Contextové inžinierstvo: Konečný sprievodca návrhom AI systémov na rok 2025
Ponorte sa do hĺbky context engineeringu pre AI. Tento sprievodca pokrýva základné princípy od promtov až po pokročilé stratégie ako správa pamäte, context rot a multi-agentný návrh.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Krajina AI vývoja prešla zásadnou premenou. Zatiaľ čo sme sa kedysi sústredili na vytvorenie dokonalého promptu, dnes čelíme omnoho zložitejšej výzve: budovať celé informačné architektúry, ktoré obklopujú a posilňujú naše jazykové modely.
Tento posun znamená evolúciu od prompt engineeringu k context engineeringu—a predstavuje budúcnosť praktického vývoja AI. Systémy, ktoré dnes prinášajú skutočnú hodnotu, sa nespoliehajú na magické promptovanie. Úspech dosahujú preto, že ich architekti sa naučili orchestráciu komplexných informačných ekosystémov.
Andrej Karpathy túto evolúciu vystihol, keď popísal context engineering ako precízne napĺňanie kontextového okna presne tou správnou informáciou v tom správnom momente. Tento zdanlivo jednoduchý výrok odhaľuje zásadnú pravdu: LLM už nie je hlavnou hviezdou. Je to kľúčová súčasť starostlivo navrhnutého systému, kde každá informácia—každý fragment pamäte, popis nástroja či získaný dokument—je zámerne umiestnený pre maximálny výsledok.
Čo je context engineering?
Historická perspektíva
Korene context engineeringu siahajú hlbšie, než si mnohí uvedomujú. Zatiaľ čo hlavný diskurz o prompt engineeringu explodoval v rokoch 2022-2023, základné koncepty context engineeringu sa objavili už pred viac než dvoma desaťročiami v oblasti ubiquitous computingu a výskumu interakcie človeka s počítačom.
Už v roku 2001 Anind K. Dey stanovil definíciu, ktorá bola prekvapivo predvídavá: kontext zahŕňa akúkoľvek informáciu, ktorá pomáha charakterizovať situáciu entity. Tento raný rámec položil základy nášho uvažovania o strojovom porozumení prostredia.
Vývoj context engineeringu prebiehal v odlišných fázach, každá formovaná pokrokom v strojovej inteligencii:
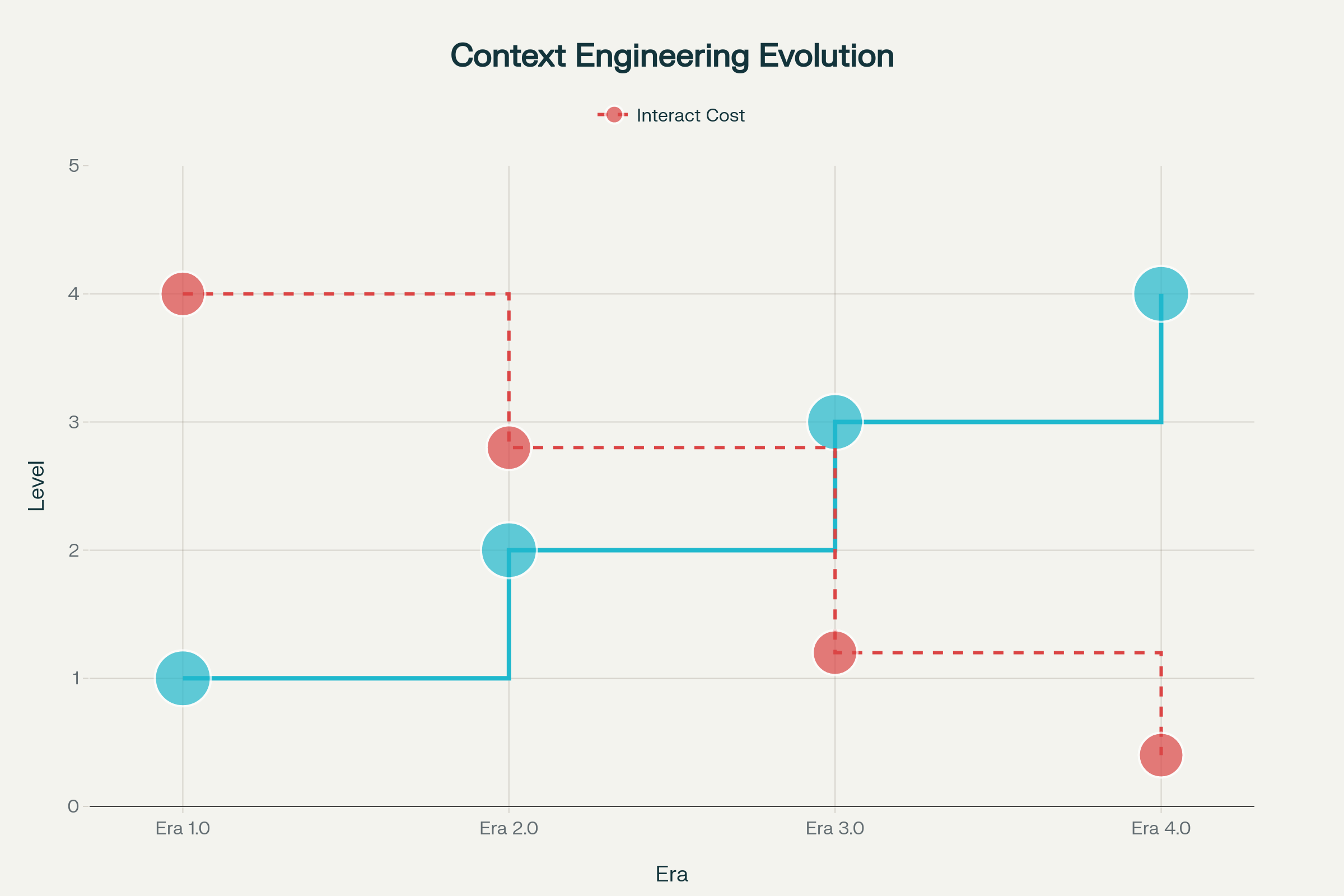
Éra 1.0: Primitívna výpočtová technika (1990s–2020) — Počas tohto obdobia stroje zvládali iba štruktúrované vstupy a základné environmentálne signály. Celé bremeno prekladu kontextu do strojovo spracovateľnej formy niesli ľudia. Typickými príkladmi sú desktopové aplikácie, mobilné aplikácie so senzormi či prvé chatboty s pevnými stromami odpovedí.
