Inżynieria kontekstu: Ostateczny przewodnik 2025 do mistrzostwa w projektowaniu systemów AI
Zanurz się głęboko w inżynierię kontekstu dla AI. Ten przewodnik obejmuje kluczowe zasady, od promptów i kontekstu po zaawansowane strategie jak zarządzanie pamięcią, zanikanie kontekstu i projektowanie multi-agentowe.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Krajobraz rozwoju AI przeszedł głęboką transformację. Tam, gdzie kiedyś obsesyjnie dopracowywaliśmy pojedynczy prompt, dziś mierzymy się z o wiele bardziej złożonym wyzwaniem: budowaniem całych architektur informacji, które otaczają i wspierają nasze modele językowe.
Ta zmiana oznacza ewolucję od inżynierii promptów do inżynierii kontekstu — i stanowi przyszłość praktycznego rozwoju AI. Systemy przynoszące dziś realną wartość nie polegają na magicznych promptach. Sukces zawdzięczają temu, że ich architekci nauczyli się orkiestracji kompleksowych ekosystemów informacji.
Andrej Karpathy doskonale oddał tę ewolucję, opisując inżynierię kontekstu jako staranną praktykę wypełniania okna kontekstu dokładnie właściwą informacją w odpowiednim momencie. To pozornie proste stwierdzenie ujawnia fundamentalną prawdę: LLM nie jest już gwiazdą spektaklu. To kluczowy komponent starannie zaprojektowanego systemu, w którym każda informacja — każdy fragment pamięci, każdy opis narzędzia, każdy pobrany dokument — został celowo umieszczony, by zmaksymalizować efekty.
Czym jest inżynieria kontekstu?
Perspektywa historyczna
Korzenie inżynierii kontekstu sięgają głębiej, niż się wydaje. Choć główna dyskusja o inżynierii promptów wybuchła w latach 2022–2023, podstawowe koncepcje inżynierii kontekstu pojawiły się ponad dwie dekady temu w badaniach nad komputerami wszędobylskimi i interakcją człowiek–komputer.
W 2001 r. Anind K. Dey sformułował definicję, która okazała się niezwykle trafna: kontekst to każda informacja pomagająca scharakteryzować sytuację encji. Ta wczesna koncepcja położyła fundament pod sposób, w jaki myślimy o maszynowym rozumieniu środowisk.
Ewolucja inżynierii kontekstu przebiegała w kilku fazach, kształtowanych przez postępy w inteligencji maszynowej:
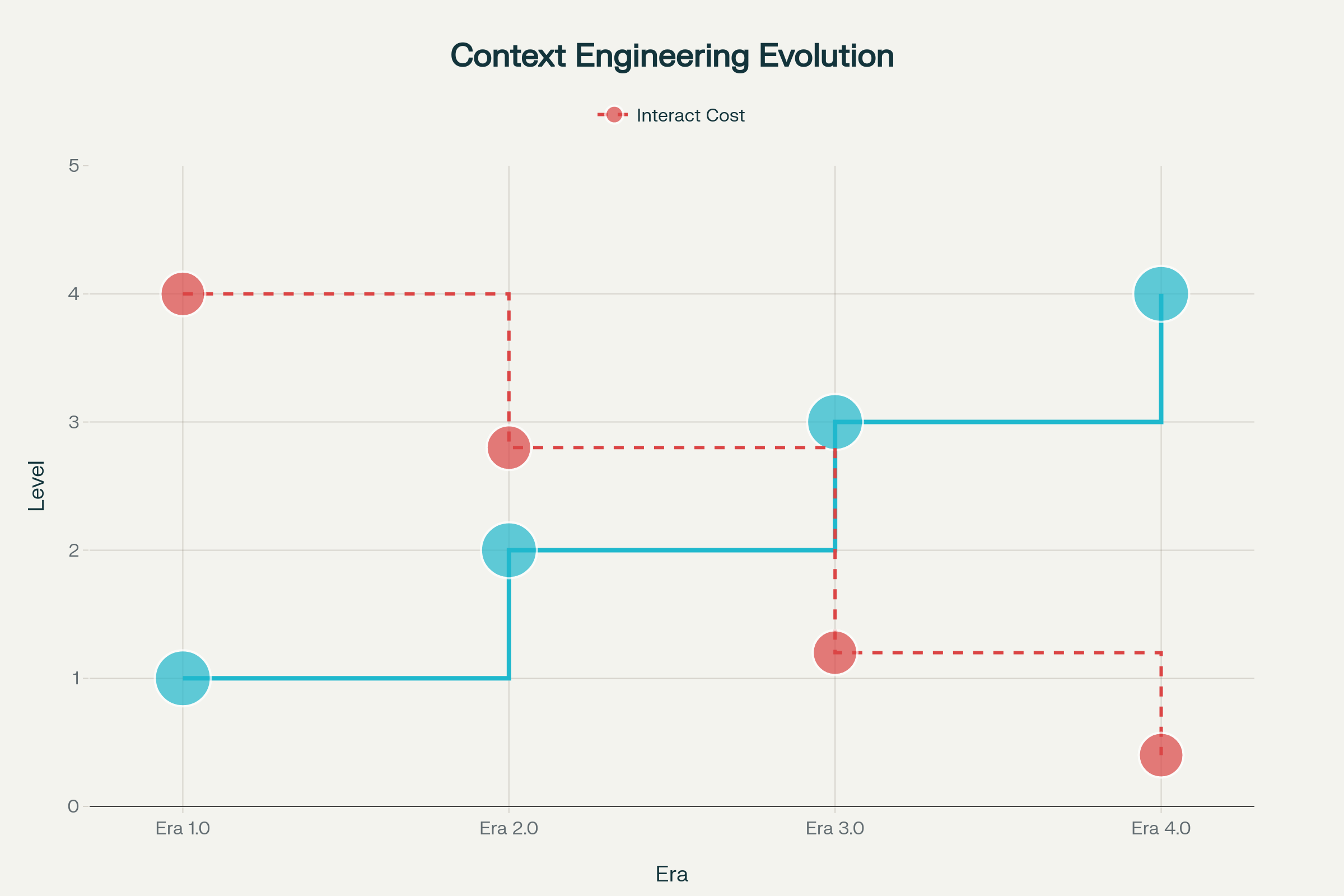
Era 1.0: Prymitywne obliczenia (lata 90.–2020) — W tym długim okresie maszyny radziły sobie wyłącznie z danymi strukturalnymi i podstawowymi sygnałami środowiskowymi. Ludzie ponosili pełen ciężar tłumaczenia kontekstu na formaty zrozumiałe dla maszyn. Przykłady: aplikacje desktopowe, aplikacje mobilne z wejściami sensorów, wczesne chatboty z sztywnymi drzewami odpowiedzi.
