Jak zbudować niestandardowe strony bazy wiedzy w Hugo z ticketów LiveAgent
Dowiedz się, jak zautomatyzować tworzenie artykułów bazy wiedzy w Hugo bezpośrednio z ticketów obsługi klienta, wykorzystując agentów AI i integrację z GitHub.
Automation
Knowledge Base
Hugo
GitHub
AI Agents
Customer Support
Zespoły obsługi klienta codziennie generują cenne informacje poprzez interakcje z użytkownikami. Te pytania, wątpliwości i rozwiązania stanowią prawdziwą kopalnię wiedzy, która – jeśli zostanie odpowiednio udokumentowana – może przynieść korzyści wszystkim Twoim klientom. Jednak ręczne przekształcanie ticketów wsparcia w dopracowane artykuły bazy wiedzy jest czasochłonne, powtarzalne i często spychane na później na rzecz bieżących zadań. A gdybyś mógł zautomatyzować cały ten proces, zamieniając surowe zapytania klientów w profesjonalnie sformatowane, zoptymalizowane pod SEO strony bazy wiedzy, które pojawiają się bezpośrednio na Twojej stronie? Właśnie to umożliwiają nowoczesne workflow automatyzacji. Łącząc system ticketowy LiveAgent z generowaniem strony statycznej w Hugo i kontrolą wersji w GitHub, możesz stworzyć płynny pipeline, który automatycznie zamienia pytania klientów w wyszukiwalne, łatwe do odnalezienia treści bazy wiedzy. W tym kompleksowym przewodniku pokażemy, jak zbudować taki system automatyzacji, omówimy architekturę techniczną oraz praktyczne kroki wdrożenia w Twojej organizacji.
Na czym polega automatyzacja bazy wiedzy
Baza wiedzy to centralne repozytorium informacji, które ma pomóc użytkownikom znaleźć odpowiedzi na typowe pytania bez konieczności kontaktu z obsługą. Tradycyjne bazy wiedzy powstają ręcznie — zespoły wsparcia piszą artykuły, formatują je, optymalizują pod kątem wyszukiwarek i publikują w systemie zarządzania treścią. Ten proces jest pracochłonny i stanowi wąskie gardło, zwłaszcza gdy firma rośnie i dziennie otrzymuje setki zapytań. Automatyzacja bazy wiedzy zmienia ten paradygmat, wykorzystując sztuczną inteligencję do wydobywania istotnych informacji z ticketów, układania ich według zdefiniowanych szablonów i publikowania bezpośrednio na stronie www. System automatyzacji działa jako inteligentny pośrednik między zespołem wsparcia a stroną internetową, identyfikując tickety zawierające wiedzę przydatną dla szerszego grona użytkowników i przekształcając surową rozmowę w dopracowaną dokumentację. Takie podejście nie tylko oszczędza czas, ale też zapewnia spójność formatowania, struktury i optymalizacji SEO wszystkich artykułów. System można skonfigurować pod kątem specyficznego kontekstu biznesowego, unikać duplikowania treści i utrzymywać spójną bazę wiedzy, która rozwija się organicznie wraz z obsługą kolejnych zgłoszeń.
Gotowy na rozwój swojej firmy?