Éra 2.0: Agentovo-centristická inteligencia (2020–Súčasnosť) — Uvedenie GPT-3 v roku 2020 znamenalo paradigmatický posun. Veľké jazykové modely priniesli skutočné porozumenie prirodzenému jazyku a schopnosť pracovať s implicitnými zámermi. Táto éra umožnila autentickú spoluprácu človeka s agentom, kde sa nejednoznačnosť a neúplné informácie stávajú zvládnuteľnými cez pokročilé jazykové chápanie a učenie v kontexte.
Éra 3.0 & 4.0: Ľudská a nadľudská inteligencia (Budúcnosť) — Najbližšie vlny prinesú systémy, ktoré dokážu vnímať a spracovávať informácie s vysokou entropiou s ľudskou plynulosťou a nakoniec prejdú od reaktívnych odpovedí k proaktívnej konštrukcii kontextu a vyhľadávaniu potrieb, ktoré používateľ ešte ani nevyjadril.
Vývoj context engineeringu naprieč štyrmi érami: od primitívnej výpočtovej techniky po nadľudskú inteligenciu
Formálna definícia
V jadre context engineering predstavuje systematickú disciplínu navrhovania a optimalizácie toku kontextových informácií cez AI systémy—od počiatočného zberu, cez ukladanie, správu až po finálne využitie na zlepšenie strojového porozumenia a vykonanie úlohy.
Matematicky to môžeme vyjadriť ako transformačnú funkciu:
$CE: (C, T) \rightarrow f_{context}$
Kde:
C predstavuje surové kontextové informácie (entity a ich charakteristiky)
T označuje cieľovú úlohu alebo aplikačnú doménu
f_{context} je výsledná funkcia spracovania kontextu
V praxi to znamená štyri základné operácie:
Zber relevantných kontextových signálov cez rôzne senzory a informačné kanály
Ukladanie týchto informácií efektívne v lokálnych systémoch, sieťovej infraštruktúre a cloudoch
Správa zložitosti cez inteligentné spracovanie textu, multimodálnych vstupov a komplexných vzťahov
Využívanie kontextu strategicky pomocou filtrovania relevancie, zdieľania medzi systémami a adaptácie podľa používateľa
Prečo je context engineering dôležitý: rámec redukcie entropie
Context engineering rieši zásadnú asymetriu v komunikácii človek-stroj. Ľudia v konverzácii ľahko vypĺňajú medzery vďaka spoločnej kultúre, emocionálnej inteligencii a situačnému povedomiu. Stroje nič z toho nemajú.
Tento rozdiel sa prejavuje ako informačná entropia. Ľudská komunikácia je efektívna vďaka masívnemu spoločnému kontextu. Pre stroje musí byť všetko explicitne reprezentované. Context engineering je v podstate o predspracovaní kontextu pre stroje—komprimovaní vysoko entropickej komplexnosti ľudských zámerov na nízkoentropické reprezentácie, ktoré stroje zvládnu.
S pokrokom strojovej inteligencie sa táto redukcia entropie čoraz viac automatizuje. Dnes, v ére 2.0, ju musia inžinieri orchestrálne riadiť manuálne. V ére 3.0 a ďalej stroje postupne preberú väčšinu tejto záťaže. Základná výzva však zostáva: preklenúť priepasť medzi ľudskou komplexnosťou a strojovým porozumením.
Prompt engineering vs context engineering: kľúčové rozdiely
Častou chybou je zamieňanie týchto dvoch disciplín. V skutočnosti ide o zásadne odlišné prístupy k architektúre AI systémov.
Prompt engineering sa zameriava na tvorbu individuálnych inštrukcií alebo dotazov, ktoré formujú správanie modelu. Ide o optimalizáciu jazykovej štruktúry toho, čo modelu komunikujete—formulácie, príklady a vzorce uvažovania v rámci jednej interakcie.
Context engineering je komplexná systémová disciplína, ktorá spravuje všetko, s čím sa model stretne počas inferencie—vrátane promptov, ale aj získaných dokumentov, pamäťových systémov, popisov nástrojov, stavových informácií a ďalšieho.
