Engenharia de Contexto: O Guia Definitivo de 2025 para Dominar o Design de Sistemas de IA
Aprofunde-se em engenharia de contexto para IA. Este guia cobre princípios fundamentais, desde prompt vs. contexto até estratégias avançadas como gestão de memória, context rot e design multiagente.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
O cenário de desenvolvimento de IA passou por uma transformação profunda. Onde antes nos preocupávamos em criar o prompt perfeito, agora enfrentamos um desafio muito mais complexo: construir arquiteturas de informação completas que envolvem e potencializam nossos modelos de linguagem.
Essa mudança marca a evolução da prompt engineering para a engenharia de contexto — e representa nada menos que o futuro do desenvolvimento prático em IA. Os sistemas que entregam valor real hoje não dependem de prompts mágicos. Eles têm sucesso porque seus arquitetos aprenderam a orquestrar ecossistemas de informação abrangentes.
Andrej Karpathy capturou perfeitamente essa evolução ao descrever engenharia de contexto como a prática cuidadosa de preencher a janela de contexto com exatamente as informações certas no momento certo. Essa afirmação aparentemente simples revela uma verdade fundamental: o LLM não é mais o astro principal do espetáculo. Ele é um componente crítico dentro de um sistema cuidadosamente projetado, onde cada pedaço de informação — cada fragmento de memória, descrição de ferramenta, documento recuperado — foi deliberadamente posicionado para maximizar resultados.
O Que é Engenharia de Contexto?
Uma Perspectiva Histórica
As raízes da engenharia de contexto são mais profundas do que muitos imaginam. Enquanto as discussões sobre prompt engineering explodiram entre 2022 e 2023, os conceitos fundamentais da engenharia de contexto surgiram há mais de duas décadas, a partir de pesquisas em computação ubíqua e interação humano-computador.
Em 2001, Anind K. Dey estabeleceu uma definição que se mostrou notavelmente premonitória: contexto abrange qualquer informação que ajude a caracterizar a situação de uma entidade. Essa estrutura inicial lançou as bases para como pensamos o entendimento de ambientes por máquinas.
A evolução da engenharia de contexto ocorreu em fases distintas, cada uma moldada por avanços em inteligência de máquina:
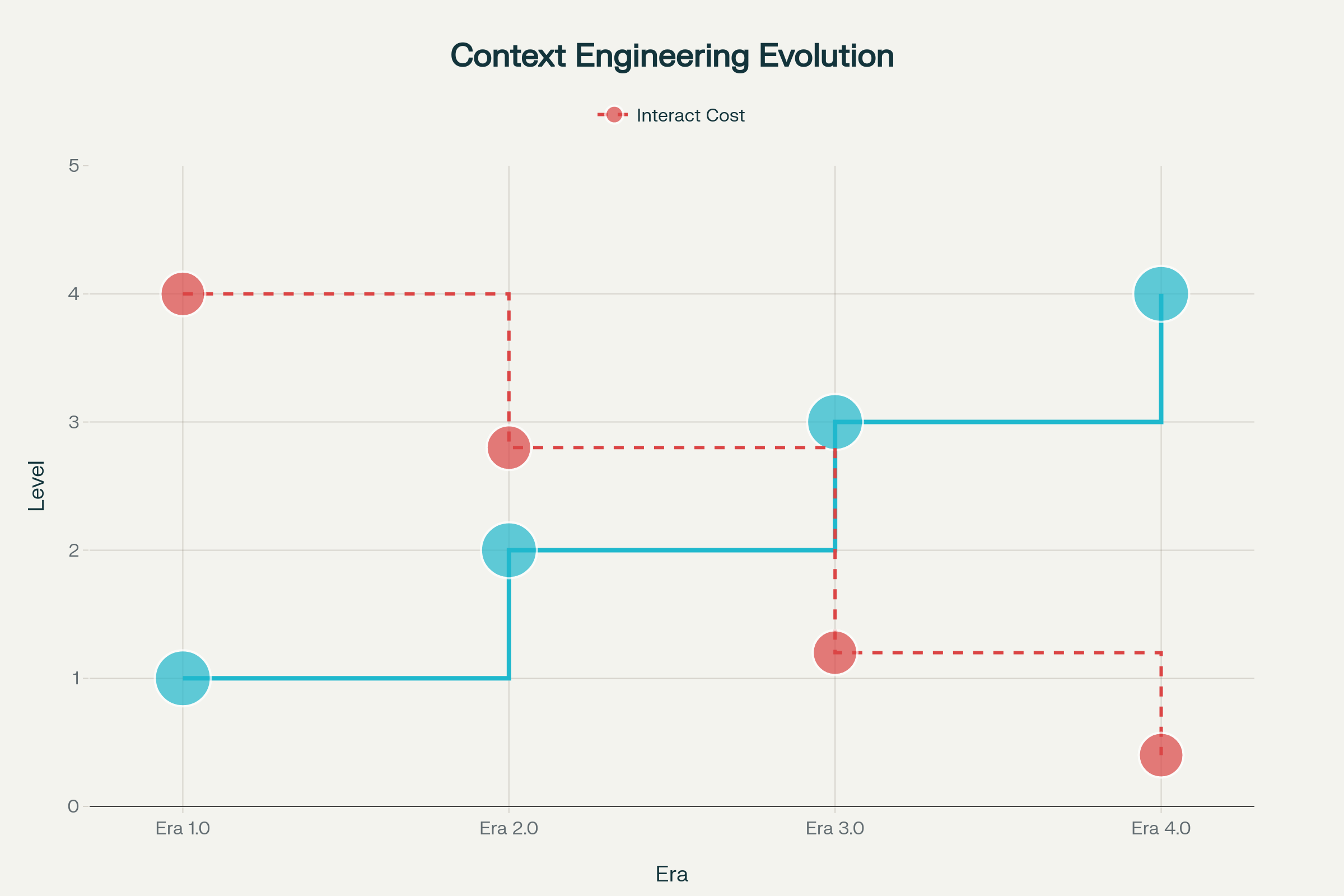
Era 1.0: Computação Primitiva (1990-2020) — Durante esse longo período, as máquinas só podiam lidar com entradas estruturadas e sinais ambientais básicos. Os humanos assumiam toda a responsabilidade de traduzir contextos para formatos processáveis por máquinas. Pense em aplicativos desktop, apps móveis com sensores e chatbots iniciais com árvores de resposta rígidas.
Era 2.0: Inteligência Centrada no Agente (2020–Presente) — O lançamento do GPT-3 em 2020 provocou uma mudança de paradigma. Grandes modelos de linguagem trouxeram real compreensão de linguagem natural e a capacidade de lidar com intenções implícitas. Essa era permitiu uma colaboração autêntica humano-agente, onde ambiguidade e informações incompletas se tornaram gerenciáveis por meio de entendimento sofisticado da linguagem e aprendizado em contexto.