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Dlaczego automatyzacja bazy wiedzy jest ważna dla Twojej firmy
Automatyzacja bazy wiedzy to korzyść biznesowa o wielu wymiarach. Po pierwsze, znacząco zmniejsza liczbę zapytań do wsparcia, umożliwiając klientom samodzielne znajdowanie odpowiedzi. Badania pokazują, że klienci wolą opcje samoobsługowe, jeśli są skuteczne, a dobrze prowadzona baza wiedzy może obniżyć liczbę ticketów nawet o 20-30%. Po drugie, poprawia satysfakcję klientów, dostarczając natychmiastowych odpowiedzi na typowe pytania, bez oczekiwania na reakcję zespołu. Po trzecie, generuje istotne korzyści SEO — artykuły bazy wiedzy są indeksowane przez wyszukiwarki i mogą przyciągać ruch organiczny na stronę, zwiększając widoczność i pozyskując nowych klientów poprzez wyszukiwarkę. Po czwarte, pozwala zachować wiedzę firmową, która w innym wypadku mogłaby przepaść wraz z odejściem pracowników. Każda interakcja wsparcia zawiera cenny kontekst i rozwiązania, które po udokumentowaniu stają się częścią trwałego zasobu wiedzy firmy. Po piąte, pozwala zespołowi wsparcia skupić się na złożonych, wartościowych sprawach zamiast wielokrotnego odpowiadania na te same pytania. Automatyzując tworzenie treści bazy wiedzy z ticketów, tworzysz swoisty mnożnik efektywności swojego działu wsparcia. Czas poświęcony na odpowiedzi zamienia się w wiedzę, która służy tysiącom kolejnych klientów. Wreszcie, system ten dostarcza danych o najczęstszych problemach klientów, co może inspirować rozwój produktu, komunikację marketingową oraz działania edukacyjne.
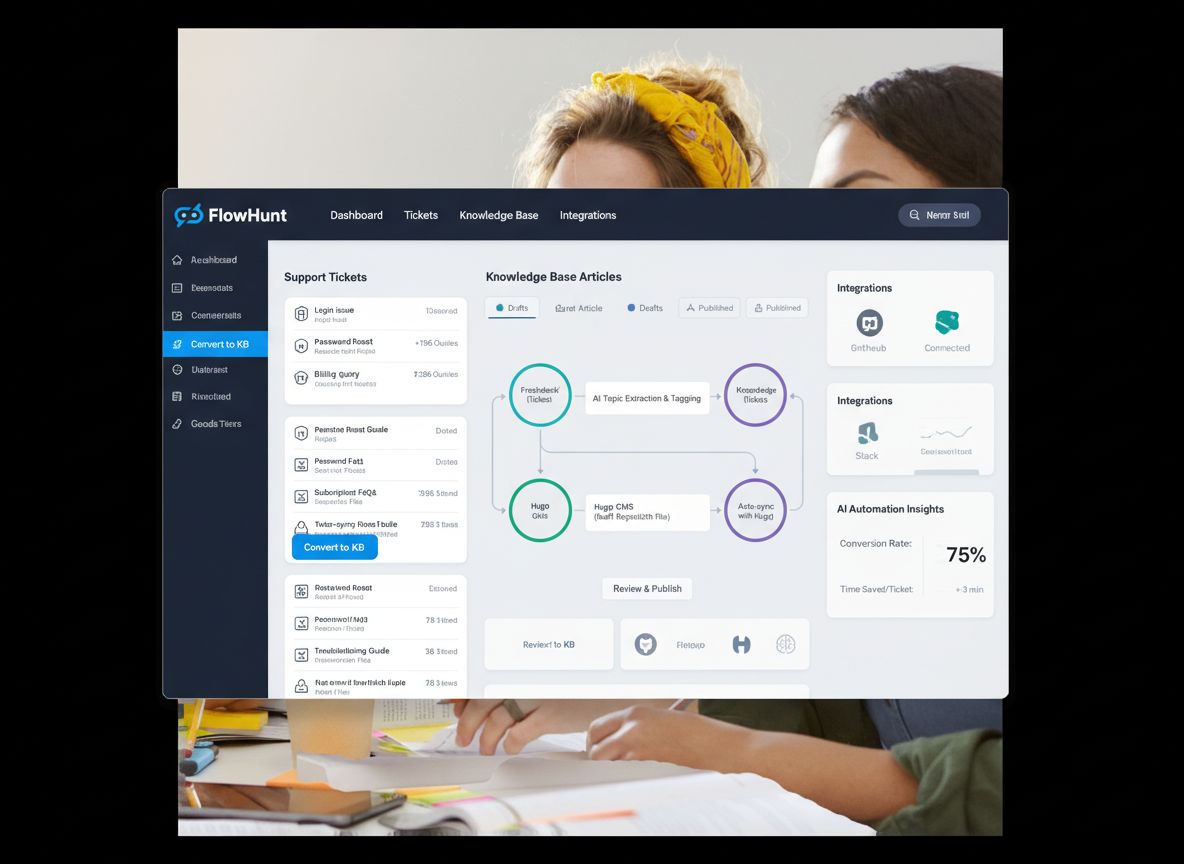
Architektura automatycznego generowania bazy wiedzy
Budowa zautomatyzowanego systemu bazy wiedzy wymaga integracji kilku narzędzi i platform w jeden spójny workflow. System zazwyczaj składa się z czterech głównych elementów: systemu ticketowego (LiveAgent), agenta AI przetwarzającego tickety, systemu kontroli wersji (GitHub) oraz generatora statycznej strony (Hugo). LiveAgent jest źródłem prawdy dla zapytań