Ingineria Contextului: Ghidul Definitiv 2025 pentru Stăpânirea Designului Sistemelor AI
Aprofundează ingineria contextului pentru AI. Acest ghid acoperă principiile de bază, de la prompt vs. context la strategii avansate precum managementul memoriei, putrezirea contextului și designul multi-agent.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Peisajul dezvoltării AI a suferit o transformare profundă. Dacă înainte ne concentram pe perfecționarea promptului, acum ne confruntăm cu o provocare mult mai complexă: construirea unor arhitecturi informaționale complete care să înconjoare și să potențeze modelele de limbaj.
Această schimbare marchează evoluția de la ingineria prompturilor la ingineria contextului—și reprezintă, fără exagerare, viitorul dezvoltării AI practice. Sistemele care aduc cu adevărat valoare astăzi nu se bazează pe prompturi magice. Ele au succes pentru că arhitecții lor au învățat să orchestreze ecosisteme informaționale cuprinzătoare.
Andrej Karpathy a surprins perfect această evoluție când a descris ingineria contextului ca practica atentă de a popula fereastra de context cu exact informația potrivită, la momentul potrivit. Această afirmație, aparent simplă, dezvăluie un adevăr fundamental: LLM-ul nu mai este vedeta spectacolului. Este o componentă esențială într-un sistem atent proiectat unde fiecare fragment de informație—fiecare bucățică de memorie, fiecare descriere de instrument, fiecare document recuperat—a fost plasat deliberat pentru a maximiza rezultatele.
Ce este Ingineria Contextului?
O Perspectivă Istorică
Rădăcinile ingineriei contextului sunt mai adânci decât cred mulți. Deși discuțiile despre ingineria prompturilor au explodat în 2022-2023, conceptele de bază ale ingineriei contextului au apărut acum peste două decenii, din cercetarea în computare ubicuă și interacțiunea om-calculator.
Încă din 2001, Anind K. Dey a stabilit o definiție surprinzător de vizionară: contextul cuprinde orice informație care ajută la caracterizarea situației unei entități. Acest cadru timpuriu a pus bazele modului în care gândim înțelegerea mediului de către mașini.
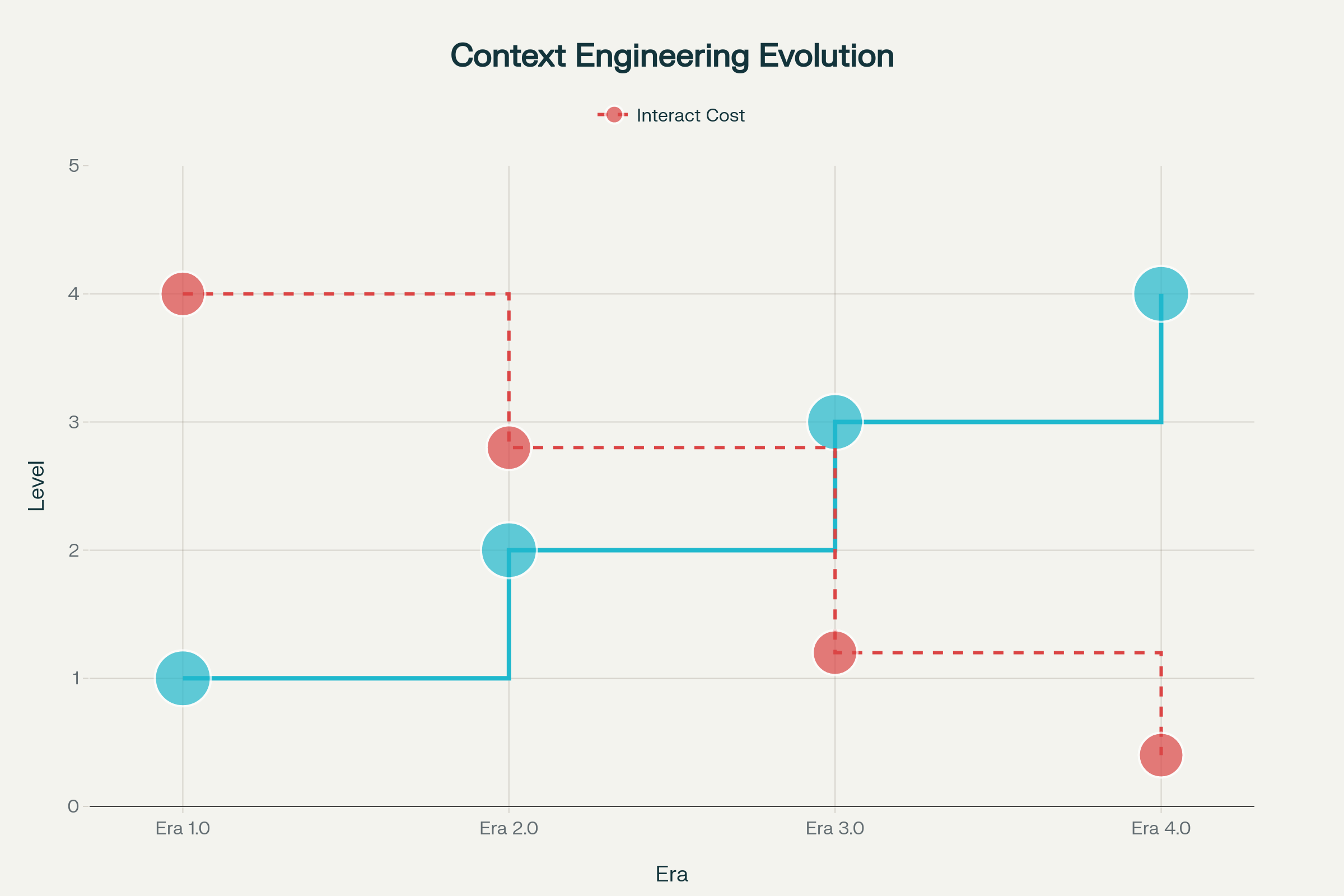
Evoluția ingineriei contextului s-a derulat pe mai multe etape, fiecare modelată de progresele inteligenței mașinilor:
Era 1.0: Computație Primtivă (anii ‘90–2020) — În această perioadă extinsă, mașinile puteau gestiona doar intrări structurate și semnale de bază din mediu. Oamenii purtau întreaga povară a traducerii contextelor în formate procesabile de computer. Gândește-te la aplicații desktop, aplicații mobile cu senzori de bază și chatboți timpurii cu arbori de răspuns rigizi.
