Middleware z człowiekiem w pętli w Pythonie: Budowanie bezpiecznych agentów AI z procesami zatwierdzania
Dowiedz się, jak zaimplementować middleware z człowiekiem w pętli w Pythonie przy użyciu LangChain, aby dodać możliwości zatwierdzania, edycji i odrzucania działań agentów AI przed wykonaniem narzędzi.
Budowa agentów AI, którzy potrafią autonomicznie wykonywać narzędzia i podejmować działania, jest potężna, ale wiąże się z wrodzonym ryzykiem. Co się stanie, gdy agent zdecyduje się wysłać e-mail z błędną informacją, zatwierdzić dużą transakcję finansową lub zmodyfikować krytyczne rekordy w bazie danych? Bez odpowiednich zabezpieczeń autonomiczni agenci mogą wyrządzić poważne szkody, zanim ktokolwiek się zorientuje. Tu właśnie middleware z człowiekiem w pętli staje się niezbędny. W tym kompleksowym przewodniku pokażemy, jak zaimplementować middleware z człowiekiem w pętli w Pythonie z wykorzystaniem LangChain, umożliwiając budowę agentów AI, którzy zatrzymują się w celu uzyskania zatwierdzenia człowieka przed wykonaniem wrażliwych operacji. Dowiesz się, jak dodać procesy zatwierdzania, wdrożyć możliwości edycji i obsłużyć odrzucenia — a wszystko to przy zachowaniu efektywności i inteligencji autonomicznych systemów.
Zrozumienie pętli agenta AI i wykonywania narzędzi
Zanim zagłębimy się w middleware z człowiekiem w pętli, kluczowe jest zrozumienie, jak fundamentalnie działają agenci AI. Agent AI działa w pętli, która powtarza się do momentu, aż agent uzna, że zadanie zostało ukończone. Podstawowa pętla agenta składa się z trzech głównych elementów: modelu językowego, który rozważa co zrobić dalej, zestawu narzędzi, które agent może wywołać, aby podjąć działanie, oraz systemu zarządzania stanem, który śledzi historię konwersacji i istotny kontekst. Agent zaczyna od otrzymania wiadomości wejściowej od użytkownika, następnie model językowy analizuje tę wiadomość wraz z dostępnymi narzędziami i decyduje, czy wywołać narzędzie, czy udzielić odpowiedzi końcowej. Jeśli model zdecyduje się wywołać narzędzie, jest ono wykonywane, a wyniki są dodawane do historii rozmowy. Ten cykl powtarza się — rozumowanie modelu, wybór narzędzia, wykonanie narzędzia, integracja wyniku — aż model uzna, że nie są potrzebne kolejne wywołania narzędzi i udzieli odpowiedzi końcowej użytkownikowi.
Ten prosty, ale potężny wzorzec stał się podstawą setek frameworków agentów AI w ostatnich latach. Elegancja pętli agenta tkwi w jej elastyczności: zmieniając narzędzia dostępne dla agenta, można umożliwić mu wykonywanie zupełnie różnych zadań. Agent z narzędziami do e-maili może zarządzać komunikacją, z narzędziami do baz danych — zapytaniami i aktualizacjami rekordów, a z narzędziami finansowymi — przetwarzać transakcje. Jednak ta elastyczność wprowadza również ryzyko. Ponieważ pętla agenta działa autonomicznie, nie ma wbudowanego mechanizmu, by zatrzymać się i zapytać człowieka, czy dane działanie powinno rzeczywiście zostać podjęte. Model może zdecydować o wysłaniu e-maila, wykonaniu zapytania do bazy danych czy zatwierdzeniu transakcji finansowej, a zanim człowiek się zorientuje, działanie zostaje zakończone. Tu właśnie widać ograniczenia podstawowej pętli agenta w środowisku produkcyjnym.
Gotowy na rozwój swojej firmy?