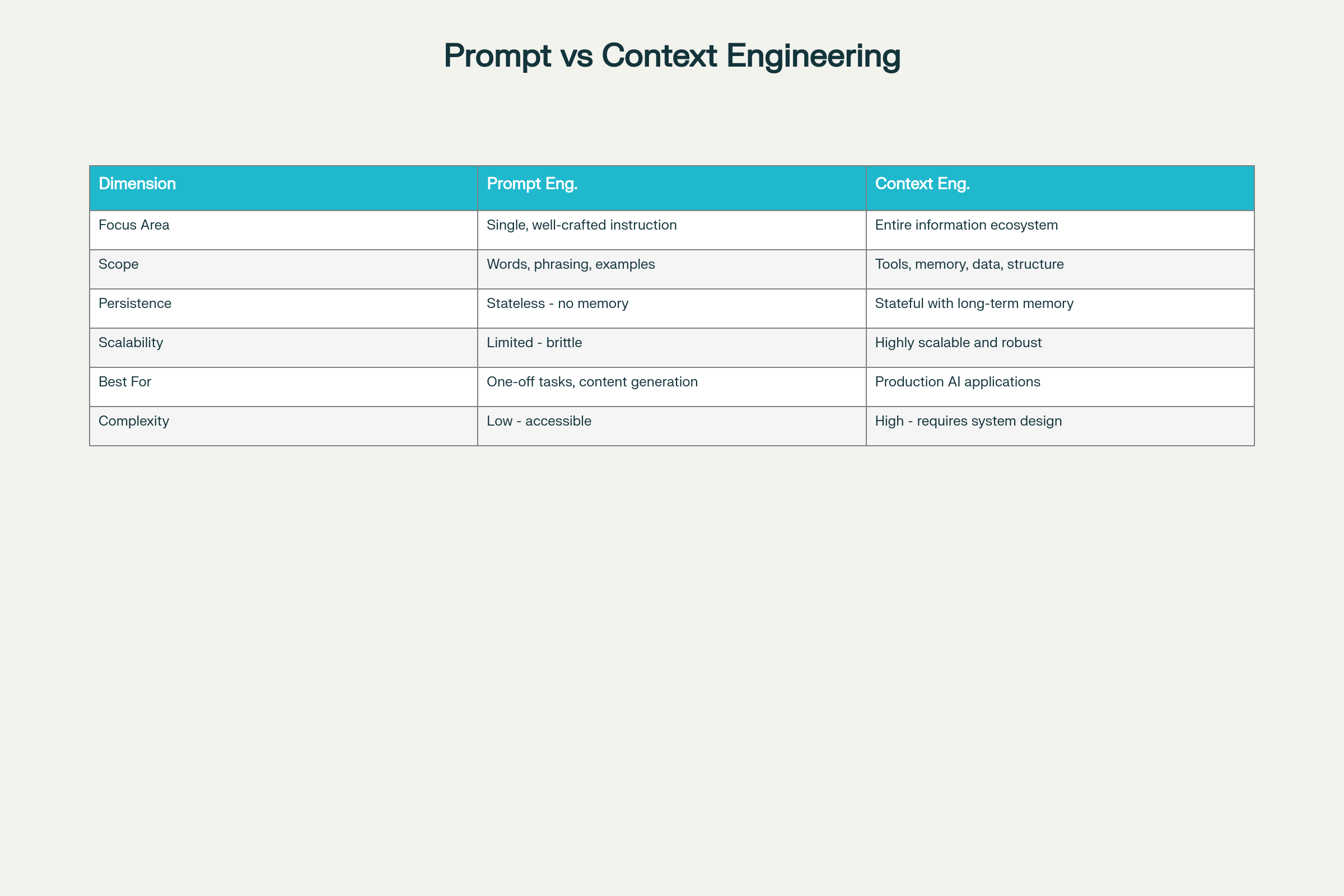
Prompt Engineering vs Context Engineering: Kľúčové rozdiely a kompromisy
Predstavte si tento rozdiel: Požiadanie ChatGPT, aby napísal profesionálny email, je prompt engineering. Vybudovanie platformy zákazníckeho servisu, ktorá uchováva históriu konverzácií cez viacero relácií, pristupuje k detailom účtu a pamätá si predchádzajúce tikety— to je context engineering.
Kľúčové rozdiely v ôsmich dimenziách:
Dimenzia
Prompt Engineering
Context Engineering
Oblasť zamerania
Optimalizácia individuálnej inštrukcie
Komplexný informačný ekosystém
Rozsah
Slová, formulácie, príklady
Nástroje, pamäť, dátová architektúra, štruktúra
Persistencia
Bezstavový—bez uchovávania pamäte
Stavový s dlhodobou pamäťou
Škálovateľnosť
Obmedzená a krehká pri škále
Vysoko škálovateľná a robustná
Najvhodnejšie pre
Jednorazové úlohy, generovanie obsahu
Produkčné AI aplikácie
Zložitosť
Nízka vstupná bariéra
Vysoká—vyžaduje systémový dizajn
Spoľahlivosť
Nepravidelná pri škále
Konzistentná a spoľahlivá
Údržba
Krehká pri zmenách požiadaviek
Modulárna a udržiavateľná
Kľúčový poznatok: Produkčné LLM aplikácie si vyžadujú najmä context engineering, nie len šikovné promptovanie. Ako poznamenali v Cognition AI, context engineering sa stal hlavnou zodpovednosťou inžinierov budujúcich AI agentov.