Eras 3.0 & 4.0: Inteligência Humana e Super-Humana (Futuro) — As próximas ondas prometem sistemas que podem captar e processar informações de alta entropia com fluidez semelhante à humana, eventualmente indo além de respostas reativas para construir proativamente contexto e antecipar necessidades que os usuários nem sequer articularam.
Evolução da Engenharia de Contexto em Quatro Eras: Da Computação Primitiva à Inteligência Super-Humana
Uma Definição Formal
Na essência, engenharia de contexto representa a disciplina sistemática de projetar e otimizar como informações contextuais fluem através de sistemas de IA — desde a coleta inicial, passando pelo armazenamento e gestão, até a utilização final para aprimorar o entendimento de máquina e a execução de tarefas.
Podemos expressar isso matematicamente como uma função de transformação:
$CE: (C, T) \rightarrow f_{context}$
Onde:
C representa informações contextuais brutas (entidades e suas características)
T denota a tarefa alvo ou domínio de aplicação
f_{context} resulta na função de processamento de contexto
Dividindo em termos práticos, revelam-se quatro operações fundamentais:
Coletar sinais contextuais relevantes através de sensores e canais de informação diversos
Armazenar essas informações de forma eficiente em sistemas locais, infraestrutura de rede e nuvem
Gerenciar complexidade por meio de processamento inteligente de texto, entradas multimodais e relações intrincadas
Usar o contexto estrategicamente, filtrando por relevância, permitindo compartilhamento entre sistemas e adaptando com base nos requisitos do usuário
Por Que Engenharia de Contexto Importa: O Enquadramento da Redução de Entropia
A engenharia de contexto aborda uma assimetria fundamental na comunicação homem-máquina. Quando humanos conversam, preenchem lacunas facilmente graças a conhecimento cultural compartilhado, inteligência emocional e consciência situacional. Máquinas não possuem nenhuma dessas capacidades.
Essa lacuna se manifesta como entropia da informação. A comunicação humana opera eficientemente porque podemos assumir grandes quantidades de contexto compartilhado. Máquinas exigem que tudo seja explicitamente representado. Engenharia de contexto é, fundamentalmente, sobre pré-processar contextos para máquinas — comprimindo a alta entropia da complexidade das intenções e situações humanas em representações de baixa entropia que as máquinas possam processar.
À medida que a inteligência de máquina avança, essa redução de entropia se torna cada vez mais automatizada. Hoje, na Era 2.0, engenheiros precisam orquestrar manualmente grande parte dessa redução. Nas Eras 3.0 e além, as máquinas assumirão progressivamente mais dessa responsabilidade de forma autônoma. Contudo, o desafio central permanece: transpor o abismo entre a complexidade humana e a compreensão de máquina.
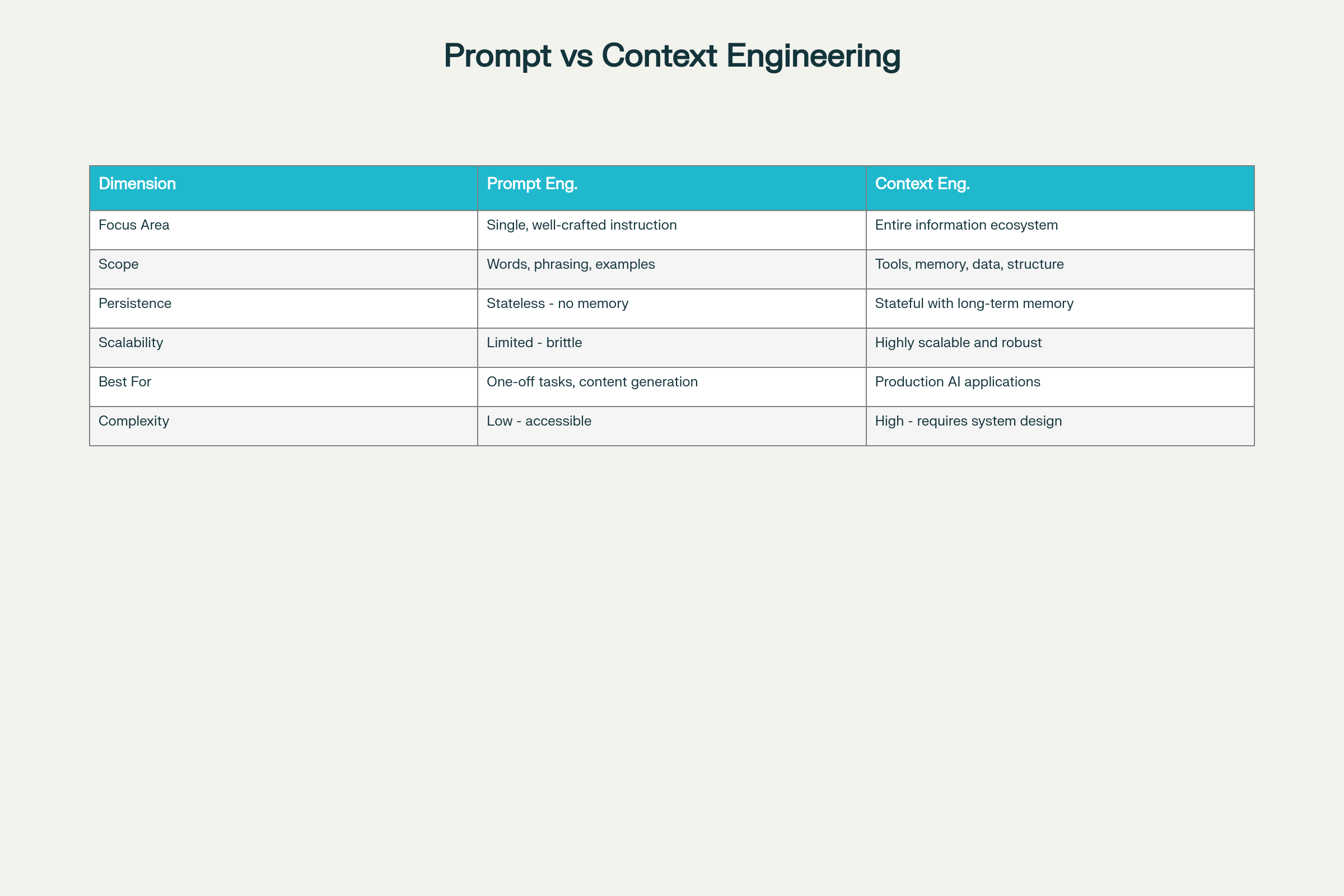
Prompt Engineering vs Engenharia de Contexto: Diferenças Críticas
Um erro comum é confundir essas duas disciplinas. Na realidade, representam abordagens fundamentalmente diferentes para a arquitetura de sistemas de IA.