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Dlaczego nadzór człowieka jest istotny w produkcyjnych systemach AI
Wraz z rosnącymi możliwościami agentów AI i wdrażaniem ich w rzeczywistych środowiskach biznesowych, potrzeba nadzoru człowieka staje się coraz ważniejsza. Waga działań autonomicznego agenta znacznie się różni w zależności od kontekstu. Niektóre wywołania narzędzi są niskiego ryzyka i można je wykonywać natychmiast bez przeglądu — np. odczyt e-maila czy pobranie informacji z bazy danych. Inne wywołania narzędzi są wysokiego ryzyka i potencjalnie nieodwracalne, takie jak wysyłanie komunikacji w imieniu użytkownika, przelewy środków, usuwanie rekordów czy podejmowanie zobowiązań wiążących organizację. W systemach produkcyjnych koszt błędu agenta przy operacji wysokiego ryzyka może być ogromny. Źle sformułowany e-mail wysłany do niewłaściwego odbiorcy może zaszkodzić relacjom biznesowym. Błędnie zatwierdzony budżet może prowadzić do strat finansowych. Usunięcie rekordu w bazie danych przez pomyłkę może skutkować utratą danych i koniecznością długotrwałego przywracania z kopii zapasowych.
Poza natychmiastowym ryzykiem operacyjnym występują także wymogi zgodności i regulacji. W wielu branżach wymagane jest, by określone decyzje były podejmowane lub zatwierdzane przez człowieka. Instytucje finansowe muszą mieć nadzór człowieka przy transakcjach powyżej określonego progu. Służba zdrowia wymaga przeglądu automatycznych decyzji przez człowieka. Kancelarie prawne muszą mieć pewność, że komunikacja jest przeglądana zanim zostanie wysłana w imieniu klienta. Wymogi te nie są tylko biurokratyczną formalnością — istnieją, ponieważ skutki w pełni autonomicznych decyzji w tych dziedzinach mogą być poważne. Dodatkowo, nadzór człowieka stanowi mechanizm informacji zwrotnej, który pomaga w ulepszaniu agenta. Gdy człowiek przegląda proponowane przez agenta działania i zatwierdza je lub sugeruje poprawki, ta informacja zwrotna może być użyta do udoskonalania promptów, logiki wyboru narzędzi czy trenowania modeli. Tworzy to pozytywny cykl — agent staje się bardziej niezawodny i lepiej dopasowany do potrzeb oraz tolerancji ryzyka organizacji.
Czym jest middleware z człowiekiem w pętli?
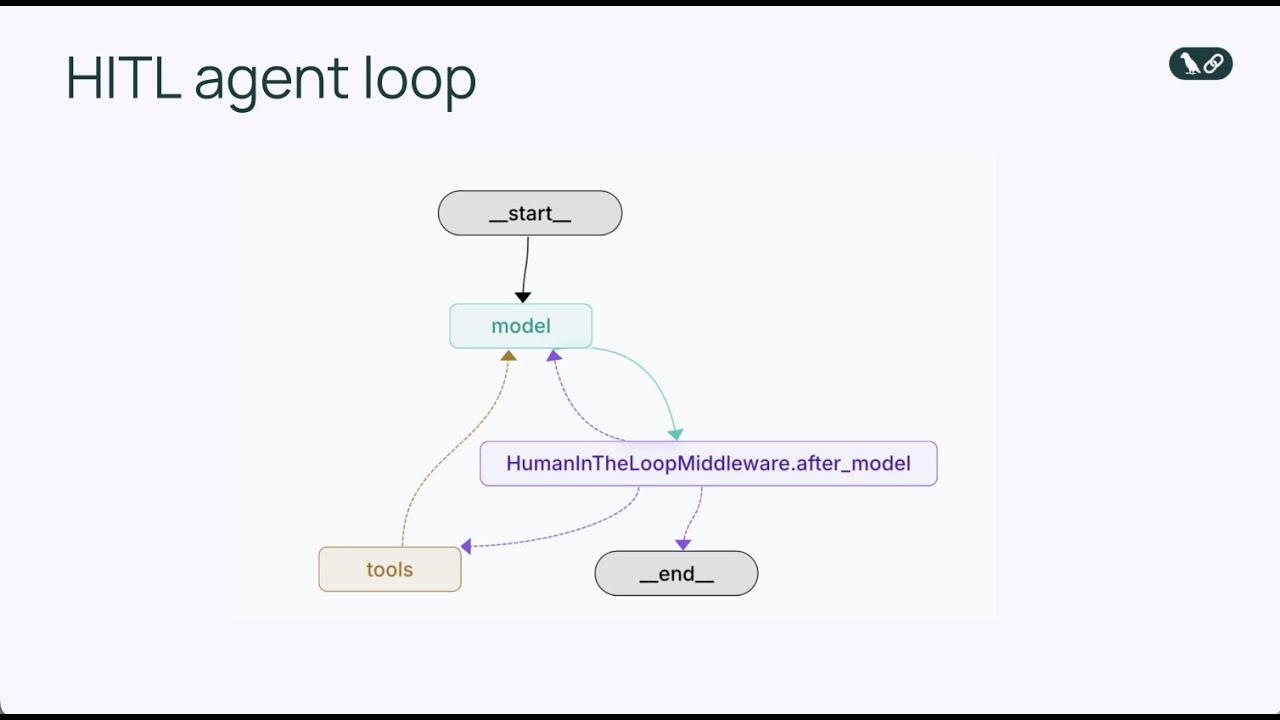