klientów i przechowuje całą historię rozmów wraz z metadanymi (tagi, kategorie, daty). Agent AI jest orkiestratorem całego procesu — otrzymuje identyfikator ticketu, pobiera pełną treść i historię konwersacji, analizuje przydatność do publikacji w bazie wiedzy, sprawdza istniejącą wiedzę, by unikać duplikatów, generuje zoptymalizowaną treść i obsługuje workflow GitHub. GitHub pełni rolę warstwy zarządzania treścią i kontroli wersji, umożliwiając przegląd, akceptację i śledzenie wszystkich zmian. Hugo zamienia pliki markdown z GitHub w szybką, bezpieczną i przyjazną SEO stronę www. Taka architektura zapewnia jasny podział ról: LiveAgent obsługuje wsparcie, agent AI – inteligencję i podejmowanie decyzji, GitHub – kontrolę wersji i współpracę, a Hugo – prezentację. Każdy element może być niezależnie rozwijany i utrzymywany bez wpływu na całość.
Dołącz do naszego newslettera
Otrzymuj najnowsze wskazówki, trendy i oferty za darmo.
Jak FlowHunt umożliwia automatyzację bazy wiedzy
FlowHunt stanowi warstwę orkiestracji, która łączy wszystkie te systemy w jeden płynny workflow. Zamiast wymagać programowania czy skomplikowanych integracji, FlowHunt pozwala wizualnie zaprojektować przepływ automatyzacji, łącząc LiveAgent, GitHub i Hugo w prostym, intuicyjnym interfejsie. Platforma obsługuje autoryzację, obsługę błędów, logikę ponawiania prób oraz całą techniczną złożoność, która normalnie wymagałaby zaangażowania zespołu inżynierskiego. Dzięki FlowHunt możesz budować zaawansowane workflow automatyzacji bez kodowania, udostępniając automatyzację bazy wiedzy zespołom bez zaplecza programistycznego. Platforma oferuje też zarządzanie pamięcią i kontekstem, pozwalając na inteligentne decyzje – kiedy tworzyć nowe artykuły, a kiedy aktualizować istniejące. Integracja z GitHub zapewnia automatyczne tworzenie pull requestów, dzięki czemu Twój zespół może zrecenzować materiał przed publikacją. Takie podejście, łączące automatyzację z kontrolą człowieka, gwarantuje wysoką jakość przy maksymalnej efektywności.
