Ako testovať AI chatbot
Získajte komplexné stratégie testovania AI chatbotov vrátane funkčných, výkonnostných, bezpečnostných a použiteľnostných testov. Objavte najlepšie postupy, nást...
11 min čítania
Naučte sa komplexné metódy merania presnosti AI helpdesk chatbota v roku 2025. Objavte metriku presnosti, recall, F1 skóre, spokojnosť používateľov a pokročilé techniky hodnotenia s FlowHunt.
Presnosť AI helpdesk chatbota merajte pomocou viacerých metrík vrátane výpočtu presnosti a recall, konfúznej matice, skóre spokojnosti používateľov, miery vyriešenia problémov a pokročilých metód hodnotenia pomocou LLM. FlowHunt poskytuje komplexné nástroje na automatizované hodnotenie presnosti a sledovanie výkonu.
Meranie presnosti AI helpdesk chatbota je nevyhnutné pre zabezpečenie spoľahlivých a užitočných odpovedí na zákaznícke otázky. Na rozdiel od jednoduchých klasifikačných úloh, presnosť chatbota zahŕňa viacero rozmerov, ktoré musia byť hodnotené spoločne, aby poskytli úplný obraz o výkone. Proces zahŕňa analýzu toho, ako dobre chatbot rozumie používateľským otázkam, poskytuje správne informácie, efektívne rieši problémy a udržiava spokojnosť používateľa počas interakcií. Komplexná stratégia merania presnosti kombinuje kvantitatívne metriky s kvalitatívnou spätnou väzbou na identifikáciu silných stránok a oblastí vyžadujúcich zlepšenie.
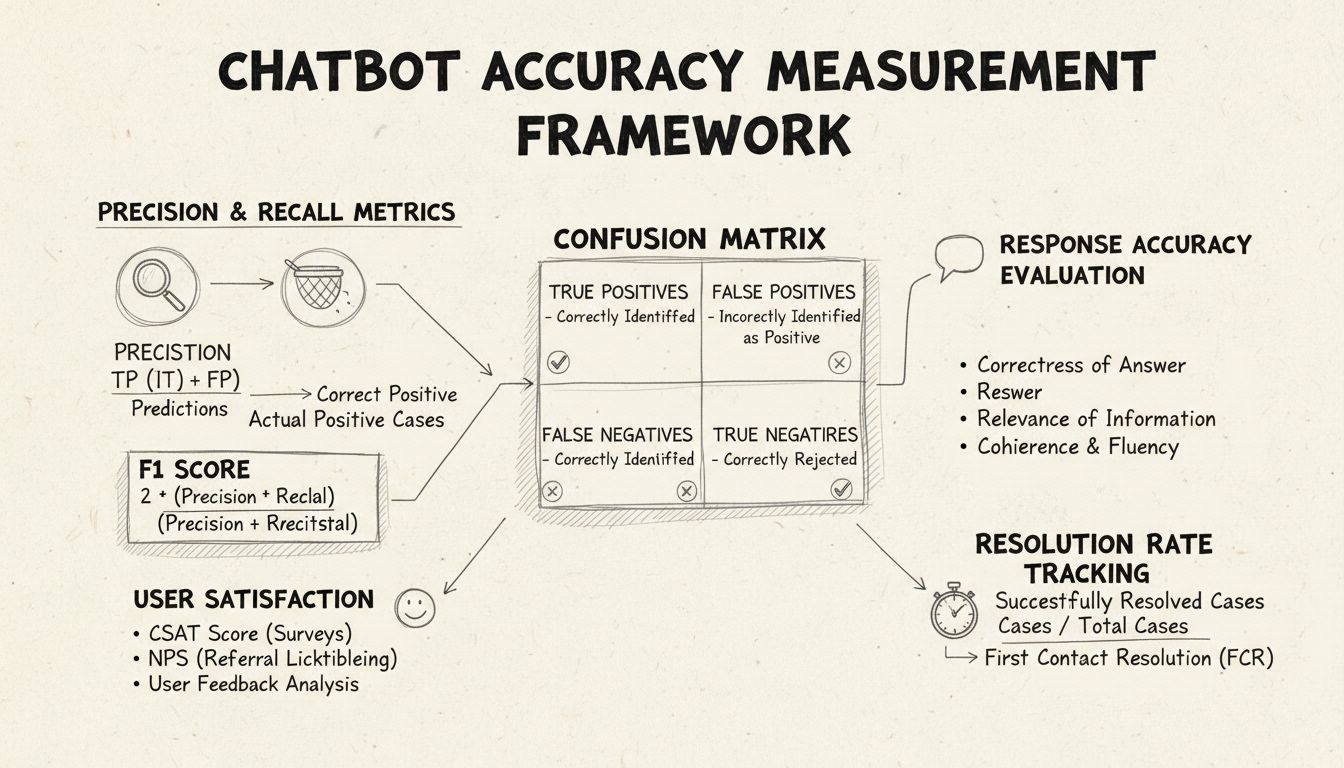
Presnosť a recall sú základné metriky odvodené z konfúznej matice, ktoré merajú rôzne aspekty výkonu chatbota. Presnosť predstavuje podiel správnych odpovedí zo všetkých odpovedí, ktoré chatbot poskytol, a vypočíta sa podľa vzorca: Presnosť = Pravé pozitíva / (Pravé pozitíva + Falošné pozitíva). Táto metrika odpovedá na otázku: „Keď chatbot poskytne odpoveď, ako často je správna?“ Vysoké skóre presnosti znamená, že chatbot zriedka poskytuje nesprávne informácie, čo je kľúčové pre udržanie dôvery používateľov v helpdesk situáciách.
