Află cum să setezi parametrii ‘From H1 if exists’, ‘Load from pointer’ și ‘Skip Last Header’.
Document Retriever
AI knowledge base
Knowledge Sources
Components
Guide
Cum să configurezi Document Retriever:
Select section...
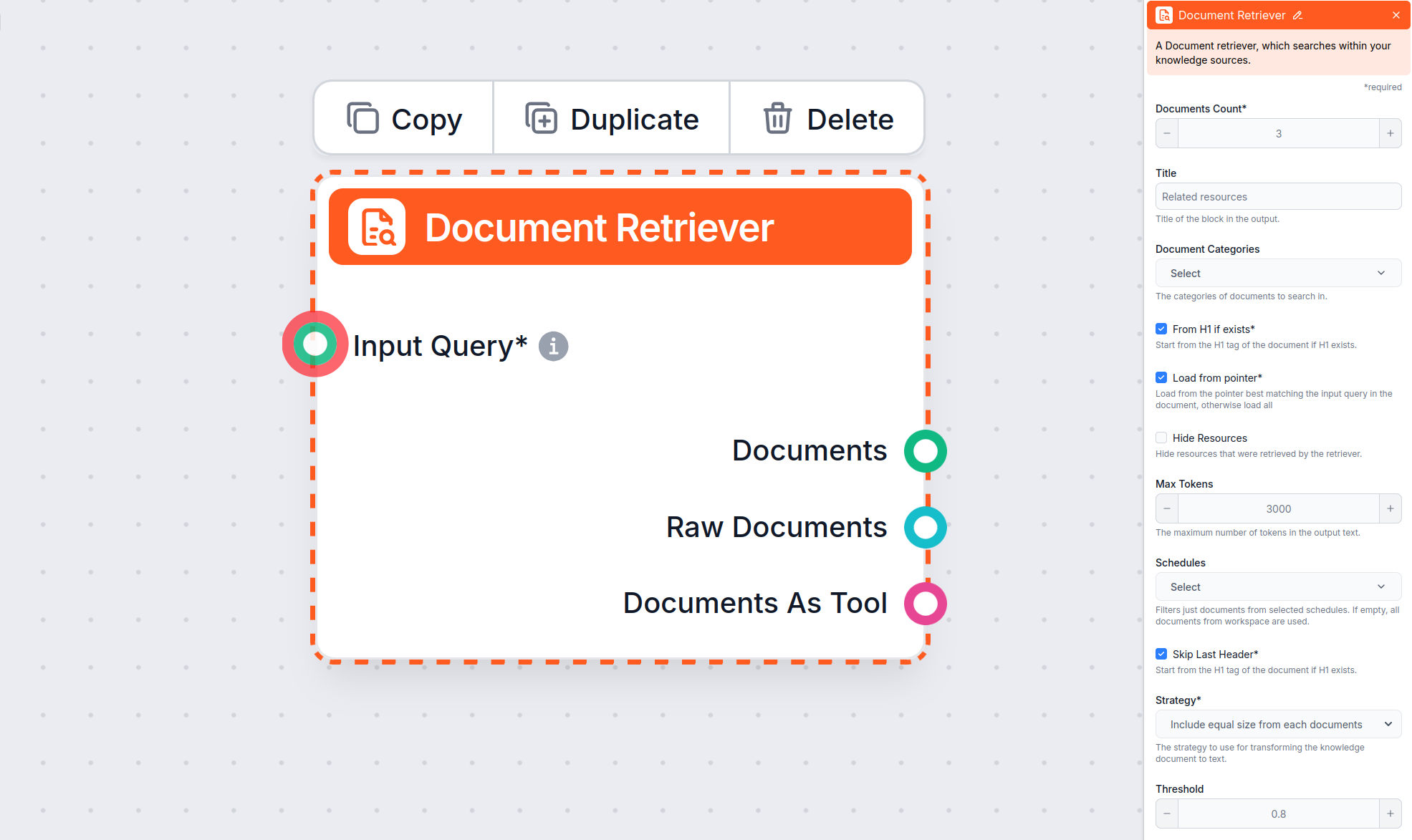
From H1 if exists – Începe extragerea de la titlul principal
Load from pointer – Extrage începând de la un marker specific
Skip Last Header – Exclude footer-ul sau anteturile redundante
Max tokens – Controlează lungimea maximă a rezultatului
Strategy – Controlează modul de transformare a mai multor documente în text
Alți parametri ai Document Retriever
Document Count
Document Categories
Hide Resources
Schedules
Threshold
Depanare
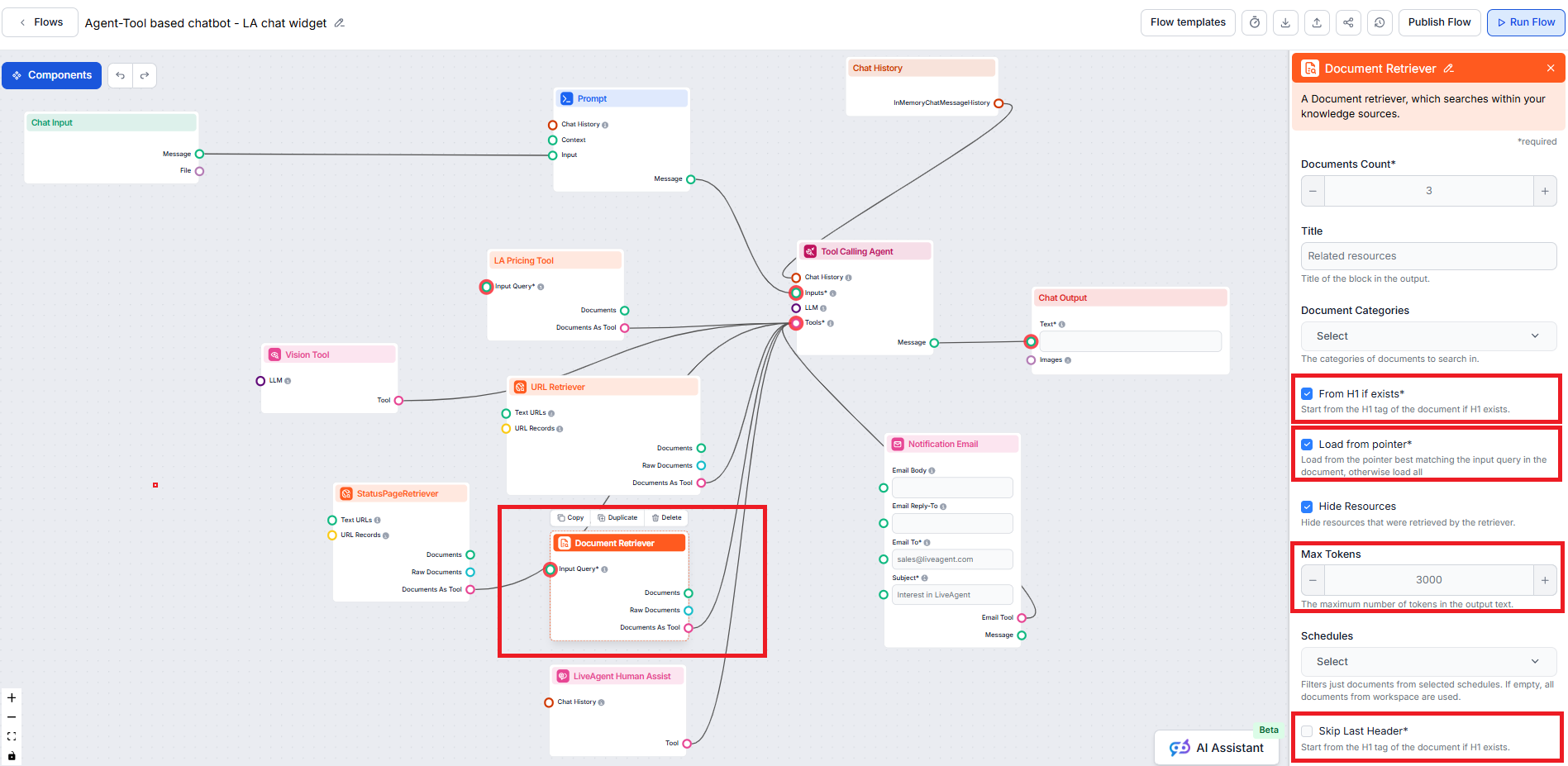
Componenta Document Retriever
permite chatbot-ului să recupereze cunoștințe din sursele pe care le-ai specificat în secțiunile Documents și Schedules. Rolul acestei componente este să controleze procesul de extragere, iar mai mulți parametri influențează modul în care aceasta recuperează informațiile din acele documente.
From H1 if exists – Începe extragerea de la titlul principal
Opțiunea From H1 if exists indică retriever-ului să înceapă extragerea conținutului de la primul antet H1 găsit (de obicei titlul principal al articolului).
Ce se întâmplă?
Dacă este bifată: Tot ce se află înainte de primul H1 (cum ar fi navigarea, breadcrumbs sau linkuri de autentificare) este ignorat. Extragerea începe la conținutul principal al articolului.