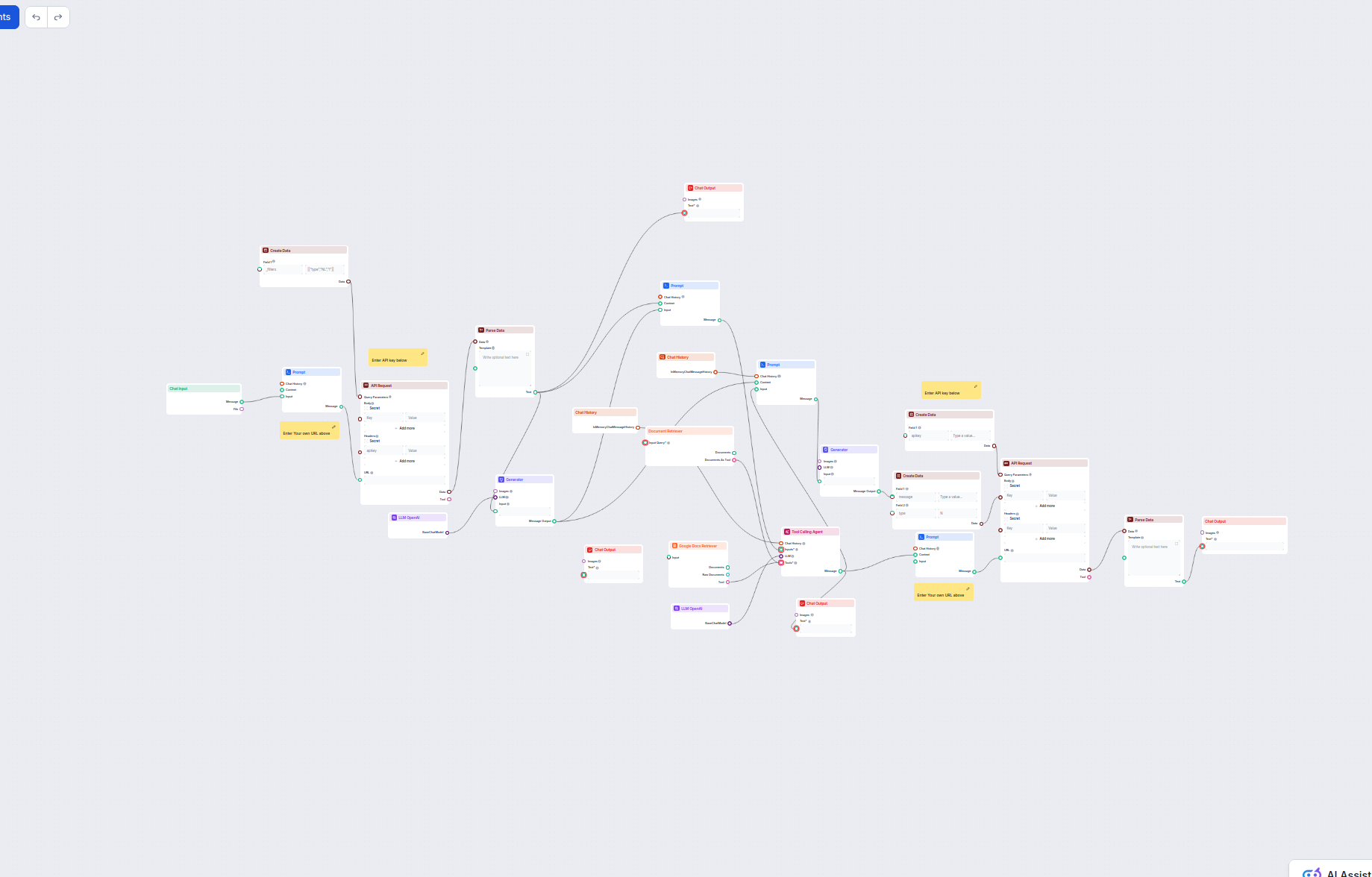
Pełny workflow: krok po kroku
Automatyczny workflow generowania bazy wiedzy składa się z kolejnych etapów, z których każdy bazuje na poprzednim, tworząc kompletny, gotowy do publikacji artykuł. Zrozumienie tego procesu jest kluczowe dla skutecznego wdrożenia go w Twojej firmie.
