Przepływy
Przepływy to mózg całego systemu w FlowHunt. Dowiedz się, jak je budować za pomocą wizualnego kreatora bez kodowania – od umieszczenia pierwszego komponentu po ...
2 min czytania
AI
No-Code
+4

Nowy otwartoźródłowy toolkit CLI FlowHunt umożliwia kompleksową ocenę przepływów z LLM jako Sędzią, zapewniając szczegółowe raportowanie i automatyczną ocenę jakości dla workflow AI.
Z radością ogłaszamy wydanie FlowHunt CLI Toolkit – naszego nowego otwartoźródłowego narzędzia wiersza poleceń, które rewolucjonizuje sposób, w jaki deweloperzy oceniają i testują przepływy AI. Ten potężny toolkit wnosi możliwości oceny przepływów na poziomie korporacyjnym do społeczności open source, oferując zaawansowane raportowanie oraz innowacyjną implementację „LLM jako Sędziego”.
FlowHunt CLI Toolkit to duży krok naprzód w testowaniu i ocenie workflow AI. Dostępny już teraz na GitHubie , otwarty zestaw narzędzi zapewnia deweloperom kompleksowe możliwości:
Toolkit odzwierciedla nasze zaangażowanie w transparentność i rozwój oparty na społeczności, udostępniając zaawansowane techniki oceny AI deweloperom na całym świecie.
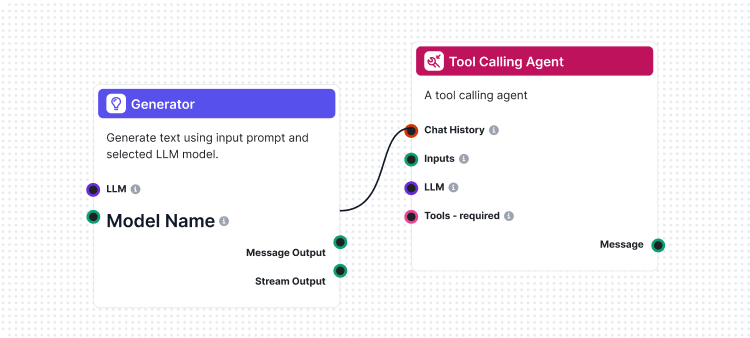
Jedną z najbardziej innowacyjnych funkcji naszego toolkitu CLI jest implementacja „LLM jako Sędziego”. Podejście to wykorzystuje sztuczną inteligencję do oceny jakości i poprawności odpowiedzi generowanych przez AI – innymi słowy, AI ocenia AI z wykorzystaniem zaawansowanych zdolności rozumowania.
Nasza implementacja wyróżnia się tym, że do stworzenia przepływu oceniającego wykorzystaliśmy sam FlowHunt. To meta-podejście pokazuje siłę i elastyczność naszej platformy oraz zapewnia solidny system oceny. Przepływ LLM jako Sędzia składa się z kilku współpracujących komponentów:
1. Szablon promptu: Tworzy prompt oceniający z określonymi kryteriami
2. Generator wyjścia strukturalnego: Przetwarza ocenę za pomocą LLM
3. Parser danych: Formatuje strukturalne wyjście do raportowania
4. Wyjście czatu: Prezentuje końcowe wyniki oceny
Sercem naszego systemu LLM jako Sędzia jest starannie przygotowany prompt zapewniający spójne i wiarygodne oceny. Oto podstawowy szablon promptu, którego używamy:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Ten prompt sprawia, że nasz sędzia LLM zapewnia:
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Przepływ LLM jako Sędzia pokazuje zaawansowaną konstrukcję workflow AI z wykorzystaniem wizualnego kreatora FlowHunt. Oto, jak współpracują komponenty:
Przepływ zaczyna się od komponentu Chat Input, który otrzymuje żądanie oceny zawierające zarówno rzeczywistą odpowiedź, jak i odpowiedź referencyjną.
Komponent Prompt Template dynamicznie tworzy prompt oceniający poprzez:
{target_response}{actual_response}Structured Output Generator przetwarza prompt wybranym LLM i generuje strukturalne wyjście zawierające:
total_rating: Wynik liczbowy od 1 do 4correctness: Binarna klasyfikacja poprawności/niepoprawnościreasoning: Szczegółowe wyjaśnienie ocenyKomponent Parse Data formatuje strukturalne dane do czytelnej postaci, a Chat Output prezentuje końcowe wyniki oceny.
System LLM jako Sędzia oferuje szereg zaawansowanych możliwości, dzięki czemu jest szczególnie skuteczny w ocenie przepływów AI:
W przeciwieństwie do prostego dopasowania tekstu, nasz sędzia LLM rozumie:
Skala ocen 4-punktowa zapewnia szczegółową ewaluację:
Każda ocena zawiera szczegółowe uzasadnienie, co pozwala:
Otrzymuj najnowsze wskazówki, trendy i oferty za darmo.