Recall, známy aj ako citlivosť, meria podiel správnych odpovedí zo všetkých správnych odpovedí, ktoré mal chatbot poskytnúť, podľa vzorca: Recall = Pravé pozitíva / (Pravé pozitíva + Falošné negatíva). Táto metrika zisťuje, či chatbot úspešne identifikuje a reaguje na všetky legitímne zákaznícke problémy. V helpdesk kontexte vysoký recall zabezpečuje, že zákazníci dostanú pomoc pri svojich problémoch namiesto odpovede, že chatbot nevie pomôcť, keď v skutočnosti by vedel. Vzťah medzi presnosťou a recall vytvára prirodzený kompromis: optimalizácia jednej často znižuje druhú, preto je potrebné ich vyvážiť podľa konkrétnych obchodných priorít.
F1 skóre poskytuje jednu metriku, ktorá vyvažuje presnosť aj recall, vypočítanú ako harmonický priemer: F1 = 2 × (Presnosť × Recall) / (Presnosť + Recall). Táto metrika je obzvlášť užitočná, keď potrebujete jednotný ukazovateľ výkonu alebo keď pracujete s nevyváženými dátovými sadami, kde jedna trieda výrazne prevyšuje ostatné. Napríklad, ak váš chatbot rieši 1 000 rutinných otázok, ale len 50 zložitých eskalácií, F1 skóre zabraňuje tomu, aby bola metrika skreslená väčšinovou triedou. F1 skóre sa pohybuje od 0 do 1, pričom 1 znamená dokonalú presnosť a recall, takže je intuitívne na rýchle pochopenie celkového výkonu chatbota.
Konfúzna matica je základný nástroj, ktorý rozdeľuje výkon chatbota do štyroch kategórií: Pravé pozitíva (správne odpovede na platné otázky), Pravé negatíva (správne odmietnutie odpovede na otázky mimo rozsahu), Falošné pozitíva (nesprávne odpovede) a Falošné negatíva (zmeškané príležitosti pomôcť). Táto matica odhaľuje konkrétne vzory zlyhaní chatbota, čo umožňuje cielené zlepšenia. Napríklad, ak matica ukazuje vysoký počet falošných negatív pri otázkach k fakturácii, môžete identifikovať, že tréningové dáta chatbota neobsahujú dostatok príkladov z tejto oblasti a treba ich doplniť.
| Metrika | Definícia | Výpočet | Obchodný dopad |
|---|---|---|---|
| Pravé pozitíva (TP) | Správne odpovede na platné otázky | Počet priamo | Buduje dôveru zákazníka |
| Pravé negatíva (TN) | Správne odmietanie otázok mimo rozsahu | Počet priamo | Predchádza dezinformáciám |
| Falošné pozitíva (FP) | Nesprávne poskytnuté odpovede | Počet priamo | Poškodzuje dôveryhodnosť |
| Falošné negatíva (FN) | Zmeškané príležitosti pomôcť | Počet priamo | Znižuje spokojnosť |
| Presnosť | Kvalita pozitívnych predpovedí | TP / (TP + FP) | Metrika spoľahlivosti |
| Recall | Pokrytie skutočných pozitív | TP / (TP + FN) | Metrika úplnosti |
| Presnosť (Accuracy) | Celková správnosť | (TP + TN) / Celkom | Celkový výkon |
Presnosť odpovede meria, ako často chatbot poskytne fakticky správnu informáciu, ktorá priamo odpovedá na používateľovu otázku. Ide o viac než jednoduché párovanie vzorov – hodnotí sa, či je obsah správny, aktuálny a vhodný pre daný kontext. Manuálne hodnotenie zahŕňa kontrolu náhodnej vzorky konverzácií ľudskými hodnotiteľmi, ktorí porovnávajú odpovede chatbota s vopred definovanou databázou správnych odpovedí. Automatizované porovnávanie je možné implementovať pomocou techník spracovania prirodzeného jazyka (NLP) na porovnávanie odpovedí s očakávanými odpoveďami uloženými vo vašom systéme, pričom je potrebné dbať na správnu kalibráciu, aby sa predišlo falošným negatívam, keď chatbot poskytne správnu odpoveď inými slovami.