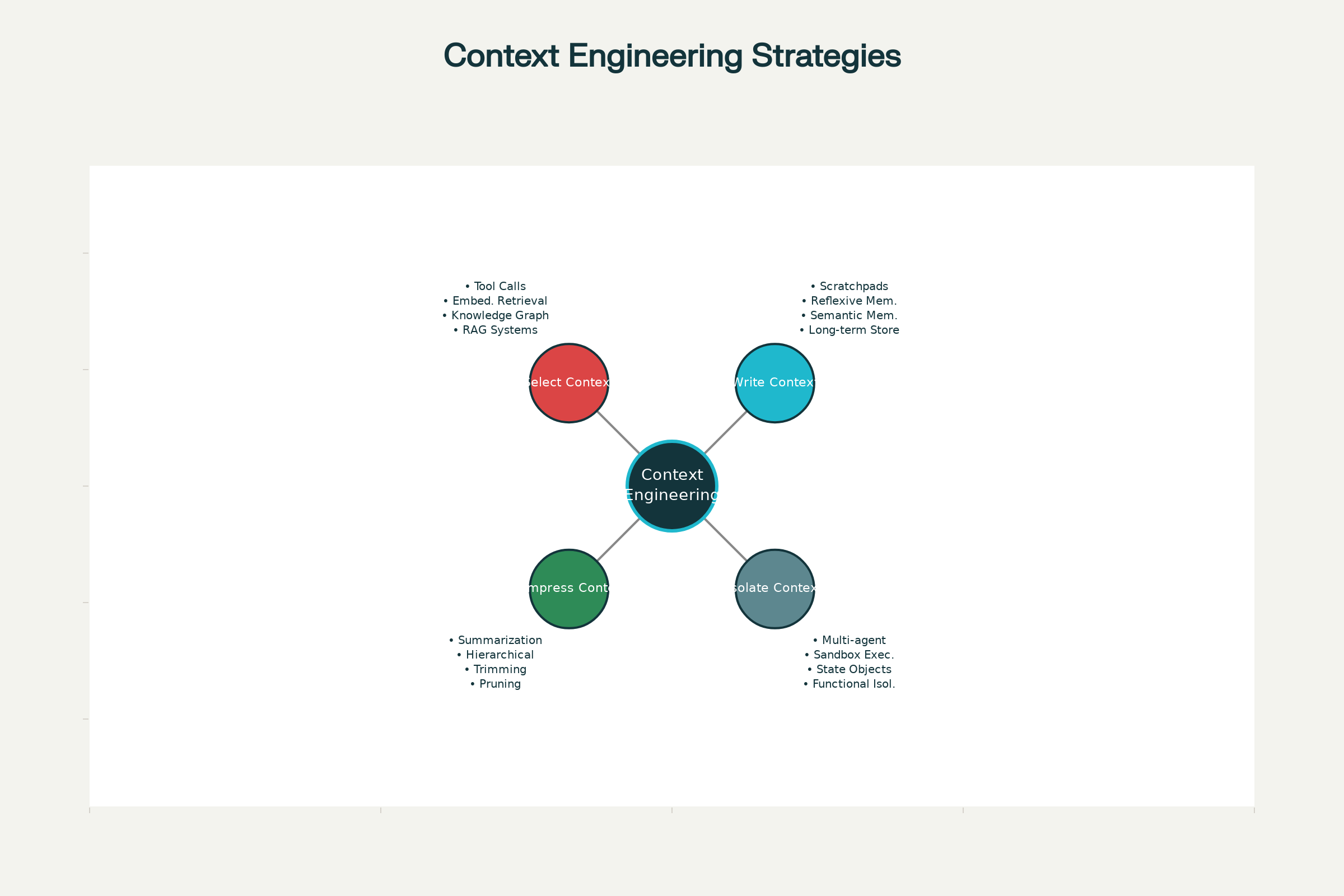
Štyri hlavné stratégie context engineeringu
Naprieč poprednými AI systémami—od Claude a ChatGPT po špecializovaných agentov v Anthropic a ďalších laboratóriách—sa vyprofilovali štyri základné stratégie pre efektívny manažment kontextu. Možno ich nasadzovať samostatne alebo kombinovať pre väčší efekt.
1. Písanie kontextu: Ukladanie informácií mimo kontextového okna
Základný princíp je elegantne jednoduchý: nenechávajte model pamätať si všetko. Uchovajte kľúčové informácie mimo kontextového okna, aby boli dostupné, keď ich treba.
Scratchpady sú najintuitívnejším príkladom. Rovnako ako si ľudia píšu poznámky pri riešení zložitých problémov, aj AI agenti využívajú scratchpady na zachovanie informácií pre budúce použitie. Implementácia môže byť jednoduchý nástroj na ukladanie poznámok alebo sofistikované polia v runtime objekte, ktorý pretrváva medzi krokmi.
Viacagentný výskumný agent Anthropic to demonštruje krásne: LeadResearcher najprv vypracuje plán a uloží ho do Pamäte na uchovanie, keďže pri prekročení 200 000 tokenov v kontexte dôjde k orezaniu a plán musí byť bezpečne zachovaný.
Pamäť rozširuje koncept scratchpadu cez viaceré relácie. Namiesto ukladania len v rámci jednej úlohy (session-scoped memory) môžu systémy budovať dlhodobé pamäte, ktoré pretrvávajú a vyvíjajú sa naprieč mnohými interakciami. Tento vzor je štandardom v produktoch ako ChatGPT, Claude Code, Cursor či Windsurf.
Výskumné projekty ako Reflexion zaviedli reflektívnu pamäť—agent reflektuje každé kolo a generuje pamäť pre budúce použitie. Generative Agents tento prístup rozširuje pravidelnou syntézou pamätí z kolekcie spätnej väzby.
Tri typy pamätí:
Epizodická: Konkrétne príklady minulých správaní alebo interakcií (cenné pre few-shot learning)
Procedurálna: Inštrukcie alebo pravidlá správania (zaisťujú konzistentnú prevádzku)
Sémantická: Fakty a vzťahy o svete (poskytujú ukotvené znalosti)
2. Výber kontextu: Vytiahnutie správnych informácií
Keď sú informácie uchované, agent musí získať len to, čo je relevantné pre aktuálnu úlohu. Zlý výber môže byť rovnako škodlivý ako žiadna pamäť—nerelevantné informácie môžu model popliesť alebo vyvolať halucinácie.
Mechanizmy výberu pamäte:
Jednoduchšie prístupy využívajú úzke, vždy zahrnuté súbory. Claude Code má súbor CLAUDE.md pre procedurálne pamäte, Cursor a Windsurf používajú súbory rules. Tento prístup však zlyháva pri stovkách faktov a vzťahov.
Pre väčšie kolekcie pamätí sa bežne nasadzuje embedding-based retrieval a znalostné grafy. Systém prevedie pamäte aj aktuálny dotaz do vektorových reprezentácií a vyberie najbližšie sémanticky podobné pamäte.
Ako však ukázal Simon Willison na AIEngineer World’s Fair, tento prístup môže zlyhať spektakulárne. ChatGPT nečakane vygeneroval jeho polohu z pamätí do obrázka, čo dokazuje, že aj sofistikované systémy môžu vyberať pamäte nevhodne. Preto je precízne inžinierstvo kľúčové.