Era 2.0: Inteligencja zorientowana na agenta (2020–teraz) — Premiera GPT-3 w 2020 r. wywołała zmianę paradygmatu. Duże modele językowe przyniosły rzeczywiste rozumienie języka naturalnego i zdolność do pracy z ukrytymi intencjami. Era ta umożliwiła autentyczną współpracę człowiek–agent, w której dwuznaczność i niepełne informacje stały się zarządzalne dzięki zaawansowanej interpretacji języka i uczeniu w kontekście.
Era 3.0 i 4.0: Inteligencja ludzka i nadludzka (przyszłość) — Nadchodzące fale to systemy zdolne do przetwarzania informacji o wysokiej entropii z ludzką płynnością, a w końcu wychodzące poza reakcję na bodźce, by proaktywnie budować kontekst i wskazywać potrzeby, których użytkownik nie był nawet świadomy.
Ewolucja inżynierii kontekstu przez cztery ery: od prymitywnych obliczeń do nadludzkiej inteligencji
Formalna definicja
U podstaw inżynieria kontekstu to systematyczna dyscyplina projektowania i optymalizacji przepływu informacji kontekstowych przez systemy AI — od początkowego pozyskania przez przechowywanie, zarządzanie, aż po ostateczne wykorzystanie w celu poprawy zrozumienia maszyn i realizacji zadań.
Można to zapisać matematycznie jako funkcję transformacji:
$CE: (C, T) \rightarrow f_{context}$
gdzie:
C oznacza surowe informacje kontekstowe (encje i ich cechy)
T to docelowe zadanie lub domena aplikacji
f_{context} daje wynikową funkcję przetwarzania kontekstu
Rozłożenie tego na praktyczne operacje ujawnia cztery podstawowe działania:
Zbieranie istotnych sygnałów kontekstowych przez różnorodne sensory i kanały informacji
Przechowywanie tych informacji efektywnie w systemach lokalnych, infrastrukturze sieciowej i chmurze
Zarządzanie złożonością przez inteligentne przetwarzanie tekstu, wejść multimodalnych i złożonych relacji
Wykorzystanie kontekstu strategicznie przez filtrację według istotności, współdzielenie między systemami i adaptację do wymagań użytkownika
Dlaczego inżynieria kontekstu jest ważna: Ramy redukcji entropii
Inżynieria kontekstu rozwiązuje fundamentalną asymetrię w komunikacji człowiek–maszyna. Gdy ludzie rozmawiają, bez wysiłku wypełniają luki dzięki wspólnej wiedzy kulturowej, inteligencji emocjonalnej i świadomości sytuacyjnej. Maszyny nie mają żadnej z tych umiejętności.
Ta luka objawia się jako entropia informacji. Komunikacja ludzka jest wydajna, bo możemy zakładać ogromne ilości wspólnego kontekstu. Maszyny wymagają, aby wszystko było jawnie reprezentowane. Inżynieria kontekstu to w gruncie rzeczy wstępne przetwarzanie kontekstu dla maszyn — kompresja złożoności i wysokiej entropii ludzkich intencji i sytuacji do reprezentacji niskoentropijnych, zrozumiałych dla maszyn.
Wraz z rozwojem inteligencji maszynowej, ta redukcja entropii staje się coraz bardziej zautomatyzowana. Dziś, w Erze 2.0, inżynierowie muszą ręcznie orkiestrwać większość tej redukcji. W Erze 3.0 i później maszyny przejmą coraz więcej tego ciężaru. Jednak główne wyzwanie pozostanie niezmienne: zbudowanie mostu między złożonością ludzką a rozumieniem maszyn.
Inżynieria promptów vs inżynieria kontekstu: Kluczowe różnice
Częsty błąd polega na utożsamianiu tych dwóch dyscyplin. W rzeczywistości reprezentują one fundamentalnie różne podejścia do architektury systemów AI.
Inżynieria promptów skupia się na tworzeniu pojedynczych instrukcji lub zapytań, by kształtować zachowanie modelu. Chodzi o optymalizację struktury językowej tego, co komunikujemy modelowi — frazowania, przykładów i wzorców rozumowania w pojedynczej interakcji.
Inżynieria kontekstu to kompleksowa dyscyplina systemowa zarządzająca wszystkim, co model napotyka podczas inferencji — w tym promptami, ale też pobranymi dokumentami, systemami pamięci, opisami narzędzi, informacją o stanie i wieloma innymi elementami.