Era 2.0: Inteligență Centrată pe Agent (2020–Prezent) — Lansarea GPT-3 în 2020 a declanșat o schimbare de paradigmă. Modelele mari de limbaj au adus o adevărată înțelegere a limbajului natural și abilitatea de a lucra cu intenții implicite. Această eră a permis colaborarea autentică om-agent, unde ambiguitatea și informațiile incomplete au putut fi gestionate prin înțelegere sofisticată a limbajului și învățare în context.
Era 3.0 & 4.0: Inteligență Umană și Supraumana (Viitorul) — Următoarele valuri promit sisteme care pot simți și procesa informație cu entropie mare cu fluiditate umană, depășind în cele din urmă răspunsul reactiv spre construirea proactivă a contextului și anticiparea nevoilor pe care utilizatorii nici măcar nu le-au articulat.
Evoluția Ingineriei Contextului în Patru Ere: De la Computare Primtivă la Inteligență Supraumana
O Definiție Formală
La bază, ingineria contextului reprezintă disciplina sistematică de a proiecta și optimiza modul în care informația contextuală circulă prin sistemele AI—de la colectarea inițială, la stocare, management și până la utilizarea finală pentru a îmbunătăți înțelegerea și execuția sarcinilor de către mașini.
Putem exprima asta matematic ca o funcție de transformare:
$CE: (C, T) \rightarrow f_{context}$
Unde:
C reprezintă informația contextuală brută (entități și caracteristici ale lor)
T denotă sarcina țintă sau domeniul de aplicare
f_{context} generează funcția de procesare a contextului rezultat
Descompus practic, se evidențiază patru operații fundamentale:
Colectarea semnalelor contextuale relevante prin senzori diverși și canale informaționale
Stocarea eficientă a acestei informații pe sisteme locale, infrastructură de rețea și platforme cloud
Gestionarea complexității prin procesare inteligentă a textului, intrări multi-modale și relații complexe
Utilizarea strategică a contextului prin filtrare pentru relevanță, partajare între sisteme și adaptare în funcție de cerințele utilizatorului
De ce Contează Ingineria Contextului: Cadrul Reducerii Entropiei
Ingineria contextului abordează o asimetrie fundamentală în comunicarea om-mașină. Când oamenii conversează, umplu fără efort golurile conversaționale prin cunoștințe culturale partajate, inteligență emoțională și conștientizare situațională. Mașinile nu dispun de niciuna dintre aceste capacități.
Această diferență se manifestă ca entropie informațională. Comunicarea umană este eficientă deoarece presupunem cantități uriașe de context comun. Mașinile necesită ca totul să fie explicit reprezentat. Ingineria contextului este, fundamental, despre preprocesarea contextelor pentru mașini—compresând complexitatea cu entropie mare a intențiilor și situațiilor umane în reprezentări cu entropie mică, procesabile de mașini.
Pe măsură ce inteligența artificială avansează, această reducere a entropiei devine tot mai automatizată. Astăzi, în Era 2.0, inginerii trebuie să orchestreze manual mare parte din această reducere. În Era 3.0 și ulterior, mașinile vor prelua tot mai mult din această povară. Totuși, provocarea centrală rămâne: să facem legătura între complexitatea umană și înțelegerea mașinii.
Ingineria Prompturilor vs. Ingineria Contextului: Diferențe Critice
O confuzie frecventă le pune la același nivel. În realitate, ele reprezintă abordări fundamental diferite de arhitectură a sistemelor AI.
Ingineria prompturilor se concentrează pe formularea instrucțiunilor sau interogărilor individuale pentru a modela comportamentul modelului. E despre optimizarea structurii lingvistice a ceea ce comunici modelului—formulări, exemple și tipare de raționament într-o singură interacțiune.
Ingineria contextului este o disciplină de sistem completă, care gestionează tot ce întâlnește modelul în timpul inferenței—incluzând prompturile, dar și documente recuperate, sisteme de memorie, descrieri de instrumente, informații de stare și multe altele.