Krok pierwszy: pobranie i walidacja ticketu
Workflow zaczyna się od podania identyfikatora ticketu z LiveAgent. Agent AI natychmiast pobiera pełną zawartość ticketu, w tym temat, treść, wszystkie tagi i całą historię rozmów między klientem a wsparciem. Taka kompletność jest niezbędna, by AI mogła wygenerować dokładną, wartościową treść. Agent sprawdza też, czy ticket zawiera wystarczające informacje i nadaje się do publikacji w bazie wiedzy. Na przykład, jeśli Twoja firma otrzymuje wiele próśb o umówienie demo, możesz skonfigurować system, by automatycznie je pomijał, bo nie zawierają wiedzy przydatnej dla szerszego grona użytkowników. Ten etap filtracji chroni bazę wiedzy przed zalewem treści administracyjnych czy transakcyjnych, które nie wnoszą wartości.
Krok drugi: wykrywanie duplikatów za pomocą pamięci
Przed wygenerowaniem nowego artykułu system sprawdza, czy podobny temat nie został już opisany. System pamięci to jedna z najważniejszych funkcji automatyzacji — zapobiega tworzeniu zduplikowanych lub bardzo podobnych artykułów, które mogłyby wprowadzać użytkowników w błąd i osłabiać SEO. Agent AI przeszukuje wcześniejsze tickety i artykuły, by znaleźć podobne tematy. Jeśli znajdzie zgodność, może zaktualizować istniejący artykuł lub pominąć tworzenie, w zależności od konfiguracji. Jeśli temat jest nowy, agent dodaje ticket do pamięci, tworząc rekord na przyszłość. Dzięki temu system staje się coraz mądrzejszy — przetwarzając kolejne tickety, buduje mapę bazy wiedzy i podejmuje coraz trafniejsze decyzje o tworzeniu lub aktualizacji treści.
Krok trzeci: analiza struktury bazy wiedzy
System analizuje istniejące repozytorium bazy wiedzy, by poznać strukturę, formatowanie i organizację treści. Ten krok jest kluczowy dla zachowania spójności wszystkich artykułów. Agent AI analizuje pliki markdown, sekcje frontmatter, układ nagłówków i wzorce treści, by poznać konwencje obowiązujące w Twojej bazie wiedzy. Sprawdza sposób kategoryzacji artykułów, używane metadane, odwołania do obrazków i elementy SEO. Dzięki temu nowo wygenerowane artykuły będą stylistycznie i strukturalnie spójne z istniejącą bazą oraz nie będą się wyróżniać jako automatycznie stworzone.
Krok czwarty: zarządzanie branchami w GitHub
By utrzymać porządek w repozytorium i zapewnić właściwy workflow recenzji, system tworzy nową lub wykorzystuje istniejącą gałąź GitHub do aktualizacji bazy wiedzy. Zamiast tworzyć nową gałąź dla każdego ticketu, system zarządza nimi inteligentnie, utrzymując porządek. Jeśli gałąź do aktualizacji bazy wiedzy już istnieje, system używa jej i dodaje nowy plik. Takie podejście zapobiega nadmiernemu rozrostowi branchy i pozwala zgrupować kilka aktualizacji w jednym pull requeście do recenzji. Nazewnictwo gałęzi jest opisowe, np. “knowledge-base-updates” lub “kb-automation”, co ułatwia identyfikację ich celu przez zespół.
Krok piąty: generowanie i formatowanie treści
Mając pełen kontekst, agent AI generuje artykuł bazy wiedzy. Wygenerowana treść zawiera poprawnie sformatowaną sekcję frontmatter z metadanymi: tytuł, opis, słowa kluczowe, tagi, kategorie, datę publikacji i elementy call-to-action. Treść artykułu ma przejrzystą strukturę przyjazną użytkownikowi i wyszukiwarce. Zwykle zawiera główny nagłówek, kilka sekcji H2 z nagłówkami w formie pytań (np. “Czym jest…?”, “Dlaczego warto…?”, “Jak to zrobić?”) oraz szczegółowe odpowiedzi w formie akapitów i punktów. Taka struktura jest zoptymalizowana pod fragmenty rozszerzone i inne funkcje SEO premiujące jasny układ Q&A. Treść zapisywana jest w markdown, co zapewnia zgodność z Hugo i łatwą edycję.