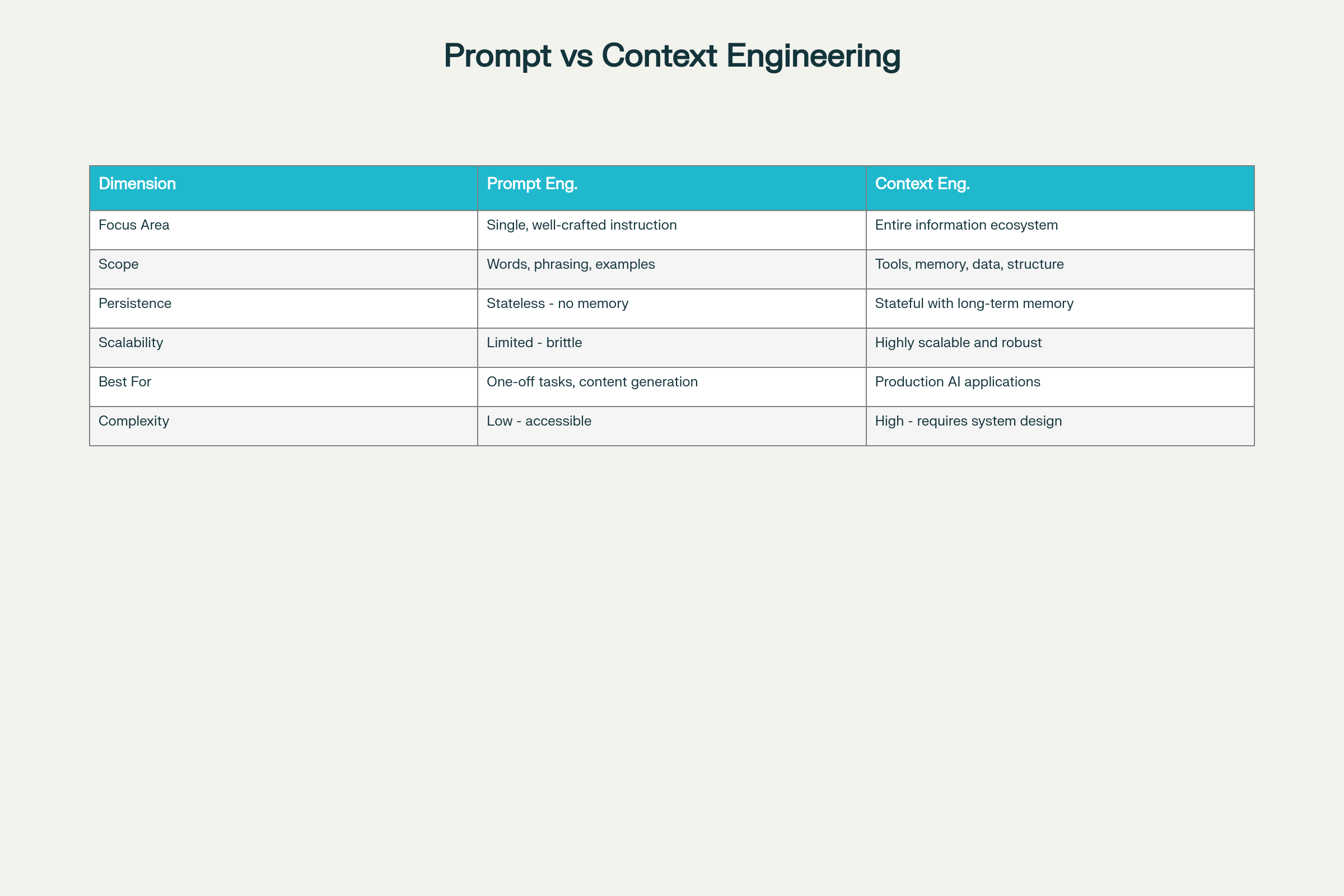
Inżynieria promptów vs inżynieria kontekstu: Kluczowe różnice i kompromisy
Rozważ tę różnicę: Poproszenie ChatGPT o napisanie profesjonalnego maila to inżynieria promptów. Zbudowanie platformy obsługi klienta, która zachowuje historię rozmów przez wiele sesji, uzyskuje dostęp do konta użytkownika i pamięta poprzednie zgłoszenia — to już inżynieria kontekstu.
Kluczowe różnice w ośmiu wymiarach:
Wymiar
Inżynieria promptów
Inżynieria kontekstu
Obszar skupienia
Optymalizacja pojedynczej instrukcji
Kompleksowy ekosystem informacji
Zakres
Słowa, frazowanie, przykłady
Narzędzia, pamięć, architektura danych, struktura
Trwałość
Bezustannie — brak retencji pamięci
Stanowy z pamięcią długoterminową
Skalowalność
Ograniczona i krucha na dużą skalę
Wysoko skalowalna i odporna
Najlepsze dla
Zadania jednorazowe, generacja treści
Produkcyjne aplikacje AI
Złożoność
Niski próg wejścia
Wysoka — wymaga wiedzy z zakresu projektowania systemów
Niezawodność
Nieprzewidywalna na dużą skalę
Spójna i godna zaufania
Utrzymanie
Wrażliwa na zmiany wymagań
Modularna i łatwa w utrzymaniu
Kluczowy wniosek: Produkcyjne aplikacje LLM wymagają przede wszystkim inżynierii kontekstu, a nie tylko sprytnie napisanych promptów. Jak zauważyła Cognition AI, inżynieria kontekstu stała się de facto główną odpowiedzialnością inżynierów budujących agentów AI.