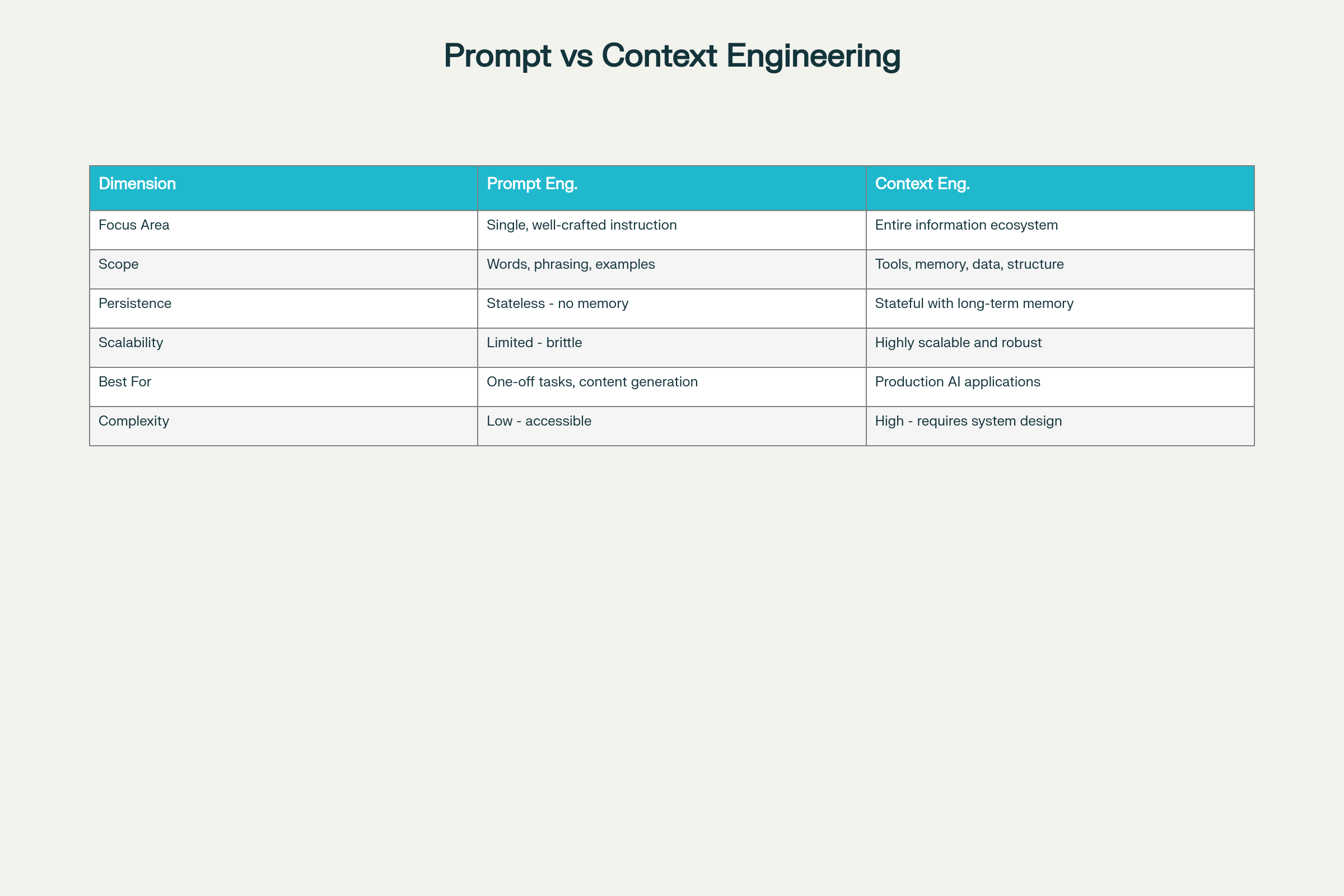
Ingineria Prompturilor vs Ingineria Contextului: Diferențe și Compromisuri Cheie
Gândește-te așa: Să ceri lui ChatGPT să compună un email profesional este inginerie de prompt. Să construiești o platformă de suport clienți care păstrează istoricul conversațiilor pe mai multe sesiuni, accesează detalii despre contul utilizatorului și reține tichete de suport anterioare—aceasta este inginerie de context.
Diferențe Cheie pe Opt Dimensiuni:
Dimensiune
Ingineria Prompturilor
Ingineria Contextului
Aria de focalizare
Optimizarea instrucțiunii individuale
Ecosistem informațional cuprinzător
Anvergură
Cuvinte, formulări, exemple
Instrumente, memorie, arhitectură date, structură
Persistență
Fără stare—fără memorie
Cu stare și memorie pe termen lung
Scalabilitate
Limitată și fragilă la scară
Scalabilă și robustă
Ideal pentru
Sarcini punctuale, generare de conținut
Aplicații AI de producție
Complexitate
Prag de intrare redus
Mare—necesită expertiză de sistem
Fiabilitate
Imprevizibilă la scară
Consistentă și de încredere
Mentenanță
Fragilă la schimbări de cerințe
Modulară și ușor de întreținut
Ideea crucială: Aplicațiile LLM de producție necesită copleșitor inginerie de context, nu doar prompturi ingenioase. După cum a observat Cognition AI, ingineria contextului a devenit, de fapt, principala responsabilitate a inginerilor care construiesc agenți AI.
