Cum să creezi pagini personalizate de bază de cunoștințe în Hugo din tichete LiveAgent
Învață cum să automatizezi crearea articolelor de bază de cunoștințe în Hugo direct din tichetele de suport clienți folosind agenți AI și integrare cu GitHub.
Automation
Knowledge Base
Hugo
GitHub
AI Agents
Customer Support
Echipele de suport clienți generează zilnic informații valoroase prin interacțiunile lor cu utilizatorii. Aceste întrebări, preocupări și soluții reprezintă o adevărată mină de aur de informații care ar putea fi utile întregii tale baze de utilizatori dacă ar fi documentate corespunzător. Totuși, conversia manuală a tichetelor de suport în articole bine redactate pentru baza de cunoștințe este consumatoare de timp, repetitivă și adesea lăsată pe planul doi în favoarea cererilor urgente. Dar dacă ai putea automatiza tot acest proces, transformând întrebările brute ale clienților în pagini de bază de cunoștințe formatate profesional și optimizate SEO, care apar direct pe website-ul tău? Exact asta fac fluxurile moderne de automatizare. Conectând sistemul tău de tichete LiveAgent cu generatorul de site static Hugo și cu controlul versiunilor prin GitHub, poți crea un flux integrat care transformă întrebările clienților în conținut ușor de găsit și indexat, automat. În acest ghid complet, vom explora cum să construiești acest sistem puternic de automatizare, arhitectura tehnică din spatele său și pașii practici pentru implementare în propria organizație.
Ce înseamnă automatizarea bazei de cunoștințe
O bază de cunoștințe este un depozit centralizat de informații creat pentru a ajuta utilizatorii să găsească răspunsuri la întrebări frecvente fără a apela la suportul direct. Bazele de cunoștințe tradiționale sunt construite manual—echipele de suport scriu articole, le formatează, le optimizează pentru motoarele de căutare și le publică printr-un sistem de management al conținutului. Acest proces necesită multă muncă și creează un blocaj major, mai ales pentru companiile în creștere care primesc zilnic sute de solicitări. Automatizarea bazei de cunoștințe schimbă această paradigmă folosind inteligența artificială pentru a extrage informații relevante din tichetele de suport, pentru a le structura conform unor șabloane prestabilite și pentru a le publica direct pe website. Sistemul de automatizare acționează ca un intermediar inteligent între echipa ta de suport și website, identificând tichetele care conțin cunoștințe generalizabile utile și transformând conversația brută în documentație profesională, bine structurată. Această abordare economisește timp și asigură consistență în format, structură și optimizare SEO pentru toate articolele. Sistemul poate fi configurat să țină cont de specificul afacerii tale, să evite crearea de conținut duplicat și să mențină o bază de cunoștințe coerentă, care crește organic odată cu volumul de tichete procesate de echipa de suport.
Pregătit să îți dezvolți afacerea?
Începe perioada de probă gratuită astăzi și vezi rezultate în câteva zile.
De ce contează automatizarea bazei de cunoștințe pentru afacerea ta
Argumentele de business pentru automatizarea bazei de cunoștințe sunt solide și variate. În primul rând, reduce dramatic volumul de solicitări prin faptul că le permite clienților să găsească răspunsuri pe cont propriu. Studiile arată constant că utilizatorii preferă opțiuni de tip self-service atunci când acestea sunt eficiente, iar o bază de cunoștințe bine întreținută poate reduce tichetele cu 20-30%. În al doilea rând, îmbunătățește satisfacția clienților oferind răspunsuri instantanee la întrebări frecvente, fără să fie nevoie ca utilizatorul să aștepte răspunsul echipei de suport. În al treilea rând, aduce beneficii SEO semnificative—articolele din baza de cunoștințe sunt indexate de motoarele de căutare și pot aduce trafic organic pe website, crescând vizibilitatea și atrăgând clienți noi care descoperă conținutul prin search. În al patrulea rând, captează cunoștințe instituționale care altfel s-ar pierde la plecarea unor membri ai echipei. Fiecare interacțiune de suport conține context și soluții valoroase care, odată documentate, devin parte din memoria organizației tale. În al cincilea rând, permite echipei de suport să se concentreze pe probleme complexe, cu valoare adăugată, în loc să răspundă la aceleași întrebări în mod repetat. Automatizând crearea de conținut pentru baza de cunoștințe din tichete, creezi practic un multiplicator de forță pentru organizația ta. Timpul petrecut de echipă răspunzând la întrebări devine cunoaștere documentată, ce va servi mii de clienți în viitor. În final, obții date valoroase despre ce probleme întâmpină clienții tăi, informații care pot ghida dezvoltarea de produs, mesajele de marketing și inițiativele de educare a clienților.