Dacă nu este bifată: Extragerea conținutului pornește de la începutul paginii, incluzând toată navigarea, anteturile și orice metadate de deasupra articolului principal.
Exemplu de utilizare: Vrei să recuperezi doar ghidul propriu-zis, fără navigarea site-ului sau anteturile de pagină care aglomerează website-ul tău.
Notă: From H1 if exists este activată în mod implicit în componenta Document Retriever.
Load from pointer – Extrage începând de la un marker specific
Opțiunea Load from pointer îți oferă mai multă precizie, permițând Document Retriever să încarce doar datele aflate după un pointer în cadrul unui articol posibil mai lung.
Ce se întâmplă?
Dacă este bifată (și este setat un pointer): Extragerea începe de la pointerul specificat, sărind peste tot ce se află înainte, chiar dacă este după H1.
Dacă nu este bifată: Extragerea începe din poziția implicită (vârful documentului sau de la primul H1, dacă această opțiune este bifată).
Ce este un “pointer”? Un pointer este, de obicei, un șir unic sau un antet prezent în document (de exemplu, un H2 sau o sintagmă/titlu de secțiune specific).
Exemplu de utilizare: Vrei să sari peste secțiunile introductive și să recuperezi informații pentru o anumită secțiune relevantă dintr-un articol sau document posibil lung (de exemplu, de la „Pasul 4: Adăugarea unui buton de chat live” într-un ghid de configurare).
Skip Last Header – Exclude footer-ul sau anteturile redundante
Opțiunea Skip Last Header este utilă pentru a ignora ultimul antet din document, care este adesea repetitiv sau folosit pentru navigare sau în subsol.
Ce se întâmplă?
Dacă este bifată: Ultimul antet (de exemplu, un titlu de articol repetat sau secțiunea „Alte articole”) este ignorat la extragere.
Dacă nu este bifată: Toate anteturile, inclusiv ultimul, sunt incluse în rezultat.
Exemplu de utilizare: Vrei să eviți ca Document Retriever să preia un antet de navigare din subsol (cum ar fi „Alte articole” de la finalul unei pagini de ajutor), asigurându-te că doar conținutul principal este procesat.
Notă: Skip Last Header poate ajuta cu documentele care generează automat subsoluri sau elemente de navigare repetitive. Totuși, dacă nu ai astfel de secțiuni, folosirea acestui parametru ar putea face ca o parte a articolului cu informații valide să nu fie recuperată. Prin urmare, este recomandat să lași această opțiune nebifată până când ai un motiv valid să o activezi.
Max tokens – Controlează lungimea maximă a rezultatului
Parametrul Max tokens îți permite să controlezi numărul maxim de tokeni (cuvinte și semne de punctuație, așa cum sunt numărate de modelul AI de bază) pe care Document Retriever îi va furniza din textul extras.
Ce se întâmplă?
Conținutul extras este limitat la numărul specificat de tokeni. Orice conținut suplimentar care depășește această limită va fi tăiat și exclus din rezultat.
Acest parametru ajută la gestionarea documentelor foarte lungi, asigurând că rezultatul rămâne în limitele de procesare ale modelelor AI.
Valoare implicită: Valoarea implicită este, de obicei, 3000 de tokeni, dar poți ajusta această valoare după necesitate.
Exemplu de utilizare: Dacă procesezi documente lungi, setarea unei valori mai mici pentru Max tokens ajută la menținerea răspunsurilor concise. Totuși, pentru cele mai bune rezultate, ia în calcul activarea parametrului „Load from pointer”. Astfel, textul extras va începe de la secțiunea cea mai relevantă a documentului, nu de la început, permițându-ți să obții un fragment de informație concentrat și gestionabil în limita de tokeni stabilită. Această combinație este deosebit de utilă când ai nevoie de rezultate concise și relevante contextual din surse ample.
Notă: Dacă observi că informațiile sunt tăiate, încearcă să crești valoarea Max tokens. Dimpotrivă, dacă vrei rezultate mai scurte și concentrate, redu parametrul Max tokens.
Strategy – Controlează modul de transformare a mai multor documente în text
Atunci când Document Retriever găsește mai multe documente relevante, parametrul Strategy determină modul în care acestea sunt combinate într-un singur rezultat text pentru chatbot-ul tău, ținând cont de limita „Max tokens”.
Două opțiuni de strategie:
Include equal size from each document: Limita de tokeni este împărțită în mod egal. De exemplu, cu trei documente și o limită de 3.000 tokeni, fiecare primește până la 1.000 tokeni. Acest lucru asigură că toate sursele contribuie în mod egal, util atunci când vrei un răspuns echilibrat care folosește informații din mai multe documente.