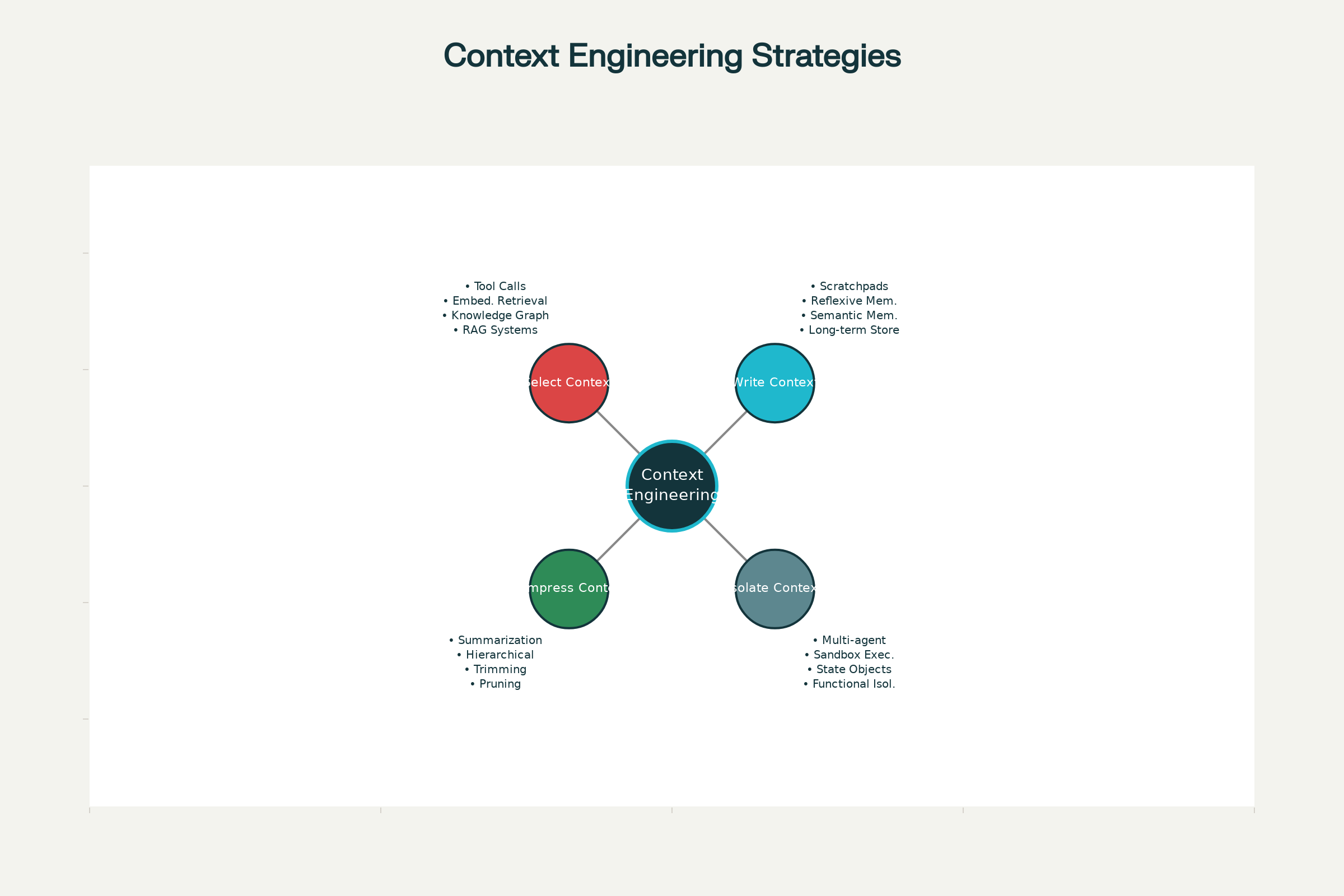
Cele Patru Strategii de Bază pentru Ingineria Contextului
În marile sisteme AI—de la Claude și ChatGPT la agenți specializați dezvoltați la Anthropic și alte laboratoare de frontieră—s-au cristalizat patru strategii de bază pentru managementul eficient al contextului. Acestea pot fi folosite independent sau combinate pentru efect sporit.
1. Scrierea Contextului: Persistarea Informației în afara Ferestrei de Context
Principiul fundamental este elegant: nu forța modelul să-și amintească tot. În schimb, persistă informațiile critice în afara ferestrei de context, unde pot fi accesate fiabil la nevoie.
Notițele (Scratchpads) sunt cea mai intuitivă implementare. Așa cum oamenii iau notițe când rezolvă probleme complexe, agenții AI folosesc scratchpads pentru a păstra informații de referință ulterioară. Implementarea poate fi la fel de simplă ca un instrument pe care agentul îl folosește pentru notițe, sau atât de sofisticată ca câmpuri într-un obiect de stare runtime care persistă între pași de execuție.
Cercetătorul multi-agent al Anthropic demonstrează acest lucru: LeadResearcher formulează un plan și îl salvează în Memorie pentru persistență, știind că dacă fereastra de context trece de 200.000 de tokeni, va avea loc trunchierea și planul trebuie păstrat.
Memoriile extind conceptul de scratchpad între sesiuni. În loc să captureze informații doar într-o singură sarcină (memorie la nivel de sesiune), sistemele pot construi memorii pe termen lung care persistă și evoluează pe parcursul mai multor interacțiuni utilizator-agent. Acest model a devenit standard în produse precum ChatGPT, Claude Code, Cursor și Windsurf.
Inițiative precum Reflexion au introdus memoria reflexivă—agentul reflectă la fiecare pas și generează memorii pentru referință viitoare. Generative Agents extind această abordare prin sintetizarea periodică a memoriilor din colecții de feedback anterior.
Trei Tipuri de Memorii:
Episodică: Exemple concrete de comportament sau interacțiuni trecute (invalabile pentru few-shot learning)
Procedurală: Instrucțiuni sau reguli de comportament (pentru consistență)
Semantică: Fapte și relații despre lume (pentru cunoaștere ancorată)
Odată ce informația a fost păstrată, agentul trebuie să recupereze doar ceea ce este relevant pentru sarcina curentă. O selecție slabă poate fi la fel de dăunătoare ca lipsa memoriei—contextul irelevant poate deruta modelul sau declanșa halucinații.
Mecanisme pentru Selectarea Memoriei:
Abordările simple folosesc fișiere înguste incluse mereu. Claude Code folosește un fișier CLAUDE.md pentru memorii procedurale, iar Cursor și Windsurf utilizează fișiere de tip rules. Totuși, această abordare nu scalează când agentul acumulează sute de fapte și relații.
Pentru colecțiile mari de memorie, recuperarea bazată pe embedding și grafuri de cunoștințe sunt des utilizate. Sistemul convertește atât memoriile, cât și interogarea curentă în reprezentări vectoriale și recuperează cele mai apropiate semantic.
Totuși, așa cum a demonstrat Simon Willison la AIEngineer World’s Fair, această abordare poate eșua spectaculos. ChatGPT a introdus locația sa din memorie într-o imagine generată, arătând că și sistemele sofisticate pot recupera amintiri nepotrivite. De aici rezultă importanța ingineriei atente.