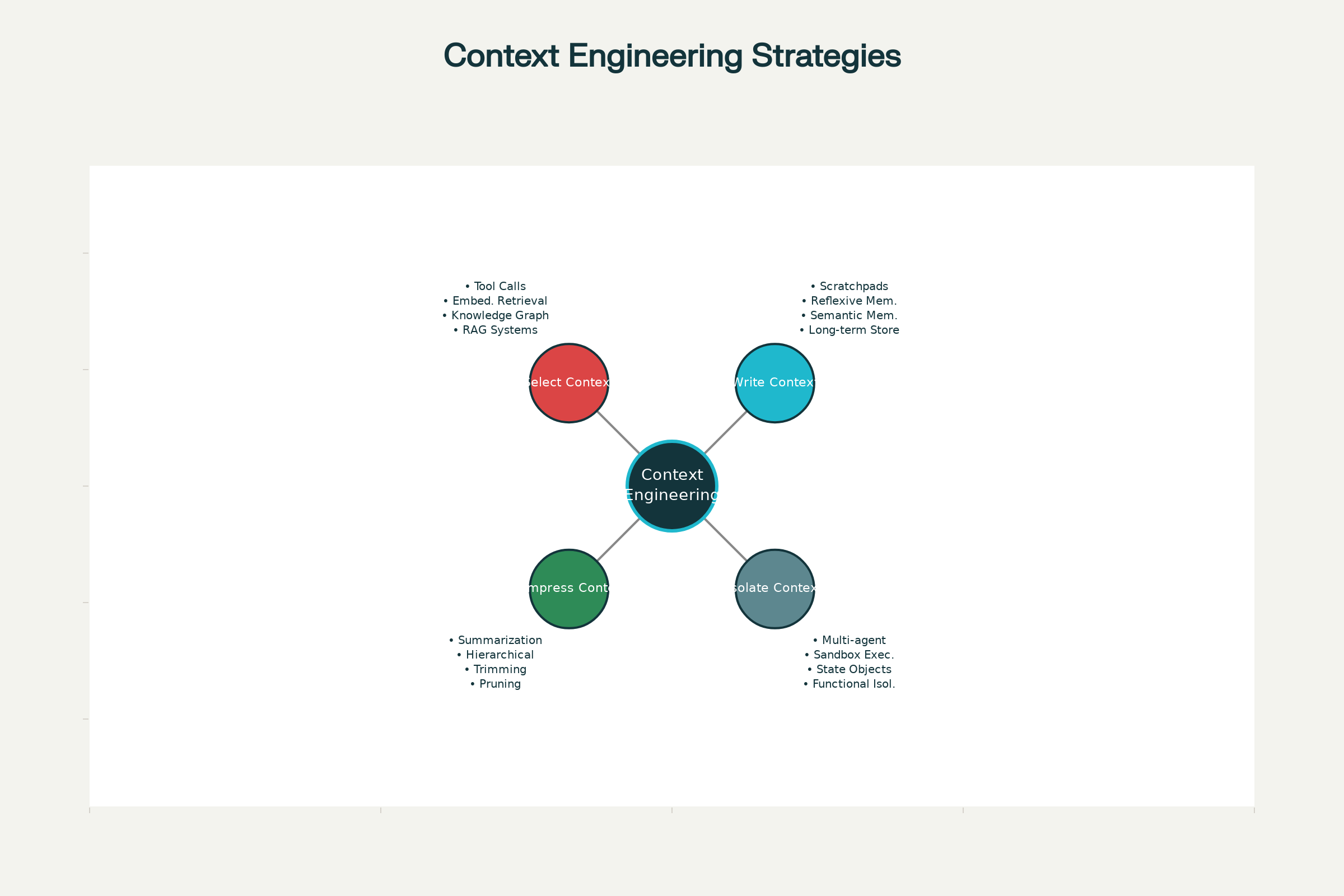
Cztery podstawowe strategie inżynierii kontekstu
We wszystkich wiodących systemach AI — od Claude i ChatGPT po wyspecjalizowanych agentów z Anthropic i innych laboratoriów — wykrystalizowały się cztery podstawowe strategie skutecznego zarządzania kontekstem. Można je stosować samodzielnie lub łączyć dla lepszego efektu.
1. Zapisuj kontekst: utrwalanie informacji poza oknem kontekstu
Zasada bazowa jest elegancko prosta: nie zmuszaj modelu do zapamiętania wszystkiego. Zamiast tego utrwalaj kluczowe informacje poza oknem kontekstu, by można je było niezawodnie odzyskać w razie potrzeby.
Notatniki (scratchpads) to najbardziej intuicyjna implementacja. Tak jak ludzie zapisują notatki podczas rozwiązywania złożonych problemów, agenci AI korzystają z notatników, by zachować informacje na przyszłość. Implementacja może być prosta — narzędzie do zapisywania notatek — lub zaawansowana — pola w obiekcie stanu, które trwają przez kolejne kroki wykonania.
Badania multi-agentowe Anthropic pięknie to ilustrują: LeadResearcher zaczyna od sformułowania podejścia i zapisania planu do Memory dla trwałości, wiedząc, że jeśli okno kontekstu przekroczy 200 000 tokenów, nastąpi obcięcie i plan musi być zachowany.
Wspomnienia (memories) rozciągają koncepcję notatnika na wiele sesji. Zamiast przechwytywać informacje tylko w obrębie jednego zadania (pamięć sesyjna), systemy mogą budować pamięci długoterminowe, które utrzymują się i ewoluują przez wiele interakcji użytkownik–agent. Ten wzorzec jest już standardem w produktach takich jak ChatGPT, Claude Code, Cursor i Windsurf.
Inicjatywy badawcze jak Reflexion pioniersko wprowadziły refleksyjne wspomnienia — agent podsumowuje każdą turę i generuje wspomnienia na przyszłość. Generative Agents poszli dalej, okresowo syntetyzując wspomnienia z kolekcji wcześniejszych informacji zwrotnych.
Trzy typy pamięci:
Epizodyczna: Konkretne przykłady wcześniejszych zachowań lub interakcji (nieocenione dla few-shot learning)
Proceduralna: Instrukcje lub reguły działania (zapewniając spójność)
Semantyczna: Fakty i relacje o świecie (zapewniające ugruntowaną wiedzę)
2. Wybieraj kontekst: przyciąganie właściwych informacji
Gdy informacja jest utrwalona, agent musi pobrać tylko to, co istotne dla bieżącego zadania. Zły wybór może być równie szkodliwy, jak brak pamięci — nieistotne dane mogą wprowadzać model w błąd lub wywoływać halucynacje.
Mechanizmy wyboru pamięci:
Prostsze podejścia stosują wąskie, zawsze dostępne pliki. Claude Code korzysta z pliku CLAUDE.md dla pamięci proceduralnych, a Cursor i Windsurf używają plików rules. Jednak ta metoda nie radzi sobie na dużą skalę, gdy agent gromadzi setki faktów i relacji.
Przy większych kolekcjach pamięci stosuje się wyszukiwanie oparte na embeddingach i grafy wiedzy. System przekształca zarówno wspomnienia, jak i bieżące zapytanie na reprezentacje wektorowe, a następnie pobiera najbardziej semantycznie podobne wspomnienia.
Jednak — jak pokazał Simon Willison na AIEngineer World’s Fair — to podejście może spektakularnie zawodzić. ChatGPT niespodziewanie wstawił jego lokalizację z pamięci do wygenerowanego obrazu, pokazując, że nawet zaawansowane systemy mogą pobierać wspomnienia niewłaściwie. To dowód, że inżynieria jest niezbędna.
Wybór narzędzi to osobny problem. Gdy agenci mają dostęp do dziesiątek lub setek narzędzi, samo ich wyliczenie może wprowadzać zamieszanie — zachodzące na siebie opisy sprawiają, że modele wybierają niewłaściwe narzędzia. Skuteczne rozwiązanie: zastosować zasady RAG do opisów narzędzi. Pobierając tylko semantycznie adekwatne narzędzia, systemy osiągnęły trzykrotną poprawę skuteczności wyboru narzędzi.
Pobieranie wiedzy to prawdopodobnie najbogatszy obszar problemowy. Agenci kodu są tego przykładem w warunkach produkcyjnych. Inżynier Windsurf zauważył, że indeksowanie kodu nie równa się efektywnemu pobieraniu kontekstu. Stosują indeksowanie, wyszukiwanie embeddingowe z analizą AST i chunkingiem według semantycznych granic. Jednak wyszukiwanie embeddingowe traci niezawodność wraz ze wzrostem bazy kodu. Sukces wymaga połączenia technik takich jak grep/wyszukiwanie plików, pobieranie przez grafy wiedzy i reranking, gdzie kontekst jest oceniany według trafności.
3. Kompresuj kontekst: zachowuj tylko to, co niezbędne
Przy zadaniach długoterminowych kontekst narasta naturalnie. Notatki, wyniki narzędzi i historia interakcji szybko przekraczają okno kontekstu. Strategie kompresji rozwiązują ten problem, inteligentnie destylując informacje, zachowując to, co ważne.
Podsumowanie (summarization) to główna technika. Claude Code stosuje “auto-compact” — gdy okno kontekstu osiąga 95% pojemności, podsumowuje całą trajektorię interakcji użytkownik–agent. Można stosować różne strategie:
Podsumowanie hierarchiczne: Generowanie podsumowań na różnych poziomach abstrakcji
Podsumowanie ukierunkowane: Kompresja konkretnych komponentów (np. wyników wyszukiwania zajmujących wiele tokenów), a nie całego kontekstu
Cognition AI ujawniło, że używają modeli fine-tuned do podsumowań na granicach agent–agent, by ograniczyć liczbę tokenów podczas przekazywania wiedzy — co pokazuje, jak głęboka może być ta inżynieria.
Przycinanie kontekstu (context trimming) to metoda komplementarna. Zamiast używać LLM do inteligentnego podsumowania, przycinanie po prostu usuwa fragmenty według ustalonych heurystyk — starsze wiadomości, filtrowanie według wagi lub prunery trenowane jak Provence do zadań QA.
Kluczowy wniosek: To, co usuwasz, może być równie ważne jak to, co zostawiasz. Skupiony kontekst 300-tokenowy często daje lepsze rezultaty niż nieskupiony kontekst 113 000-tokenowy w zadaniach konwersacyjnych.
4. Izoluj kontekst: rozdzielanie informacji między systemami
Wreszcie strategie izolacji uznają, że różne zadania wymagają różnych informacji. Zamiast upychać cały kontekst do okna pojedynczego modelu, techniki izolacji dzielą kontekst między wyspecjalizowane systemy.
Architektury multi-agentowe są tu najpowszechniejsze. Biblioteka OpenAI Swarm została zaprojektowana wokół “separacji zagadnień” — wyspecjalizowane sub-agenty obsługują konkretne zadania z własnymi narzędziami, instrukcjami i oknami kontekstu.
Badania Anthropic pokazują siłę tego podejścia: wiele agentów z izolowanymi kontekstami przewyższało implementacje jednoagentowe, głównie dlatego, że każde okno kontekstu subagenta można było dopasować do wąskiego podzadania. Subagenci pracują równolegle z własnymi oknami kontekstu, eksplorując różne aspekty pytania jednocześnie.
Jednak systemy multi-agentowe mają swoje kompromisy. Anthropic raportował nawet piętnastokrotnie większe zużycie tokenów niż czat jednoagentowy. To wymaga starannej orkiestracji, inżynierii promptów do planowania i zaawansowanych mechanizmów koordynacji.
Piaskownice (sandbox environments) to inna strategia izolacji. CodeAgent od HuggingFace pokazuje: zamiast zwracać JSON, który model musi zinterpretować, agent generuje kod wykonywany w piaskownicy. Wybrane wyjścia (wartości zwrotne) są przekazywane do LLM, trzymając obiekty zajmujące wiele tokenów poza środowiskiem modelu. To rozwiązanie sprawdza się przy danych wizualnych i audio.
Izolacja obiektu stanu to prawdopodobnie najbardziej niedoceniana technika. Stan uruchomieniowy agenta może być zaprojektowany jako struktura (np. model Pydantic) z wieloma polami. Jedno pole (np. messages) jest eksponowane do LLM na każdym kroku, inne są izolowane do selektywnego użytku. To daje precyzyjną kontrolę bez złożoności architektonicznej.
Cztery podstawowe strategie skutecznej inżynierii kontekstu w agentach AI
Problem zanikania kontekstu: kluczowe wyzwanie
Choć zwiększanie długości kontekstu jest szeroko świętowane, najnowsze badania ujawniają niepokojącą prawdę: dłuższy kontekst nie oznacza automatycznie lepszych wyników.
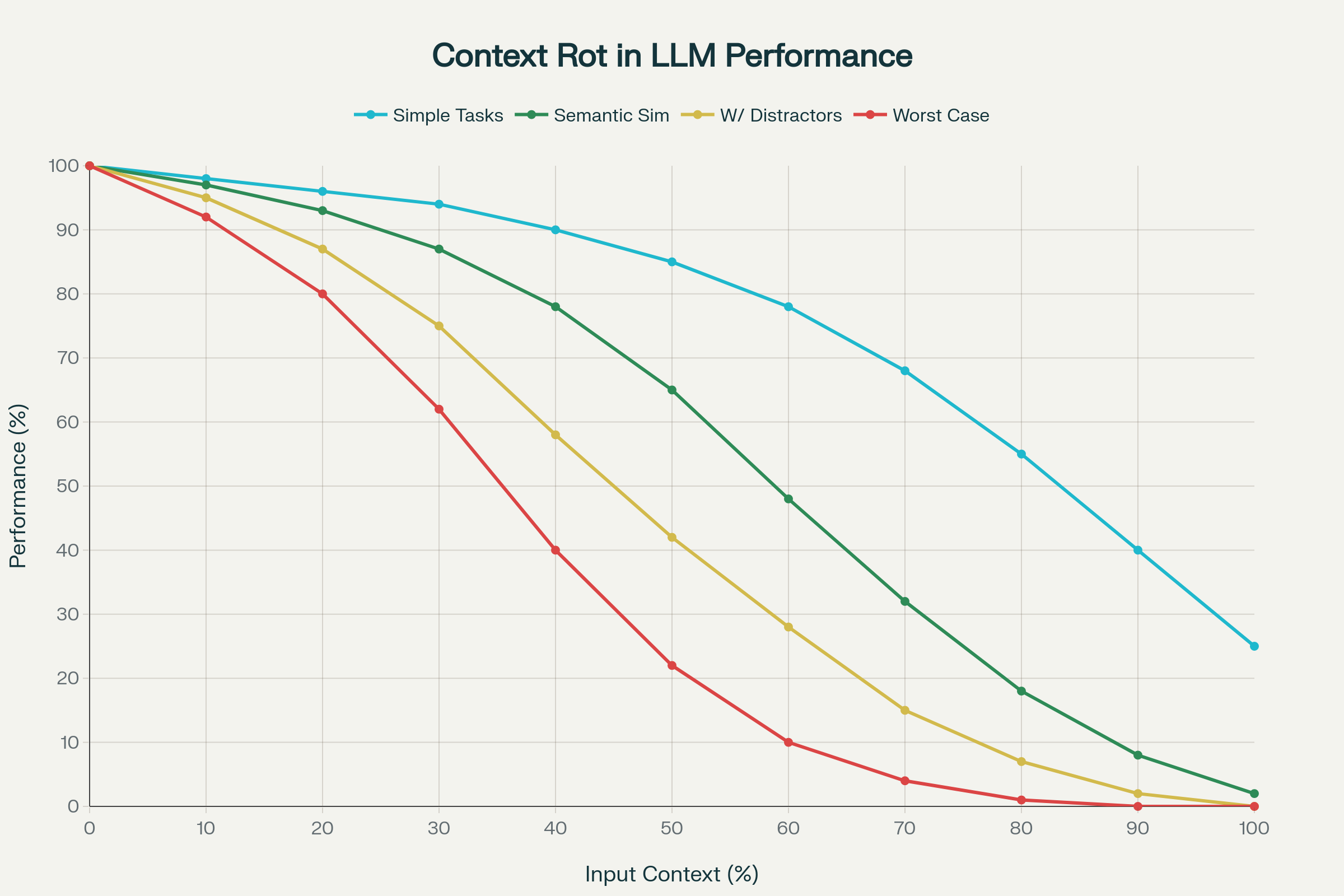
Przełomowe badanie 18 czołowych LLM — w tym GPT-4.1, Claude 4, Gemini 2.5 i Qwen 3 — ujawniło zjawisko nazwane zanikaniem kontekstu: nieprzewidywalne i często gwałtowne pogorszenie wydajności wraz ze wzrostem wejściowego kontekstu.
Kluczowe ustalenia dotyczące zanikania kontekstu
1. Niejednorodne pogarszanie się wydajności
Wydajność nie spada liniowo i przewidywalnie. Modele wykazują gwałtowne, idiosynkratyczne spadki w zależności od konkretnego modelu i zadania. Model może utrzymywać 95% dokładności do pewnej długości kontekstu, po czym nagle spaść do 60%. Te klify są nieprzewidywalne między modelami.
2. Złożoność semantyczna potęguje zjawisko
Proste zadania (np. powtarzanie słów, precyzyjne wyszukiwanie semantyczne) wykazują umiarkowany spadek. Gdy jednak “igły w stogu siana” wymagają podobieństwa semantycznego zamiast ścisłych dopasowań, wydajność gwałtownie spada. Dodanie rozpraszaczy — informacji podobnych, lecz nie tych, których model potrzebuje — dramatycznie pogarsza wyniki.
3. Uprzedzenia pozycyjne i załamanie uwagi
Mechanizm uwagi transformera nie skaluje się liniowo dla długich kontekstów. Tokeny na początku (uprzedzenie pierwszeństwa) i końcu (uprzedzenie świeżości) otrzymują nieproporcjonalnie więcej uwagi. W skrajnych przypadkach uwaga załamuje się całkowicie, powodując ignorowanie znaczących części wejścia.
4. Wzorce porażek specyficzne dla modelu
Różne LLM wykazują unikalne zachowania na dużą skalę:
GPT-4.1: Ma tendencję do halucynowania, powtarzania błędnych tokenów
Gemini 2.5: Wstawia niepowiązane fragmenty lub znaki interpunkcyjne
Claude Opus 4: Może odmawiać realizacji zadania lub być przesadnie ostrożny
5. Wpływ na rzeczywiste rozmowy
Najbardziej kompromitujące: w benchmarku LongMemEval modele mające dostęp do pełnych rozmów (~113k tokenów) radziły sobie znacznie gorzej niż przy otrzymaniu tylko skupionego segmentu 300-tokenowego. Pokazuje to, że zanikanie kontekstu degraduje zarówno pobieranie informacji, jak i rozumowanie w realnych dialogach.