Krok szósty: tworzenie pliku i commit
System tworzy nowy plik markdown w folderze bazy wiedzy, nadając mu odpowiednią nazwę na podstawie tematu artykułu. Nazwa pliku jest z reguły zslugowana (małe litery, myślniki zamiast spacji), zgodnie ze standardami webowymi. Plik zawiera komplet frontmatter i treść wygenerowaną w poprzednim kroku. Po utworzeniu pliku system dokonuje commita na odpowiedniej gałęzi GitHub z opisowym komentarzem, który odnosi się do oryginalnego ticketu. Dzięki temu powstaje trwały ślad powiązania artykułu bazy wiedzy z zapytaniem klienta, co ułatwia późniejsze odniesienia.
Krok siódmy: pull request i recenzja
Na koniec system tworzy pull request z gałęzi bazy wiedzy do głównej gałęzi repozytorium. Pull request zawiera opis zmian, numer ticketu, który je wywołał, i odpowiedni kontekst. PR jest punktem kontrolnym, w którym zespół może przejrzeć treść, wprowadzić poprawki, upewnić się, że artykuł spełnia wymagania jakościowe i jest zgodny ze strategią bazy wiedzy. Ten etap recenzji człowieka jest kluczowy — mimo że treści AI są zazwyczaj wysokiej jakości, ludzka kontrola zapewnia dokładność, spójność z marką i adekwatność. Po zaakceptowaniu pull requestu można go scalić z główną gałęzią, co uruchamia przebudowę strony w Hugo i publikację nowego artykułu.
Wdrożenie w praktyce: jak znaleźć i użyć ID ticketu
Aby skorzystać z tego workflow, musisz znaleźć odpowiedni identyfikator ticketu w LiveAgent. LiveAgent wyświetla ID ticketu w dwóch dogodnych miejscach. Po pierwsze, bezpośrednio w interfejsie znajdziesz etykietę “Ticket” z widocznym identyfikatorem, który można skopiować. Po drugie, często wygodniej jest znaleźć ID w adresie URL strony ticketu. Po otwarciu ticketu w LiveAgent, na końcu adresu URL zobaczysz parametr w formie “ID=12345”. To właśnie ten identyfikator należy podać do workflow automatyzacji. Gdy masz już ID, wystarczy wprowadzić je w workflow FlowHunt, a cały proces uruchomi się automatycznie. System pobierze ticket, przeanalizuje go, sprawdzi duplikaty, wygeneruje artykuł, utworzy branch i pull request w GitHub oraz powiadomi zespół o konieczności recenzji. Całość trwa zwykle od kilku sekund do kilku minut, w zależności od złożoności ticketu i wielkości bazy wiedzy.
Przyspiesz swój workflow z FlowHunt
Przekonaj się, jak FlowHunt automatyzuje tworzenie bazy wiedzy z ticketów wsparcia – od analizy i generowania treści, przez integrację z GitHub, po publikację w Hugo – wszystko w jednym spójnym workflow.