Selectarea Instrumentelor este o provocare proprie. Când agenții au acces la zeci sau sute de instrumente, simpla enumerare a lor poate cauza confuzie—descrieri suprapuse duc la alegeri greșite. O soluție eficientă: aplică principii RAG asupra descrierilor instrumentelor. Recuperând doar instrumente relevante semantic, s-au obținut îmbunătățiri de trei ori la acuratețea selecției.
Recuperarea Cunoștințelor este poate cea mai bogată zonă de probleme. Agenții de cod exemplifică această provocare la scară de producție. Un inginer Windsurf nota că indexarea codului nu înseamnă și recuperarea eficientă a contextului. Folosesc indexare și căutare embedding cu parsare AST și segmentare pe granițe semantice. Dar căutarea embedding devine nesigură pe codebase-uri mari. Succesul necesită combinarea de tehnici precum grep/căutare fișiere, recuperare pe graful de cunoștințe și re-rankare pentru relevanță.
3. Comprimarea Contextului: Păstrează Doar Ce e Necesar
Pe măsură ce agenții lucrează la sarcini pe termen lung, contextul se acumulează natural. Notițe, rezultate de instrumente și istoric interacțiuni pot depăși rapid fereastra de context. Strategiile de compresie rezolvă această problemă distilând inteligent informația, păstrând esențialul.
Rezumatul este tehnica principală. Claude Code implementează “auto-compact”—când fereastra de context atinge 95% din capacitate, rezumă întreaga traiectorie a interacțiunilor utilizator-agent. Se pot folosi strategii variate:
Rezumat recursiv: Crearea de rezumate ale rezumatelor pentru ierarhii compacte
Rezumat ierarhic: Generarea de rezumate la niveluri de abstractizare diferite
Rezumat țintit: Comprimarea anumitor componente (ca rezultate de căutare voluminoase), nu a întregului context
Cognition AI a dezvăluit că folosesc modele fine-tunate pentru rezumat la granițele agent-agent pentru a reduce consumul de tokeni la transferul de cunoștințe—dovedind profunzimea de inginerie necesară.
Tăierea Contextului reprezintă o abordare complementară. În loc să folosești un LLM pentru rezumat inteligent, tăierea elimină pur și simplu context folosind euristici: ștergerea mesajelor vechi, filtrarea pe importanță sau utilizarea unor pruneri antrenate precum Provence pentru QA.
Ideea cheie: Ce elimini contează la fel de mult ca ce păstrezi. Un context concentrat de 300 de tokeni bate adesea un context dispersat de 113.000 de tokeni la sarcini conversaționale.
4. Izolarea Contextului: Distribuirea Informației între Sisteme
În final, strategiile de izolare recunosc că sarcinile diferite necesită informații diferite. În loc să înghesui totul într-o singură fereastră de context, izolarea separă contextul între sisteme specializate.
Arhitecturi Multi-agent sunt cel mai des întâlnite. Biblioteca OpenAI Swarm a fost concepută explicit pe “separarea preocupărilor”—unde sub-agenți specializați gestionează sarcini cu instrumente, instrucțiuni și ferestre de context proprii.
Cercetarea Anthropic demonstrează eficiența: mulți agenți cu contexte izolate au depășit implementările cu agent unic, deoarece fiecare fereastră de context se poate aloca unei sub-sarcini restrânse. Subagenții operează în paralel, explorând simultan diverse aspecte.
Totuși, sistemele multi-agent implică compromisuri. Anthropic a raportat de până la cincisprezece ori mai mult consum de tokeni decât chat-ul cu un singur agent. Sunt necesare orchestrare atentă, prompt engineering pentru planificare și mecanisme sofisticate de coordonare.
Mediile Sandbox sunt o altă strategie de izolare. CodeAgent de la HuggingFace o demonstrează: în loc să returneze JSON pentru raționarea modelului, agentul generează cod care rulează într-un sandbox. Doar rezultatele selectate sunt retrimise către LLM, ținând obiectele voluminoase izolate în mediul de execuție. Aceasta excelează pentru date vizuale și audio.
Izolarea Obiectului de Stare este poate cea mai subapreciată tehnică. Starea de execuție a agentului poate fi proiectată ca schemă structurată (ex. model Pydantic) cu mai multe câmpuri. Un câmp (ca messages) este expus la fiecare pas LLM-ului, altele rămân izolate pentru uz selectiv. Oferă control fin fără complexitate arhitecturală.
