Como Testar Chatbot de IA
Aprenda estratégias abrangentes de teste para chatbots de IA, incluindo testes funcionais, de desempenho, segurança e usabilidade. Descubra as melhores práticas...
13 min de leitura
Aprenda métodos abrangentes para medir a precisão de chatbots de helpdesk com IA em 2025. Descubra métricas de precisão, recall, F1, satisfação do usuário e técnicas avançadas de avaliação com a FlowHunt.
Meça a precisão de chatbots de helpdesk com IA utilizando múltiplas métricas, incluindo cálculos de precisão e recall, matrizes de confusão, pontuações de satisfação do usuário, taxas de resolução e métodos avançados de avaliação baseados em LLM. A FlowHunt oferece ferramentas completas para avaliação automatizada de precisão e monitoramento de performance.
Medir a precisão de um chatbot de helpdesk com IA é essencial para garantir que ele forneça respostas confiáveis e úteis às dúvidas dos clientes. Ao contrário de tarefas simples de classificação, a precisão de um chatbot abrange múltiplas dimensões que devem ser avaliadas em conjunto para fornecer um panorama completo do desempenho. O processo envolve analisar o quão bem o chatbot compreende as solicitações do usuário, fornece informações corretas, resolve questões de forma eficaz e mantém a satisfação do usuário ao longo das interações. Uma estratégia abrangente de medição de precisão combina métricas quantitativas com feedback qualitativo para identificar pontos fortes e áreas que precisam de melhorias.
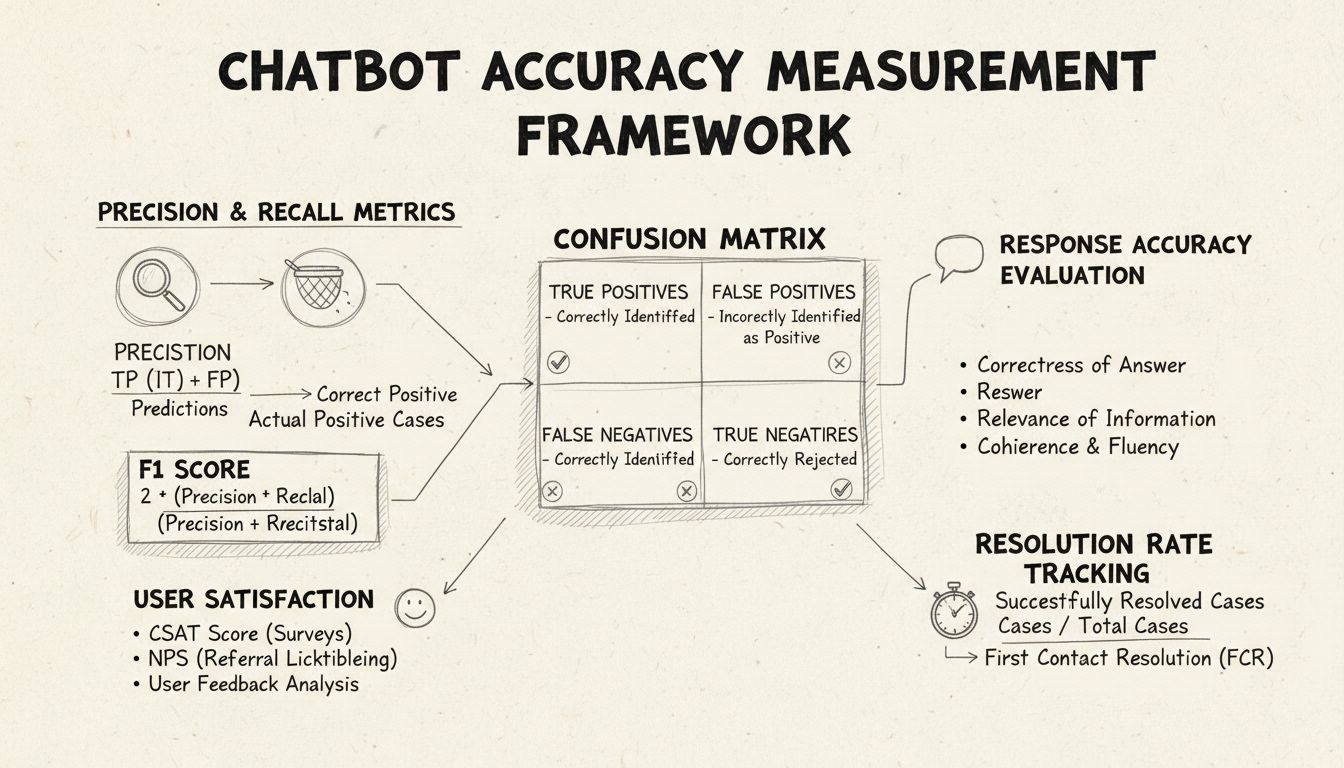
Precisão e recall são métricas fundamentais derivadas da matriz de confusão que medem diferentes aspectos do desempenho do chatbot. Precisão representa a proporção de respostas corretas em relação a todas as respostas fornecidas pelo chatbot, calculada pela fórmula: Precisão = Verdadeiros Positivos / (Verdadeiros Positivos + Falsos Positivos). Esta métrica responde à pergunta: “Quando o chatbot fornece uma resposta, com que frequência ela está correta?” Um alto índice de precisão indica que o chatbot raramente fornece informações incorretas, o que é crucial para manter a confiança do usuário em cenários de helpdesk.