Arhitectura generării automate a bazei de cunoștințe
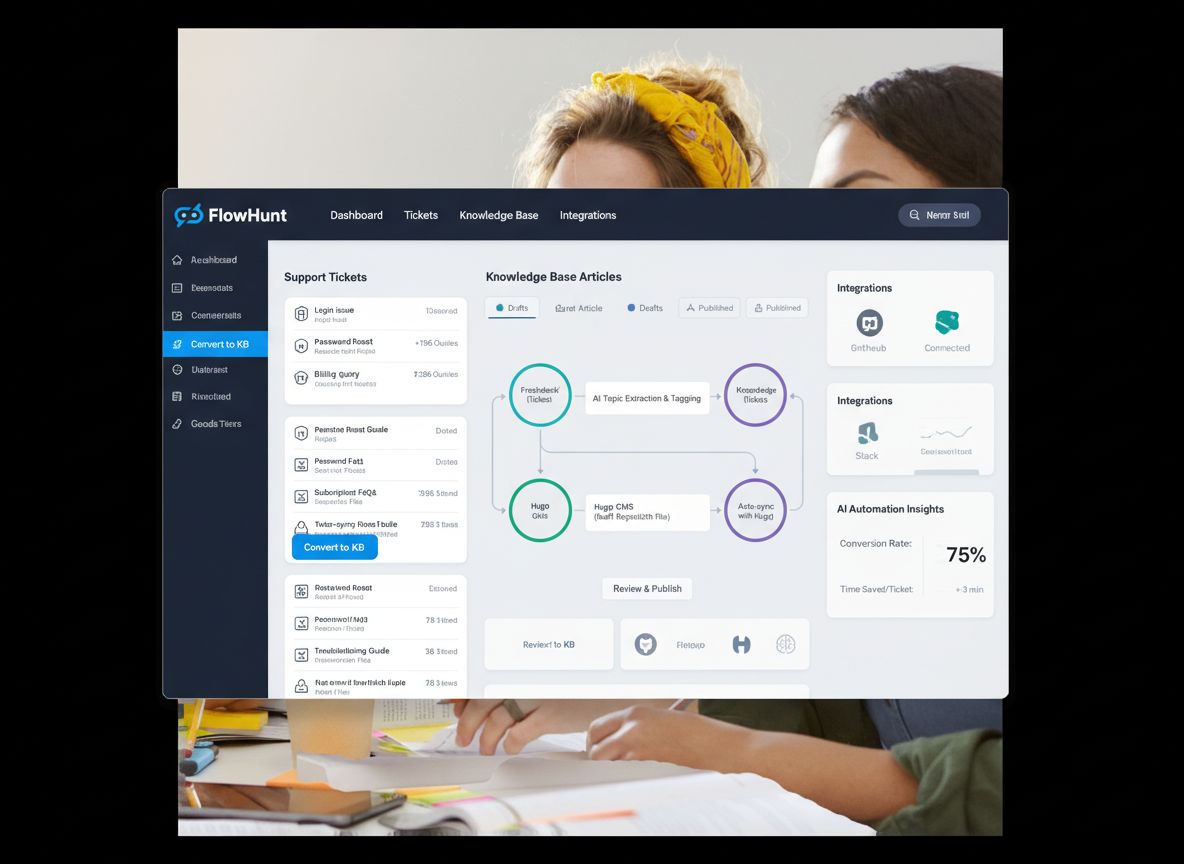
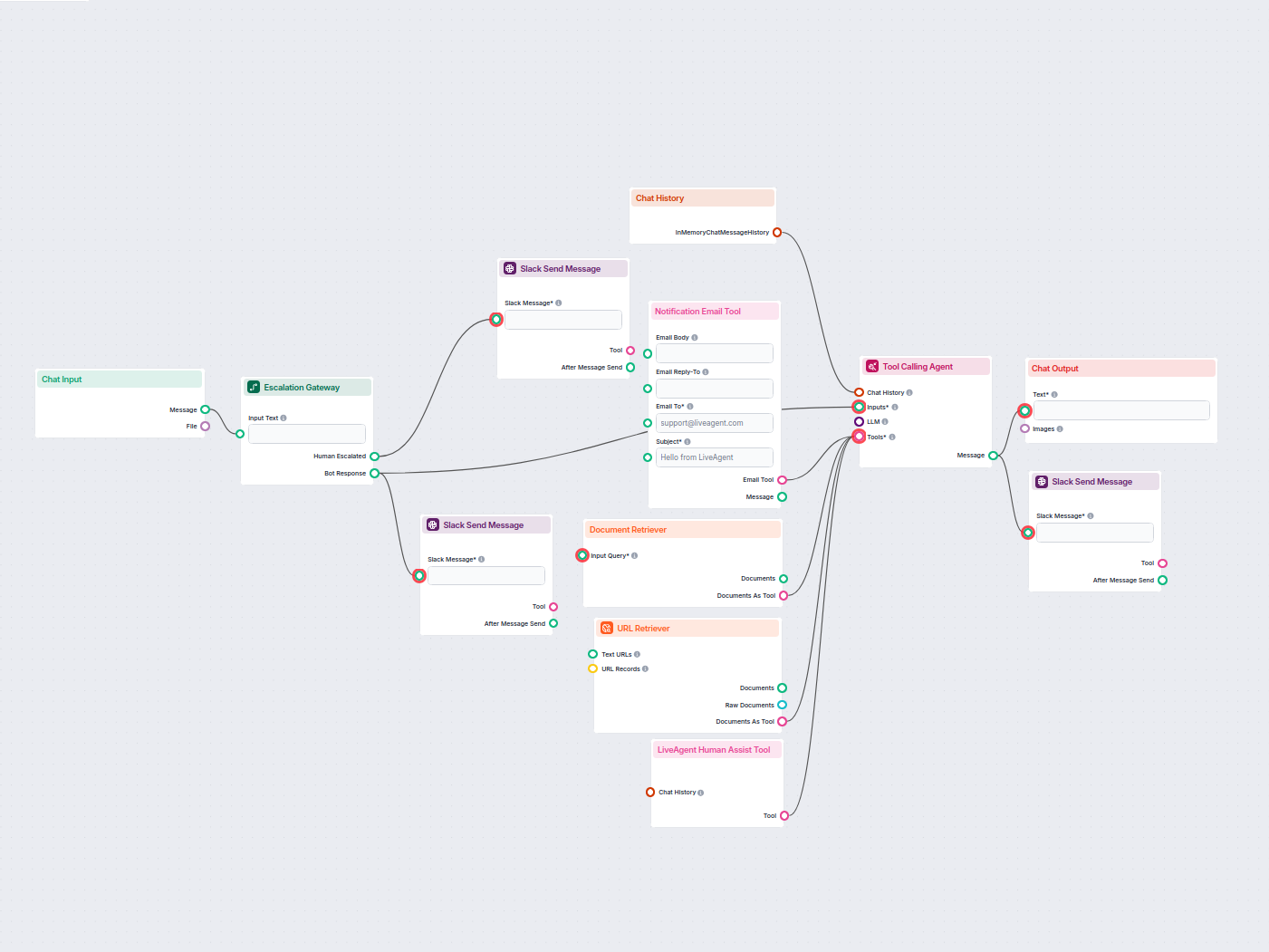
Construirea unui sistem automatizat de bază de cunoștințe presupune integrarea mai multor instrumente și platforme într-un flux coerent. Sistemul tipic include patru componente principale: un sistem de tichete (LiveAgent), un agent AI care procesează tichetele, un sistem de control al versiunilor (GitHub) și un generator de site static (Hugo). LiveAgent servește drept sursă de adevăr pentru solicitările clienților, stocând toate conversațiile cu metadate precum etichete, categorii și timestamp-uri. Agentul AI orchestrează întregul proces—primește un ID de tichet, extrage conținutul complet și istoricul conversației, analizează dacă este potrivit pentru publicare, verifică existența unor articole similare, generează conținut SEO optimizat în formatul potrivit și gestionează workflow-ul GitHub. GitHub acționează ca strat de management al conținutului și control al versiunilor, permițând revizuiri, aprobare și urmărirea tuturor modificărilor. Hugo transformă fișierele markdown din GitHub într-un website rapid, sigur și optimizat SEO. Această arhitectură creează o separare clară a responsabilităților: LiveAgent se ocupă de suport, agentul AI de inteligență și decizii, GitHub de controlul versiunilor și colaborare, iar Hugo de prezentare. Frumusețea acestui sistem este că fiecare componentă poate fi menținută și actualizată independent, fără a perturba restul fluxului.