Výber nástrojov je samostatnou výzvou. Ak má agent desiatky či stovky nástrojov, ich jednoduché vymenovanie spôsobí zmätok—prekrytie popisov vedie k nevhodnému výberu. Efektívne riešenie: aplikovať RAG princípy na popisy nástrojov. Vyhľadávaním len relevantných nástrojov dosahujú systémy trojnásobné zlepšenie presnosti výberu.
Získavanie znalostí je najbohatšou oblasťou. Kódoví agenti to ukazujú vo veľkom. Ako poznamenal inžinier Windsurf, indexovanie kódu neznamená efektívnu retrieval. Nasadzujú embedding search s AST parsingom a chunkovaním podľa významových hraníc. No embedding search sa stáva nespoľahlivým pri rastúcich kódbázach. Úspech vyžaduje kombináciu grep/file search, retrievalu cez znalostné grafy a re-ranking, kde je kontext zoradený podľa relevancie.
3. Kompresia kontextu: Zachovanie len podstatného
Pri dlhších úlohách kontext prirodzene narastá. Poznámky, výstupy nástrojov a história interakcií môžu rýchlo prekročiť kontextové okno. Kompresné stratégie tento problém riešia inteligentným zhutňovaním informácií pri zachovaní dôležitého.
Sumarizácia je hlavná technika. Claude Code používa “auto-compact”—pri zaplnení 95% okna sumarizuje celú trajektóriu interakcií. Môže ísť o stratégie:
Rekurzívna sumarizácia: tvorba súhrnov súhrnov pre kompaktné hierarchie
Hierarchická sumarizácia: sumarizácia na viacerých úrovniach abstrakcie
Cielená sumarizácia: zhutňovanie len vybraných častí (napr. obsiahlych výsledkov vyhľadávania), nie celého kontextu
Cognition AI používa jemne doladené modely na sumarizáciu na hraniciach medzi agentmi, čím znižuje spotrebu tokenov pri prenose znalostí—čo dokazuje hĺbku inžinierstva potrebnú v tomto kroku.
Orezávanie kontextu je doplnkový prístup. Namiesto inteligentnej sumarizácie LLM sa kontext orezáva pomocou heuristík—odstraňovanie starých správ, filtrovanie podľa dôležitosti alebo využitie trénovaných orezávačov ako Provence pre QA úlohy.
Kľúčová myšlienka: Čo odstránite, je často rovnako dôležité ako to, čo ponecháte. Sústredený 300-tokenový kontext často prekoná rozptýlený 113 000-tokenový v konverzačných úlohách.
4. Izolácia kontextu: Rozdelenie informácií medzi systémy
Nakoniec, izolačné stratégie uznávajú, že rôzne úlohy vyžadujú rôzne informácie. Namiesto vkladania všetkého do jedného okna, izolačné techniky rozdeľujú kontext medzi špecializované systémy.
Multi-agentné architektúry sú najčastejším prístupom. Knižnica OpenAI Swarm vznikla na “separácii úloh”—špecializované subagenty riešia konkrétne úlohy s vlastnými nástrojmi, inštrukciami a kontextovým oknom.
Výskum Anthropic ukazuje silu tohto prístupu: množstvo agentov s izolovanými kontextami prekonalo jednoagentné implementácie, pretože každé subagentove okno je úzko zamerané na svoju úlohu. Subagenti pracujú paralelne so svojimi oknami a skúmajú rôzne aspekty otázky.
No multi-agentné systémy prinášajú kompromisy. Anthropic zaznamenali až pätnásťnásobnú spotrebu tokenov oproti jednoagentnému chatu. Vyžaduje to starostlivú orchestráciu, promptovanie plánovania a sofistikované koordinačné mechanizmy.
Sandbox prostredia sú ďalšou izolačnou stratégiou. CodeAgent od HuggingFace to demonštruje: namiesto vrátenia JSONu, ktorý by musel model analyzovať, agent generuje kód, ktorý sa spustí v sandboxe. Vybrané výstupy sa vracajú LLM, pričom objemné objekty zostávajú izolované v runtime. Tento prístup vyniká pri vizuálnych a audio dátach.
Izolácia stavových objektov je možno najpodceňovanejšia technika. Runtime stav agenta môže byť navrhnutý ako štruktúrované schémy (napr. Pydantic model) s viacerými poľami. Jedno pole (napr. messages) je na každom kroku vystavené LLM, ostatné zostávajú izolované. To umožňuje jemne riadenú kontrolu bez komplikovanej architektúry.