Recall, também conhecido como sensibilidade, mede a proporção de respostas corretas em relação a todas as respostas corretas que o chatbot deveria ter fornecido, usando a fórmula: Recall = Verdadeiros Positivos / (Verdadeiros Positivos + Falsos Negativos). Esta métrica verifica se o chatbot identifica e responde com sucesso a todas as questões legítimas dos clientes. Em contextos de helpdesk, um recall elevado garante que os clientes recebam assistência para seus problemas, em vez de serem informados de que o chatbot não pode ajudar quando, na verdade, poderia. A relação entre precisão e recall cria um trade-off natural: otimizar uma geralmente reduz a outra, exigindo um equilíbrio cuidadoso de acordo com as prioridades do seu negócio.
O F1 Score fornece uma métrica única que equilibra precisão e recall, calculada como a média harmônica: F1 = 2 × (Precisão × Recall) / (Precisão + Recall). Essa métrica é especialmente valiosa quando se busca um indicador de desempenho unificado ou ao lidar com conjuntos de dados desbalanceados, nos quais uma classe supera significativamente as outras. Por exemplo, se seu chatbot lida com 1.000 perguntas rotineiras, mas apenas 50 casos complexos, o F1 Score impede que a métrica seja distorcida pela classe majoritária. O F1 Score varia de 0 a 1, sendo 1 a representação de precisão e recall perfeitos, tornando-o intuitivo para que stakeholders compreendam o desempenho geral do chatbot rapidamente.
A matriz de confusão é uma ferramenta fundamental que divide o desempenho do chatbot em quatro categorias: Verdadeiros Positivos (respostas corretas para perguntas válidas), Verdadeiros Negativos (recusa correta a perguntas fora do escopo), Falsos Positivos (respostas incorretas) e Falsos Negativos (oportunidades perdidas de ajudar). Essa matriz revela padrões específicos das falhas do chatbot, permitindo melhorias direcionadas. Por exemplo, se a matriz mostra muitos falsos negativos em dúvidas de cobrança, é possível identificar que os dados de treinamento do chatbot carecem de exemplos suficientes sobre o tema, necessitando de reforço nesse domínio.
