Dowiedz się, jak ustawić parametry ‘Od H1 jeśli istnieje’, ‘Ładuj od wskaźnika’ oraz ‘Pomiń ostatni nagłówek’.
Document Retriever
AI knowledge base
Knowledge Sources
Components
Guide
Jak skonfigurować Document Retriever:
Select section...
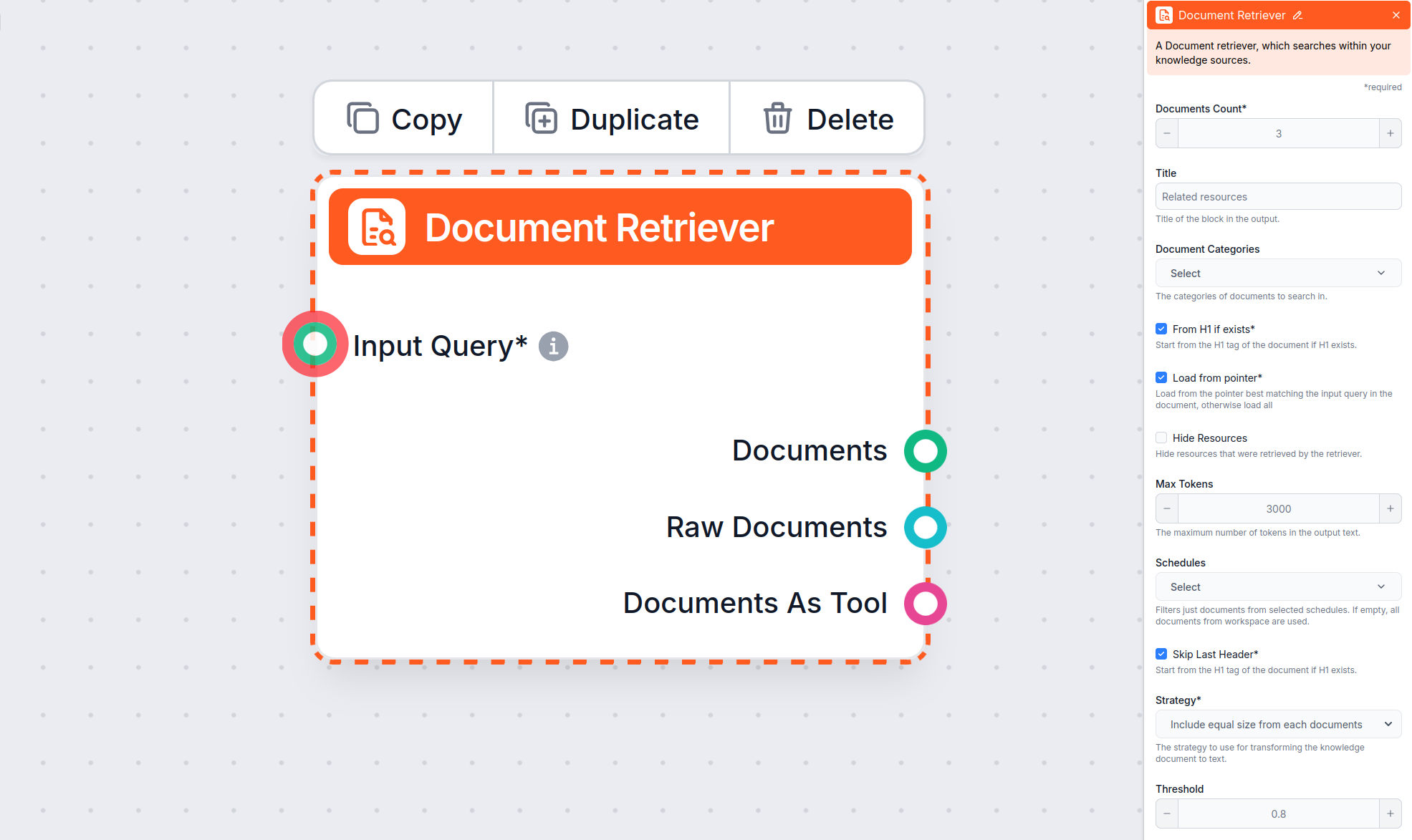
Od H1 jeśli istnieje – Rozpocznij ekstrakcję od głównego tytułu
Ładuj od wskaźnika – Wyodrębnij od określonego miejsca
Pomiń ostatni nagłówek – Wyklucz stopkę lub powtarzające się nagłówki
Maksymalna liczba tokenów – Kontrola długości wyjściowej