Zanikanie kontekstu: Pogorszenie wydajności wraz ze wzrostem długości wejściowych tokenów dla 18 LLM
Wnioski: Jakość ważniejsza od ilości
Najważniejszy wniosek z badań nad zanikaniem kontekstu jest jasny: liczba wejściowych tokenów nie jest jedynym czynnikiem decydującym o jakości. To, jak kontekst jest konstruowany, filtrowany i prezentowany, jest równie — a często nawet bardziej — istotne.
To odkrycie uzasadnia całą dyscyplinę inżynierii kontekstu. Zamiast traktować długie okna kontekstu jako panaceum, zaawansowane zespoły wiedzą, że staranna inżynieria kontekstu — przez kompresję, selekcję i izolację — jest niezbędna dla utrzymania wydajności przy dużych wejściach.
Inżynieria kontekstu w praktyce: zastosowania
Studium przypadku 1: Systemy agentów wieloetapowych (Claude Code, Cursor)
Claude Code i Cursor to najnowocześniejsze implementacje inżynierii kontekstu dla wsparcia kodowania:
Zbieranie: Systemy zbierają kontekst z wielu źródeł — otwarte pliki, strukturę projektu, historię edycji, wyjście terminala i komentarze użytkownika.
Zarządzanie: Zamiast wrzucać wszystkie pliki do prompta, inteligentnie kompresują. Claude Code stosuje podsumowania hierarchiczne. Kontekst jest tagowany według funkcji (np. “aktualnie edytowany plik”, “referencja”, “komunikat o błędzie”).
Wykorzystanie: Przy każdej turze system wybiera odpowiednie pliki i elementy kontekstu, prezentuje je w uporządkowany sposób i utrzymuje osobne ścieżki dla rozumowania i widocznego wyjścia.
Kompresja: Gdy zbliża się ograniczenie okna kontekstu, auto-compact się uruchamia, podsumowując przebieg interakcji przy zachowaniu kluczowych decyzji.
Efekt: Narzędzia te pozostają użyteczne nawet przy dużych projektach (tysiące plików) bez pogorszenia wydajności pomimo ograniczeń okna kontekstu.
Studium przypadku 2: Tongyi DeepResearch (Open-Source Deep Research Agent)
Tongyi DeepResearch pokazuje, jak inżynieria kontekstu umożliwia złożone zadania badawcze:
Pipeline syntezy danych: Zamiast polegać na ograniczonych, ręcznie adnotowanych danych, Tongyi stosuje zaawansowaną syntezę danych, tworząc pytania na poziomie doktoranckim poprzez iteracyjne zwiększanie złożoności. Każda iteracja pogłębia wiedzę i buduje coraz trudniejsze zadania rozumowania.
Zarządzanie kontekstem: System korzysta z paradygmatu IterResearch — w każdej rundzie badawczej rekonstruuje zwięzłe środowisko pracy używając tylko kluczowych wyników z poprzedniej rundy. Zapobiega to “uduszeniu poznawczemu” przez kumulację informacji w jednym oknie kontekstu.
Równoległa eksploracja: Kilku agentów badawczych działa równolegle z izolowanymi kontekstami, eksplorując różne aspekty; agent syntezy integruje ich wyniki.
Wyniki: Tongyi DeepResearch osiąga wyniki porównywalne z systemami firmowymi jak DeepResearch OpenAI — 32,9 pkt na Humanity’s Last Exam i 75 pkt na benchmarkach zorientowanych na użytkownika.
Studium przypadku 3: Multi-agentowy badacz Anthropic
Badania Anthropic pokazują, jak izolacja i specjalizacja poprawiają wyniki:
Architektura: Wyspecjalizowane sub-agenty realizują konkretne zadania badawcze (przegląd literatury, synteza, weryfikacja) z osobnymi oknami kontekstu.
Korzyści: To podejście przewyższyło systemy jednoagentowe, bo każdy subagent miał zoptymalizowany kontekst dla swojego zadania.
Kompromis: Choć jakość była wyższa, zużycie tokenów wzrosło nawet piętnastokrotnie względem czatu jednoagentowego.
To potwierdza kluczowy wniosek: inżynieria kontekstu często oznacza kompromis między jakością, szybkością i kosztem. Odpowiednia równowaga zależy od wymagań aplikacji.