Po wdrożeniu podstawowego workflow możesz skorzystać z szeregu zaawansowanych opcji, by dostosować system do własnych potrzeb. Możesz skonfigurować workflow, by ignorował wybrane typy ticketów na podstawie tagów, kategorii czy słów kluczowych. Przykładowo, możesz pominąć tickety oznaczone jako “billing” lub “account-specific”, bo zwykle nie zawierają one wiedzy uniwersalnej. Możesz ustawić progi jakości lub długości artykułu — jeśli ticket jest zbyt krótki lub mało szczegółowy, system może go pominąć i poczekać na pełniejsze informacje. System pamięci można dostroić pod kątem algorytmu dopasowania — od prostego dopasowania słów kluczowych po zaawansowaną analizę semantyczną. Możesz także dostosować frontmatter i strukturę treści do własnych wymagań, dodając niestandardowe pola lub modyfikując format artykułu. Niektóre firmy dodają metadane takie jak poziom trudności, grupa docelowa czy powiązane artykuły. Możesz skonfigurować automatyczne dodawanie obrazków do artykułów (generowanych przez AI lub z własnej biblioteki). System może też tworzyć artykuły w wielu językach, jeśli obsługujesz międzynarodowych klientów. Możesz ustawić powiadomienia i zatwierdzenia, np. wymagać akceptacji artykułów z wybranych kategorii przez konkretne osoby przed publikacją.
Praktyczny przykład: błąd integracji WordPress
Przykład workflow w praktyce: klient zgłasza ticket dotyczący błędu integracji z WordPressem. Ticket zawiera komunikaty o błędach, zrzuty ekranu i szczegółowy opis prób rozwiązania. Zespół wsparcia odpowiada krokami naprawczymi i ostatecznie rozwiązuje problem. To idealny kandydat do automatyzacji bazy wiedzy. Po podaniu ID ticketu workflow pobiera całą konwersację, analizuje ją i sprawdza pamięć. Ponieważ nie istnieje jeszcze artykuł o błędach integracji WordPress, system dodaje temat do pamięci i generuje artykuł. Analizuje istniejącą bazę i wykrywa, że dla artykułów technicznych stosujesz układ: objawy, przyczyny, rozwiązania, zapobieganie. Wygenerowany artykuł zachowuje tę strukturę, tworząc kompleksowy poradnik, który pomoże kolejnym klientom rozwiązać problem samodzielnie. Artykuł trafia do brancha GitHub, generowany jest pull request, zespół go przegląda, wprowadza poprawki i scala. W ciągu kilku minut artykuł jest dostępny na stronie, zindeksowany przez wyszukiwarki i pomaga klientom. Kolejny użytkownik szukający “WordPress integration error” znajdzie Twój artykuł i rozwiąże problem bez kontaktu z supportem.
Mierzenie sukcesu i zwrotu z inwestycji
Aby uzasadnić inwestycję w automatyzację bazy wiedzy, warto mierzyć jej efekty. Kluczowe metryki to spadek liczby ticketów dotyczących zagadnień opisanych w bazie, wzrost ruchu organicznego z wyszukiwarek, zaoszczędzony czas zespołu wsparcia i wzrost satysfakcji klientów. Możesz śledzić, ilu klientów korzysta z artykułów bazy wiedzy przed kontaktem z supportem, ile ticketów odwołuje się do tych artykułów oraz ilu klientów deklaruje, że znalazło tam odpowiedź na swoje pytanie. Możesz oceniać jakość artykułów na podstawie zaangażowania użytkowników: czasu na stronie, głębokości scrollowania i współczynnika odrzuceń. Wartościowe artykuły będą miały lepsze metryki. Możesz też liczyć liczbę wygenerowanych artykułów, zaoszczędzony czas względem ręcznego tworzenia i obniżenie kosztów wsparcia. Większość firm zauważa, że automatyzacja bazy wiedzy zwraca się już w pierwszych miesiącach poprzez niższe koszty obsługi i wyższą satysfakcję klientów.
