AI-ul poate analiza cantități mari de date în câteva secunde, dar doar unele dintre date vor fi relevante sau potrivite pentru output. Componenta Document la Text îți oferă control asupra modului în care datele preluate sunt procesate și transformate în text.
Componenta Document la Text este concepută pentru a transforma documente de cunoștințe introduse într-un format de text simplu. Acest lucru este deosebit de util în fluxurile de lucru de AI și procesare a datelor unde este nevoie de date text pentru procesări ulterioare, analiză sau ca input pentru modele de limbaj.
Ce face componenta
Această componentă preia unul sau mai multe documente structurate (precum HTML, Markdown, PDF-uri sau alte formate suportate) și extrage conținutul textual. Poți specifica exact care părți din documente să fie exportate, dacă să incluzi sau nu metadate și cum să gestionezi secțiunile sau titlurile documentului. Output-ul este un obiect mesaj unificat ce conține textul extras, gata pentru sarcini precum sumarizare, clasificare sau răspuns la întrebări.
Inputuri
Componenta acceptă mai multe inputuri configurabile:
| Nume Input | Tip | Obligatoriu | Descriere | Valoare Implicită |
|---|---|---|---|---|
| Documente | Listă[Document] | Da | Documentele de cunoștințe ce trebuie transformate în text. | N/A (furnizat de utilizator) |
| De la H1 dacă există | Boolean | Da | Începe extragerea de la primul header H1, dacă este prezent. | true |
| Încarcă de la pointer | Boolean | Da | Începe extragerea de la pointerul care se potrivește cel mai bine cu query-ul sau încarcă tot dacă nu există potrivire. | true |
| Max Tokens | Integer | Nu | Numărul maxim de tokeni în textul de output. | 3000 |
| Omite ultimul header | Boolean | Da | Omite ultimul header (adesea un footer) pentru a optimiza output-ul. | false |
| Strategie | String | Da | Strategia de extragere a textului: concatenează documentele sau include părți egale din fiecare. | “Include dimensiune egală din fiecare document” |
| Exportă conținut | Multi-select | Nu | Ce tipuri de conținut să fie incluse (ex: H1, H2, Paragraf). | Toate tipurile selectate |
| Include Metadate | Multi-select | Nu | Câmpuri de metadate ce se pot include în output, dacă sunt disponibile. | Produs |
Tipuri de conținut disponibile: H1, H2, H3, H4, H5, H6, Paragraf
Opțiuni metadate: Autor, Produs, BreadcrumbList, VideoObject, BlogPosting, FAQPage, WebSite, opengraph
Outputuri
Componenta generează următorul output:
- Mesaj: Un obiect mesaj ce conține textul transformat și orice metadate incluse.
Funcționalități cheie & Utilitate
- Extragere flexibilă a conținutului: Poți controla exact ce părți din documente să fie extrase (ex: doar titlurile principale și paragrafele, sau tot conținutul).
- Incluziune metadate: Opțional poți include metadate bogate (ex: autor, produs sau date structurate) în output, util pentru contextualizare ulterioară.
- Gestionarea limitei de tokeni: Poți limita dimensiunea output-ului pentru a se încadra în cerințele modelului din aval, setând un număr maxim de tokeni.
- Strategie de extragere personalizată:
- Concatenează documentele, umple de la primul până la limita de tokeni: Prioritizează completarea secvențială a output-ului de la primul document.
- Include dimensiune egală din fiecare document: Echilibrează conținutul din mai multe documente în limita de tokeni.
- Gestionare inteligentă a secțiunilor: Opțiuni de a omite footerele documentului sau de a începe din secțiunea cea mai relevantă pentru query-ul tău, crescând relevanța textului extras.
Cazuri de utilizare tipice
- Preprocesarea bazelor de cunoștințe pentru modele AI (ex: înainte de embedding sau indexare).
- Sumarizarea sau condensarea documentelor mari prin extragerea doar a secțiunilor relevante.
- Furnizarea de conținut structurat către chatboți, motoare de căutare sau alte fluxuri de procesare a limbajului natural.
- Construirea de sisteme hibride de recuperare ce combină textul cu metadate pentru context mai bogat.