Strategia – Kontrola sposobu łączenia wielu dokumentów w tekst
Inne parametry Document Retriever
Liczba dokumentów
Kategorie dokumentów
Ukryj zasoby
Harmonogramy
Próg trafności
Rozwiązywanie problemów
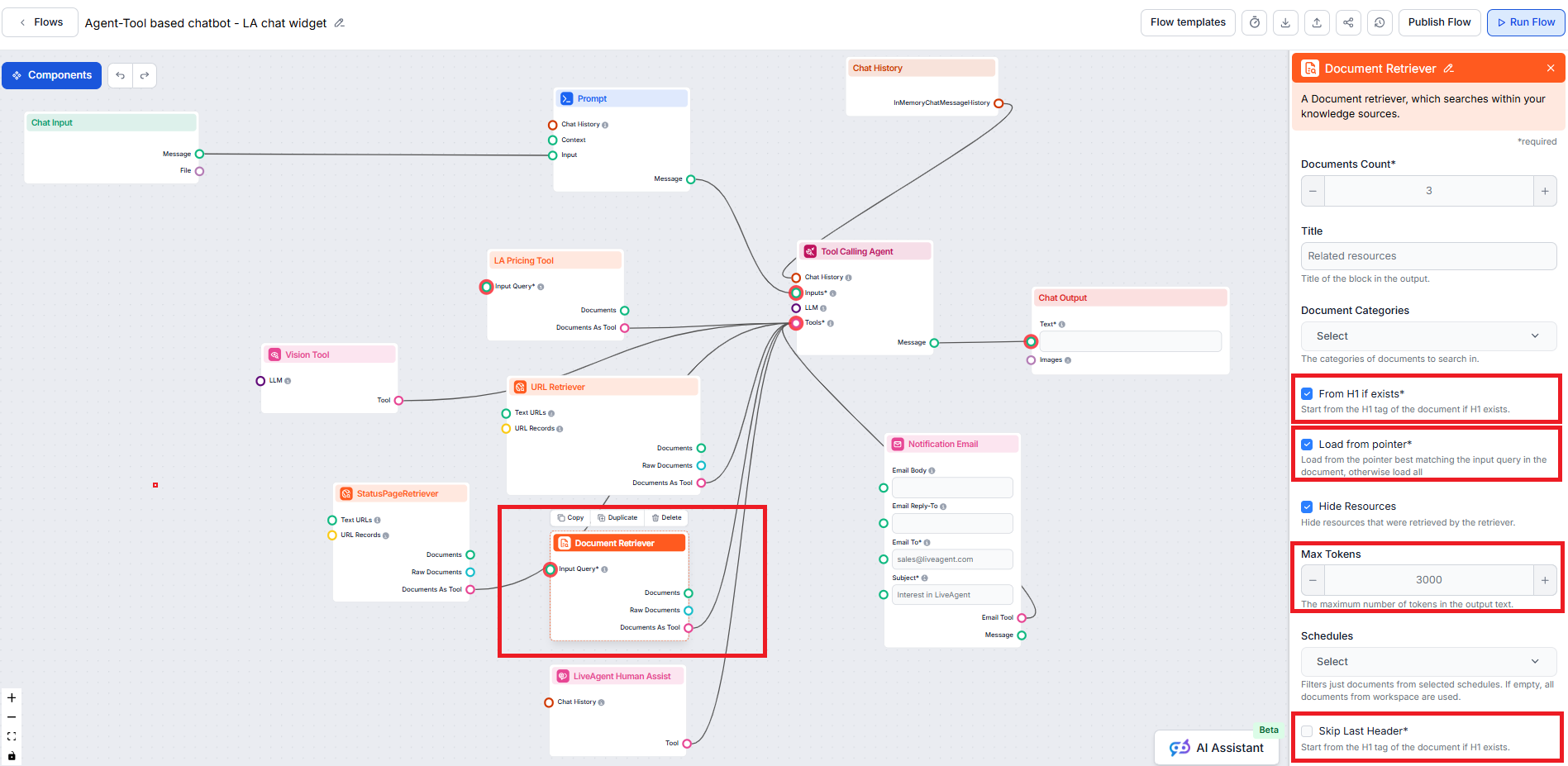
Komponent Document Retriever
pozwala chatbotowi pobierać wiedzę ze źródeł, które określiłeś w sekcji Dokumenty i Harmonogramy. Rolą tego komponentu jest kontrola procesu pobierania, a wiele parametrów wpływa na to, jak informacje z tych dokumentów są pozyskiwane.