Prompt engineering centra-se na elaboração de instruções ou consultas individuais para moldar o comportamento do modelo. Trata-se de otimizar a estrutura linguística da comunicação com o modelo — a redação, exemplos e padrões de raciocínio em uma única interação.
Engenharia de contexto é uma disciplina sistêmica abrangente, que gerencia tudo o que o modelo encontra durante a inferência — incluindo prompts, mas também documentos recuperados, sistemas de memória, descrições de ferramentas, informações de estado e muito mais.
Prompt Engineering vs Engenharia de Contexto: Principais Diferenças e Tradeoffs
Considere esta distinção: Pedir ao ChatGPT para compor um e-mail profissional é prompt engineering. Construir uma plataforma de atendimento ao cliente que mantém histórico de conversas em múltiplas sessões, acessa detalhes de contas do usuário e lembra chamados anteriores — isso é engenharia de contexto.
Diferenças-Chave em Oito Dimensões:
Dimensão
Prompt Engineering
Engenharia de Contexto
Foco
Otimização de instrução individual
Ecossistema de informação abrangente
Escopo
Palavras, redação, exemplos
Ferramentas, memória, arquitetura de dados, estrutura
Persistência
Sem estado — não retém memória
Com estado e memória de longo prazo
Escalabilidade
Limitada e frágil em escala
Altamente escalável e robusta
Melhor Para
Tarefas pontuais, geração de conteúdo
Aplicações de IA em produção
Complexidade
Baixa barreira de entrada
Alta — exige expertise em design de sistemas
Confiabilidade
Imprevisível em escala
Consistente e confiável
Manutenção
Frágil a mudanças de requisitos
Modular e de fácil manutenção
A principal percepção: aplicações em LLM para produção demandam, em sua maioria, engenharia de contexto e não apenas prompts engenhosos. Como observado pela Cognition AI, engenharia de contexto se tornou, na prática, a principal responsabilidade dos engenheiros que constroem agentes de IA.
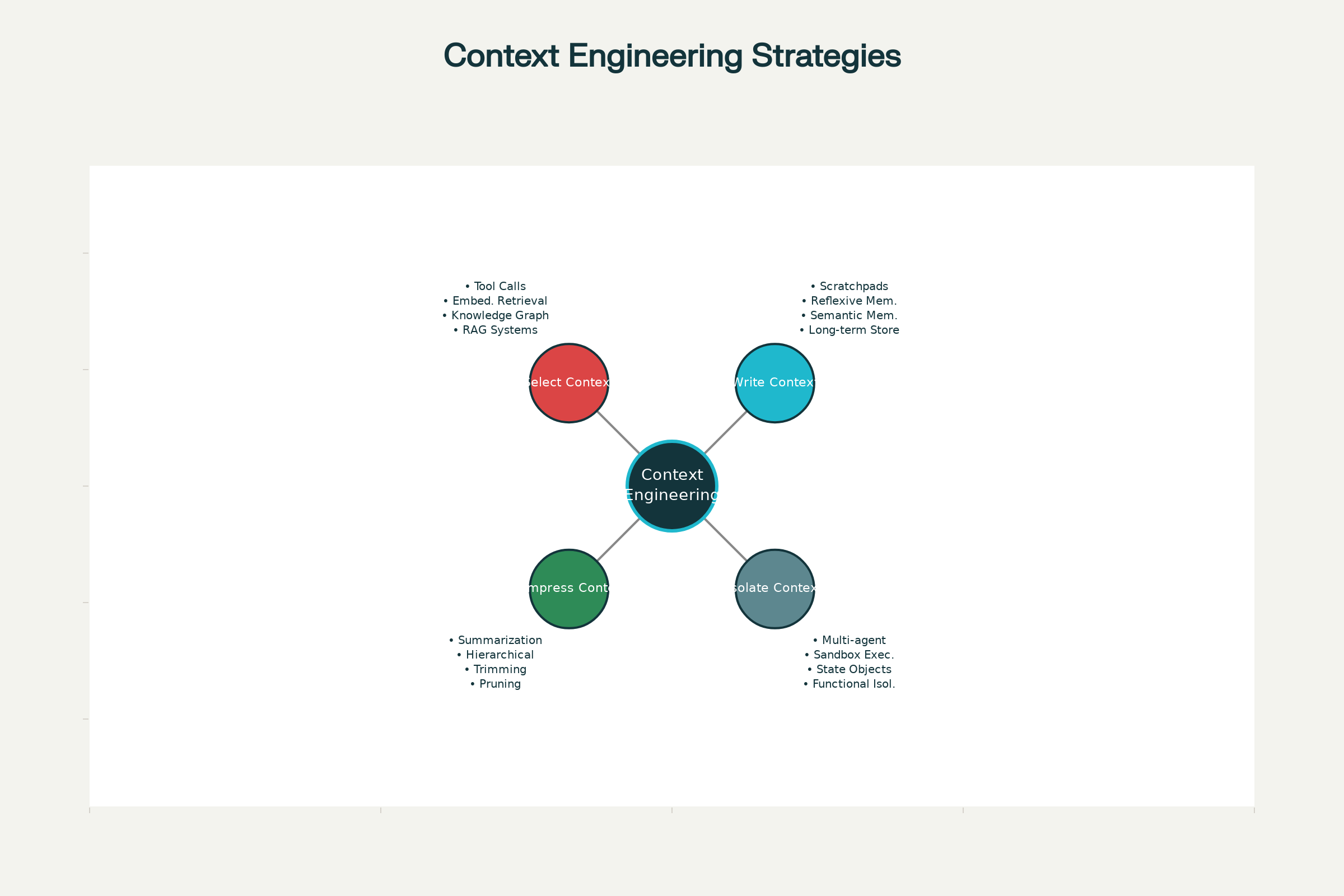
As Quatro Estratégias Fundamentais de Engenharia de Contexto
Nos principais sistemas de IA — de Claude e ChatGPT a agentes especializados desenvolvidos pela Anthropic e outros laboratórios de ponta — quatro estratégias fundamentais se cristalizaram para uma gestão eficaz do contexto. Elas podem ser empregadas de forma independente ou combinada para maior efeito.
1. Escrever Contexto: Persistindo Informações Fora da Janela de Contexto
O princípio fundamental é elegantemente simples: não force o modelo a lembrar de tudo. Em vez disso, persista informações críticas fora da janela de contexto, onde podem ser acessadas de forma confiável quando necessário.
