmy modele na podstawie typowego zlecenia blogowego. Wszystkie testy wykonano w FlowHunt, zmieniając tylko modele LLM.
Główne kryteria oceny:
Polecenie testowe:
Napisz wpis na bloga zatytułowany “10 prostych sposobów na życie w duchu zrównoważonego rozwoju bez dużych wydatków”. Ton powinien być praktyczny i przystępny, z naciskiem na konkretne, realne porady dla zabieganych osób. Wyróżnij frazę “zrównoważony rozwój z budżetem” jako główne słowo kluczowe. Dodaj przykłady z codziennych sytuacji, np. zakupy spożywcze, korzystanie z energii, nawyki osobiste. Zakończ zachętą do wdrożenia choć jednej rady już dziś.
Uwaga: Flow generuje wyłącznie wyniki do ok. 500 słów. Jeśli wydają się powierzchowne lub niezbyt pogłębione, to celowy zabieg.
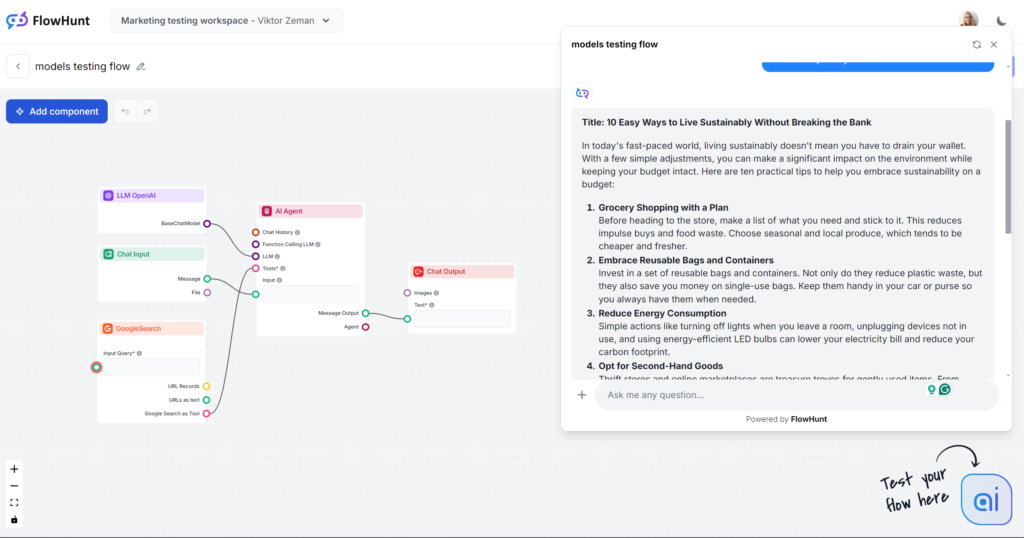
W ślepym teście już po zdaniu otwierającym „W dzisiejszym zabieganym świecie…” rozpoznasz ten model. Jego styl jest powszechnie znany, bo to nie tylko najczęściej wybierana opcja, ale i podstawa większości narzędzi AI do pisania. GPT-4o to zawsze bezpieczny wybór do ogólnych treści, ale trzeba liczyć się z rozwlekłością i ogólnikami.
Ton i język
Pomijając oklepane zdanie wstępne, GPT-4o zrobił dokładnie to, czego się spodziewaliśmy. Nikt nie uwierzy, że to dzieło człowieka, ale artykuł jest przyzwoicie ułożony i w pełni realizuje polecenie. Ton rzeczywiście jest praktyczny i przystępny, od razu skupiając się na konkretnych poradach zamiast lania wody.
Użycie słów kluczowych
GPT-4o dobrze wypadł w teście słów kluczowych. Nie tylko użył głównego słowa kluczowego, ale także podobnych fraz czy innych odpowiednich wyrażeń.
Czytelność
W skali Flescha-Kincaida wynik to poziom 10–12 klasy (dość trudny) – 51,2 pkt. Jeszcze jeden punkt mniej i byłby to już poziom studiów. Przy tak krótkim tekście nawet samo słowo „zrównoważony rozwój” może wyraźnie wpływać na czytelność. Nadal jest jednak sporo miejsca na poprawę.