| Métrica | Definição | Cálculo | Impacto no Negócio |
|---|---|---|---|
| Verdadeiros Positivos (VP) | Respostas corretas para perguntas válidas | Contado diretamente | Constrói confiança do cliente |
| Verdadeiros Negativos (VN) | Recusa correta a perguntas fora do escopo | Contado diretamente | Previne desinformação |
| Falsos Positivos (FP) | Respostas incorretas fornecidas | Contado diretamente | Prejudica credibilidade |
| Falsos Negativos (FN) | Oportunidades perdidas de ajudar | Contado diretamente | Reduz satisfação |
| Precisão | Qualidade das previsões positivas | VP / (VP + FP) | Métrica de confiabilidade |
| Recall | Cobertura dos positivos reais | VP / (VP + FN) | Métrica de completude |
| Acurácia | Correção geral | (VP + VN) / Total | Desempenho geral |
A precisão das respostas mede com que frequência o chatbot fornece informações factualmente corretas que respondem diretamente à solicitação do usuário. Isso vai além da simples correspondência de padrões para avaliar se o conteúdo é preciso, atualizado e apropriado ao contexto. Processos de revisão manual envolvem avaliadores humanos analisando uma amostra aleatória de conversas, comparando as respostas do chatbot com uma base de conhecimento predefinida de respostas corretas. Métodos automatizados de comparação podem ser implementados usando técnicas de processamento de linguagem natural para comparar respostas com as esperadas armazenadas em seu sistema, embora exijam calibração cuidadosa para evitar falsos negativos quando o chatbot fornece informações corretas com redação diferente da resposta de referência.
A relevância da resposta avalia se a resposta do chatbot realmente aborda o que o usuário perguntou, mesmo que não seja perfeitamente correta. Essa dimensão captura situações em que o chatbot fornece informações úteis que, embora não sejam a resposta exata, direcionam a conversa para a resolução. Métodos baseados em PLN, como similaridade cosseno, podem medir a similaridade semântica entre a pergunta do usuário e a resposta do chatbot, oferecendo uma pontuação de relevância automatizada. Mecanismos de feedback do usuário, como avaliações positivas/negativas após cada interação, fornecem uma avaliação direta da relevância por quem mais importa — seus clientes. Esses sinais de feedback devem ser continuamente coletados e analisados para identificar padrões sobre quais tipos de perguntas o chatbot lida bem ou mal.
O Índice de Satisfação do Cliente (CSAT) mede a satisfação do usuário nas interações com o chatbot por meio de pesquisas diretas, geralmente utilizando uma escala de 1 a 5 ou avaliações simples de satisfação. Após cada interação, os usuários são convidados a classificar sua satisfação, fornecendo feedback imediato sobre se o chatbot atendeu suas necessidades. Pontuações de CSAT acima de 80% geralmente indicam forte desempenho, enquanto abaixo de 60% sinalizam problemas importantes a serem investigados. A vantagem do CSAT é sua simplicidade e objetividade — os usuários declaram explicitamente se estão satisfeitos —, mas ele pode ser influenciado por fatores além da precisão do chatbot, como a complexidade do problema ou expectativas do usuário.
O Net Promoter Score mede a probabilidade de usuários recomendarem o chatbot a outros, calculado pela pergunta “Quão provável é que você recomende este chatbot a um colega?”, numa escala de 0 a 10. Respondentes com nota 9-10 são promotores, 7-8 são neutros, e 0-6 são detratores. NPS = (Promotores - Detratores) / Total de Respondentes × 100. Essa métrica está fortemente correlacionada à lealdade do cliente a longo prazo e indica se o chatbot gera experiências positivas que os usuários desejam compartilhar. Um NPS acima de 50 é considerado excelente, enquanto NPS negativo aponta problemas sérios de desempenho.
A análise de sentimento examina o tom emocional das mensagens do usuário antes e depois das interações com o chatbot para avaliar a satisfação. Técnicas avançadas de PLN classificam mensagens como positivas, neutras ou negativas, revelando se os usuários ficam mais satisfeitos ou frustrados ao longo das conversas. Uma mudança positiva de sentimento indica que o chatbot resolveu as preocupações com sucesso; mudanças negativas sugerem que o chatbot pode ter frustrado usuários ou falhado em atender suas necessidades. Esta métrica captura dimensões emocionais que métricas tradicionais de precisão não alcançam, fornecendo contexto valioso para entender a qualidade da experiência do usuário.