Patru Strategii de Bază pentru Ingineria Contextului Eficientă în Agenții AI
Problema Putrezirii Contextului: O Provocare Critică
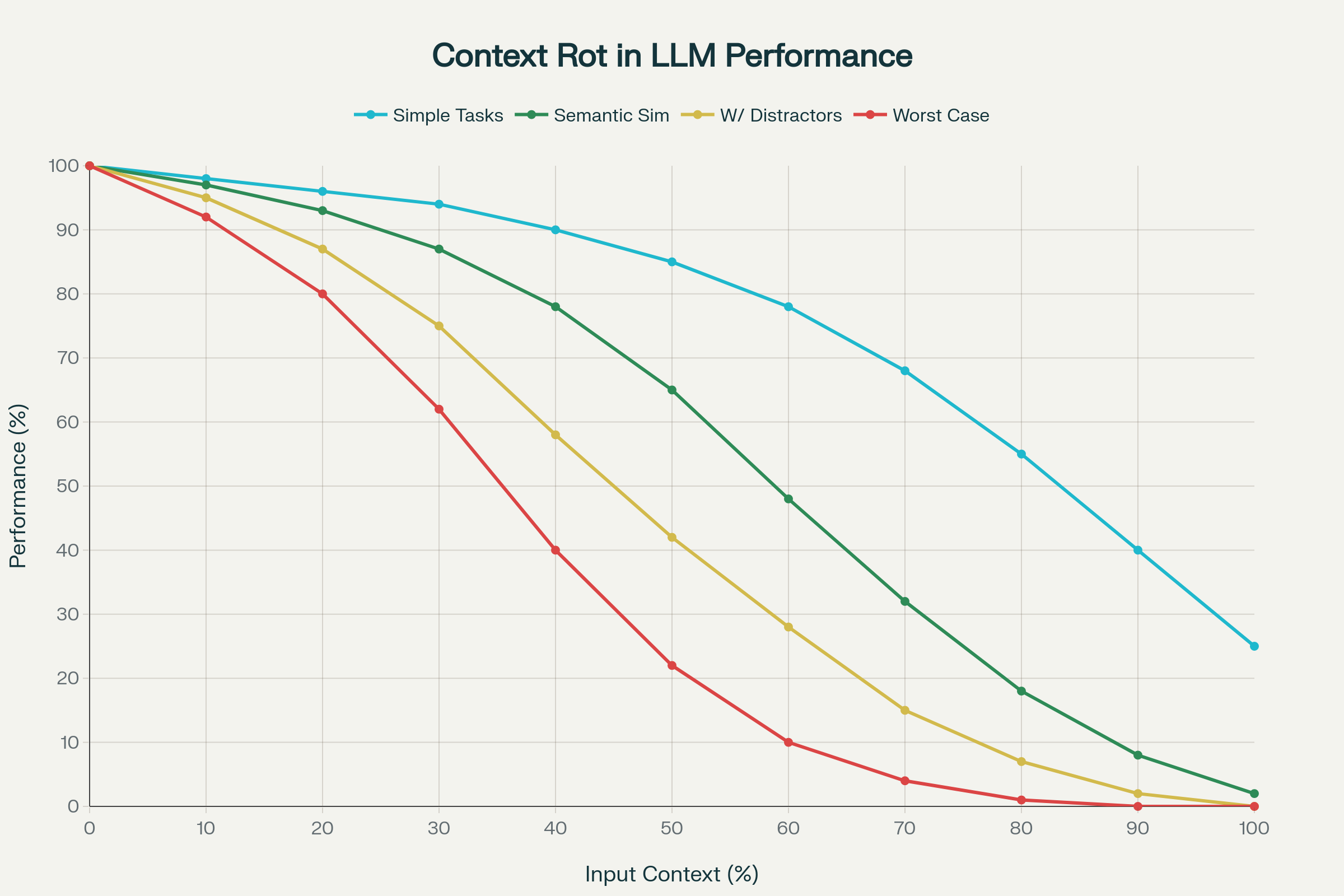
Deși industria a sărbătorit progresele privind lungimea contextului, cercetările recente scot la iveală o realitate îngrijorătoare: contextul mai lung nu înseamnă performanță mai bună.
Un studiu de referință analizând 18 LLM-uri de vârf—including GPT-4.1, Claude 4, Gemini 2.5 și Qwen 3—a descoperit fenomenul numit putrezirea contextului: degradarea imprevizibilă și adesea severă a performanței pe măsură ce contextul de intrare crește.
Constatări Cheie despre Putrezirea Contextului
1. Degradare Neuniformă a Performanței
Performanța nu scade liniar sau previzibil. Modelele afișează scăderi bruște, idiosincratice în funcție de model și sarcină. Un model poate menține 95% acuratețe până la un anumit prag, apoi scade brusc la 60%. Aceste „prăpastii” sunt imprevizibile.
Sarcinile simple (copierea cuvintelor sau recuperare semantică exactă) scad moderat. Dar când „acul în carul cu fân” necesită similaritate semantică, performanța scade vertiginos. Distractorii plauzibili agravează dramatic acuratețea.
3. Bias de poziție și colapsul atenției
Atenția transformatoarelor nu scalează liniar pe contexte lungi. Tokenii de la început (bias de primacy) și de la final (recency) primesc atenție disproporționată. În cazuri extreme, atenția colapsează, modelul ignorând părți mari din input.
4. Modele cu tipare de eșec specifice
LLM-urile diferite au comportamente unice la scară:
GPT-4.1: Tinde spre halucinații, repetă tokeni greșiți
Gemini 2.5: Introduce fragmente sau semne de punctuație irelevante
Claude Opus 4: Poate refuza sarcina sau devine prea precaut
5. Impact real în conversații
Mai grav: în benchmark-ul LongMemEval, modelele având acces la conversații complete (~113k tokeni) au avut performanță mai bună când li s-a oferit doar segmentul concentrat de 300 de tokeni. Dovadă că putrezirea contextului degradează atât recuperarea, cât și raționamentul în dialoguri reale.
Putrezirea Contextului: Degradarea Performanței la Creșterea Numărului de Tokeni de Intrare pentru 18 LLM-uri
Implicații: Calitate peste Cantitate
Concluzia principală: numărul de tokeni de intrare nu determină singur calitatea. Modul în care contextul este construit, filtrat și prezentat este la fel de important, dacă nu chiar mai important.
Această descoperire validează întreaga disciplină a ingineriei contextului. În loc să privim ferestrele lungi de context ca pe o soluție magică, echipele sofisticate recunosc că ingineria atentă a contextului—prin compresie, selecție și izolare—este esențială pentru menținerea performanței cu inputuri mari.
Ingineria Contextului în Practică: Aplicații Reale
Studiu de Caz 1: Sisteme Multi-turn Agent (Claude Code, Cursor)
Claude Code și Cursor sunt implementări de vârf ale ingineriei contextului pentru asistență la cod:
Colectare: Aceste sisteme adună context din surse diverse—fișiere deschise, structură de proiect, istoric editări, output terminal, comentarii utilizator.
Management: În loc să includă toate fișierele în prompt, comprimă inteligent. Claude Code folosește rezumate ierarhice. Contextul este etichetat funcțional (ex. “fișier editat”, “dependință referențiată”, “mesaj de eroare”).