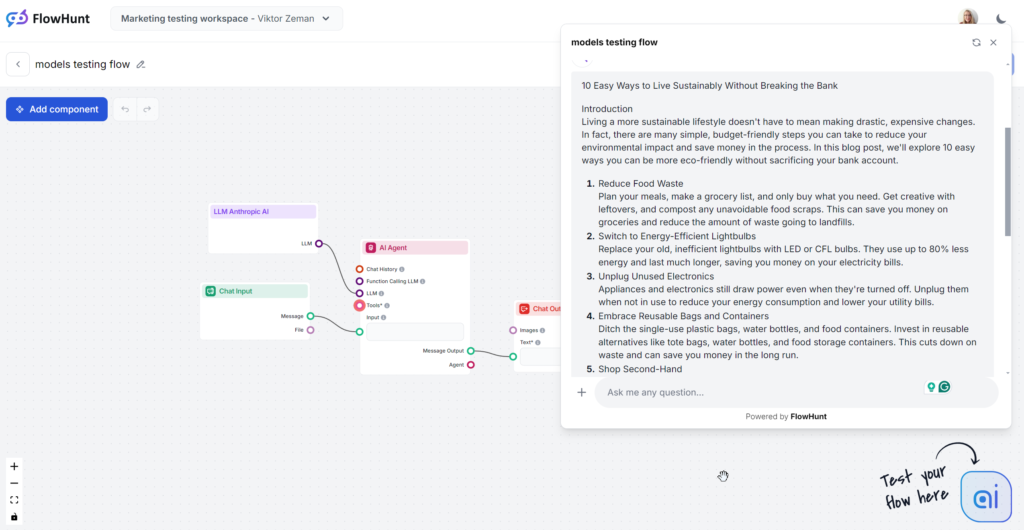
Testowany wariant Claude to model Sonnet ze „środka stawki”, który uchodzi za najlepszy do treści. Artykuł czyta się dobrze i brzmi bardziej po ludzku niż teksty GPT-4o czy Llamy. Claude to idealne rozwiązanie, gdy zależy Ci na czystych, prostych treściach i efektywnym przekazie – bez rozwlekłości GPT czy efekciarstwa Groka.
Ton i język
Claude wyróżnia się prostotą, przystępnością i „ludzkimi” odpowiedziami. Ton jest praktyczny i natychmiast przechodzi do konkretnych porad.
Użycie słów kluczowych
Claude jako jedyny zignorował w poleceniu frazę kluczową – użył jej tylko w 1 z 3 wygenerowanych tekstów. Nawet wtedy pojawiła się dopiero w zakończeniu i brzmiała nieco wymuszenie.
Czytelność
Sonnet Claude’a osiągnął wysoki wynik w skali Flescha-Kincaida – 8–9 klasa (prosty angielski), tylko kilka punktów za Grokiem. Podczas gdy Grok zmienił cały ton i słownictwo, by to osiągnąć, Claude użył podobnych słów jak GPT-4o. Co poprawiło czytelność? Krótsze zdania, codzienne słowa, brak lania wody.
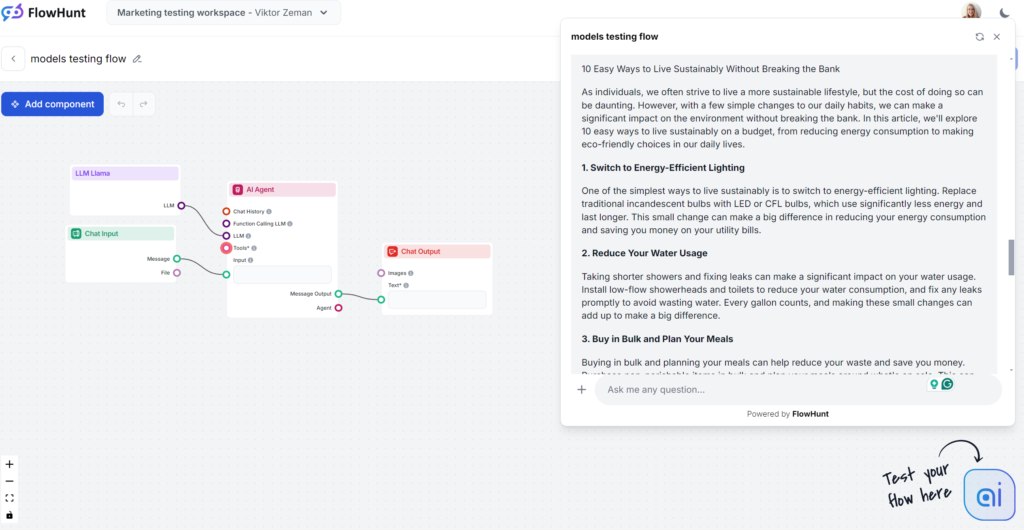
Najmocniejszą stroną Llamy było użycie słów kluczowych. Styl pisania był z kolei mało inspirujący i lekko rozwlekły, ale i tak mniej nużący niż GPT-4o. Llama to kuzyn GPT-4o – bezpieczny wybór z nieco rozwlekłym i ogólnikowym stylem. To świetna opcja, jeśli ogólnie lubisz styl modeli OpenAI, ale chcesz uniknąć typowych fraz GPT.