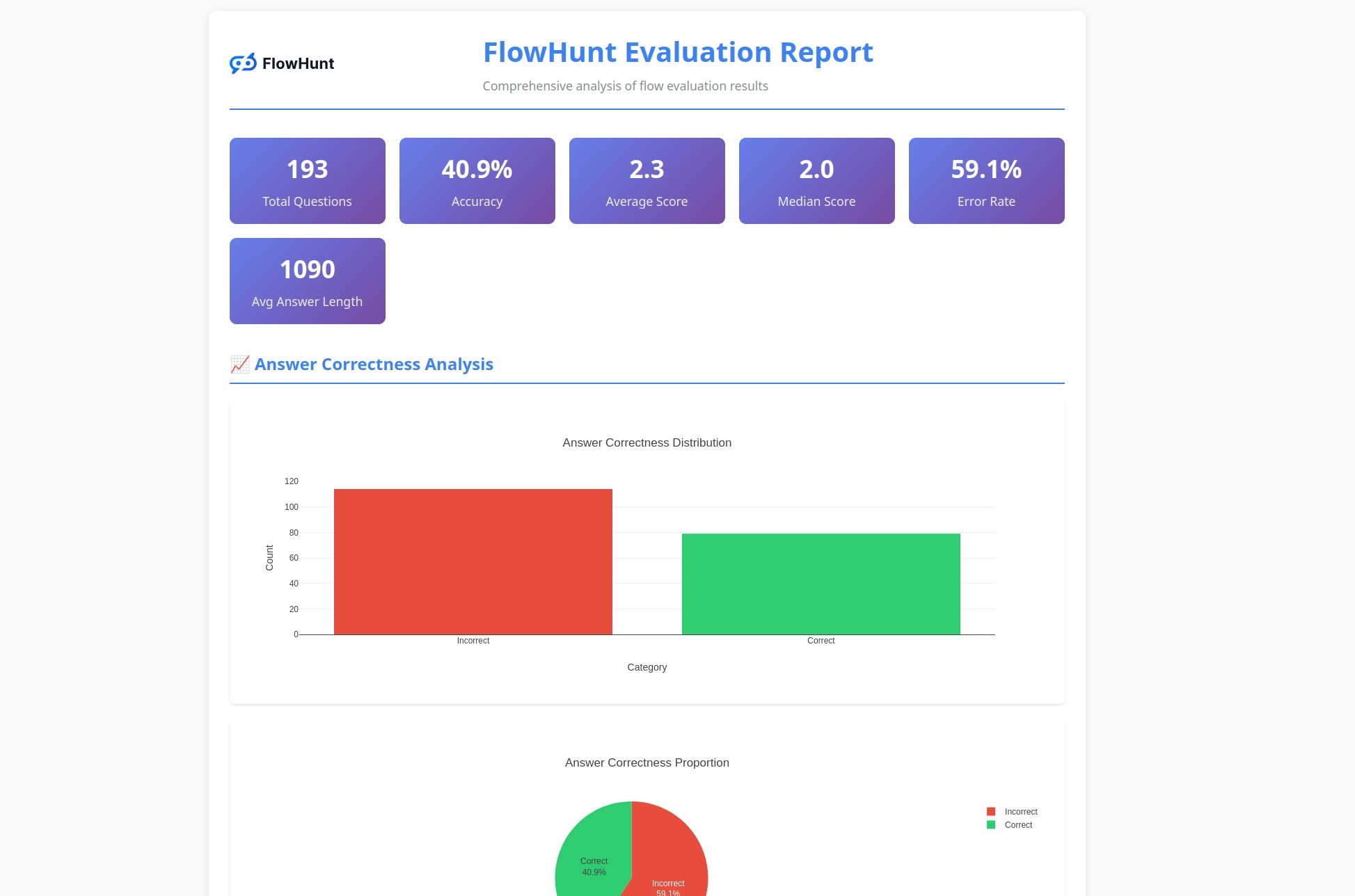
Toolkit CLI generuje szczegółowe raporty, które dostarczają praktycznych wniosków dotyczących wydajności przepływów:
Chcesz zacząć oceniać swoje przepływy AI profesjonalnymi narzędziami? Oto jak wystartować:
Jednolinijkowa instalacja (zalecana) dla macOS i Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Automatycznie zostanie:
flowhunt do PATHInstalacja manualna:
# Sklonuj repozytorium
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Instalacja przez pip
pip install -e .