Utilizare: La fiecare pas, sistemul selectează fișierele și elementele de context relevante, le prezintă structurat și menține pârghii separate pentru raționament și output vizibil.
Rezultat: Aceste unelte rămân utilizabile pe proiecte mari (mii de fișiere) fără degradare, în ciuda limitărilor ferestrei de context.
Studiu de Caz 2: Tongyi DeepResearch (Agent de Cercetare Deep Open-Source)
Tongyi DeepResearch arată cum ingineria contextului permite sarcini complexe de cercetare:
Pipeline de Sinteză Date: În loc de date annotate uman limitate, Tongyi folosește o sinteză sofisticată, generând întrebări de nivel PhD prin upgrade-uri iterative de complexitate. Fiecare iterație adâncește limitele cunoașterii și construiește sarcini de raționament complexe.
Management Context: Sistemul folosește paradigma IterResearch—la fiecare tură de cercetare, reconstruiește un workspace aerisit folosind doar outputurile esențiale din runda precedentă. Astfel evită „sufocarea cognitivă” prin acumularea tuturor informațiilor într-o singură fereastră de context.
Explorare Paralelă: Mai mulți agenți de cercetare operează în paralel cu contexte izolate, explorând aspecte diferite. Un agent de sinteză integrează apoi rezultatele pentru răspunsuri cuprinzătoare.
Rezultate: Tongyi DeepResearch atinge performanțe comparabile cu sisteme proprietare precum OpenAI DeepResearch, obținând 32.9 la Humanity’s Last Exam și 75 pe benchmark-uri centrate pe utilizator.
Studiu de Caz 3: Cercetătorul Multi-Agent Anthropic
Cercetarea Anthropic arată cum izolarea și specializarea cresc performanța:
Arhitectură: Sub-agenți specializați gestionează sarcini (revizuire literatură, sinteză, verificare) cu ferestre de context separate.
Beneficii: Această abordare a depășit sistemele cu un singur agent, fiecare context fiind optimizat pentru o sarcină restrânsă.
Compromis: Deși calitatea e superioară, consumul de tokeni a crescut de până la cincisprezece ori față de chat-ul cu agent unic.
Concluzie: ingineria contextului implică adesea compromisuri între calitate, viteză și cost. Echilibrul depinde de cerințele aplicației.
Cadrul de Considerații de Design
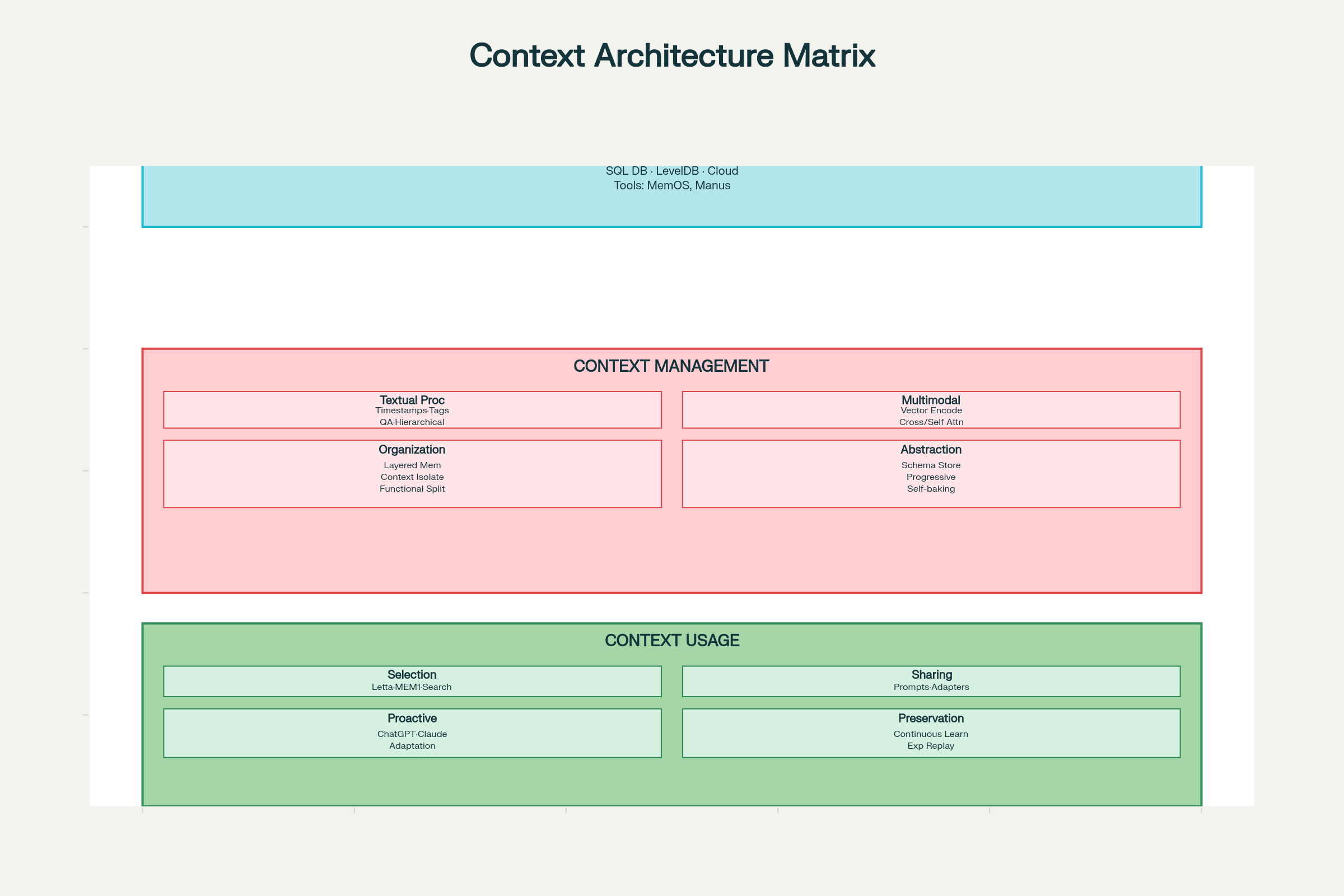
Implementarea eficientă a ingineriei contextului cere gândire sistematică pe trei dimensiuni: colectare & stocare, management și utilizare.