Ton i język
Artykuły generowane przez Llamę brzmią podobnie jak te od GPT-4o. Rozwlekłość i ogólnikowość są porównywalne, ale ton jest praktyczny i przystępny.
Użycie słów kluczowych
Meta zwycięża w teście słów kluczowych. Llama użyła frazy kluczowej więcej niż raz, również we wstępie, oraz naturalnie wplotła podobne wyrażenia.
Czytelność
W skali Flescha-Kincaida wynik to 10–12 klasa (dość trudny), 53,4 pkt – nieco lepiej niż GPT-4o (51,2). Przy tak krótkim tekście nawet samo słowo „zrównoważony rozwój” może wpływać na czytelność. Nadal można to poprawić.
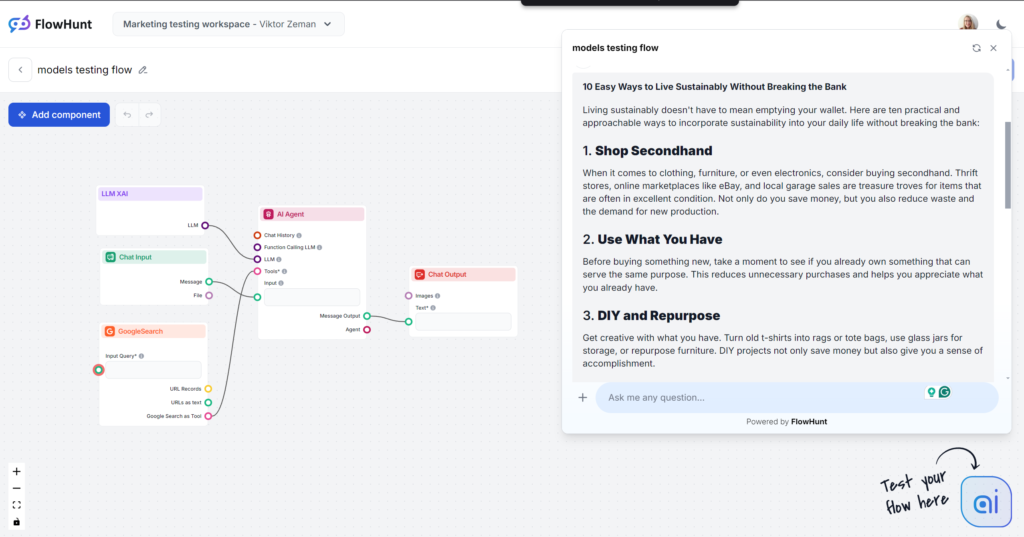
Grok był ogromnym zaskoczeniem, zwłaszcza jeśli chodzi o ton i język. Dzięki naturalnemu i swobodnemu stylowi masz wrażenie, że dostajesz szybkie porady od dobrego znajomego. Jeśli lubisz styl swobodny i zadziorny – Grok to Twój wybór.
Ton i język
Tekst czyta się świetnie. Język jest naturalny, zdania krótkie, Grok dobrze wykorzystuje idiomy. Model trzyma się swojego podstawowego tonu i przesuwa granicę „ludzkiego” tekstu. Uwaga: swobodny styl Groka nie zawsze sprawdzi się w B2B i treściach SEO.
Użycie słów kluczowych
Grok użył frazy kluczowej, o którą prosiliśmy, ale tylko w podsumowaniu. Inne modele lepiej umieściły słowa kluczowe i dodały trafne wyrażenia, a Grok bardziej skupił się na płynności języka.
Czytelność
Dzięki luźnemu językowi Grok uzyskał świetny wynik w skali Flescha-Kincaida – 61,4 pkt, czyli 7–8 klasa (prosty angielski). To optymalne dla udostępniania tematu szerokiemu odbiorcy. Ta różnica w czytelności jest wręcz namacalna.
Otrzymuj najnowsze wskazówki, trendy i oferty za darmo.
Siła LLM-ów wynika z jakości danych treningowych, które bywają stronnicze lub nieprecyzyjne, co może prowadzić do szerzenia dezinformacji. Kluczowe jest więc weryfikowanie i sprawdzanie treści generowanych przez AI pod kątem rzetelności i inkluzywności. Testując różne modele, pamiętaj, że każdy z nich inaczej podchodzi do prywatności danych wejściowych i ograniczania szkodliwych wyników.
Aby stosować LLM-y etycznie, organizacje powinny wdrożyć zasady dotyczące prywatności, ograniczania stronniczości i moderacji treści. Wymaga to regularnej współpracy między twórcami AI, autorami treści i prawnikami. Oto lista najważniejszych zagadnień etycznych:
Wybór LLM-ów powinien być zgodny z wytycznymi etycznymi organizacji. Zarówno modele open-source, jak i komercyjne należy oceniać pod kątem potencjalnych nadużyć.