Rascunhos (Scratchpads) oferecem a implementação mais intuitiva. Assim como humanos anotam enquanto resolvem problemas complexos, agentes de IA usam rascunhos para guardar informações para referência futura. A implementação pode ser tão simples quanto uma ferramenta para guardar notas, ou sofisticada como campos em um objeto de estado de execução que persistem entre etapas.
O pesquisador multiagente da Anthropic demonstra isso lindamente: o LeadResearcher começa formulando uma abordagem e salva seu plano na Memória para persistência, reconhecendo que se a janela de contexto exceder 200.000 tokens, haverá truncamento e o plano precisa ser retido.
Memórias expandem o conceito de rascunho entre sessões. Em vez de capturar informações apenas em uma tarefa (memória de sessão), sistemas podem construir memórias de longo prazo que persistem e evoluem em várias interações usuário-agente. Esse padrão tornou-se padrão em produtos como ChatGPT, Claude Code, Cursor e Windsurf.
Iniciativas de pesquisa como Reflexion inovaram com memórias reflexivas — o agente reflete a cada turno e gera memórias para referência futura. Generative Agents ampliaram essa abordagem sintetizando memórias a partir de coleções de feedbacks passados.
Três Tipos de Memórias:
Episódica: Exemplos concretos de comportamentos ou interações passadas (valioso para few-shot learning)
Procedural: Instruções ou regras que regem o comportamento (garantindo operação consistente)
Semântica: Fatos e relações sobre o mundo (fornecendo conhecimento fundamentado)
2. Selecionar Contexto: Trazendo as Informações Certas
Uma vez que as informações estejam preservadas, o agente deve recuperar apenas o que é relevante para a tarefa atual. Seleção ruim pode ser tão prejudicial quanto não ter memória alguma — informações irrelevantes podem confundir o modelo ou induzir alucinações.
Mecanismos de Seleção de Memória:
Abordagens simples utilizam arquivos restritos sempre incluídos. Claude Code usa um arquivo CLAUDE.md para memórias procedurais, enquanto Cursor e Windsurf usam arquivos de regras. No entanto, essa abordagem não escala quando o agente acumula centenas de fatos e relações.
Para coleções maiores de memória, recuperação baseada em embeddings e grafos de conhecimento são comumente usados. O sistema converte memórias e a consulta atual em representações vetoriais e recupera as memórias semanticamente mais próximas.
Mas, como Simon Willison demonstrou no AIEngineer World’s Fair, essa abordagem pode falhar de forma espetacular. O ChatGPT injetou inesperadamente sua localização a partir das memórias em uma imagem gerada, ilustrando como mesmo sistemas sofisticados podem recuperar memórias de forma inadequada. Isso ressalta por que a engenharia meticulosa é essencial.
Seleção de Ferramentas apresenta seu próprio desafio. Quando agentes têm acesso a dezenas ou centenas de ferramentas, apenas enumerá-las pode causar confusão — descrições sobrepostas levam modelos a selecionar ferramentas inadequadas. Uma solução eficaz: aplicar princípios RAG às descrições de ferramentas. Recuperando apenas ferramentas semanticamente relevantes, sistemas alcançaram melhorias de três vezes na precisão de seleção.
Recuperação de Conhecimento talvez represente o problema mais rico. Agentes de código exemplificam esse desafio em escala de produção. Como um engenheiro da Windsurf observou, indexar código não equivale a recuperação efetiva de contexto. Eles fazem indexação e busca por embeddings com análise de AST e divisão em blocos semanticamente significativos. Mas a busca por embeddings perde confiabilidade à medida que o codebase cresce. O sucesso exige combinar técnicas como grep/busca em arquivos, recuperação baseada em grafo de conhecimento e re-rankings de contexto por relevância.
3. Comprimir Contexto: Retendo Apenas o Essencial
À medida que agentes trabalham em tarefas de longo prazo, o contexto se acumula naturalmente. Anotações, saídas de ferramentas e histórico de interações podem rapidamente ultrapassar a janela de contexto. Estratégias de compressão enfrentam esse desafio destilando informações de forma inteligente enquanto preservam o que importa.
Resumo é a técnica principal. Claude Code implementa “auto-compactação” — quando a janela de contexto chega a 95% da capacidade, resume toda a trajetória de interações usuário-agente. Isso pode empregar várias estratégias:
Resumo recursivo: Criando resumos de resumos para construir hierarquias compactas
Resumo hierárquico: Gerando resumos em múltiplos níveis de abstração
Resumo direcionado: Comprimindo componentes específicos (como resultados de busca pesados em tokens) ao invés de todo o contexto
A Cognition AI revelou que usam modelos fine-tuned para resumo nas fronteiras entre agentes, reduzindo o uso de tokens na transferência de conhecimento — mostrando a profundidade de engenharia exigida.
Aparar Contexto é uma abordagem complementar. Em vez de usar um LLM para resumir de forma inteligente, aparar simplesmente corta o contexto usando heurísticas — removendo mensagens antigas, filtrando por importância ou usando pruners treinados como Provence para tarefas de QA.
A principal percepção: O que você remove pode importar tanto quanto o que mantém. Um contexto focado de 300 tokens frequentemente supera um contexto de 113.000 tokens sem foco em tarefas de conversação.
4. Isolar Contexto: Dividindo Informações Entre Sistemas
Por fim, estratégias de isolamento reconhecem que tarefas diferentes exigem informações diferentes. Em vez de enfiar todo o contexto na janela de um único modelo, técnicas de isolamento particionam o contexto entre sistemas especializados.
Arquiteturas Multiagentes são a abordagem mais prevalente. A biblioteca Swarm da OpenAI foi explicitamente projetada em torno da “separação de responsabilidades” — subagentes especializados lidam com tarefas específicas com suas próprias ferramentas, instruções e janelas de contexto.
A pesquisa da Anthropic demonstra o poder dessa abordagem: muitos agentes com contextos isolados superaram implementações de agente único, principalmente porque cada janela de contexto pode ser alocada para uma subtarefa mais restrita. Subagentes operam em paralelo com suas próprias janelas de contexto, explorando diferentes aspectos da questão simultaneamente.
Contudo, sistemas multiagentes trazem tradeoffs. A Anthropic relatou até quinze vezes mais uso de tokens em comparação ao chat de agente único. Isso exige orquestração cuidadosa, prompt engineering para planejamento e mecanismos sofisticados de coordenação.