Considerații de Design pentru Ingineria Contextului: Arhitectură de Sistem și Componente
Sisteme Distribuite: Pentru scară mare cu redundanță și toleranță la erori
Pattern-uri de Design:
MemOS: Sistem de operare pentru management unificat al memoriei
Manus: Memorie structurată cu acces bazat pe roluri
Principiu cheie: Proiectează pentru recuperare eficientă, nu doar stocare. Sistemul optim este cel unde găsești rapid ce ai nevoie.
Decizii de Design pentru Management
Procesare Context Textual:
Marcarea cu Timestamps: Simplă, dar limitată. Păstrează ordinea cronologică, dar fără structură semantică—probleme de scalare.
Etichetare Rol/Funcție: Marchează fiecare element cu funcția sa—“scop”, “decizie”, “acțiune”, “eroare” etc. Suportă etichetare multi-dimensională (prioritate, sursă, încredere). Sisteme ca LLM4Tag enablează asta la scară.
Compresie cu Perechi QA: Conversia interacțiunilor în perechi întrebare-răspuns comprimate, păstrând esențialul cu mai puțini tokeni.
Notițe Ierarhice: Compresie progresivă în vectori de semnificație, ca în H-MEM, captând esența semantică pe mai multe niveluri.
Procesare Context Multi-modal:
Spații Vectoriale Comparabile: Encodează toate modalitățile (text, imagine, audio) în spații vectoriale comparabile prin embedding comun (ca ChatGPT, Claude).
Cross-Attention: Folosește o modalitate pentru ghidarea atenției pe alta (ex. Qwen2-VL).
Encoding Independent cu Self-Attention: Encodează separat, apoi combină prin mecanisme de atenție unificate.
Organizarea Contextului:
Arhitectură de Memorie Stratificată: Memorie de lucru (context curent), memorie pe termen scurt (istoric recent), memorie pe termen lung (fapte persistente).
Izolare Funcțională a Contextului: Sub-agenți cu ferestre de context separate pentru funcții diferite (modelul Claude).
Abstracția Contextului (Self-Baking):
Termenul “self-baking” desemnează îmbunătățirea contextului prin procesări repetate. Pattern-uri:
Stochează context brut, apoi adaugă rezumate în limbaj natural (Claude Code, Gemini CLI)
Extrage fapte cheie cu scheme fixe (abordarea ChatSchema)
Comprimă progresiv în vectori de semnificație (sisteme H-MEM)
Decizii de Design pentru Utilizare
Selectarea Contextului:
Recuperare pe bază de embedding (cel mai comun)
Traversare graf de cunoștințe (pentru relații complexe)
Scorare pe similaritate semantică
Pondere pe recență/prioritate
Partajarea Contextului:
În sistem:
Embedding context selectat în prompturi (AutoGPT, ChatDev)
Mesaje structurate între agenți (Letta, MemOS)
Memorie partajată prin comunicare indirectă (A-MEM)
Între sisteme:
Adaptori pentru conversia formatului contextului (Langroid)
Reprezentări partajate între platforme (Sharedrop)
Inferență Proactivă a Utilizatorului:
ChatGPT și Claude analizează tiparele de interacțiune pentru a
Întrebări frecvente
Ingineria prompturilor se concentrează pe crearea unei singure instrucțiuni pentru un LLM. Ingineria contextului este o disciplină de sisteme mai largă care gestionează întregul ecosistem informațional pentru un model AI, inclusiv memoria, instrumentele și datele recuperate, pentru a optimiza performanța pe sarcini complexe, cu stare.
'Putrezirea contextului' este degradarea imprevizibilă a performanței unui LLM pe măsură ce contextul de intrare devine mai lung. Modelele pot avea scăderi bruște de acuratețe, pot ignora părți din context sau pot halucina, evidențiind nevoia de calitate și management atent al contextului, nu doar de cantitate.
Cele patru strategii principale sunt: 1. Scrierea contextului (persistarea informației în afara ferestrei de context, ca notițe sau memorie), 2. Selectarea contextului (recuperarea doar a informațiilor relevante), 3. Comprimarea contextului (rezumarea sau tăierea pentru a economisi spațiu), și 4. Izolarea contextului (folosind sisteme multi-agent sau sandbox-uri pentru a separa preocupările).
Arshia este Inginer de Fluxuri AI la FlowHunt. Cu o pregătire în informatică și o pasiune pentru inteligența artificială, el este specializat în crearea de fluxuri eficiente care integrează instrumente AI în sarcinile de zi cu zi, sporind productivitatea și creativitatea.
Arshia Kahani
Inginer de Fluxuri AI
Stăpânește Ingineria Contextului
Ești gata să construiești următoarea generație de sisteme AI? Explorează resursele și instrumentele noastre pentru a implementa ingineria avansată a contextului în proiectele tale.
Trăiască Ingineria Contextului: Construirea Sistemelor AI de Producție cu Baze de Date Vectoriale Moderne
Descoperă cum ingineria contextului transformă dezvoltarea AI, evoluția de la RAG la sisteme gata de producție și de ce bazele de date vectoriale moderne precum...
OpenAI DevDay 2025: Apps SDK, Agent Kit, MCP și de ce Prompting-ul rămâne esențial pentru succesul AI
Explorează anunțurile OpenAI de la DevDay 2025, inclusiv Apps SDK, Agent Kit și Model Context Protocol. Află de ce prompting-ul este mai important ca niciodată ...