Cum ajută FlowHunt la automatizarea bazei de cunoștințe
FlowHunt oferă stratul de orchestrare care leagă toate aceste sisteme într-un flux unitar. În loc să fie nevoie de dezvoltare custom sau integrări complexe, FlowHunt îți permite să proiectezi vizual fluxul de automatizare, conectând LiveAgent, GitHub și Hugo printr-o interfață simplă și intuitivă. Platforma gestionează autentificarea, tratarea erorilor, logica de retry și toată complexitatea tehnică ce ar necesita altfel resurse de inginerie dedicate. Cu FlowHunt poți crea fluxuri sofisticate de automatizare fără să scrii cod, ceea ce face automatizarea bazei de cunoștințe accesibilă echipelor fără dezvoltatori dedicați. Platforma oferă și gestionare de memorie și context, permițând automatizării tale să învețe din execuțiile anterioare și să ia decizii inteligente despre când să creeze articole noi sau să le actualizeze pe cele existente. Integrarea FlowHunt cu GitHub permite crearea automată de pull request-uri, astfel încât echipa ta să poată revizui conținutul generat înainte de publicare. Acest pas “human-in-the-loop” asigură calitatea, păstrând totodată eficiența automatizării.
Fluxul complet: proces pas cu pas
Fluxul de generare automată a bazei de cunoștințe urmează o succesiune clară de pași, fiecare construind pe cel precedent pentru a crea un articol complet, gata de producție. Înțelegerea acestui proces este esențială pentru implementarea eficientă în organizație.
Pasul unu: Preluarea și validarea tichetului
Fluxul începe atunci când furnizezi un ID de tichet din sistemul LiveAgent. Agentul AI recuperează imediat conținutul complet al tichetului, inclusiv subiectul, corpul mesajului, toate etichetele și istoricul complet al conversației dintre client și echipa de suport. Această recuperare completă este esențială pentru ca AI-ul să aibă tot contextul necesar pentru a genera conținut relevant și corect. Agentul validează și că tichetul conține suficiente informații și este potrivit pentru publicare. De exemplu, dacă organizația ta primește multe cereri de programare demo, poți configura sistemul să le ignore automat, evitând a crea conținut irelevant pentru ceilalți utilizatori. Această filtrare previne aglomerarea bazei de cunoștințe cu conținut administrativ sau tranzacțional fără valoare pentru public.
Înainte de a genera conținut nou, sistemul verifică memoria pentru a determina dacă există deja un articol similar. Acest sistem de memorie este unul dintre cele mai importante elemente ale automatizării, prevenind crearea de articole duplicate sau foarte asemănătoare, care ar putea deruta utilizatorii și afecta negativ SEO. Agentul AI caută printre tichetele și articolele generate anterior pentru a identifica subiecte similare. Dacă găsește o potrivire, poate actualiza articolul existent cu informații noi sau poate sări peste creare, în funcție de configurare. Dacă nu există subiecte similare, agentul adaugă tichetul la memorie, creând o referință care va fi folosită la procesarea tichetelor viitoare. Această abordare orientată pe memorie face ca sistemul să devină tot mai inteligent pe măsură ce procesezi mai multe tichete, construind o hartă completă a bazei tale de cunoștințe și permițând decizii tot mai bune în timp.