Od H1 jeśli istnieje – Rozpocznij ekstrakcję od głównego tytułu
Opcja Od H1 jeśli istnieje nakazuje retrieverowi rozpoczęcie wyodrębniania treści od nagłówka H1, który znajdzie (zwykle główny tytuł artykułu).
Co się dzieje?
Jeśli zaznaczone: Wszystko przed pierwszym H1 (np. nawigacja, okruszki, linki logowania) jest ignorowane. Ekstrakcja zaczyna się od głównej treści artykułu.
Jeśli odznaczone: Wyodrębnianie treści zaczyna się od samej góry strony, obejmując całą nawigację, nagłówki i wszelkie metadane powyżej głównego artykułu.
Przykład użycia: Chcesz pobrać wyłącznie właściwy przewodnik, bez zbędnych elementów nawigacyjnych lub nagłówka strony, które występują na Twojej witrynie.
Uwaga: Opcja Od H1 jeśli istnieje jest domyślnie włączona w komponencie Document Retriever.
Ładuj od wskaźnika – Wyodrębnij od określonego miejsca
Opcja Ładuj od wskaźnika daje większą precyzję, pozwalając Document Retrieverowi ładować dane tylko od wybranego wskaźnika w potencjalnie dłuższym artykule.
Co się dzieje?
Jeśli zaznaczone (i ustawiono wskaźnik): Ekstrakcja zaczyna się od wskazanego wskaźnika, pomijając wszystko przed nim, nawet jeśli znajduje się po H1.
Jeśli odznaczone: Ekstrakcja zaczyna się od pozycji domyślnej (góra dokumentu lub od pierwszego H1, jeśli ta opcja też jest wybrana).
Czym jest „wskaźnik”? Wskaźnik to zazwyczaj unikalny ciąg znaków lub nagłówek obecny w dokumencie (np. H2 lub konkretna fraza bądź tytuł sekcji).
Przykład użycia: Chcesz pominąć sekcje wstępne i pobrać informacje dla konkretnej, istotnej sekcji w potencjalnie długim artykule lub dokumencie (np. od „Krok 4: Dodaj przycisk czatu na żywo” w przewodniku konfiguracji).
Gotowy na rozwój swojej firmy?
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Pomiń ostatni nagłówek – Wyklucz stopkę lub powtarzające się nagłówki
Opcja Pomiń ostatni nagłówek jest przydatna, gdy chcesz zignorować ostatni nagłówek w dokumencie, który często jest powtarzany lub służy do nawigacji bądź jako stopka.
Co się dzieje?
Jeśli zaznaczone: Ostatni nagłówek (np. powtórzony tytuł artykułu lub sekcja „Inne artykuły”) jest pomijany podczas ekstrakcji.
Jeśli odznaczone: Wszystkie nagłówki, w tym ostatni, są uwzględnione w wyniku.
Przykład użycia: Chcesz, aby Document Retriever nie ładował nagłówka stopki nawigacyjnej (np. „Inne artykuły” na końcu strony pomocy), zapewniając przetwarzanie wyłącznie głównej treści.