A Resolução no Primeiro Contato mede a porcentagem de questões resolvidas pelo chatbot sem necessidade de encaminhamento para agentes humanos. Essa métrica impacta diretamente a eficiência operacional e a satisfação do cliente, pois os usuários preferem resolver seus problemas imediatamente. Taxas de FCR acima de 70% indicam forte desempenho do chatbot, enquanto abaixo de 50% sugerem falta de conhecimento ou capacidade para lidar com demandas comuns. Acompanhar o FCR por categoria de problema revela quais tipos de questões o chatbot resolve bem e quais precisam de intervenção humana, orientando melhorias no treinamento e na base de conhecimento.
A taxa de escalonamento mede com que frequência o chatbot transfere conversas para agentes humanos, enquanto a frequência de fallback indica com que frequência o chatbot recorre a respostas genéricas como “Não entendi” ou “Por favor, reformule sua pergunta.” Altas taxas de escalonamento (acima de 30%) indicam falta de conhecimento ou confiança do chatbot em muitos cenários, enquanto altos índices de fallback sugerem problemas de reconhecimento de intenção ou dados de treinamento insuficientes. Essas métricas identificam lacunas específicas nas capacidades do chatbot que podem ser resolvidas com expansão da base de conhecimento, re-treinamento do modelo ou aprimoramento dos componentes de compreensão de linguagem natural.
O tempo de resposta mede a rapidez com que o chatbot responde às mensagens dos usuários, normalmente em milissegundos ou segundos. Usuários esperam respostas quase instantâneas; atrasos acima de 3-5 segundos impactam significativamente a satisfação. O tempo de atendimento mede a duração total desde o início do contato até a resolução ou escalonamento do problema, oferecendo insights sobre a eficiência do chatbot. Tempos de atendimento mais curtos indicam que o chatbot entende e resolve questões rapidamente, enquanto tempos mais longos sugerem necessidade de múltiplas rodadas de esclarecimento ou dificuldade com dúvidas complexas. Essas métricas devem ser acompanhadas separadamente por categoria de problema, já que questões técnicas complexas naturalmente exigem mais tempo de atendimento do que perguntas simples de FAQ.
LLM As a Judge representa uma abordagem sofisticada de avaliação, na qual um grande modelo de linguagem avalia a qualidade das respostas de outro sistema de IA. Essa metodologia é especialmente eficaz para avaliar respostas do chatbot em múltiplas dimensões de qualidade ao mesmo tempo, como precisão, relevância, coerência, fluência, segurança, completude e tom. Pesquisas mostram que juízes LLM podem alcançar até 85% de alinhamento com avaliações humanas, tornando-se uma alternativa escalável à revisão manual. O processo envolve definir critérios específicos de avaliação, criar prompts detalhados de julgamento com exemplos, fornecer ao juiz tanto a solicitação original do usuário quanto a resposta do chatbot, e receber pontuações estruturadas ou feedback detalhado.
O processo LLM As a Judge geralmente utiliza duas abordagens: avaliação de saída única, em que o juiz pontua uma resposta individual usando avaliação sem referência (sem resposta padrão) ou comparação baseada em referência (com resposta esperada); e comparação pareada, em que o juiz compara duas respostas para identificar a superior. Essa flexibilidade permite avaliar tanto o desempenho absoluto quanto melhorias relativas ao testar diferentes versões ou configurações do chatbot. A plataforma FlowHunt oferece suporte à implementação do LLM As a Judge por meio de interface drag-and-drop, integração com LLMs líderes como ChatGPT e Claude, e toolkit CLI para relatórios avançados e avaliações automatizadas.
Além dos cálculos básicos de precisão, a análise detalhada da matriz de confusão revela padrões específicos de falhas do chatbot. Ao examinar quais tipos de perguntas produzem falsos positivos versus falsos negativos, é possível identificar fraquezas sistemáticas. Por exemplo, se a matriz mostra que o chatbot frequentemente classifica erroneamente perguntas de cobrança como suporte técnico, isso revela um desequilíbrio nos dados de treinamento ou problema de reconhecimento de intenção no domínio de cobrança. Criar matrizes de confusão separadas por categoria de problema permite melhorias direcionadas ao invés de re-treinamento genérico do modelo.