Stronniczość, nieścisłości i halucynacje to główne problemy generowanych przez AI treści. Przez wbudowane wytyczne często prowadzi to do ogólnikowych, mało wartościowych wyników LLM-ów. Firmy często muszą wdrażać dodatkowe szkolenia i zabezpieczenia, by sobie z tym poradzić. Dla małych biznesów czas i zasoby na własne trenowanie modeli są poza zasięgiem. Alternatywą jest korzystanie z modeli ogólnych przez narzędzia takie jak FlowHunt.
FlowHunt pozwala dodać wybrane zasoby wiedzy, dostęp do internetu i nowe możliwości klasycznym bazowym modelom. Dzięki temu możesz dobrać odpowiedni model do zadania – bez ograniczeń modelu bazowego ani konieczności opłacania wielu subskrypcji.
Kolejnym problemem jest złożoność tych modeli. Liczące miliardy parametrów, bywają trudne w zarządzaniu, zrozumieniu i debugowaniu. FlowHunt daje znacznie większą kontrolę niż zwykła rozmowa z AI – możesz budować własne narzędzia AI z gotowych bloków i dostrajać je do swoich potrzeb.
Przyszłość modeli językowych (LLM-ów) w tworzeniu treści zapowiada się obiecująco i ekscytująco. Wraz z rozwojem modeli wzrośnie ich precyzja oraz zmniejszy się liczba błędów i stronniczości. Oznacza to, że twórcy będą mogli generować rzetelny, ludzko brzmiący tekst dzięki AI.
LLM-y nie będą ograniczone tylko do tekstu – staną się biegłe w tworzeniu treści multimodalnych, zarządzając zarówno tekstem, jak i obrazami, co otworzy nowe możliwości dla branż kreatywnych. Dzięki większym i lepiej filtrowanym zbiorom danych LLM-y będą tworzyć bardziej wiarygodne treści i udoskonalać styl pisania.
Jednak obecnie LLM-y nie są w stanie tego zrobić samodzielnie, a te możliwości są podzielone między różne firmy i modele, które konkurują o Twoją uwagę i środki. FlowHunt zbiera je wszystkie i pozwala…
GPT-4 jest najpopularniejszy i najbardziej uniwersalny do ogólnych treści, ale Llama od Meta oferuje świeższy styl pisania. Claude 3 sprawdza się najlepiej przy czystych, prostych treściach, natomiast Grok wyróżnia się swobodnym, naturalnym tonem. Najlepszy wybór zależy od Twoich celów i preferencji stylistycznych.
Warto zwrócić uwagę na czytelność, ton, oryginalność, użycie słów kluczowych oraz dopasowanie modelu do Twoich potrzeb. Weź też pod uwagę mocne strony, takie jak kreatywność, uniwersalność gatunkowa czy potencjał integracji oraz wyzwania, jak stronniczość, rozwlekłość czy wymagania sprzętowe.
FlowHunt pozwala testować i porównywać wiele wiodących LLM-ów w jednym środowisku, dając kontrolę nad wynikami i umożliwiając znalezienie najlepszego modelu dla Twojego procesu tworzenia treści bez potrzeby wielu subskrypcji.
Tak. LLM-y mogą utrwalać stronniczość, generować dezinformację i rodzić obawy dotyczące prywatności danych. Konieczne jest sprawdzanie faktów generowanych przez AI, ocena modeli pod kątem zgodności etycznej i ustalenie zasad odpowiedzialnego użytkowania.
Przyszłe LLM-y będą oferować większą precyzję, mniejszą stronniczość i multimodalne generowanie treści (tekst, obrazy itp.), umożliwiając twórcom tworzenie bardziej wiarygodnych i kreatywnych materiałów. Zintegrowane platformy, jak FlowHunt, uproszczą dostęp do tych zaawansowanych możliwości.
Przetestuj najlepsze LLM-y obok siebie i usprawnij proces pisania treści dzięki zintegrowanej platformie FlowHunt.
Generowanie tekstu za pomocą dużych modeli językowych (LLM) odnosi się do zaawansowanego wykorzystania modeli uczenia maszynowego do tworzenia tekstu podobnego ...
Duży model językowy (LLM) to rodzaj sztucznej inteligencji, trenowany na ogromnych zbiorach tekstowych, aby rozumieć, generować i przetwarzać ludzki język. LLM-...

Poznaj kluczowe wymagania GPU dla dużych modeli językowych (LLM), w tym różnice między treningiem a inferencją, specyfikacje sprzętowe i jak wybrać odpowiednią ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.