Folosește când: Ai documentație în care diferite aspecte ale unui subiect sunt împărțite pe mai multe documente, iar un răspuns complet necesită extragerea informațiilor din mai multe surse în mod echilibrat. Această abordare este eficientă când niciun document nu conține toate detaliile necesare și vrei să te asiguri că informațiile din fiecare sursă relevantă sunt prezente în răspuns, oferind astfel o perspectivă diversificată sau bine echilibrată.
Concat documents, fill from first up to the tokens limit: Documentele sunt adăugate în ordinea relevanței până când se atinge limita de tokeni. Cel mai relevant document ocupă primul spațiul; dacă mai rămâne spațiu, sunt adăugate și celelalte, în ordine. Dacă primul document este lung, poate folosi întreaga limită.
Folosește când: Ai documentație care conține informații detaliate despre fiecare subiect într-un singur document, iar pentru răspunsuri ar fi util să folosești cât mai mult din acest document, în loc să combini informații din mai multe documente similare.
Cum alegi?
Folosește Include equal size from each document dacă vrei reprezentare echilibrată din toate sursele.
Folosește Concat documents, fill from first up to tokens limit dacă vrei ca cel mai relevant document (sau cele mai relevante) să fie prioritizate și nu contează dacă nu sunt incluse toate sursele.
Notă: Aceste strategii afectează doar modul în care textul este construit din documentele extrase, înainte de a fi trimis către pasul următor (cum ar fi generarea AI). Ele nu schimbă ce documente sunt extrase—doar modul în care conținutul lor este îmbinat și tăiat pentru a se încadra în setarea Max tokens.
Alți parametri ai Document Retriever
Deși acest articol se concentrează pe configurarea parametrilor ‘From H1 if exists’, ‘Load from pointer’, ‘Skip Last Header’ și ‘Max tokens’, Document Retriever oferă și alți parametri care ajută la controlul modului în care documentele sunt selectate și extrase:
Document Count
Această setare limitează numărul de documente pe care fluxul le va extrage, asigurând rezultate relevante și generarea rapidă a răspunsurilor.
Document Categories
Această setare opțională îți permite să limitezi extragerea la una sau mai multe categorii pe care le-ai creat în secțiunea Documents din Knowledge Sources.
Hide Resources
Aceasta îți permite să incluzi sau să ascunzi o secțiune separată, înaintea răspunsului efectiv al chatbot-ului, cu o listă a resurselor extrase de retriever. Pentru integrarea cu LiveAgent, trebuie bifată, deoarece această secțiune nu este suportată și nu va fi afișată corect în widgetul chatbot LiveAgent.
Schedules
Îți permite să restricționezi extragerea la unul sau mai multe Schedules pe care le-ai specificat pentru crawl sau actualizarea conținutului în Knowledge Sources.
Threshold
Controlează cât de apropiate trebuie să fie documentele extrase de interogarea introdusă, folosind un scor de relevanță (de la 0 la 1). De exemplu, un prag de 0,7–0,8 este recomandat pentru răspunsuri foarte relevante. Pragurile mai mari oferă potriviri mai precise, în timp ce pragurile mai mici pot include documente mai puțin relevante.
Exemplu: Dacă setezi un prag de 0,6 și ai patru articole cu scoruri de relevanță de 0,8, 0,65, 0,5 și 0,9, doar cele peste 0,6 (adică 0,8, 0,65 și 0,9) vor fi folosite pentru extragere.
Depanare
Dacă răspunsul oferit de chatbot nu conține informații despre care ești sigur că sunt disponibile în documentele sau schedule-urile tale, încearcă să verifici istoricul conversației cu opțiunea “Verbose” pentru a vedea jurnalele detaliate despre dacă Document Retriever a fost folosit și ce documente au fost extrase. Dacă este necesar, ajustează setările și promptul pe baza acestor jurnale.
Cum să alimentezi un chatbot FlowHunt cu secțiuni selectate din documentația cPanel (nu cu întregul site)
Un ghid detaliat pentru importarea doar a unor secțiuni specifice din docs.cpanel.net în chatbotul tău FlowHunt, astfel încât acesta să devină expert pe subiect...
Chatbotul tău poate accesa și utiliza instant documente, pagini HTML și chiar videoclipuri YouTube pentru a-ți personaliza contextul unic. Perfect pentru a adău...
2 min citire
AI Chatbot
Knowledge Management
+3
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.