Testes A/B comparam diferentes versões do chatbot para determinar qual apresenta melhor desempenho em métricas-chave. Isso pode envolver a avaliação de diferentes templates de resposta, configurações de base de conhecimento ou modelos de linguagem subjacentes. Ao direcionar aleatoriamente parte do tráfego para cada versão e comparar métricas como taxa de FCR, CSAT e precisão das respostas, é possível tomar decisões baseadas em dados sobre quais melhorias implementar. O teste A/B deve ser realizado por tempo suficiente para capturar variações naturais das solicitações dos usuários e garantir significância estatística dos resultados.
A FlowHunt oferece uma plataforma integrada para construir, implantar e avaliar chatbots de helpdesk com IA com avançadas capacidades de medição de precisão. O construtor visual da plataforma permite que usuários não técnicos criem fluxos sofisticados de chatbot, enquanto seus componentes de IA integram os principais modelos de linguagem como ChatGPT e Claude. O kit de avaliação da FlowHunt permite implementar a metodologia LLM As a Judge, permitindo que você defina critérios de avaliação personalizados e avalie automaticamente o desempenho do chatbot em todo o seu conjunto de conversas.
Para implementar uma medição abrangente de precisão com a FlowHunt, comece definindo critérios de avaliação alinhados aos objetivos do negócio — seja priorizando precisão, velocidade, satisfação do usuário ou taxas de resolução. Configure o LLM juiz da plataforma com prompts detalhados que especifiquem como avaliar as respostas, incluindo exemplos concretos de boas e más respostas. Carregue seu conjunto de conversas ou conecte o tráfego ao vivo, depois execute avaliações para gerar relatórios detalhados mostrando o desempenho em todas as métricas. O painel da FlowHunt oferece visibilidade em tempo real do desempenho do chatbot, permitindo identificação rápida de problemas e validação de melhorias.
Estabeleça uma medição de referência antes de implementar melhorias, criando um ponto de comparação para avaliar o impacto das mudanças. Colete medições continuamente em vez de periodicamente, permitindo a detecção precoce de degradação de desempenho causada por deriva de dados ou envelhecimento do modelo. Implemente loops de feedback em que avaliações e correções dos usuários alimentam automaticamente o processo de treinamento, melhorando continuamente a precisão do chatbot. Segmente as métricas por categoria de problema, tipo de usuário e período para identificar áreas específicas que precisam de atenção, evitando depender apenas de estatísticas agregadas.
Garanta que seu conjunto de avaliação represente perguntas reais de usuários e respostas esperadas, evitando casos de teste artificiais que não refletem padrões reais de uso. Valide regularmente as métricas automatizadas com avaliações humanas, pedindo que avaliadores analisem manualmente uma amostra de conversas para garantir que o sistema de medição permaneça calibrado à qualidade real. Documente claramente sua metodologia e definições de métricas, permitindo avaliações consistentes ao longo do tempo e comunicação clara dos resultados aos stakeholders. Por fim, estabeleça metas de desempenho para cada métrica alinhadas aos objetivos do negócio, criando responsabilidade pela melhoria contínua e objetivos claros para os esforços de otimização.
A avançada plataforma de automação com IA da FlowHunt ajuda você a criar, implantar e avaliar chatbots de helpdesk de alto desempenho com ferramentas integradas de medição de precisão e capacidades de avaliação baseadas em LLM.
Aprenda estratégias abrangentes de teste para chatbots de IA, incluindo testes funcionais, de desempenho, segurança e usabilidade. Descubra as melhores práticas...
Conheça as melhores formas de abordar assistentes de chatbot de IA em 2025. Descubra estilos de comunicação formais, casuais e divertidos, convenções de nomeaçã...
Domine o uso de chatbots de IA com nosso guia abrangente. Aprenda técnicas de prompting eficazes, melhores práticas e como tirar o máximo proveito dos chatbots ...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.