Štyri hlavné stratégie efektívneho context engineeringu v AI agentoch
Problém context rot: kritická výzva
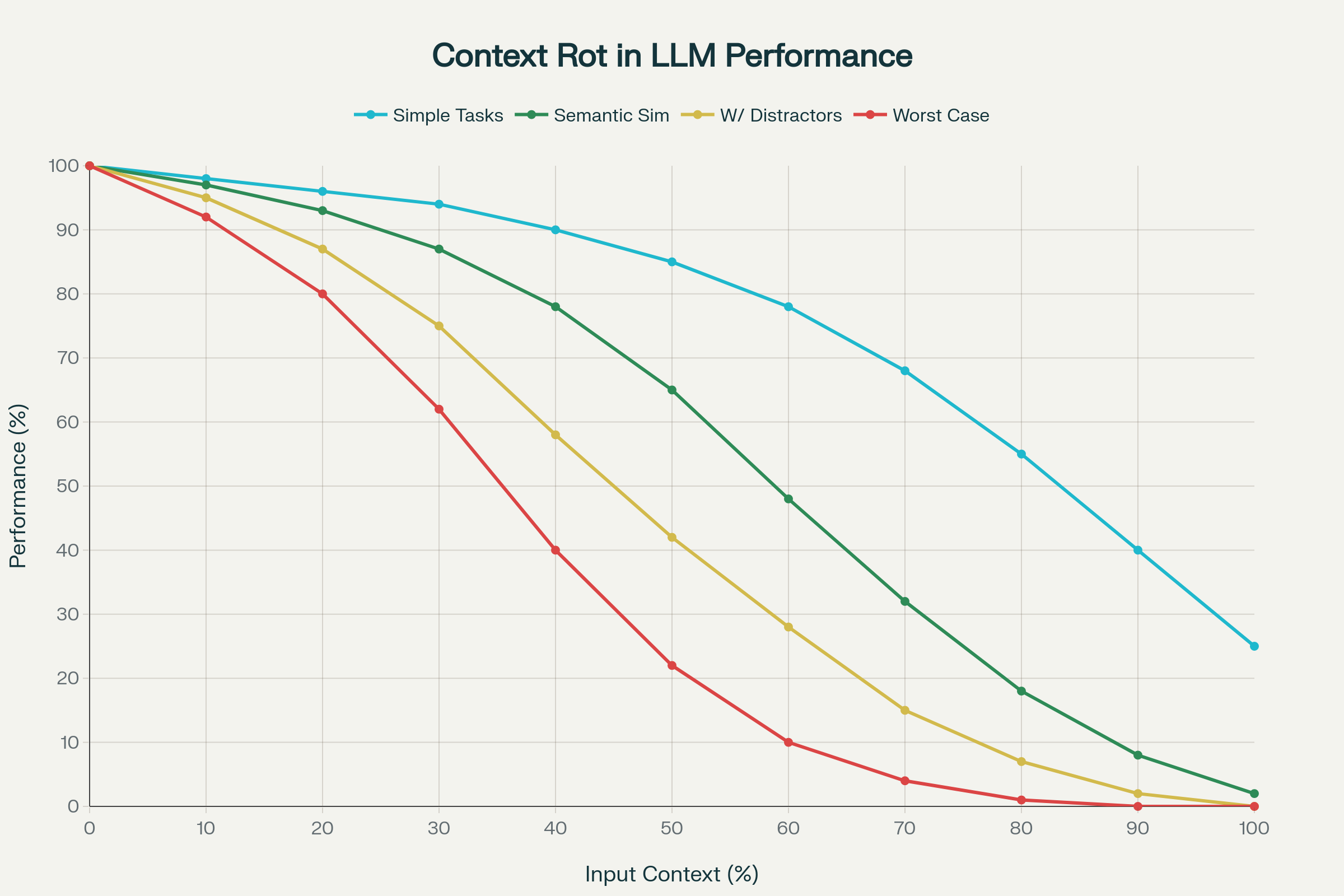
Napriek oslavovaným pokrokom v dĺžke kontextu nové výskumy ukazujú znepokojujúcu realitu: dlhší kontext automaticky neznamená lepší výkon.
Prelomová štúdia 18 popredných LLM—vrátane GPT-4.1, Claude 4, Gemini 2.5 a Qwen 3—odhalila jav zvaný context rot: nepredvídateľné a často závažné zhoršovanie výkonu so zvyšovaním vstupného kontextu.
Kľúčové zistenia o context rot
1. Nerovnomerná degradácia výkonu
Výkon neklesá lineárne a predvídateľne. Modely prejavujú prudké, idiosynkratické pády závislé od modelu a úlohy. Model môže držať 95% presnosť do určitej dĺžky, potom náhle klesnúť na 60%. Tieto zlomy sú nepredvídateľné pri rôznych modeloch.
2. Sémantická zložitosť zhoršuje context rot
Jednoduché úlohy (kopírovanie opakovaných slov, presné vyhľadávanie) ukazujú mierny pokles. Avšak ak “ihly v kope sena” vyžadujú sémantickú podobnosť, výkon prudko klesá. Pridanie podobných, no nesprávnych informácií (distraktorov) dramaticky znižuje presnosť.
3. Pozíciová zaujatost a kolaps pozornosti
Pozornosť transformera nerastie lineárne s dĺžkou kontextu. Tokeny na začiatku (primacy bias) a na konci (recency bias) dostávajú neúmernú pozornosť. V extrémnych prípadoch pozornosť kolabuje a model ignoruje veľké časti vstupu.
4. Modelovo špecifické vzory zlyhaní
Rôzne LLM vykazujú unikátne správanie pri škále:
GPT-4.1: inklinuje k halucináciám a opakovaniu nesprávnych tokenov
Gemini 2.5: vkladá nesúvisiace fragmenty alebo interpunkciu
Claude Opus 4: môže odmietnuť úlohu alebo byť príliš opatrný
5. Skutočný vplyv v konverzačných nastaveniach
Najviac znepokojujúce: v benchmarci LongMemEval modely s prístupom k celej konverzácii (~113k tokenov) dosiahli lepší výkon, keď dostali len sústredený 300-tokenový výsek. To dokazuje, že context rot degraduje retrieval aj uvažovanie v reálnych dialógoch.
Context Rot: Degradácia výkonu pri náraste dĺžky vstupných tokenov naprieč 18 LLM
Dôsledky: Kvalita pred kvantitou
Hlavný poznatok z výskumu context rot je jasný: počet vstupných tokenov nie je jediným určujúcim faktorom kvality. Rovnako dôležité je, ako je kontext zostavený, filtrovaný a prezentovaný.
Tento zistenie potvrdzuje význam context engineeringu. Namiesto dlhých kontextových okien ako univerzálneho riešenia chápu pokročilé tímy, že dôsledné context engineering—kompresiou, výberom a izoláciou—je nevyhnutné pre udržanie výkonu pri veľkých vstupoch.
Context engineering v praxi: reálne aplikácie
Prípadová štúdia 1: Multi-turn agentné systémy (Claude Code, Cursor)
Claude Code a Cursor predstavujú špičkové implementácie context engineeringu pre asistenciu pri kódovaní:
Zber: Systémy zbierajú kontext z viacerých zdrojov—otvorené súbory, štruktúra projektu, história zmien, terminálový výstup, komentáre používateľa.
Správa: Namiesto vkladania všetkých súborov do promptu inteligentne komprimujú. Claude Code používa hierarchické sumáre. Kontext je tagovaný podľa funkcie (napr. “aktuálne editovaný súbor”, “referencovaná závislosť”, “chybové hlásenie”).
Využitie: Pri každom kroku vyberie systém relevantné súbory a prvky kontextu, prezentuje ich v štruktúrovanej forme a udržiava samostatné stopy pre uvažovanie a viditeľný výstup.
Kompresia: Pri približovaní sa limitu kontextu spúšťa auto-compact, ktorý sumarizuje trajektóriu interakcií pri zachovaní kľúčových rozhodnutí.
Výsledok: Nástroje sú použiteľné aj vo veľkých projektoch (tisíce súborov) bez degradácie výkonu napriek obmedzeniam kontextového okna.
Prípadová štúdia 2: Tongyi DeepResearch (open-source agent pre hlboký výskum)
Tongyi DeepResearch ukazuje, ako context engineering umožňuje komplexné výskumné úlohy:
Pipeline syntézy dát: Namiesto obmedzených ručne anotovaných dát používa Tongyi sofistikovanú syntézu dát, kde sa PhD-úrovňové otázky generujú cez iteratívne vrstvenie komplexity. Každé kolo prehlbuje poznanie a tvorí komplexnejšie úlohy.
Správa kontextu: Systém používa paradigmu IterResearch—v každom kole rekonštruuje zjednodušený workspace len s esenciálnymi výstupmi z predchádzajúceho kola. Zabraňuje “kognitívnemu zaduseniu” akumulovaním všetkého do jedného okna.
Paralelný prieskum: Viacero výskumných agentov pracuje paralelne s izolovaným kontextom, každý skúma inú oblasť. Syntetizujúci agent integruje ich zistenia do komplexných odpovedí.
Výsledky: Tongyi DeepResearch dosahuje výkon porovnateľný s proprietárnymi systémami ako OpenAI DeepResearch, skóre 32.9 na Humanity’s Last Exam a 75 na užívateľských benchmarkoch.
Prípadová štúdia 3: Multi-agentný výskumný agent Anthropic
Výskum Anthropic demonštruje, ako izolácia a špecializácia zvyšuje výkon:
Architektúra: Špecializované subagenty riešia konkrétne úlohy (prehľad literatúry, syntéza, verifikácia) s oddelenými kontextovými oknami.
Výhody: Tento prístup prekonal jednoagentné systémy, každý subagent má kontext optimalizovaný pre svoju úlohu.
Kompromis: Pri vyššej kvalite narastá spotreba tokenov až pätnásobne v porovnaní s jednoagentným chatom.
To poukazuje na dôležitý poznatok: context engineering často znamená kompromisy medzi kvalitou, rýchlosťou a nákladmi. Správna rovnováha závisí od požiadaviek aplikácie.
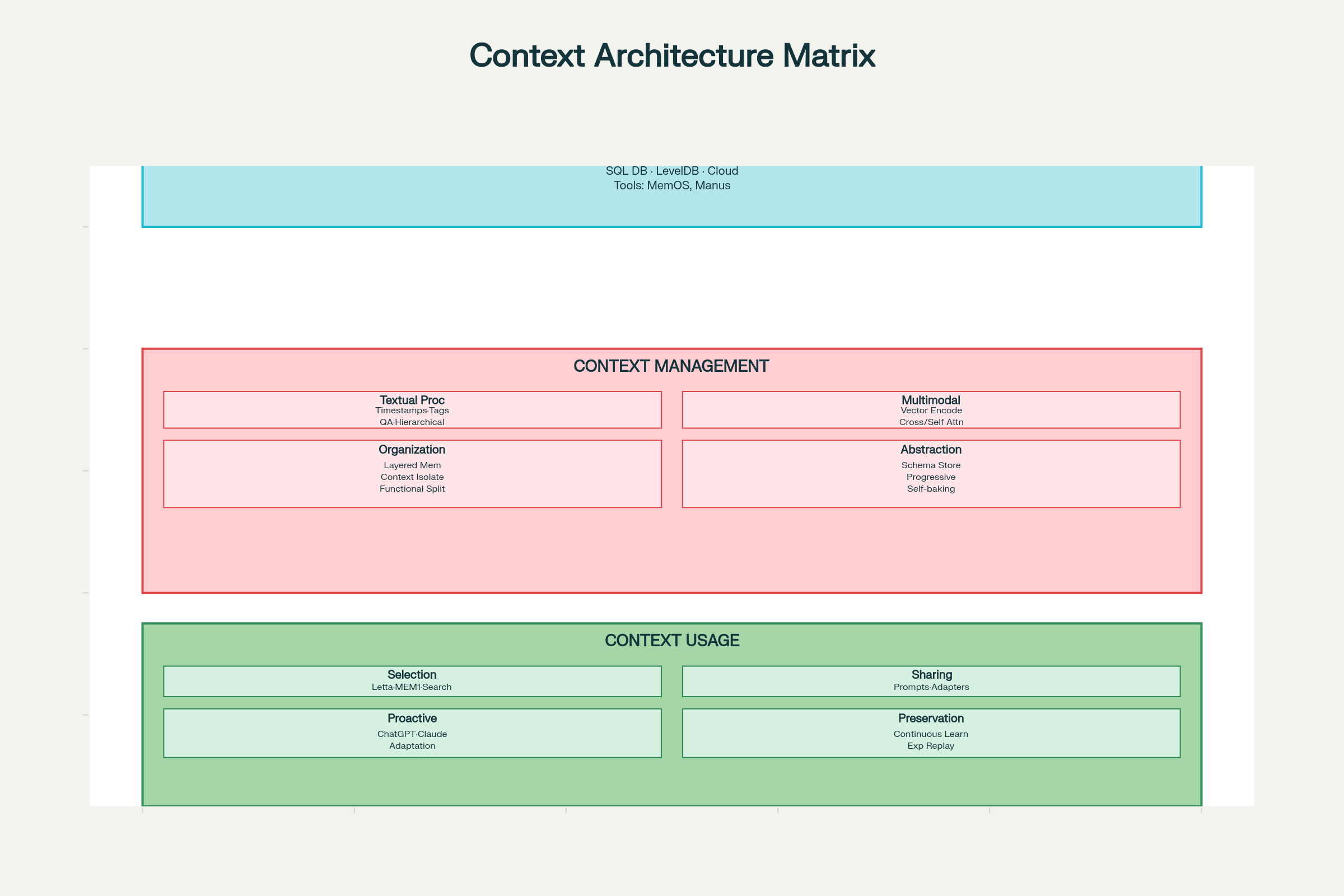
Rámec dizajnových rozhodnutí
Efektívny context engineering si vyžaduje systematické uvažovanie v troch dimenziách: zber a ukladanie, správa a využitie.
Dizajnové úvahy context engineeringu: kompletná architektúra a komponenty systému
Rozhodnutia o zbere a ukladaní
Voľba úložiska:
Lokálne úložisko (SQLite, LevelDB): Rýchle, s nízkou latenciou, vhodné pre klientskych agentov
Distribuované systémy: Pre masívnu škálu s redundanciou a odolnosťou
Vzorové návrhy:
MemOS: Operačný systém pamäte pre jednotnú správu pamätí
Manus: Štruktúrovaná pamäť s prístupom podľa rolí
Kľúčová zásada: Navrhujte na efektívny retrieval, nielen ukladanie. Ideálne úložisko je také, kde rýchlo nájdete, čo potrebujete.
Rozhodnutia o správe
Spracovanie textového kontextu:
Časové označenie: Jednoduché, ale obmedzené. Zachováva chronológiu, ale žiadnu sémantickú štruktúru, čo spôsobuje problémy pri rastúcom počte interakcií.
Tagovanie podľa funkcie/úlohy: Každý prvok označte funkciou—“cieľ”, “rozhodnutie”, “akcia”, “chyba” atď. Podporuje viacrozmerné tagovanie (priorita, zdroj, dôvera). Nové systémy ako LLM4Tag umožňujú škálovanie.
Kompresia do QA párov: Konvertujte interakcie do komprimovaných otázok a odpovedí, čím zachováte esenciu a šetríte tokeny.
Hierarchické poznámky: Postupné zhutňovanie do významových vektorov (H-MEM systémy), ktoré zachytávajú sémantickú podstatu na viacerých úrovniach.
Spracovanie multimodálneho kontextu:
Porovnateľné vektorové priestory: Zakódujte všetky modality (text, obrázok, audio) do porovnateľných vektorov pomocou spoločných embedding modelov (ako ChatGPT, Claude).
Cross-attention: Jedna modalita riadi pozornosť na inú (Qwen2-VL).
Nezávislé kódovanie a self-attention: Modalitu kódujte samostatne a kombinujte cez jednotnú pozornosť.
Organizácia kontextu:
Vrstvená architektúra pamäte: Oddelte pracovnú pamäť (aktuálny kontext), krátkodobú (nedávna história) a dlhodobú (trvalé fakty).
Funkčná izolácia kontextu: Subagenti s oddelenými oknami pre rôzne funkcie (prístup Claude).
Abstrakcia kontextu (self-baking):
“Self-baking” znamená schopnosť kontextu zlepšovať sa opakovaným spracovaním. Vzory
Najčastejšie kladené otázky
Prompt engineering sa zameriava na vytváranie jednotlivých inštrukcií pre LLM. Context engineering je širšia systémová disciplína, ktorá spravuje celé informačné ekosystémy pre AI model, vrátane pamäte, nástrojov a získaných dát, s cieľom optimalizovať výkon pri komplexných, stavových úlohách.
Context rot je nepredvídateľné zhoršovanie výkonu LLM, keď sa vstupný kontext predlžuje. Modely môžu prudko strácať presnosť, ignorovať časti kontextu alebo halucinovať, čo poukazuje na potrebu kvality a starostlivého manažmentu kontextu pred jeho kvantitou.
Štyri hlavné stratégie sú: 1. Písanie kontextu (ukladanie informácií mimo kontextového okna, napr. scratchpady alebo pamäť), 2. Výber kontextu (vyťahovanie iba relevantných informácií), 3. Kompresia kontextu (zhrnutie alebo orezanie na úsporu miesta) a 4. Izolácia kontextu (využitie multi-agentných systémov alebo sandboxov na oddelenie úloh).
Arshia je inžinierka AI workflowov v spoločnosti FlowHunt. S pozadím v informatike a vášňou pre umelú inteligenciu sa špecializuje na tvorbu efektívnych workflowov, ktoré integrujú AI nástroje do každodenných úloh, čím zvyšuje produktivitu a kreativitu.
Arshia Kahani
Inžinierka AI workflowov
Majster context engineeringu
Ste pripravení budovať novú generáciu AI systémov? Preskúmajte naše zdroje a nástroje na implementáciu pokročilého context engineeringu vo vašich projektoch.
Nech žije inžinierstvo kontextu: Budovanie produkčných AI systémov s modernými vektorovými databázami
Objavte, ako inžinierstvo kontextu mení vývoj AI, aký je posun od RAG k produkčne pripraveným systémom a prečo sú moderné vektorové databázy ako Chroma kľúčové ...
Prečo zvíťazilo posilňovacie učenie: Evolúcia dolaďovania AI modelov a príbeh OpenPipe
Objavte, ako sa posilňovacie učenie a dolaďovanie stali dominantným prístupom k optimalizácii AI modelov – od destilácie GPT-4 po nástup open-source modelov – n...
12 min čítania
AI
Machine Learning
+3
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.