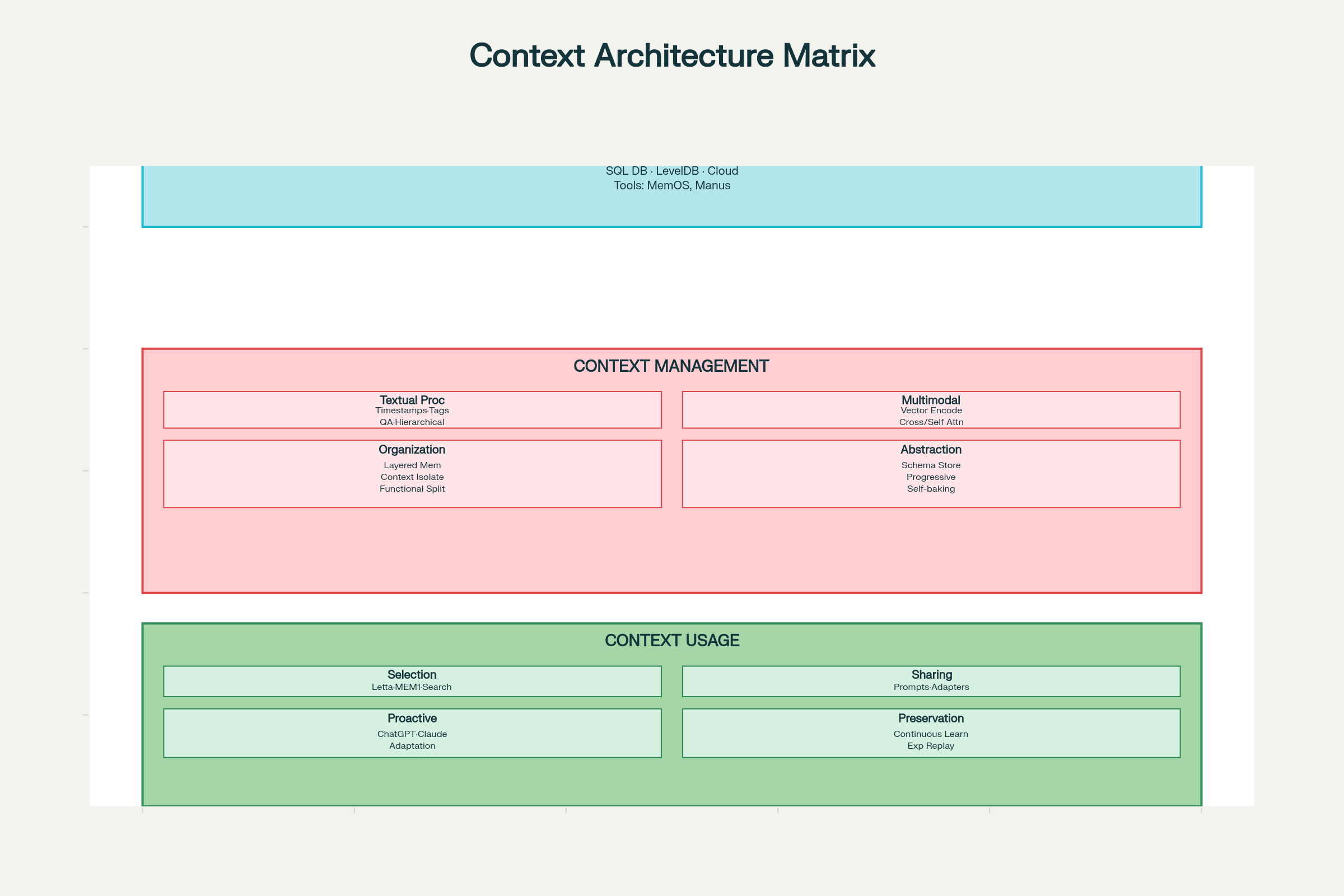
Ramy projektowania inżynierii kontekstu
Skuteczna inżynieria kontekstu wymaga systematycznego myślenia w trzech wymiarach: zbieranie i przechowywanie, zarządzanie oraz wykorzystanie.
Ramy projektowania inżynierii kontekstu: pełna architektura systemu i komponenty
Decyzje projektowe dotyczące zbierania i przechowywania
Wybór technologii przechowywania:
Pamięć lokalna (SQLite, LevelDB): Szybka, niskie opóźnienia, dobra dla agentów po stronie klienta
Przechowywanie w chmurze (DynamoDB, PostgreSQL): Skalowalność, dostępność z dowolnego miejsca
Systemy rozproszone: Do masowej skali z redundancją i tolerancją błędów
Wzorce projektowe:
MemOS: System operacyjny pamięci dla zunifikowanego zarządzania pamięcią
Manus: Strukturalna pamięć z dostępem opartym na rolach
Główna zasada: Projektuj pod kątem efektywnego pobierania, nie tylko przechowywania. Optymalny system przechowywania to taki, w którym szybko znajdziesz to, czego potrzebujesz.
Decyzje projektowe dotyczące zarządzania
Przetwarzanie kontekstu tekstowego:
Oznaczanie znacznikami czasu: Proste, ale ograniczone. Zachowuje chronologię, lecz nie daje struktury semantycznej — przy dużej liczbie interakcji pojawiają się problemy ze skalowaniem.
Tagowanie funkcji/roli: Każdy element kon
Najczęściej zadawane pytania
Inżynieria promptów koncentruje się na tworzeniu pojedynczej instrukcji dla LLM. Inżynieria kontekstu to szersza dyscyplina systemowa, która zarządza całym ekosystemem informacji dla modelu AI, obejmując pamięć, narzędzia i pobierane dane, aby zoptymalizować wydajność przy złożonych, stanowych zadaniach.
Zanikanie kontekstu to nieprzewidywalny spadek wydajności LLM wraz ze wzrostem długości wejściowego kontekstu. Modele mogą wykazywać gwałtowne spadki dokładności, ignorować części kontekstu lub halucynować, podkreślając potrzebę jakości i ostrożnego zarządzania kontekstem zamiast polegania na ilości.
Cztery główne strategie to: 1. Zapisuj kontekst (utrwalanie informacji poza oknem kontekstu, np. notatniki lub pamięć), 2. Wybieraj kontekst (pobieranie tylko istotnych informacji), 3. Kompresuj kontekst (podsumowywanie lub skracanie w celu oszczędności miejsca) oraz 4. Izoluj kontekst (wykorzystywanie systemów multi-agentowych lub piaskownic do rozdzielania zagadnień).
Arshia jest Inżynierką Przepływów Pracy AI w FlowHunt. Z wykształceniem informatycznym i pasją do sztucznej inteligencji, specjalizuje się w tworzeniu wydajnych przepływów pracy, które integrują narzędzia AI z codziennymi zadaniami, zwiększając produktywność i kreatywność.
Arshia Kahani
Inżynierka Przepływów Pracy AI
Opanuj inżynierię kontekstu
Gotowy na budowę nowej generacji systemów AI? Przeglądaj nasze zasoby i narzędzia, aby wdrożyć zaawansowaną inżynierię kontekstu w swoich projektach.
Niech żyje inżynieria kontekstu: Budowanie produkcyjnych systemów AI z użyciem nowoczesnych baz wektorowych
Poznaj, jak inżynieria kontekstu przekształca rozwój AI, ewolucję od RAG do systemów gotowych na produkcję oraz dlaczego nowoczesne bazy wektorowe, takie jak Ch...
Inżynieria kontekstu dla agentów AI: Sztuka dostarczania LLM-om właściwych informacji
Dowiedz się, jak projektować kontekst dla agentów AI poprzez zarządzanie informacjami zwrotnymi z narzędzi, optymalizację wykorzystania tokenów oraz wdrażanie s...