Ambientes Sandbox oferecem outra estratégia de isolamento. O CodeAgent da HuggingFace demonstra isso: em vez de retornar JSON que o modelo precisa interpretar, o agente gera código que executa em um sandbox. Saídas selecionadas (valores de retorno) são passadas de volta ao LLM, mantendo objetos pesados em tokens isolados no ambiente de execução. Isso é excelente para dados visuais e de áudio.
Isolamento de Objeto de Estado talvez seja a técnica mais subestimada. O estado de execução do agente pode ser projetado como um esquema estruturado (por exemplo, modelo Pydantic) com múltiplos campos. Um campo (como messages) é exposto ao LLM a cada etapa, enquanto outros permanecem isolados para uso seletivo. Isso provê controle refinado sem complexidade arquitetural.
Quatro Estratégias Fundamentais para Engenharia de Contexto Eficaz em Agentes de IA
O Problema do Context Rot: Um Desafio Crítico
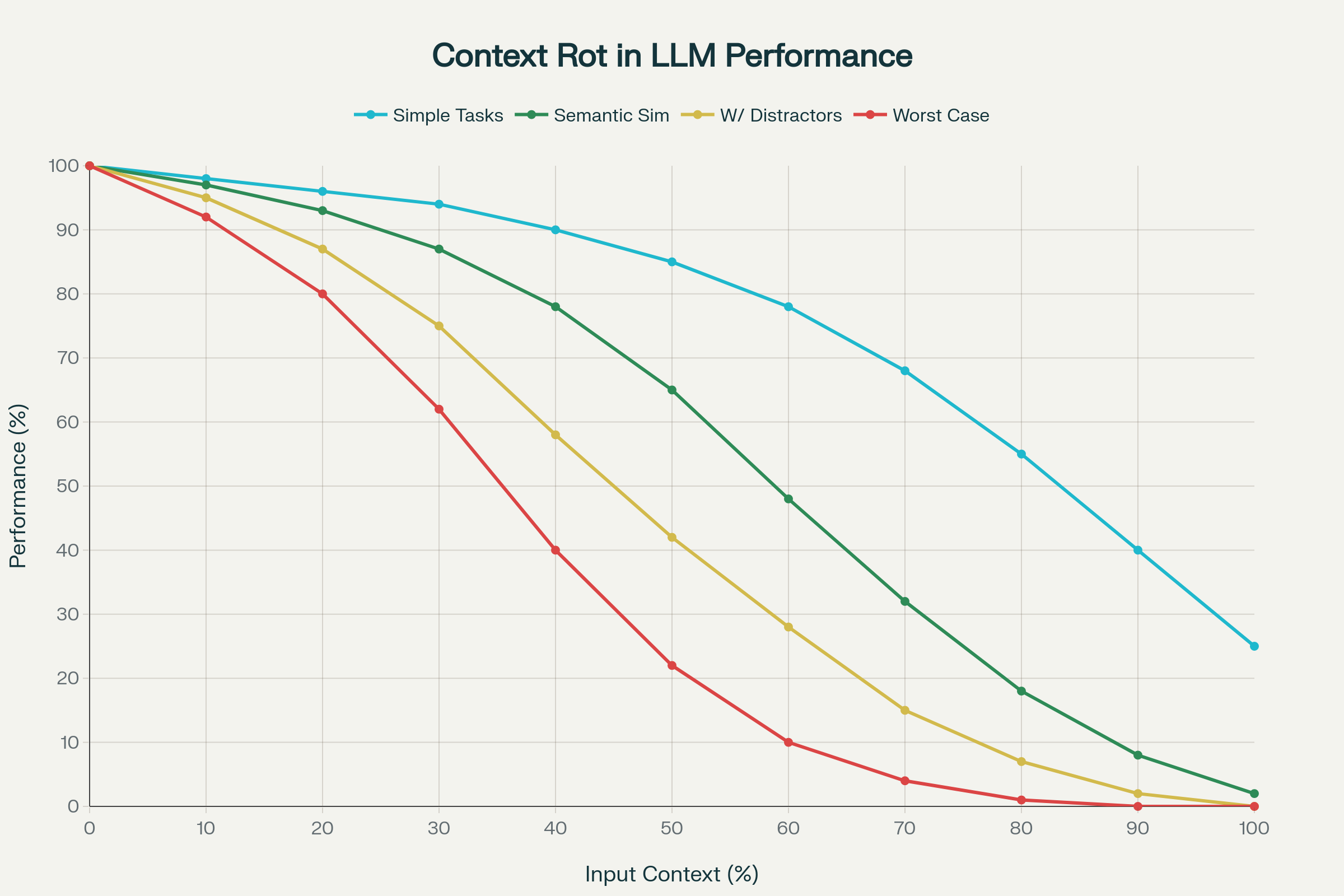
Enquanto avanços em comprimento de contexto são celebrados na indústria, pesquisas recentes revelam uma realidade preocupante: contextos mais longos não se traduzem automaticamente em melhor desempenho.
Um estudo de referência analisando 18 LLMs líderes — incluindo GPT-4.1, Claude 4, Gemini 2.5 e Qwen 3 — descobriu um fenômeno chamado context rot: a degradação imprevisível (e muitas vezes grave) do desempenho à medida que o contexto de entrada aumenta.
Principais Descobertas sobre Context Rot
1. Degradação Não Uniforme do Desempenho
O desempenho não cai de forma linear ou previsível. Em vez disso, os modelos apresentam quedas bruscas e idiossincráticas, dependendo do modelo e da tarefa. Um modelo pode manter 95% de precisão até certo comprimento de contexto, então despencar para 60%. Esses “cliffs” são imprevisíveis entre modelos.
2. Complexidade Semântica Amplifica o Context Rot
Tarefas simples (como copiar palavras repetidas ou recuperação semântica exata) apresentam declínio moderado. Mas quando “agulhas no palheiro” exigem similaridade semântica e não apenas correspondência exata, o desempenho despenca. Acrescentar distratores plausíveis — informações semelhantes, mas não exatamente o que o modelo precisa — piora drasticamente a precisão.
3. Viés de Posição e Colapso de Atenção
A atenção do transformer não escala linearmente em contextos longos. Tokens do início (viés de primazia) e do fim (viés de recência) recebem atenção desproporcional. Em casos extremos, a atenção colapsa totalmente, fazendo o modelo ignorar partes substanciais da entrada.
4. Padrões de Falha Específicos por Modelo
LLMs diferentes exibem comportamentos únicos em escala:
GPT-4.1: Tende a alucinar, repetindo tokens incorretos
Gemini 2.5: Introduz fragmentos ou pontuações não relacionadas
Claude Opus 4: Pode recusar tarefas ou se tornar excessivamente cauteloso
5. Impacto Real em Conversação
Talvez o mais grave: no benchmark LongMemEval, modelos com acesso à conversa inteira (aproximadamente 113 mil tokens) tiveram desempenho significativamente melhor ao receberem apenas o segmento de 300 tokens focado. Isso demonstra que context rot prejudica tanto a recuperação quanto o raciocínio em diálogos reais.