Middleware z człowiekiem w pętli to specjalistyczny komponent, który przechwytuje pętlę agenta w kluczowym momencie: tuż przed wykonaniem narzędzia. Zamiast pozwalać agentowi od razu uruchomić narzędzie, middleware zatrzymuje wykonanie i prezentuje proponowane działanie człowiekowi do przeglądu. Człowiek ma wtedy kilka opcji odpowiedzi. Może zatwierdzić działanie, pozwalając na jego wykonanie dokładnie tak, jak zaproponował agent. Może edytować działanie, modyfikując parametry (np. zmieniając odbiorcę e-maila lub treść wiadomości) przed wykonaniem. Może też całkowicie odrzucić działanie, wysyłając agentowi informację zwrotną, dlaczego działanie było nieodpowiednie i prosząc o ponowne rozważenie podejścia. Ten trójdzielny mechanizm — zatwierdzenie, edycja, odrzucenie — zapewnia elastyczność i możliwość dostosowania poziomu nadzoru człowieka.
Middleware działa poprzez modyfikację standardowej pętli agenta, dodając dodatkowy punkt decyzyjny. W podstawowej pętli agenta sekwencja wygląda tak: model wywołuje narzędzia → narzędzia się wykonują → wyniki wracają do modelu. Z middleware z człowiekiem w pętli: model wywołuje narzędzia → middleware przechwytuje → człowiek przegląda → człowiek decyduje (zatwierdź/edytuj/odrzuć) → jeśli zatwierdzone lub edytowane, narzędzie się wykonuje → wynik wraca do modelu. Wstawienie tego punktu decyzyjnego nie przerywa pętli agenta; wręcz przeciwnie, wzmacnia ją, dodając zawór bezpieczeństwa. Middleware jest konfigurowalny — można określić, które narzędzia mają wymagać przeglądu człowieka, a które mogą być wykonywane automatycznie. Możesz np. wymagać przerywania dla wszystkich narzędzi do wysyłania e-maili, ale pozwolić na automatyczne wykonanie zapytań tylko do odczytu z bazy danych. Taka szczegółowa kontrola sprawia, że nadzór człowieka pojawia się dokładnie tam, gdzie jest potrzebny, bez wprowadzania zbędnych blokad dla operacji niskiego ryzyka.
Dołącz do naszego newslettera
Otrzymuj najnowsze wskazówki, trendy i oferty za darmo.
Trzy typy odpowiedzi: Zatwierdzenie, Edycja i Odrzucenie
Gdy middleware z człowiekiem w pętli przerywa wykonywanie narzędzia przez agenta, człowiek ma trzy podstawowe formy odpowiedzi, z których każda służy innemu celowi w procesie zatwierdzania. Zrozumienie tych typów odpowiedzi jest kluczowe przy projektowaniu skutecznych systemów z człowiekiem w pętli.
Zatwierdzenie to najprostszy typ odpowiedzi. Gdy człowiek przegląda proponowane wywołanie narzędzia i uznaje, że jest ono właściwe i powinno zostać wykonane dokładnie tak, jak zaproponował agent, wydaje decyzję o zatwierdzeniu. Sygnał ten mówi middleware, że narzędzie należy wykonać z dokładnie takimi parametrami, jakie wskazał agent. W przypadku asystenta e-mailowego, zatwierdzenie oznacza, że szkic e-maila jest poprawny i powinien zostać wysłany do wybranego odbiorcy z podanym tematem i treścią. Zatwierdzenie to ścieżka najmniejszego oporu — pozwala, by zaproponowane przez agenta działanie zostało wykonane bez zmian. Jest to odpowiednie, gdy agent wykonał swoją pracę dobrze, a człowiek zgadza się z propozycją. Decyzje o zatwierdzeniu podejmowane są zwykle szybko, co jest ważne, by przegląd człowieka nie stał się wąskim gardłem spowalniającym proces.
Edycja to bardziej złożony typ odpowiedzi, uznający, że ogólne podejście agenta jest poprawne, ale niektóre szczegóły wymagają poprawienia przed wykonaniem. Gdy człowiek wybiera odpowiedź edycji, nie odrzuca decyzji agenta o działaniu, lecz doprecyzowuje szczegóły tego działania. W scenariuszu e-mailowym edycja może oznaczać zmianę adresu odbiorcy, modyfikację tematu na bardziej profesjonalny lub dostosowanie treści wiadomości — np. dodanie dodatkowego kontekstu lub usunięcie potencjalnie problematycznych sformułowań. Kluczową cechą odpowiedzi edycji jest modyfikacja parametrów narzędzia przy zachowaniu tej samej operacji. Agent zdecydował o wysłaniu e-maila, człowiek zgadza się, że to właściwe działanie, ale chce dostosować, co e-mail zawiera lub do kogo jest wysyłany. Po dokonaniu przez człowieka edycji narzędzie wykonuje się z poprawionymi parametrami, a wynik wraca do agenta. To bardzo cenne podejście, bo pozwala agentowi proponować działania, a człowiekowi — dopracowywać je zgodnie z wiedzą ekspercką i kontekstem organizacyjnym.
Odrzucenie to najbardziej znaczący typ odpowiedzi, ponieważ nie tylko wstrzymuje wykonanie proponowanego działania, ale także przekazuje agentowi informację zwrotną, dlaczego działanie było nieodpowiednie. Gdy człowiek odrzuca wywołanie narzędzia, oznacza to, że proponowanego działania nie należy podejmować w ogóle, a agent otrzymuje wskazówkę, jak powinien zmienić podejście. W przykładzie e-maila odrzucenie może mieć miejsce, gdy agent proponuje wysłanie e-maila zatwierdzającego duży budżet bez wystarczających szczegółów lub uzasadnienia. Człowiek odrzuca to działanie i wysyła wiadomość do agenta, że najpierw potrzebne są szczegóły. Ta wiadomość odrzucająca staje się częścią kontekstu agenta, który może teraz rozważyć tę informację i zaproponować inne podejście. Agent może wtedy np. zaproponować nowego e-maila z prośbą o więcej informacji o budżecie. Odrzucenie jest kluczowe, by zapobiec wielokrotnemu proponowaniu nieodpowiednich działań przez agenta. Jasna informacja zwrotna pomaga agentowi uczyć się i poprawiać decyzje.
Implementacja middleware z człowiekiem w pętli: Praktyczny przykład
Przejdźmy przez konkretną implementację middleware z człowiekiem w pętli przy użyciu LangChain i Pythona. Przykładem będzie asystent e-mailowy — praktyczny scenariusz, który jasno pokazuje wartość nadzoru człowieka i jest łatwy do zrozumienia. Asystent będzie mógł wysyłać e-maile w imieniu użytkownika, a my dodamy middleware z człowiekiem w pętli, by każda wysyłka była przeglądana przed wykonaniem.
Najpierw zdefiniujemy narzędzie do wysyłania e-maili, z trzema parametrami: adres odbiorcy, temat i treść e-maila. Narzędzie jest proste — reprezentuje czynność wysyłania e-maila. W realnym wdrożeniu mogłoby być zintegrowane np. z Gmailem czy Outlookiem, ale w przykładzie uprośćmy je:
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Wyślij e-mail do wskazanego odbiorcy."""returnf"E-mail wysłany do {recipient} z tematem '{subject}'"
Następnie tworzymy agenta korzystającego z tego narzędzia. Użyjemy GPT-4 jako modelu językowego i podamy prompt systemowy określający agenta jako pomocnego asystenta e-mailowego. Agent jest inicjalizowany z narzędziem do wysyłania e-maili i gotowy do obsługi żądań użytkownika:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Jesteś pomocnym asystentem e-mailowym dla Sydney. Możesz wysyłać e-maile w imieniu użytkownika.")
W tym momencie mamy prostego agenta, który może wysyłać e-maile, ale nie ma nadzoru człowieka — agent może wysyłać e-maile bez przeglądu. Teraz dodajemy middleware z człowiekiem w pętli. Implementacja jest niezwykle prosta i wymaga tylko dwóch linii:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Jesteś pomocnym asystentem e-mailowym dla Sydney. Możesz wysyłać e-maile w imieniu użytkownika.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
Dodając HumanInTheLoopMiddleware i określając interrupt_on={"send_email": True}, mówimy agentowi, by zatrzymał się przed wykonaniem dowolnego wywołania send_email i poczekał na zatwierdzenie człowieka. Wartość True oznacza, że każde wywołanie send_email wywoła przerwanie z domyślną konfiguracją. Jeśli chcielibyśmy większą kontrolę, możemy określić, jakie typy decyzji są dozwolone (zatwierdź, edytuj, odrzuć) lub dodać własny opis przerwania.
Testowanie middleware w scenariuszach niskiego ryzyka
Po wdrożeniu middleware przetestujmy go w scenariuszu niskiego ryzyka. Wyobraźmy sobie, że użytkownik prosi agenta o odpowiedź na nieformalny e-mail od koleżanki Alicji, która proponuje kawę w przyszłym tygodniu. Agent przetwarza żądanie i decyduje o wysłaniu przyjaznej odpowiedzi. Oto co się dzieje:
Użytkownik wysyła wiadomość: “Odpowiedz Alicji na jej e-mail o kawie w przyszłym tygodniu.”
Model językowy agenta przetwarza prośbę i decyduje o wywołaniu narzędzia send_email z parametrami np. recipient=“alice@example.com
”, subject=“Kawa w przyszłym tygodniu?”, body=“Chętnie umówię się z Tobą na kawę w przyszłym tygodniu!”
Zanim e-mail zostanie wysłany, middleware przechwytuje wywołanie i zgłasza przerwanie.
Człowiek widzi przygotowanego e-maila i przegląda go. Wiadomość wygląda odpowiednio — jest przyjazna, profesjonalna i spełnia prośbę użytkownika.
Człowiek zatwierdza działanie.
Middleware pozwala na wykonanie narzędzia, e-mail zostaje wysłany.
Ten przepływ pokazuje podstawową ścieżkę zatwierdzania. Przegląd człowieka dodaje warstwę bezpieczeństwa bez znaczącego spowolnienia procesu. W operacjach niskiego ryzyka zatwierdzenie następuje zwykle szybko, ponieważ propozycja agenta jest rozsądna i nie wymaga zmian.
Testowanie middleware w scenariuszach wysokiego ryzyka: Odpowiedź edycji
Teraz rozważmy poważniejszy scenariusz, gdzie edycja jest szczególnie cenna. Załóżmy, że agent otrzymuje prośbę o odpowiedź na e-mail od partnera startupu z żądaniem zatwierdzenia budżetu inżynieryjnego na 1 mln dolarów na Q1. To decyzja wysokiego ryzyka, wymagająca przemyślenia. Agent może zaproponować e-mail o treści: “Przejrzałem i zatwierdzam propozycję budżetu inżynieryjnego na 1 mln dolarów na Q1.”