Uwaga: Pomiń ostatni nagłówek pomaga w dokumentach, które automatycznie generują stopki lub powtarzalne elementy nawigacyjne. Jednak jeśli nie masz takich sekcji, użycie tego parametru może sprawić, że część artykułu zawierająca ważne informacje nie zostanie pobrana. Dlatego zaleca się pozostawienie tej opcji odznaczonej, dopóki nie pojawi się uzasadniony powód, by ją włączyć.
Maksymalna liczba tokenów – Kontrola długości wyjściowej
Parametr Maksymalna liczba tokenów pozwala określić maksymalną liczbę tokenów (słów i znaków interpunkcyjnych zliczanych przez model AI), które Document Retriever zwróci z wyodrębnionego tekstu.
Co się dzieje?
Wyodrębniona zawartość ograniczona jest do określonej liczby tokenów. Nadmiarowa treść przekraczająca limit zostanie ucięta i nie pojawi się w wyniku.
Parametr ten pomaga zarządzać bardzo długimi dokumentami, zapewniając, że wynik mieści się w granicach przetwarzania modeli AI.
Wartość domyślna: Domyślnie jest to zwykle 3000 tokenów, ale można ją dostosować według potrzeb.
Przykład użycia: Jeśli przetwarzasz obszerne dokumenty, ustawienie niższej wartości maksymalnej liczby tokenów pomaga uzyskać zwięzłe odpowiedzi. Dla najlepszych efektów warto jednak rozważyć włączenie parametru „Ładuj od wskaźnika”. Dzięki temu wyodrębniony tekst zacznie się od najbardziej istotnej sekcji dokumentu, a nie od początku, co umożliwi uzyskanie skupionej i łatwej do zarządzania porcji informacji w wyznaczonym limicie tokenów. To połączenie jest szczególnie przydatne, gdy zależy Ci na zwięzłych, kontekstowo istotnych odpowiedziach z dużych źródeł.
Uwaga: Jeśli zauważysz, że informacje są ucinane, spróbuj zwiększyć wartość maksymalnej liczby tokenów. Jeśli natomiast zależy Ci na krótszych, bardziej precyzyjnych wynikach, zmniejsz ten parametr.
Dołącz do naszego newslettera
Otrzymuj najnowsze wskazówki, trendy i oferty za darmo.
Strategia – Kontrola sposobu łączenia wielu dokumentów w tekst
Gdy Document Retriever znajdzie kilka odpowiednich dokumentów, parametr Strategia decyduje, jak zostaną one połączone w jeden wynik tekstowy dla Twojego chatbota, uwzględniając limit „Maksymalna liczba tokenów”.
Dwie opcje strategii:
Uwzględnij równą część z każdego dokumentu: Limit tokenów jest dzielony równomiernie. Na przykład, przy trzech dokumentach i limicie 3000 tokenów, każdy otrzyma do 1000 tokenów. Zapewnia to równy wkład wszystkich źródeł, co jest przydatne, gdy zależy Ci na zbalansowanej odpowiedzi opartej na różnych dokumentach.
Stosuj, gdy: Masz dokumentację, w której różne aspekty tematu rozproszone są po wielu dokumentach, a stworzenie kompleksowej odpowiedzi wymaga czerpania z kilku źródeł jednocześnie. Podejście to sprawdza się, gdy żaden dokument nie zawiera wszystkich potrzebnych szczegółów, a zależy Ci na reprezentacji informacji z każdego istotnego źródła w odpowiedzi, zapewniając różnorodność lub szeroką perspektywę.
Łącz dokumenty, wypełnij od pierwszego do limitu tokenów: Dokumenty są dodawane według trafności do momentu osiągnięcia limitu tokenów. Najbardziej trafny dokument wypełnia przestrzeń jako pierwszy; jeśli pozostanie miejsce, dodawane są kolejne, mniej trafne. Jeśli pierwszy dokument jest obszerny, może wykorzystać cały limit samodzielnie.