Weryfikacja instalacji:
flowhunt --help
flowhunt --version
1. Uwierzytelnienie Najpierw zaloguj się do swojego FlowHunt API:
flowhunt auth
2. Lista przepływów
flowhunt flows list
3. Oceń przepływ Przygotuj plik CSV z danymi testowymi:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Uruchom ocenę z LLM jako Sędzią:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Wykonanie wsadowe przepływów
flowhunt batch-run your-flow-id input.csv --output-dir results/
System oceny zapewnia kompleksową analizę:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Funkcje obejmują:
Toolkit CLI bezproblemowo integruje się z platformą FlowHunt, umożliwiając:
Wydanie naszego toolkitu CLI to coś więcej niż nowe narzędzie – to wizja przyszłości rozwoju AI, gdzie:
Jakość jest mierzalna: Zaawansowane techniki oceny sprawiają, że wydajność AI można ilościowo porównywać.
Testowanie jest zautomatyzowane: Kompleksowe frameworki testowe ograniczają ręczną pracę i zwiększają niezawodność.
Transparentność to standard: Szczegółowe uzasadnienia i raportowanie sprawiają, że zachowanie AI jest zrozumiałe i możliwe do debugowania.
Społeczność napędza innowacje: Narzędzia open source umożliwiają wspólne ulepszanie i dzielenie się wiedzą.
Udostępniając FlowHunt CLI Toolkit jako open source, pokazujemy nasze zaangażowanie w:
FlowHunt CLI Toolkit z LLM jako Sędzią to znaczący postęp w możliwościach oceny przepływów AI. Łącząc zaawansowaną logikę oceny z kompleksowym raportowaniem i otwartoźródłową dostępnością, umożliwiamy deweloperom budowanie lepszych i bardziej niezawodnych systemów AI.
Meta-podejście, w którym FlowHunt ocenia przepływy FlowHunt, pokazuje dojrzałość i elastyczność naszej platformy, stanowiąc jednocześnie potężne narzędzie dla całej społeczności rozwoju AI.
Niezależnie od tego, czy tworzysz proste chatboty, czy złożone systemy multi-agentowe, FlowHunt CLI Toolkit dostarcza infrastrukturę oceny niezbędną do zapewnienia jakości, niezawodności i ciągłego rozwoju.
Chcesz podnieść poziom oceny swoich przepływów AI? Odwiedź nasze repozytorium na GitHubie , aby rozpocząć pracę z FlowHunt CLI Toolkit już dziś i samodzielnie doświadczyć mocy LLM jako Sędziego.
Przyszłość rozwoju AI zaczyna się tu – i jest otwarta.
FlowHunt CLI Toolkit to otwartoźródłowe narzędzie wiersza poleceń do oceny przepływów AI z rozbudowanymi możliwościami raportowania. Obejmuje funkcje takie jak ocena LLM jako Sędziego, analizę wyników poprawnych/niepoprawnych oraz szczegółowe metryki wydajności.
LLM jako Sędzia wykorzystuje zaawansowany przepływ AI zbudowany w FlowHunt do oceny innych przepływów. Porównuje rzeczywiste odpowiedzi z wzorcami, dostarczając oceny, klasyfikację poprawności i szczegółowe uzasadnienia dla każdej oceny.
FlowHunt CLI Toolkit jest otwartoźródłowy i dostępny na GitHub pod adresem https://github.com/yasha-dev1/flowhunt-toolkit. Możesz go sklonować, współtworzyć i dowolnie używać do oceny własnych przepływów AI.
Toolkit generuje szczegółowe raporty, w tym podział wyników poprawnych/niepoprawnych, oceny LLM jako Sędziego z punktacją i uzasadnieniami, metryki wydajności oraz szczegółową analizę zachowania przepływów dla różnych przypadków testowych.
Tak! Przepływ LLM jako Sędzia jest zbudowany na platformie FlowHunt i można go dostosować do różnych scenariuszy oceny. Możesz modyfikować szablon promptu i kryteria oceny pod własne potrzeby.
Yasha jest utalentowanym programistą specjalizującym się w Pythonie, Javie i uczeniu maszynowym. Yasha pisze artykuły techniczne o AI, inżynierii promptów i tworzeniu chatbotów.

Buduj i oceniaj zaawansowane workflow AI na platformie FlowHunt. Zacznij tworzyć przepływy, które potrafią oceniać inne przepływy już dziś.
Przepływy to mózg całego systemu w FlowHunt. Dowiedz się, jak je budować za pomocą wizualnego kreatora bez kodowania – od umieszczenia pierwszego komponentu po ...

FlowHunt 2.4.1 wprowadza najnowsze modele AI, w tym Claude, Grok, Llama, Mistral, DALL-E 3 oraz Stable Diffusion, rozszerzając Twoje możliwości eksperymentowani...

Automatyzuj i orkiestruj procesy biznesowe, integrując FlowHunt z serwerem iFlytek Workflow MCP. Wykorzystaj inteligentne planowanie przepływów pracy, wsparcie ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.