Gdy ten e-mail trafia do człowieka przez middleware, człowiek rozpoznaje, że to poważne zobowiązanie finansowe, którego nie należy zatwierdzać pochopnie. Człowiek nie chce odrzucać samej idei odpowiedzi, ale chce zmodyfikować treść na bardziej ostrożną. Człowiek wybiera odpowiedź edycji, zmieniając treść e-maila na: “Dziękuję za propozycję. Chciałbym dokładniej przeanalizować szczegóły przed wydaniem zgody. Czy możesz przesłać szczegółowy podział budżetu?”
Przykład odpowiedzi edycji w kodzie:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Propozycja budżetu inżynieryjnego na Q1",
"body": "Dziękuję za propozycję. Chciałbym dokładniej przeanalizować szczegóły przed wydaniem zgody. Czy możesz przesłać szczegółowy podział budżetu?" }
}
}
Po otrzymaniu decyzji edycji middleware wykonuje narzędzie z poprawionymi parametrami. E-mail zostaje wysłany z treścią zmienioną przez człowieka, co jest właściwe w przypadku decyzji finansowych wysokiego ryzyka. To pokazuje siłę odpowiedzi edycji: pozwala człowiekowi wykorzystać umiejętność agenta do tworzenia szkiców komunikacji, ale zapewnia, że finalny efekt odzwierciedla osąd człowieka i standardy organizacji.
Testowanie middleware z odrzuceniem i informacją zwrotną
Odpowiedź odrzucenia jest szczególnie mocna, bo nie tylko blokuje nieodpowiednie działanie, ale też daje agentowi informację zwrotną pomagającą poprawić rozumowanie. Rozważmy ponownie scenariusz z e-mailem dotyczącym budżetu. Załóżmy, że agent proponuje e-mail: “Przejrzałem i zatwierdzam budżet inżynieryjny na 1 mln dolarów na Q1.”
Człowiek widzi tę propozycję i wie, że jest zbyt pochopna. Zobowiązanie na 1 mln dolarów nie powinno być zatwierdzane bez dogłębnej analizy, rozmów ze stronami i poznania szczegółów budżetu. Człowiek nie chce tylko edytować e-maila, lecz całkowicie odrzucić to podejście i poprosić agenta o przemyślenie zadania. Człowiek wybiera odpowiedź odrzucenia z informacją zwrotną:
reject_decision = {
"type": "reject",
"message": "Nie mogę zatwierdzić tego budżetu bez dodatkowych informacji. Proszę przygotuj e-mail z prośbą o szczegółowy podział propozycji, w tym o rozbicie środków pomiędzy zespoły inżynieryjne oraz określenie konkretnych rezultatów."}
Po otrzymaniu odrzucenia middleware nie wykonuje narzędzia. Zamiast tego przekazuje wiadomość odrzucającą agentowi jako część kontekstu rozmowy. Agent widzi, że jego propozycja została odrzucona i wie dlaczego. Może teraz rozważyć informację zwrotną i zaproponować inne podejście. W tym przypadku agent może zaproponować nowego e-maila z prośbą o szczegóły dotyczące budżetu, co jest bardziej odpowiednie w przypadku prośby finansowej wysokiego ryzyka. Człowiek może następnie zatwierdzić zmodyfikowaną propozycję, dalej ją edytować lub ponownie odrzucić.
Ten iteracyjny proces — propozycja, przegląd, odrzucenie z informacją zwrotną, kolejna propozycja — jest jedną z największych zalet middleware z człowiekiem w pętli. Tworzy współpracę, w której szybkość i rozumowanie agenta są połączone z osądem człowieka i wiedzą ekspercką.
Przyspiesz swój workflow z FlowHunt
Zobacz, jak FlowHunt automatyzuje przepływy treści i SEO oparte o AI — od researchu i generowania treści po publikację i analitykę — wszystko w jednym miejscu.
Zaawansowana konfiguracja: Szczegółowa kontrola przerwań
Podstawowa implementacja middleware z człowiekiem w pętli jest prosta, ale LangChain oferuje również zaawansowane opcje konfiguracji, pozwalające precyzyjnie określić, jak i kiedy mają występować przerwania. Jedną z ważnych opcji jest określenie, jakie typy decyzji są dostępne dla danego narzędzia. Możesz np. dopuścić zatwierdzenie i edycję dla e-maili, ale nie odrzucenie. Albo dopuścić wszystkie trzy dla transakcji finansowych, ale tylko zatwierdzenie dla zapytań tylko do odczytu.
Przykład bardziej szczegółowej konfiguracji:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Automatyczne wykonanie, brak przerwania"delete_record": {
"allowed_decisions": ["approve", "reject"] # Brak edycji przy usuwaniu }
}
)
]
)
W tej konfiguracji wysyłanie e-maili będzie przerywane i pozwoli na wszystkie trzy typy decyzji. Operacje odczytu wykonują się automatycznie bez przerwania. Usuwanie rekordów przerywa, ale nie pozwala na edycję — człowiek może tylko zatwierdzić lub odrzucić, bez modyfikacji parametrów. Taka szczegółowa kontrola umożliwia dodanie nadzoru człowieka tam, gdzie to potrzebne, bez wprowadzania zbędnych wąskich gardeł przy operacjach niskiego ryzyka.
Kolejną funkcją zaawansowaną jest możliwość podania własnych opisów przerwań. Domyślnie middleware wyświetla ogólny opis typu “Wykonanie narzędzia wymaga zatwierdzenia”. Możesz spersonalizować opis, by lepiej dopasować go do danego kontekstu:
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"],
"description": "Wysyłka e-maili wymaga zatwierdzenia przez człowieka przed wykonaniem" }
}
)
Ważne aspekty implementacyjne: Checkpointery i zarządzanie stanem
Jednym z kluczowych aspektów wdrożenia middleware z człowiekiem w pętli, który łatwo przeoczyć, jest potrzeba checkpointera. Checkpointer to mechanizm zapisujący stan agenta w momencie przerwania, umożliwiający wznowienie workflow później. To niezbędne, bo przegląd człowieka nie następuje natychmiast — może minąć trochę czasu między przerwaniem a wydaniem decyzji przez człowieka. Bez checkpointera stan agenta zostałby utracony, a workflow nie można byłoby poprawnie wznowić.
LangChain oferuje kilka opcji checkpointerów. Do developmentu i testów możesz użyć checkpointera w pamięci:
W środowiskach produkcyjnych najlepiej użyć trwałego checkpointera zapisującego stan do bazy danych lub pliku, by przerwania można było wznowić nawet po restarcie aplikacji. Checkpointer utrzymuje pełny zapis stanu agenta na każdym etapie, w tym historię rozmowy, wywołania narzędzi i ich wyniki. Gdy człowiek wydaje decyzję (zatwierdzenie, edycja, odrzucenie), middleware pobiera zapisany stan, stosuje decyzję i wznawia pętlę agenta od tego miejsca.
Zastosowania i scenariusze z rzeczywistości
Middleware z człowiekiem w pętli znajduje zastosowanie w wielu rzeczywistych scenariuszach, gdzie autonomiczni agenci podejmują działania wymagające nadzoru człowieka. W finansach agenci przetwarzający transakcje, zatwierdzający pożyczki czy zarządzający inwestycjami mogą korzystać z middleware, by decyzje wysokiej wartości były przeglądane przez uprawnione osoby przed realizacją. W ochronie zdrowia agenci rekomendujący leczenie czy mający dostęp do danych pacjentów mogą wykorzystywać middleware do zapewnienia zgodności z przepisami i protokołami klinicznymi. W sektorze prawnym agenci piszący korespondencję lub mający dostęp do poufnych dokumentów mogą używać middleware, by zapewnić nadzór adwokata. W obsłudze klienta agenci dokonujący zwrotów, podejmujący zobowiązania czy eskalujący sprawy mogą stosować middleware, by działania były zgodne z polityką firmy.
Poza branżowymi zastosowaniami, middleware z człowiekiem w pętli sprawdza się wszędzie tam, gdzie koszt pomyłki agenta jest znaczący. Dotyczy to m.in. systemów moderacji treści (usuwanie treści generowanych przez użytkowników), działów HR (decyzje kadrowe), czy łańcuchów dostaw (składanie zamówień, zmiany w zapasach). Wspólnym mianownikiem tych przypadków jest to, że działania proponowane przez agenta mają realne konsekwencje i warto, by przed ich realizacją przeglądał je człowiek.