Stosuj, gdy: Masz dokumentację zawierającą szczegółowe informacje o każdym temacie w jednym dokumencie i odpowiedzi na pytania skorzystają z jak największej ilości treści z tego dokumentu, zamiast łączyć informacje z wielu źródeł o podobnej tematyce.
Jak wybrać?
Wybierz Uwzględnij równą część z każdego dokumentu, jeśli chcesz, by wszystkie źródła były równomiernie reprezentowane.
Wybierz Łącz dokumenty, wypełnij od pierwszego do limitu tokenów, jeśli priorytetem jest najtrafniejszy dokument, a mniej zależy Ci na uwzględnieniu każdego źródła.
Uwaga: Te strategie wpływają jedynie na sposób budowania tekstu z pobranych dokumentów przed przekazaniem go do kolejnego kroku (np. generowania AI). Nie zmieniają tego, które dokumenty są pobierane, a jedynie sposób ich łączenia i skracania do ustawionego limitu tokenów.
Inne parametry Document Retriever
Chociaż ten artykuł koncentruje się na ustawieniach ‘Od H1 jeśli istnieje’, ‘Ładuj od wskaźnika’, ‘Pomiń ostatni nagłówek’ i ‘Maksymalna liczba tokenów’, Document Retriever oferuje także dodatkowe parametry, które pomagają kontrolować wybór i pobieranie dokumentów:
Liczba dokumentów
To ustawienie ogranicza liczbę dokumentów, które przepływ powinien pobierać, zapewniając trafność wyników i szybsze generowanie odpowiedzi.
Kategorie dokumentów
Opcjonalne ustawienie pozwalające ograniczyć pobieranie do jednej lub więcej kategorii utworzonych przez Ciebie w sekcji Dokumenty w Źródłach Wiedzy.
Ukryj zasoby
Pozwala dodać lub ukryć osobną sekcję przed właściwą odpowiedzią chatbota z listą zasobów pobranych przez retrievera. Do integracji z LiveAgent należy zaznaczyć tę opcję, ponieważ ta sekcja nie jest wspierana i nie wyświetli się poprawnie w widżecie chatbota LiveAgent.
Harmonogramy
Pozwala ograniczyć pobieranie do jednego lub więcej Harmonogramów, które określiłeś do indeksowania lub aktualizacji treści w Źródłach Wiedzy.
Próg trafności
Określa, jak bardzo pobierane dokumenty muszą pasować do zapytania, używając współczynnika trafności (od 0 do 1). Na przykład, próg 0,7–0,8 jest zalecany dla bardzo trafnych odpowiedzi. Wyższy próg daje bardziej precyzyjne dopasowania, niższy może uwzględniać mniej trafne dokumenty.
Przykład: Jeśli ustawisz próg na 0,6 i masz cztery artykuły ze współczynnikami trafności 0,8, 0,65, 0,5 i 0,9, do pobrania zostaną użyte tylko te powyżej 0,6 (czyli 0,8, 0,65 i 0,9).
Rozwiązywanie problemów
Jeśli odpowiedź udzielona przez chatbota nie zawiera informacji, o których wiesz, że są dostępne w Twoich dokumentach lub harmonogramach, sprawdź historię rozmowy z włączoną opcją „Verbose”, by zobaczyć szczegółowe logi dotyczące użycia Document Retriever oraz pobranych dokumentów. W razie potrzeby dostosuj ustawienia i prompt na podstawie tych logów.
Jak zasilić chatbota FlowHunt wybranymi sekcjami dokumentacji cPanel (nie całą stroną)
Szczegółowy przewodnik dotyczący importu jedynie wybranych sekcji docs.cpanel.net do chatbota FlowHunt, dzięki czemu stanie się ekspertem w określonych tematach...
Twój chatbot może natychmiast uzyskiwać dostęp do dokumentów i wykorzystywać je, strony HTML, a nawet filmy z YouTube, aby dostosować się do Twojego unikalnego ...
2 min czytania
AI Chatbot
Knowledge Management
+3
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.