Tabel Rezumat
| Capacitate | Descriere |
|---|---|
| Tipuri de input | Listă de Documente |
| Tip output | Mesaj (Text + Metadate) |
| Granularitate conținut | Selectează titluri/paragrafe de inclus |
| Opțiuni metadate | Selectează multiple câmpuri de metadate pentru export |
| Control dimensiune output | Setează număr maxim de tokeni |
| Strategii de extragere | Concatenare sau echilibrare între documente |
| Selecție secțiune | Începe de la H1, de la pointer sau omite ultimul header |
Strategie
Botul poate parcurge multe documente pentru a crea output-ul text. Setarea Strategie îți oferă control asupra modului în care utilizează aceste documente inteligent, rămânând în limita de tokeni.
În prezent, există două strategii posibile:
- Include dimensiune egală din fiecare document: Utilizează în mod egal toate documentele găsite.
- Concatenează documentele, umple de la primul până la limita de tokeni: Leagă documentele în funcție de relevanța față de query.
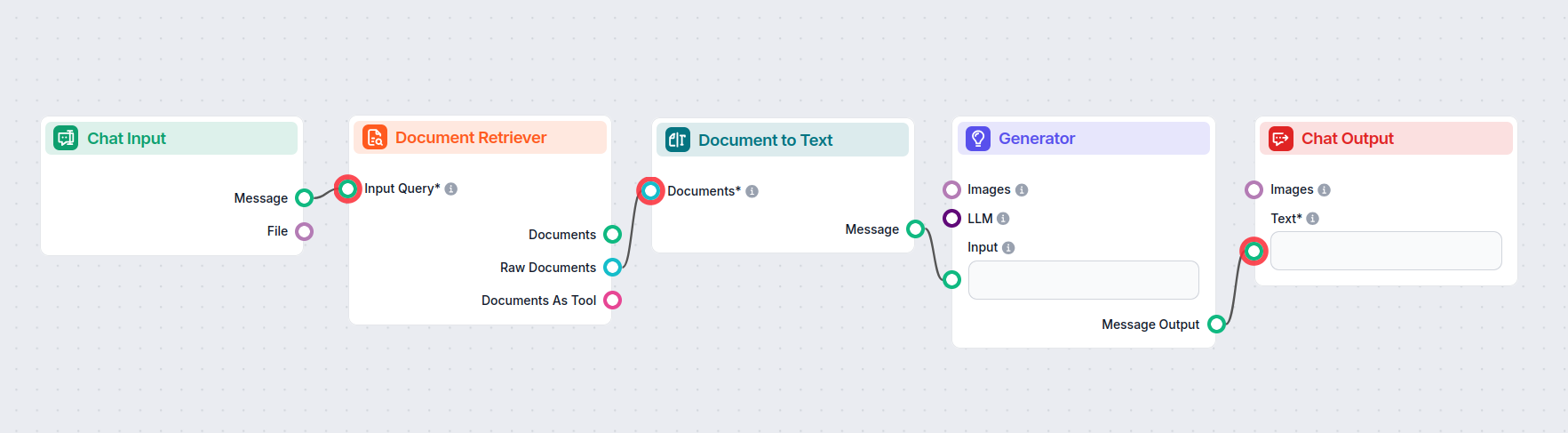
Cum conectezi componenta Document la Text în flow-ul tău
Aceasta este o componentă de tip transformator, ceea ce înseamnă că intermediază între două output-uri. Document la Text preia output-ul Documentelor generate de componentele Retriever:
- Document Retriever – preia cunoștințe din surse de cunoștințe conectate (pagini, documente etc.).
- URL Retriever – Îți permite să specifici o adresă URL de unde botul va prelua cunoștințe.
- GoogleSearch – Oferă botului abilitatea de a căuta pe web informații relevante.
Cunoștințele sunt convertite în text Markdown lizibil pe măsură ce trec prin transformator. Acest text poate fi apoi conectat la componente care necesită input text, precum splittere, widget-uri sau output-uri.
Iată un exemplu de flow ce folosește componenta Document la Text pentru a face legătura între Document Retrievers și AI Generator: