Cum să verifici autenticitatea unui chatbot AI
Află metode dovedite pentru a verifica autenticitatea chatbot-urilor AI în 2025. Descoperă tehnici tehnice de verificare, verificări de securitate și cele mai b...
12 min citire
Află metode complete de măsurare a acurateței chatbot-urilor AI pentru helpdesk în 2025. Descoperă precizia, recall-ul, scorurile F1, metrici de satisfacție a utilizatorului și tehnici avansate de evaluare cu FlowHunt.
Măsoară acuratețea chatbot-ului AI pentru helpdesk folosind mai multe metrici, inclusiv calcule de precizie și recall, matrici de confuzie, scoruri de satisfacție a utilizatorului, rate de rezolvare și metode avansate de evaluare bazate pe LLM. FlowHunt oferă instrumente complete pentru evaluarea automată a acurateței și monitorizarea performanței.
Măsurarea acurateței unui chatbot AI pentru helpdesk este esențială pentru a te asigura că acesta oferă răspunsuri fiabile și utile la solicitările clienților. Spre deosebire de sarcinile simple de clasificare, acuratețea chatbot-ului cuprinde mai multe dimensiuni care trebuie evaluate împreună pentru a oferi o imagine completă a performanței. Procesul implică analizarea modului în care chatbot-ul înțelege cererile utilizatorilor, furnizează informații corecte, rezolvă eficient problemele și menține satisfacția utilizatorului pe parcursul interacțiunilor. O strategie cuprinzătoare de măsurare a acurateței combină metrici cantitative cu feedback calitativ pentru a identifica punctele forte și zonele care necesită îmbunătățiri.
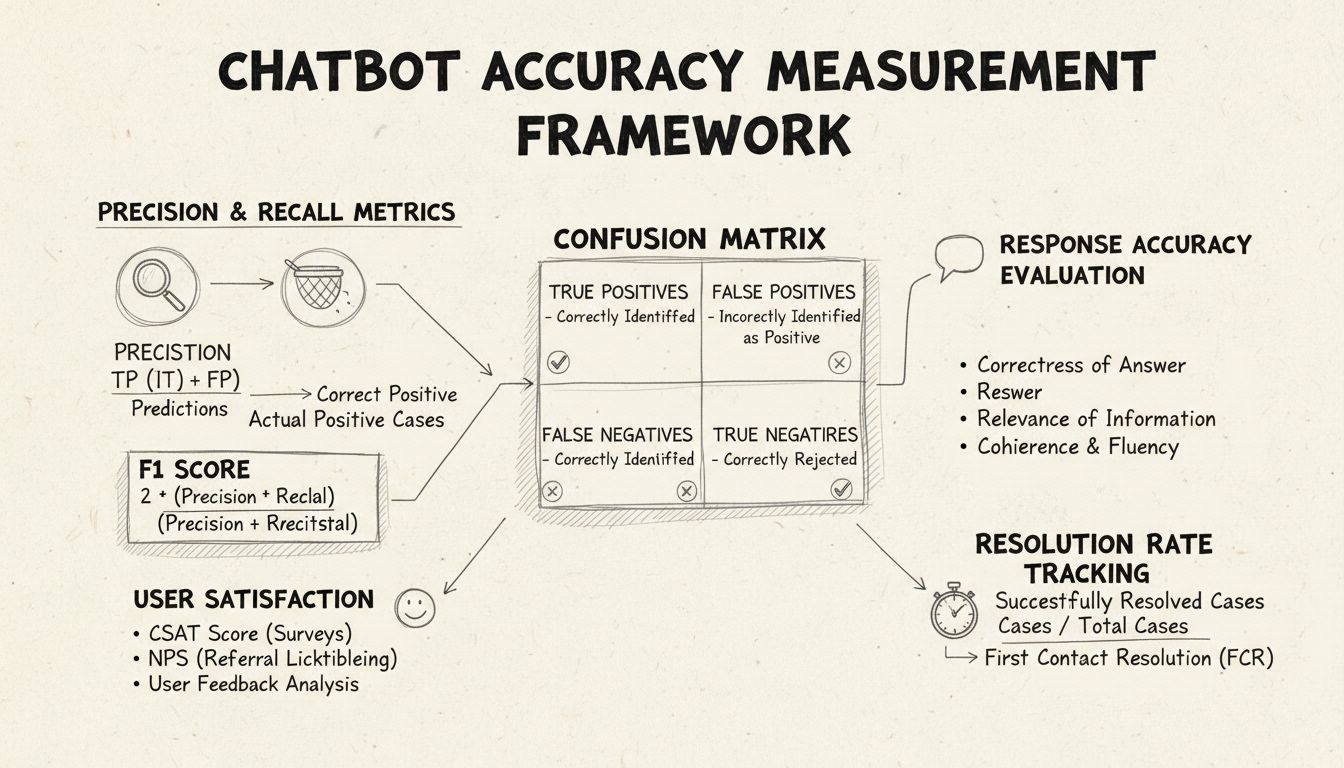
Precizia și recall-ul sunt metrici fundamentale derivate din matricea de confuzie care măsoară diferite aspecte ale performanței chatbot-ului. Precizia reprezintă proporția răspunsurilor corecte din totalul răspunsurilor oferite de chatbot, calculată folosind formula: Precizie = Pozitive Adevărate / (Pozitive Adevărate + Pozitive False). Această metrică răspunde la întrebarea: “Cât de des este corect răspunsul chatbot-ului atunci când oferă un răspuns?” Un scor ridicat de precizie indică faptul că chatbot-ul oferă rar informații incorecte, ceea ce este crucial pentru menținerea încrederii utilizatorilor în scenariile de helpdesk.
Recall-ul, cunoscut și ca sensibilitate, măsoară proporția răspunsurilor corecte din totalul răspunsurilor corecte pe care chatbot-ul ar fi trebuit să le furnizeze, folosind formula: Recall = Pozitive Adevărate / (Pozitive Adevărate + Negative False). Această metrică arată dacă chatbot-ul identifică și răspunde cu succes tuturor problemelor legitime ale clienților. În contextul helpdesk, un recall ridicat asigură că toți clienții primesc asistență pentru problemele lor, nu doar li se spune că chatbot-ul nu îi poate ajuta când, de fapt, ar putea. Relația dintre precizie și recall creează un compromis natural: optimizarea unei metrici o poate reduce pe cealaltă, necesitând echilibru atent în funcție de prioritățile afacerii.
Scorul F1 oferă o unică metrică ce echilibrează atât precizia, cât și recall-ul, fiind calculat ca media armonică: F1 = 2 × (Precizie × Recall) / (Precizie + Recall). Această metrică este deosebit de valoroasă atunci când ai nevoie de un indicator unificat al performanței sau când lucrezi cu seturi de date dezechilibrate, unde o clasă depășește semnificativ celelalte. De exemplu, dacă chatbot-ul tău gestionează 1.000 de solicitări de rutină, dar doar 50 de escaladări complexe, scorul F1 previne ca metrica să fie influențată doar de clasa majoritară. Scorul F1 variază între 0 și 1, unde 1 indică precizie și recall perfecte, făcându-l intuitiv pentru părțile interesate pentru a înțelege rapid performanța generală a chatbot-ului.
Matricea de confuzie este un instrument de bază care descompune performanța chatbot-ului în patru categorii: Pozitive Adevărate (răspunsuri corecte la întrebări valide), Negative Adevărate (refuzuri corecte la întrebări în afara domeniului), Pozitive False (răspunsuri incorecte) și Negative False (oportunități ratate de a ajuta). Această matrice scoate la iveală tipare specifice ale eșecurilor chatbot-ului, permițând îmbunătățiri țintite. De exemplu, dacă matricea arată multe negative false pentru întrebări legate de facturare, poți deduce că datele de antrenament ale chatbot-ului nu includ suficiente exemple din domeniul facturării și necesită îmbunătățiri în acea zonă.
| Metrică | Definiție | Calcul | Impact asupra afacerii |
|---|---|---|---|
| Pozitive Adevărate (TP) | Răspunsuri corecte la întrebări valide | Numărate direct | Construiește încrederea clienților |
| Negative Adevărate (TN) | Refuzuri corecte la întrebări în afara domeniului | Numărate direct | Previne dezinformarea |
| Pozitive False (FP) | Răspunsuri incorecte oferite | Numărate direct | Dăunează credibilității |
| Negative False (FN) | Oportunități ratate de a ajuta | Numărate direct | Reduce satisfacția |
| Precizie | Calitatea predicțiilor pozitive | TP / (TP + FP) | Măsură a fiabilității |
| Recall | Acoperirea pozitivelor reale | TP / (TP + FN) | Măsură a completitudinii |
| Acuratețe | Corectitudinea generală | (TP + TN) / Total | Performanță generală |
Acuratețea răspunsurilor măsoară cât de des chatbot-ul oferă informații factual corecte care răspund direct la întrebarea utilizatorului. Aceasta depășește simpla potrivire de tipar și evaluează dacă informația este corectă, actuală și potrivită pentru context. Procesele de revizuire manuală implică evaluatori umani care analizează un eșantion aleator de conversații, comparând răspunsurile chatbot-ului cu o bază prestabilită de răspunsuri corecte. Metodele automate de comparare pot fi implementate folosind tehnici de procesare a limbajului natural pentru a potrivi răspunsurile cu cele așteptate stocate în sistem, deși acestea necesită calibrare atentă pentru a evita negative false atunci când chatbot-ul oferă răspunsuri corecte folosind formulări diferite față de răspunsul de referință.
Relevanța răspunsului evaluează dacă răspunsul chatbot-ului chiar abordează ceea ce a întrebat utilizatorul, chiar dacă răspunsul nu este perfect corect. Această dimensiune surprinde situațiile în care chatbot-ul oferă informații utile care, deși nu sunt răspunsul exact, duc conversația spre rezolvare. Metodele bazate pe NLP, cum ar fi similaritatea cosinusului, pot măsura similaritatea semantică dintre întrebarea utilizatorului și răspunsul chatbot-ului, oferind un scor de relevanță automatizat. Mecanismele de feedback ale utilizatorului, precum aprecierile sau respingerile după fiecare interacțiune, oferă o evaluare directă a relevanței din partea celor care contează cel mai mult—clienții tăi. Aceste semnale de feedback trebuie colectate și analizate continuu pentru a identifica tiparele de întrebări la care chatbot-ul răspunde bine versus cele la care performează slab.
Scorul de Satisfacție al Clientului (CSAT) măsoară satisfacția utilizatorului în urma interacțiunii cu chatbot-ul prin sondaje directe, de obicei folosind o scală de la 1 la 5 sau evaluări simple de satisfacție. După fiecare interacțiune, utilizatorii sunt invitați să evalueze cât de satisfăcuți sunt, oferind feedback imediat asupra modului în care chatbot-ul le-a îndeplinit așteptările. Scorurile CSAT peste 80% indică, în general, o performanță bună, în timp ce scorurile sub 60% semnalează probleme semnificative ce necesită investigații. Avantajul CSAT este simplitatea și directitatea—utilizatorii declară explicit dacă sunt sau nu mulțumiți—însă poate fi influențat de factori dincolo de acuratețea chatbot-ului, precum complexitatea problemei sau așteptările utilizatorului.
Net Promoter Score evaluează probabilitatea ca utilizatorii să recomande chatbot-ul altora, calculat întrebând “Cât de probabil este să recomanzi acest chatbot unui coleg?” pe o scală de la 0 la 10. Răspunsurile de 9-10 sunt promotori, 7-8 pasivi, iar 0-6 detractori. NPS = (Promotori - Detractori) / Numărul Total de Răspunsuri × 100. Această metrică corelează puternic cu loialitatea pe termen lung a clienților și oferă indicii dacă chatbot-ul creează experiențe pozitive pe care utilizatorii vor să le împărtășească. Un NPS peste 50 este considerat excelent, iar unul negativ indică probleme serioase de performanță.
Analiza sentimentului examinează tonul emoțional al mesajelor utilizatorului înainte și după interacțiunea cu chatbot-ul pentru a evalua satisfacția. Tehnici NLP avansate clasifică mesajele ca fiind pozitive, neutre sau negative, dezvăluind dacă utilizatorii devin mai mulțumiți sau frustrați în timpul conversației. O schimbare pozitivă de sentiment indică faptul că chatbot-ul a rezolvat cu succes preocupările, în timp ce schimbările negative sugerează că chatbot-ul a eșuat să răspundă nevoilor sau a frustrat utilizatorii. Această metrică surprinde dimensiuni emoționale omise de metricile tradiționale de acuratețe, oferind context valoros pentru înțelegerea calității experienței utilizatorului.
Rezolvarea la primul contact măsoară procentul problemelor clienților rezolvate de chatbot fără a necesita escaladare către agenți umani. Această metrică influențează direct eficiența operațională și satisfacția clienților, deoarece aceștia preferă să-și rezolve problemele imediat, fără a fi transferați. Ratele FCR peste 70% indică performanță bună a chatbot-ului, în timp ce ratele sub 50% sugerează că chatbot-ul nu dispune de suficiente informații sau capacități pentru a gestiona solicitările comune. Monitorizarea FCR pe categorii de probleme arată ce tipuri de întrebări gestionează bine chatbot-ul și care necesită intervenție umană, ghidând îmbunătățirea bazei de cunoștințe și a procesului de antrenare.
Rata de escaladare măsoară cât de des chatbot-ul transferă conversațiile către agenți umani, în timp ce frecvența fallback-urilor monitorizează cât de des chatbot-ul recurge la răspunsuri generice precum „Nu înțeleg” sau „Te rog reformulează întrebarea”. Ratele ridicate de escaladare (peste 30%) indică faptul că chatbot-ul nu are cunoștințe sau încredere în multe scenarii, iar ratele mari de fallback sugerează recunoaștere slabă a intenției sau date de antrenament insuficiente. Aceste metrici identifică lacune specifice în capabilitățile chatbot-ului, ce pot fi adresate prin extinderea bazei de cunoștințe, reantrenarea modelului sau îmbunătățirea componentelor de procesare a limbajului natural.
Timpul de răspuns măsoară viteza cu care chatbot-ul răspunde mesajelor utilizatorilor, de obicei exprimat în milisecunde sau secunde. Utilizatorii se așteaptă la răspunsuri aproape instantanee; întârzierile peste 3-5 secunde afectează semnificativ satisfacția. Timpul de gestionare măsoară durata totală de la inițierea contactului de către utilizator până când problema este rezolvată sau escaladată, oferind informații despre eficiența chatbot-ului. Timpurile de gestionare mai scurte indică faptul că chatbot-ul înțelege rapid și rezolvă problemele, în timp ce duratele mai mari sugerează că chatbot-ul are nevoie de mai multe clarificări sau se confruntă cu întrebări complexe. Aceste metrici trebuie monitorizate separat pe categorii, deoarece problemele tehnice complexe necesită în mod natural timp de gestionare mai mare decât întrebările simple de tip FAQ.
LLM Ca Judecător reprezintă o abordare sofisticată de evaluare, unde un model lingvistic mare evaluează calitatea răspunsurilor generate de un alt sistem AI. Această metodă este eficientă în special pentru evaluarea răspunsurilor chatbot-ului pe mai multe dimensiuni de calitate simultan, cum ar fi acuratețea, relevanța, coerența, fluența, siguranța, completitudinea și tonul. Cercetările arată că judecătorii LLM ating până la 85% aliniere cu evaluările umane, ceea ce îi face o alternativă scalabilă la revizuirea manuală. Procesul implică definirea unor criterii specifice de evaluare, redactarea de prompturi detaliate pentru judecător cu exemple, furnizarea atât a întrebării originale a utilizatorului, cât și a răspunsului chatbot-ului, și obținerea de scoruri structurate sau feedback detaliat.
Procesul LLM Ca Judecător utilizează de obicei două abordări: evaluarea unui singur răspuns (unde judecătorul notează o ieșire individuală fie fără referință, fie comparativ cu un răspuns așteptat) și comparația pereche (unde judecătorul compară două răspunsuri pentru a identifica pe cel superior). Această flexibilitate permite evaluarea atât a performanței absolute, cât și a îmbunătățirilor relative atunci când testezi versiuni sau configurații diferite ale chatbot-ului. Platforma FlowHunt suportă implementări LLM Ca Judecător prin interfața sa vizuală drag-and-drop, integrarea cu modele de top precum ChatGPT și Claude, și toolkit-ul CLI pentru raportare avansată și evaluări automate.
Dincolo de calculele de bază ale acurateței, analiza detaliată a matricii de confuzie scoate la iveală tipare specifice ale eșecurilor chatbot-ului. Prin examinarea tipurilor de întrebări care generează pozitive false versus negative false, poți identifica slăbiciuni sistematice. De exemplu, dacă matricea arată că chatbot-ul clasifică frecvent eronat întrebările de facturare ca fiind probleme de suport tehnic, acest lucru dezvăluie un dezechilibru în datele de antrenament sau o problemă de recunoaștere a intenției specifică domeniului de facturare. Crearea de matrici de confuzie separate pentru diferite categorii permite îmbunătățiri direcționate, nu doar reantrenarea generală a modelului.