Porównanie z alternatywnymi podejściami
Warto rozważyć, jak middleware z człowiekiem w pętli wypada na tle alternatywnych metod wprowadzania nadzoru człowieka. Jedną z opcji jest przeglądanie wszystkich działań agenta przez człowieka po ich wykonaniu, ale to rozwiązanie ma poważne wady. W momencie przeglądu przez człowieka działanie mogło już wywołać nieodwracalne skutki — e-mail już wysłano, rekord usunięto, transakcję zrealizowano. Middleware z człowiekiem w pętli zapobiega takim sytuacjom, blokując je przed realizacją.
Innym podejściem jest ręczne wykonywanie wszystkich czynności przez człowieka, co jednak niweczy sens posiadania agenta. Agenci są cenni właśnie dlatego, że mogą szybko i sprawnie wykonywać rutynowe zadania, pozwalając ludziom skupić się na decyzjach wyższego poziomu. Celem middleware jest znalezienie równowagi: agenci wykonują rutynę, ale przy operacjach wysokiego ryzyka zatrzymują się na przegląd człowieka.
Trzecią opcją jest wdrożenie reguł (guardrails) lub walidacji, blokujących nieodpowiednie
Najczęściej zadawane pytania
Middleware z człowiekiem w pętli to komponent, który zatrzymuje wykonywanie agenta AI przed uruchomieniem określonych narzędzi, umożliwiając człowiekowi zatwierdzenie, edycję lub odrzucenie proponowanego działania. Dodaje to warstwę bezpieczeństwa dla kosztownych lub ryzykownych operacji.
Stosuj go przy operacjach wysokiego ryzyka, takich jak wysyłanie e-maili, transakcje finansowe, zapisy do bazy danych lub jakiekolwiek wykonywanie narzędzi wymagających nadzoru pod kątem zgodności, albo których błędne wykonanie mogłoby mieć poważne konsekwencje.
Trzy główne typy odpowiedzi to: Zatwierdzenie (wykonanie narzędzia jak zaproponowano), Edycja (modyfikacja parametrów narzędzia przed wykonaniem) oraz Odrzucenie (odmowa wykonania i odesłanie informacji zwrotnej do modelu do poprawy).
Zaimportuj HumanInTheLoopMiddleware z langchain.agents.middleware, skonfiguruj z narzędziami, na których chcesz przerywać działanie, i przekaż do funkcji tworzenia agenta. Potrzebny będzie także checkpointer do utrzymania stanu pomiędzy przerwami.
Arshia jest Inżynierką Przepływów Pracy AI w FlowHunt. Z wykształceniem informatycznym i pasją do sztucznej inteligencji, specjalizuje się w tworzeniu wydajnych przepływów pracy, które integrują narzędzia AI z codziennymi zadaniami, zwiększając produktywność i kreatywność.
Arshia Kahani
Inżynierka Przepływów Pracy AI
Automatyzuj swoje przepływy AI bezpiecznie z FlowHunt
Twórz inteligentnych agentów z wbudowanymi procesami zatwierdzania i nadzorem człowieka. FlowHunt umożliwia łatwą implementację automatyzacji z człowiekiem w pętli dla procesów biznesowych.
Budowanie rozszerzalnych agentów AI: Dogłębne spojrzenie na architekturę middleware
Dowiedz się, jak architektura middleware w LangChain 1.0 rewolucjonizuje rozwój agentów, umożliwiając programistom budowę potężnych, rozszerzalnych głębokich ag...
Zintegruj FlowHunt z MCP Run Python, aby bezpiecznie wykonywać kod Pythona w odizolowanym środowisku. Wykorzystaj Pyodide i Deno do bezpiecznego, zdalnego uruch...
Zintegruj FlowHunt z ForeverVM MCP Server, aby umożliwić dynamiczne tworzenie REPL Pythona, bezpieczne wykonywanie kodu oraz automatyczne zarządzanie sesjami dl...
4 min czytania
AI
ForeverVM
+4
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.