Pasul trei: Analiza structurii bazei de cunoștințe
Sistemul examinează apoi depozitul tău existent de articole pentru a înțelege cum este structurat și formatat conținutul. Acest pas e esențial pentru consistență. Agentul AI analizează fișierele markdown existente, frontmatter-ul, structura titlurilor și tiparele de conținut pentru a învăța convențiile tale. Studiază modul de categorisire, ce metadate sunt incluse, cum sunt referențiate imaginile și ce elemente SEO există. Prin această analiză, sistemul învață stilul și structura ta specifică, asigurând că noile articole generate se integrează perfect cu cele existente și nu ies în evidență ca fiind automate.
Pasul patru: Managementul ramurilor GitHub
Pentru a păstra controlul versiunilor și a permite fluxuri de revizuire, sistemul creează sau folosește o ramură GitHub existentă pentru actualizările bazei de cunoștințe. În loc să creeze o ramură nouă pentru fiecare tichet, sistemul gestionează inteligent ramurile pentru a menține depozitul organizat. Dacă există deja o ramură pentru update-uri de bază de cunoștințe, sistemul o folosește și adaugă noul fișier acolo. Astfel, eviți proliferarea ramurilor, dar poți grupa mai multe update-uri într-un singur pull request pentru revizuire. Numele ramurii e de obicei descriptiv, precum “knowledge-base-updates” sau “kb-automation”, pentru a fi ușor de recunoscut de către echipă.
Pasul cinci: Generarea și formatarea conținutului
Cu tot contextul adunat, agentul AI generează articolul pentru baza de cunoștințe. Conținutul include o secțiune frontmatter formatată corect, cu metadate precum titlu, descriere, cuvinte cheie, etichete, categorii, dată și elemente call-to-action. Corpul articolului urmează o structură gândită atât pentru lizibilitatea utilizatorului, cât și pentru optimizare SEO. De obicei, conține un titlu principal, mai multe secțiuni H2 cu întrebări (ex: “Ce este?”, “De ce să facem asta?”, “Cum procedăm?”) și răspunsuri detaliate sub formă de paragrafe și bullet points. Această structură e optimizată pentru featured snippets și alte funcții Google care recompensează formatarea clară question-answer. Conținutul este redat în format markdown, standardul pentru Hugo și majoritatea site-urilor statice, asigurând compatibilitatea și ușurința editării.
Pasul șase: Crearea fișierului și commit
Sistemul creează un nou fișier markdown în folderul bazei de cunoștințe, cu un nume de fișier generat pe baza subiectului (de obicei în format slugificat, cu litere mici și cratime). Fișierul conține frontmatter-ul complet și corpul articolului generate anterior. După creare, sistemul face commit la modificări în ramura GitHub, cu un mesaj descriptiv care face referire la ID-ul tichetului original. Acest mesaj de commit creează o legătură permanentă între articol și solicitarea inițială, asigurând trasabilitate și context pentru referințe viitoare.
Pasul șapte: Crearea și revizuirea pull request-ului
La final, sistemul creează un pull request de pe ramura bazei de cunoștințe către ramura principală. Acest pull request include o descriere a modificărilor, ID-ul tichetului care a generat articolul și contextul relevant. Pull request-ul servește drept punct de control unde echipa ta poate revizui articolul generat, ajusta dacă e nevoie, verifica dacă respectă standardele de calitate și dacă se aliniază cu strategia bazei de cunoștințe. Acest pas uman e esențial—deși conținutul AI e în general de calitate, intervenția umană asigură acuratețea, consistența brandului și adecvarea. După aprobare, pull request-ul poate fi îmbinat în ramura principală, declanșând rebuild-ul Hugo și publicarea noului articol.
Implementare practică: identificarea și folosirea ID-urilor de tichete
Pentru a folosi acest flux de automatizare, ai nevoie să identifici corect ID-ul tichetului din LiveAgent. LiveAgent afișează ID-urile în două locuri. În primul rând, în interfață, vei vedea o etichetă “Tichet” cu ID-ul evidențiat—poți copia acest ID direct de acolo. În al doilea rând, și adesea mai comod, găsești ID-ul în URL-ul paginii tichetului. Când deschizi un tichet în LiveAgent, URL-ul va conține un parametru de forma “ID=12345” la sfârșit. Acesta este exact ID-ul pe care trebuie să-l introduci în fluxul FlowHunt. După ce ai ID-ul, îl introduci în workflow-ul FlowHunt și procesul pornește automat: sistemul preia tichetul, îl analizează, verifică duplicatele, generează articolul, creează ramura și pull request-ul în GitHub și notifică echipa ta pentru revizuire. Întregul proces se finalizează, de regulă, în câteva secunde sau minute, în funcție de complexitatea tichetului și de dimensiunea bazei de cunoștințe existente.
Accelerează-ți fluxul de lucru cu FlowHunt
Descoperă cum FlowHunt automatizează crearea bazei tale de cunoștințe din tichete: de la analiză și generare de conținut până la integrare GitHub și publicare Hugo — totul într-un singur flux.
După ce ai pus la punct fluxul de bază, există mai multe opțiuni avansate de configurare pentru a optimiza sistemul în funcție de nevoile tale. Poți seta sistemul să ignore anumite tipuri de tichete pe baza etichetelor, categoriilor sau a unor cuvinte cheie. De exemplu, poți sări peste toate tichetele etichetate “facturare” sau “cont” deoarece, de regulă, acestea nu reprezintă cunoștințe generalizabile. Poți seta și praguri pentru calitatea sau lungimea articolelor—dacă un tichet e prea scurt sau nu are destule detalii, sistemul îl poate omite și aștepta informații mai complete. Sistemul de memorie poate fi configurat să folosească diverși algoritmi de potrivire, de la matching simplu pe cuvinte cheie la analiză semantică avansată. Poți personaliza frontmatter-ul și structura conținutului pentru a se potrivi cerințelor tale, adăugând câmpuri personalizate sau modificând formatul articolului. Unele organizații adaugă metadate precum nivel de dificultate, public țintă sau articole conexe. Poți seta sistemul să adauge automat imagini generate cu AI sau extrase din biblioteca ta de asset-uri. Sistemul poate crea articole în mai multe limbi dacă ai utilizatori internaționali. De asemenea, poți configura notificări și aprobări—de exemplu, să fie necesară aprobarea unor membri ai echipei pentru anumite categorii de articole înainte de publicare.
Exemplu real: Eroare de integrare WordPress
Să luăm un exemplu practic din fluxul automatizat. Un client trimite un tichet de suport legat de o eroare de integrare WordPress. Tichetul conține mesaje de eroare, capturi de ecran și o descriere detaliată a pașilor parcurși. Echipa de suport răspunde cu pași de depanare și rezolvă problema. Acest tichet devine un candidat perfect pentru automatizare. Când ID-ul tichetului este introdus în flux, sistemul preia conversația completă, o analizează și verifică memoria. Dacă nu există deja un articol despre erori de integrare WordPress, sistemul adaugă subiectul în memorie și continuă generarea articolului. Sistemul analizează baza ta de cunoștințe și vede că ai un format specific pentru articole de depanare: secțiuni pentru simptome, cauze, soluții și prevenție. Articolul generat urmează acest format, creând un ghid complet despre erorile de integrare WordPress, ce va ajuta viitorii clienți să rezolve problema independent. Articolul este creat într-o ramură GitHub, se generează un pull request, echipa ta îl revizuiește, face ajustări dacă e nevoie și îl îmbină. În câteva minute, articolul e live pe site, indexat de motoarele de căutare și gata să ajute alți utilizatori. Data viitoare când cineva caută “eroare integrare WordPress” sau întâmpină această problemă, va găsi articolul tău și își va rezolva problema fără a contacta suportul.
Măsurarea succesului și ROI-ului
Pentru a justifica investiția în automatizarea bazei de cunoștințe, este important să măsori impactul. Indicatorii cheie includ reducerea volumului de tichete pentru întrebări deja acoperite de articole, creșterea traficului organic din motoarele de căutare, timpul economisit de echipa de suport și îmbunătățirea scorurilor de satisfacție a clienților. Poți urmări câți clienți accesează articolele înainte să contacteze suportul, câte tichete fac referire la articole și câți clienți declară că au găsit răspunsul necesar în baza de cunoștințe. Poți măsura și calitatea articolelor generate urmărind indicatori precum timpul petrecut pe pagină, adâncimea scroll-ului și bounce rate-ul. Articolele valoroase vor avea metrici de engagement mai ridicați. De asemenea, poți urmări numărul de articole generate, timpul economisit față de crearea manuală și economiile rezultate din reducerea volumului de suport. Majoritatea organizațiilor constată că automatizarea bazei de cunoștințe se amortizează în primele luni, prin reducerea costurilor cu suportul și creșterea satisfacției clienților.
Concluzie
Automatizarea creării de articole pentru baza de cunoștințe din tichete LiveAgent reprezintă o oportunitate majoră de a crește eficiența suportului, de a îmbunătăți SEO-ul website-ului tău și de a construi o resursă valoroasă pentru clienți, mult timp după interacțiunea inițială. Conectând LiveAgent, GitHub, Hugo și automatizarea AI prin FlowHunt, creezi un sistem care transformă solicitările brute ale clienților în articole de bază de cunoștințe, profesionale, automat. Fluxul este simplu—furnizezi un ID de tichet, iar sistemul se ocupă de generarea conținutului, integrarea cu GitHub și crearea de pull request. Sistemul de memorie previne crearea de conținut duplicat, iar revizuirea umană păstrează calitatea și coerența brandului. Pe măsură ce baza ta de cunoștințe crește, devine un activ tot mai valoros, reducând costurile de suport, crescând satisfacția clienților și aducând trafic organic pe site. Implementarea este accesibilă și echipelor fără expertiză tehnică profundă, făcând această automatizare puternică disponibilă pentru organizații de orice dimensiune.
Întrebări frecvente
Ce este un tichet LiveAgent?
Un tichet LiveAgent este o solicitare sau întrebare de suport clienți înregistrată în sistemul de tichete LiveAgent. Fiecare tichet conține un subiect, corpul mesajului, etichete și întregul istoric al conversației, care pot fi folosite pentru a genera conținut pentru baza de cunoștințe.
Cum îmi găsesc ID-ul tichetului în LiveAgent?
Poți găsi ID-ul tichetului în două moduri: (1) Caută eticheta 'Tichet' cu ID-ul afișat în interfața LiveAgent, sau (2) Verifică URL-ul la final, unde apare 'ID=your-ticket-id'. Copiază acest ID pentru a-l folosi în fluxul de automatizare.
Poate fluxul să ignore anumite tipuri de tichete?
Da, fluxul poate fi configurat să ignore anumite tipuri de tichete. De exemplu, poți seta să sară peste cererile de programare demo pentru a evita crearea de pagini duplicate pentru subiecte similare.
Ce se întâmplă dacă există deja un articol similar în baza de cunoștințe?
Fluxul folosește memoria pentru a verifica dacă un subiect similar a fost procesat anterior. Dacă găsește o potrivire, va actualiza articolul existent dacă este nevoie sau va sări peste creare pentru a evita duplicatele.
Cum se integrează fluxul cu GitHub?
Fluxul creează sau folosește o ramură GitHub existentă, generează un fișier markdown cu frontmatter corect, face commit la modificări și creează un pull request pentru revizuire înainte de a fi îmbinat în ramura principală.
Arshia este Inginer de Fluxuri AI la FlowHunt. Cu o pregătire în informatică și o pasiune pentru inteligența artificială, el este specializat în crearea de fluxuri eficiente care integrează instrumente AI în sarcinile de zi cu zi, sporind productivitatea și creativitatea.
Arshia Kahani
Inginer de Fluxuri AI
Automatizează crearea bazei tale de cunoștințe
Transformă tichetele de suport clienți în articole SEO optimizate pentru baza de cunoștințe automat, cu fluxurile inteligente AI de la FlowHunt.
Cum să automatizezi răspunsul la tichete în LiveAgent cu FlowHunt
Învață cum să integrezi fluxurile AI FlowHunt cu LiveAgent pentru a răspunde automat la tichetele clienților, folosind reguli inteligente de automatizare și int...
Implementează un chatbot inteligent pentru suport clienți în LiveAgent care răspunde automat întrebărilor vizitatorilor, recuperează documente din baza de cunoș...