Podsumowanie
Automatyzacja tworzenia bazy wiedzy na podstawie ticketów LiveAgent to duża szansa na poprawę efektywności wsparcia, wzrost widoczności SEO strony i stworzenie wartościowego zasobu, który służy klientom długo po zakończeniu obsługi. Łącząc LiveAgent, GitHub, Hugo i automatyzację napędzaną AI przez FlowHunt, tworzysz system, który zamienia surowe zapytania w dopracowane artykuły bazy wiedzy automatycznie. Workflow jest prosty — podajesz identyfikator ticketu, a system obsługuje wszystko: generowanie treści, integrację z GitHub, tworzenie pull requestów. System pamięci chroni przed duplikatami, a etap recenzji dba o jakość i spójność z marką. Wraz z rozwojem bazy wiedzy staje się ona coraz cenniejszym zasobem, który obniża koszty wsparcia, zwiększa satysfakcję klientów i przyciąga ruch organiczny. Wdrożenie jest dostępne także dla zespołów bez głębokiej wiedzy technicznej, dzięki czemu potężna automatyzacja jest w zasięgu firm każdej wielkości.
Najczęściej zadawane pytania
Czym jest ticket LiveAgent?
Ticket LiveAgent to zgłoszenie lub zapytanie klienta zarejestrowane w systemie ticketowym LiveAgent. Każdy ticket zawiera temat, treść, tagi i pełną historię konwersacji, które mogą posłużyć do wygenerowania treści bazy wiedzy.
Jak znaleźć swój identyfikator ticketu w LiveAgent?
Identyfikator ticketu znajdziesz na dwa sposoby: (1) Poszukaj etykiety 'Ticket' z wyświetlonym ID w interfejsie LiveAgent lub (2) sprawdź końcówkę adresu URL, gdzie widnieje 'ID=twoje-id-ticketu'. Skopiuj ten identyfikator, aby użyć go w automatyzacji.
Czy workflow może ignorować określone typy ticketów?
Tak, workflow można skonfigurować tak, aby ignorował wybrane typy ticketów. Na przykład, możesz ustawić pomijanie próśb o umówienie demo, aby uniknąć tworzenia zduplikowanych stron bazy wiedzy dla podobnych tematów.
Co się stanie, jeśli podobny artykuł w bazie wiedzy już istnieje?
Workflow korzysta z pamięci, aby sprawdzić, czy podobny temat był już wcześniej przetwarzany. Jeśli znajdzie zgodność, zaktualizuje istniejący artykuł lub pominie tworzenie, aby uniknąć duplikatów.
Jak workflow integruje się z GitHub?
Workflow tworzy lub wykorzystuje istniejącą gałąź GitHub, generuje plik markdown z poprawnym frontmatterem, dokonuje commita zmian i tworzy pull request do przeglądu przed scaleniem z główną gałęzią.
Arshia jest Inżynierką Przepływów Pracy AI w FlowHunt. Z wykształceniem informatycznym i pasją do sztucznej inteligencji, specjalizuje się w tworzeniu wydajnych przepływów pracy, które integrują narzędzia AI z codziennymi zadaniami, zwiększając produktywność i kreatywność.
Arshia Kahani
Inżynierka Przepływów Pracy AI
Zautomatyzuj tworzenie swojej bazy wiedzy
Przekształcaj tickety obsługi klienta w zoptymalizowane pod SEO artykuły bazy wiedzy automatycznie dzięki przepływom AI FlowHunt.
Agent AI, które blogują i kodują za Ciebie: Automatyzacja tworzenia treści i workflow GitHub
Dowiedz się, jak agenci AI mogą automatycznie generować blogi zoptymalizowane pod SEO, tworzyć pliki markdown i wysyłać pull requesty na GitHub — wszystko na po...
Agent Obsługi Klienta AI z Bazą Wiedzy i Wzbogacaniem przez API
Ten oparty na AI workflow automatyzuje obsługę klienta poprzez łączenie wyszukiwania w wewnętrznej bazie wiedzy, pobierania informacji z Google Docs, integracji...
Automatyczne generowanie bloga WordPress za pomocą agentów AI: Kompletny przewodnik po bezobsługowym publikowaniu treści
Dowiedz się, jak zautomatyzować tworzenie, publikowanie i tagowanie blogów WordPress za pomocą agentów AI, integracji MCP oraz harmonogramowania zadań cron, aby...
16 min czytania
Automation
WordPress
+3
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.