Testarea A/B compară diferite versiuni ale chatbot-ului pentru a determina care performează mai bine pe metricile cheie. Aceasta poate implica testarea diferitelor template-uri de răspuns, configurații ale bazei de cunoștințe sau modele lingvistice de bază. Prin rutarea aleatorie a unei părți din trafic către fiecare versiune și compararea metricilor precum rata FCR, scorurile CSAT și acuratețea răspunsurilor, poți lua decizii bazate pe date despre ce îmbunătățiri să implementezi. Testarea A/B ar trebui să se desfășoare pe o perioadă suficientă pentru a surprinde variația naturală a întrebărilor utilizatorilor și a asigura semnificația statistică a rezultatelor.
FlowHunt oferă o platformă integrată pentru crearea, implementarea și evaluarea chatbot-urilor AI pentru helpdesk cu capabilități avansate de măsurare a acurateței. Constructorul vizual al platformei permite utilizatorilor non-tehnici să creeze fluxuri sofisticate pentru chatbot, în timp ce componentele AI se integrează cu modele lingvistice de top precum ChatGPT și Claude. Toolkit-ul de evaluare FlowHunt suportă implementarea metodologiei LLM Ca Judecător, permițând definirea criteriilor personalizate de evaluare și evaluarea automată a performanței chatbot-ului pe întregul set de conversații.
Pentru a implementa o măsurare completă a acurateței cu FlowHunt, începe prin a-ți defini criteriile specifice de evaluare aliniate la obiectivele de business—fie că prioritizezi acuratețea, viteza, satisfacția utilizatorului sau ratele de rezolvare. Configurează LLM-ul judecător al platformei cu prompturi detaliate ce specifică cum să evalueze răspunsurile, inclusiv exemple concrete de răspunsuri bune și slabe. Încarcă setul tău de conversații sau conectează traficul live, apoi rulează evaluările pentru a genera rapoarte detaliate cu performanța pe toate metricile. Dashboard-ul FlowHunt oferă vizibilitate în timp real asupra performanței chatbot-ului, permițând identificarea rapidă a problemelor și validarea îmbunătățirilor.
Stabilește o măsurătoare de referință înainte de a implementa îmbunătățiri, pentru a crea un punct de comparație în evaluarea impactului schimbărilor. Colectează măsurători continuu, nu periodic, pentru a detecta din timp degradarea performanței cauzată de driftul datelor sau de învechirea modelului. Implementează bucle de feedback unde evaluările și corecțiile utilizatorilor sunt introduse automat în procesul de antrenare, îmbunătățind constant acuratețea chatbot-ului. Segmentează metricile pe categorii de probleme, tipuri de utilizatori și perioade de timp pentru a identifica zonele ce necesită atenție, nu te baza doar pe statistici agregate.
Asigură-te că setul de date pentru evaluare reprezintă întrebări reale ale utilizatorilor și răspunsuri așteptate, evitând cazurile artificiale care nu reflectă tiparele de utilizare reale. Validează regulat metricile automate cu evaluări umane, cerând evaluatorilor să analizeze manual un eșantion de conversații, pentru a te asigura că sistemul de măsurare rămâne calibrat la calitatea reală. Documentează clar metodologia de măsurare și definițiile metricilor, pentru a permite evaluare consistentă în timp și comunicare transparentă a rezultatelor către părțile interesate. În final, stabilește ținte de performanță pentru fiecare metrică, aliniate la obiectivele de business, pentru a crea responsabilitate în procesul de îmbunătățire continuă și a oferi obiective clare pentru eforturile de optimizare.
Platforma avansată de automatizare AI FlowHunt te ajută să creezi, implementezi și evaluezi chatbot-uri helpdesk performante cu instrumente integrate de măsurare a acurateței și capabilități de evaluare bazate pe LLM.
Află metode dovedite pentru a verifica autenticitatea chatbot-urilor AI în 2025. Descoperă tehnici tehnice de verificare, verificări de securitate și cele mai b...
Află strategii complete de testare a chatbot-urilor AI, inclusiv testare funcțională, de performanță, securitate și utilizabilitate. Descoperă cele mai bune pra...
Stăpânește utilizarea chatbotului AI cu ghidul nostru complet. Învață tehnici eficiente de promptare, bune practici și cum să obții cele mai bune rezultate de l...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.