Context Rot: Degradação do Desempenho com o Aumento do Comprimento de Tokens em 18 LLMs
Implicações: Qualidade Acima de Quantidade
A principal conclusão das pesquisas sobre context rot é clara: a quantidade de tokens de entrada não é o único fator determinante de qualidade. Como o contexto é construído, filtrado e apresentado é igualmente — ou mais — vital.
Esse achado valida toda a disciplina de engenharia de contexto. Em vez de ver janelas longas como panaceia, equipes sofisticadas reconhecem que engenharia de contexto cuidadosa — através de compressão, seleção e isolamento — é essencial para manter o desempenho com entradas substanciais.
Engenharia de Contexto na Prática: Aplicações Reais
Estudo de Caso 1: Sistemas Multi-Turn (Claude Code, Cursor)
Claude Code e Cursor representam implementações de ponta em engenharia de contexto para assistência de código:
Coleta: Esses sistemas reúnem contexto de múltiplas fontes — arquivos abertos, estrutura do projeto, histórico de edições, saída do terminal e comentários do usuário.
Gestão: Em vez de despejar todos os arquivos no prompt, comprimem inteligentemente. Claude Code usa resumos hierárquicos. O contexto é etiquetado por função (ex: “arquivo atualmente editado”, “dependência referenciada”, “mensagem de erro”).
Uso: A cada turno, o sistema seleciona quais arquivos e elementos de contexto são relevantes, apresenta-os de forma estruturada e mantém trilhas separadas para raciocínio e saída visível.
Compressão: Ao se aproximar do limite de contexto, o auto-compactador resume a trajetória da interação, preservando decisões-chave.
Resultado: Essas ferramentas permanecem utilizáveis em grandes projetos (milhares de arquivos) sem perda de desempenho, apesar das restrições da janela de contexto.
Estudo de Caso 2: Tongyi DeepResearch (Agente Open-Source para Pesquisa Profunda)
O Tongyi DeepResearch mostra como a engenharia de contexto viabiliza tarefas complexas de pesquisa:
Pipeline de Síntese de Dados: Em vez de depender de dados humanos limitados, o Tongyi utiliza uma abordagem sofisticada de síntese de dados, criando questões de pesquisa de nível PhD via upgrades iterativos de complexidade. Cada iteração aprofunda fronteiras de conhecimento e constrói tarefas de raciocínio mais complexas.
Gestão de Contexto: O sistema adota o paradigma IterResearch — em cada rodada de pesquisa, reconstrói um workspace enxuto usando apenas saídas essenciais da rodada anterior. Isso evita a “sufocação cognitiva” de acumular todas as informações em uma única janela de contexto.
Exploração Paralela: Vários agentes de pesquisa operam em paralelo com contextos isolados, cada um explorando diferentes aspectos. Um agente de síntese então integra os achados para respostas abrangentes.
Resultados: Tongyi DeepResearch atinge desempenho comparável a sistemas proprietários como o DeepResearch da OpenAI, pontuando 32,9 na Humanity’s Last Exam e 75 em benchmarks centrados no usuário.
Estudo de Caso 3: Pesquisador Multiagente da Anthropic
A pesquisa da Anthropic mostra como isolamento e especialização melhoram o desempenho:
Arquitetura: Subagentes especializados cuidam de tarefas específicas de pesquisa (revisão de literatura, síntese, verificação) com janelas de contexto separadas.
Benefícios: Essa abordagem superou sistemas de agente único, com cada subagente otimizando seu contexto para a tarefa restrita.
Tradeoff: Embora superior em qualidade, o uso de tokens aumentou até quinze vezes comparado ao chat de agente único.
Isso destaca: engenharia de contexto frequentemente envolve tradeoffs entre qualidade, velocidade e custo. O equilíbrio certo depende dos requisitos da aplicação.
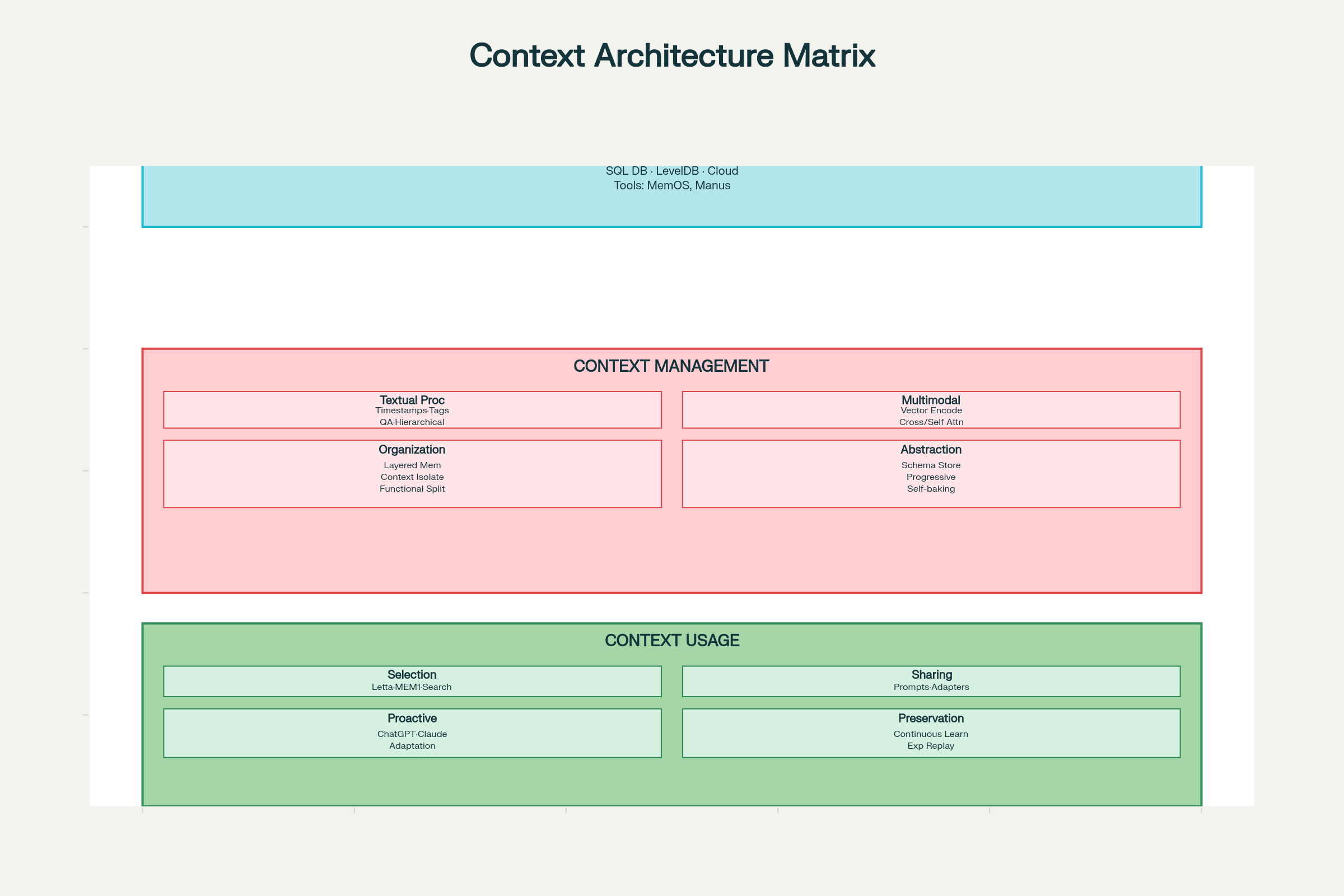
O Framework de Considerações de Design
Implementar engenharia de contexto eficaz exige pensamento sistemático em três dimensões: coleta & armazenamento, gestão e uso.
Considerações de Design em Engenharia de Contexto: Arquitetura Completa de Sistema e Componentes
Decisões de Projeto para Coleta & Armazenamento
Escolha de Tecnologias de Armazenamento:
Armazenamento Local (SQLite, LevelDB): Rápido, baixa latência, ideal para agentes client-side
Armazenamento em Nuvem (DynamoDB, PostgreSQL): Escalável, acessível de qualquer lugar
Sistemas Distribuídos: Para escala massiva com redundância e tolerância a falhas
Padrões de Projeto:
MemOS: Sistema operacional de memória para gestão unificada
Manus: Memória estruturada com acesso baseado em papéis
Princípio-chave: Projete para recuperação eficiente, não apenas armazenamento. O sistema de armazenamento ótimo é aquele em que você encontra rapidamente o que precisa.
Decisões de Projeto para Gestão
Processamento de Contexto Textual:
Marcação Temporal: Simples, mas limitada. Preserva ordem cronológica, mas sem estrutura semântica, levando a problemas de escala conforme as interações se acumulam.
Tagueamento de Papel/Função: Marque cada elemento do contexto com sua função — “meta”, “decisão”, “ação”, “erro” etc. Suporta tagueamento multidimensional (prioridade, fonte, confiança). Sistemas recentes como LLM4Tag permitem isso em escala.
Compressão com Pares de Pergunta-Resposta: Converta interações em pares QA comprimidos, preservando informações essenciais e reduzindo tokens.
Notas Hierárquicas: Compressão progressiva em vetores de significado, como nos sistemas H-MEM, capturando essência semântica em múltiplos níveis de abstração.
Processamento de Contexto Multimodal:
Espaços Vetoriais Comparáveis: Codifique todas as modalidades (texto, imagem, áudio) em espaços vetoriais comparáveis através de modelos de embedding compartilhados (como no ChatGPT e Claude).
Cross-Attention: Use uma modalidade para guiar a atenção a outra (como no Qwen2-VL).
Codificação Independente com Self-Attention: Codifique modalidades separadamente, depois combine por mecanismos unificados de atenção.
Organização do Contexto:
Arquitetura de Memória em Camadas: Separe memória de trabalho (contexto atual), memória de curto prazo (histórico recente) e memória de longo prazo (fatos persistentes).
Isolamento Funcional de Contexto: Use subagentes com janelas de contexto separadas para diferentes funções (abordagem do Claude).
Abstração de Contexto (Self-Baking):
“Self-baking” refere-se à capacidade do contexto de melhorar por processamento repetido. Padrões incluem:
Armazenar contexto bruto e depois adicionar resumos em linguagem natural (Claude Code, Gemini CLI)
Extrair fatos-chave por esquemas fixos (abordagem ChatSchema)
Comprimir progressivamente em vetores de significado (H-MEM)
Decisões de Projeto para Uso
Seleção de Contexto:
Recuperação baseada em embeddings (mais comum)
Percurso em grafos de conhecimento (para relações complexas)
Pontuação de similaridade semântica
Peso por recência/prioridade
Compartilhamento de Contexto:
Dentro do sistema:
Embedding do contexto selecionado em prompts (AutoGPT, ChatDev)
Troca estruturada de mensagens entre agentes (Letta, MemOS)
Memória compartilhada via comunicação indireta (A-MEM)
Entre sistemas:
Adaptadores que convertem o formato de contexto (Langroid)
Representações compartilhadas entre plataformas (Sharedrop)
Inferência Proativa do Usuário:
ChatGPT e Claude analisam padrões de interação para antecipar necessidades
Sistemas de contexto aprendem a apresentar informações antes de serem solicitadas
O equilíbrio entre utilidade e privacidade permanece desafio central
Habilidades em Engenharia de Contexto: O Que Times Precisam Dominar
À medida que engenharia de contexto se torna central no desenvolvimento de IA, certas habilidades diferenciam equipes eficazes das que têm dificuldade para escalar.
1. Montagem Estratégica de Contexto
Times devem entender que informação serve a cada tarefa. Não basta coletar dados — é preciso entender os requisitos a fundo para separar o essencial do ruído.
Na Prática:
Analise modos de falha para identificar contexto ausente
Faça A/B testing de diferentes composições de contexto
Implemente observabilidade para rastrear quais elementos impulsionam desempenho
2. Arquitetura de Sistemas de Memória
Projetar sistemas de memória eficazes exige entender tipos de memória e quando usá-los:
Quando uma informação deve estar na memória de curto ou longo prazo?
Como diferentes tipos de memória devem interagir?
Que estratégias de compressão mantêm fidelidade reduzindo tokens?
3. Busca Semântica e Recuperação
Além de matching por palavra-chave, equipes precisam dominar:
Modelos de embedding e suas limitações
Métricas de similaridade vetorial e tradeoffs
Estratégias de re-ranking e filtragem
Tratamento de queries ambíguas
4. Economia de Tokens e Análise de Custos
Cada byte de contexto traz tradeoffs:
Monitore uso de tokens em diferentes composições
Entenda custos específicos de processamento por modelo
Equilibre qualidade, custo e latência
5. Orquestração de Sistemas
Com múltiplos agentes, ferramentas e sistemas de memória, a orquestração cuidadosa é essencial:
Coordenação entre subagentes
Gestão de falhas e recuperação
Gerenciamento de estado em tarefas de longo prazo
6. Avaliação e Mensuração
Engenharia de contexto é disciplina de otimização:
Defina métricas de desempenho
Faça A/B testing de abordagens de engenharia de contexto
Meça impacto na experiência do usuário, não só na acurácia do modelo
Como comentou um engenheiro sênior, o caminho mais rápido para entregar software de IA de qualidade envolve pegar pequenos conceitos modulares de construção de agentes e incorporá-los nos produtos existentes.
Melhores Práticas para Implementar Engenharia de Contexto
1. Comece Simples, Evolua Deliberadamente
Inicie com prompt engineering básico mais memória tipo rascunho. Só acrescente complexidade (isolamento multiagente, recuperação sofisticada) com evidências claras de necessidade.
2. Meça Tudo
Use ferramentas como LangSmith para observabilidade. Acompanhe:
Uso de tokens por abordagem de contexto
Métricas de desempenho (acurácia, correção, satisfação do usuário)
Tradeoffs de custo e latência
3. Automatize a Gestão de Memória
Curadoria manual de memória não escala. Implemente:
Resumo automático em fronteiras de contexto
Filtragem inteligente e score de relevância
Funções de decaimento para informações antigas
4. Projete para Clareza e Auditabilidade
A qualidade do contexto importa mais quando você entende o que o modelo vê. Use:
Formatos claros e estruturados (JSON, Markdown)
Contexto tagueado com papéis explícitos
Separação de responsabilidades entre componentes de contexto
5. Construa com Contexto em Primeiro Lugar, Não o LLM
Em vez de começar por “qual LLM usar”, inicie por “que contexto esta tarefa exige?” O LLM vira um componente em um sistema maior, guiado pelo contexto.
6. Abrace Arquiteturas em Camadas
Separe:
Memória de trabalho (janela de contexto atual)
Memória de curto prazo (interações recentes)
Memória de longo prazo (fatos persistentes)
Cada camada tem propósito distinto e pode ser otimizada separadamente.
Desafios e Perspectivas Futuras
Desafios Atuais
1. Context Rot e Escalabilidade
Embora existam técnicas para mitigar context rot, o problema fundamental permanece. Conforme as entradas crescem, mecanismos sofisticados de seleção e compressão se tornam cada vez mais necessários.
2. Consistência e Coerência de Memória
Manter consistência entre tipos de memória e ao longo do tempo é desafiador. Memórias conflitantes ou desatualizadas degradam o desempenho.
3. Privacidade e Divulgação Seletiva
Com sistemas mantendo contextos cada vez mais ricos sobre usuários, equilibrar personalização e privacidade é crítico. O “a janela de contexto não pertence mais ao usuário” surge quando informações inesperadas aparecem.
4. Sobrecarga Computacional
Engenharia de contexto sofisticada aumenta o custo computacional. Seleção, compressão e recuperação consomem recursos. Encontrar o equilíbrio certo é um desafio em aberto.
Perspectivas Promissoras
1. Context Engineers Aprendizes
Em vez de gerenciar contexto manualmente, sistemas podem aprender estratégias ótimas de seleção por meta-learning ou reinforcement learning.
2. Emergência de Mecanismos Simbólicos
Pesquisas recentes sugerem que LLMs desenvolvem mecanismos simbólicos emergentes. Explorar isso pode permitir abstração e raciocínio de contexto mais sofisticados.
3. Ferramentas Cognitivas e Prompt Programming
Frameworks como “Cognitive Tools” da IBM encapsulam operações de raciocínio como módulos. Isso transforma engenharia de contexto em software componível — peças pequenas e reutilizáveis que trabalham juntas.
4. Teoria de Campos Neurais para Contexto
Em vez de elementos discretos, modelar contexto como campo neural contínuo pode permitir gestão mais fluida e adaptativa.
5. Semântica Quântica e Superposição
Pesquisas iniciais exploram se o contexto pode aproveitar conceitos de superposição quântica — onde informações existem em múltiplos estados até serem necessárias. Isso pode revolucionar armazenamento e recuperação de contexto.
Conclusão: Por Que Engenharia de Contexto Importa Agora
Estamos em um ponto de inflexão no desenvolvimento de IA. Por anos, o foco foi tornar os modelos maiores e
Perguntas frequentes
Prompt engineering foca em criar uma única instrução para um LLM. Engenharia de contexto é uma disciplina sistêmica mais ampla que gerencia todo o ecossistema de informações para um modelo de IA, incluindo memória, ferramentas e dados recuperados, para otimizar o desempenho em tarefas complexas e com estado.
Context rot é a degradação imprevisível do desempenho de um LLM à medida que seu contexto de entrada se torna mais extenso. Os modelos podem apresentar quedas bruscas de precisão, ignorar partes do contexto ou alucinar, ressaltando a necessidade de qualidade e gestão cuidadosa do contexto, e não apenas quantidade.
As quatro estratégias fundamentais são: 1. Escrever Contexto (persistir informações fora da janela de contexto, como rascunhos ou memória), 2. Selecionar Contexto (recuperar apenas informações relevantes), 3. Comprimir Contexto (resumir ou aparar para economizar espaço) e 4. Isolar Contexto (usar sistemas multiagentes ou sandboxes para separar responsabilidades).
Arshia é Engenheira de Fluxos de Trabalho de IA na FlowHunt. Com formação em ciência da computação e paixão por IA, ela se especializa em criar fluxos de trabalho eficientes que integram ferramentas de IA em tarefas do dia a dia, aumentando a produtividade e a criatividade.
Arshia Kahani
Engenheira de Fluxos de Trabalho de IA
Domine a Engenharia de Contexto
Pronto para construir a próxima geração de sistemas de IA? Explore nossos recursos e ferramentas para implementar engenharia de contexto avançada em seus projetos.
O Futuro É Impulsionado: Por Que a Engenharia de Prompts É a Nova Habilidade Fundamental?
Descubra por que a engenharia de prompts está se tornando rapidamente uma habilidade essencial para todo profissional, como ela está transformando a produtivida...
A Década dos Agentes de IA: Karpathy sobre o Cronograma da AGI
Explore a perspectiva detalhada de Andrej Karpathy sobre os cronogramas da AGI, agentes de IA e por que a próxima década será crítica para o desenvolvimento da ...
Por que os Melhores Engenheiros Estão Abandonando Servidores MCP: 3 Alternativas Comprovadas para Agentes de IA Eficientes
Descubra por que engenheiros de ponta estão deixando de usar servidores MCP e explore três alternativas comprovadas—abordagens baseadas em CLI, ferramentas base...
19 min de leitura
AI Agents
MCP
+3
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.