Relevantnosť odpovede hodnotí, či chatbotova odpoveď naozaj rieši to, na čo sa používateľ pýta – aj keď nie je dokonale správna. Tento rozmer zachytáva situácie, keď chatbot poskytne užitočné informácie, ktoré síce nie sú presne odpoveďou, ale posúvajú konverzáciu k vyriešeniu problému. NLP metódy ako kosínová podobnosť môžu merať sémantickú podobnosť medzi otázkou používateľa a odpoveďou chatbota, čo umožňuje automatizované skórovanie relevantnosti. Mechanizmy spätnej väzby od používateľov, ako napríklad hodnotenie palcom hore/dole po každej interakcii, poskytujú priamu relevantnú spätnú väzbu od najdôležitejších osôb – vašich zákazníkov. Tieto signály by sa mali priebežne zbierať a analyzovať na identifikovanie vzorov v tom, ktoré typy otázok chatbot zvláda dobre a ktoré nie.
Skóre spokojnosti zákazníka (CSAT) meria spokojnosť používateľov s interakciou s chatbotom prostredníctvom priamych prieskumov, zvyčajne na škále 1–5 alebo prostredníctvom jednoduchého hodnotenia spokojnosti. Po každej interakcii sú používatelia požiadaní, aby ohodnotili svoju spokojnosť, čím poskytujú okamžitú spätnú väzbu o tom, či chatbot splnil ich potreby. CSAT skóre nad 80 % zvyčajne znamená silný výkon, skóre pod 60 % signalizuje významné problémy vyžadujúce ďalšie vyšetrovanie. Výhodou CSAT je jeho jednoduchosť a priamosť – používatelia jasne povedia, či sú spokojní – výsledok však môžu ovplyvniť aj iné faktory, napríklad zložitosť problému alebo očakávania používateľa.
Net Promoter Score meria pravdepodobnosť, že používateľ odporučí chatbota iným, vypočítaná na základe otázky „Ako pravdepodobné je, že odporučíte tento chatbot kolegovi?“ na škále 0–10. Respondenti s hodnotením 9–10 sú promotéri, 7–8 sú pasívni, 0–6 sú kritici. NPS = (Promotéri – Kritici) / Celkový počet respondentov × 100. Táto metrika úzko súvisí s dlhodobou lojalitou zákazníkov a poskytuje prehľad o tom, či chatbot vytvára pozitívne skúsenosti, ktoré chcú používatelia zdieľať. NPS nad 50 sa považuje za vynikajúce, záporné NPS signalizuje vážne problémy s výkonom.
Analýza sentimentu skúma emocionálny tón správ používateľov pred a po interakcii s chatbotom na zistenie spokojnosti. Pokročilé NLP techniky klasifikujú správy ako pozitívne, neutrálne alebo negatívne, a odhaľujú, či sú používatelia počas konverzácie spokojnejší alebo frustrovanejší. Pozitívny posun v sentimente znamená, že chatbot úspešne vyriešil obavy, kým negatívny posun naznačuje, že používateľa skôr frustroval alebo mu nepomohol. Táto metrika zachytáva emocionálne aspekty, ktoré tradičné metriky presnosti prehliadajú, a poskytuje cenný kontext na pochopenie kvality používateľskej skúsenosti.
Miera vyriešenia na prvý kontakt meria percento zákazníckych problémov vyriešených chatbotom bez potreby eskalácie na ľudského agenta. Táto metrika priamo ovplyvňuje efektivitu prevádzky aj spokojnosť zákazníka, keďže zákazníci uprednostňujú okamžité vyriešenie problémov pred odovzdaním. FCR nad 70 % znamená výborný výkon chatbota, pod 50 % naznačuje nedostatočné znalosti alebo schopnosti riešiť bežné otázky. Sledovanie FCR podľa kategórie problému odhalí, ktoré typy problémov chatbot zvláda dobre a ktoré vyžadujú zásah človeka, čo pomáha pri zlepšovaní tréningu a znalostnej bázy.
Miera eskalácie meria, ako často chatbot odovzdá konverzáciu ľudskému agentovi, zatiaľ čo frekvencia fallbacku sleduje, ako často chatbot použije generické odpovede ako „Nerozumiem“ alebo „Prosím, preformulujte otázku“. Vysoké miery eskalácie (nad 30 %) naznačujú nedostatok znalostí alebo istoty v mnohých situáciách, vysoké miery fallbacku signalizujú slabé rozpoznávanie zámeru alebo nedostatočné tréningové dáta. Tieto metriky identifikujú konkrétne medzery vo vedomostiach chatbota, ktoré sa dajú riešiť rozšírením znalostnej bázy, pretrénovaním modelu alebo vylepšením komponentov na rozpoznávanie prirodzeného jazyka.
Čas odpovede meria, ako rýchlo chatbot reaguje na používateľské správy, zvyčajne v milisekundách až sekundách. Používatelia očakávajú takmer okamžité odpovede; meškania nad 3–5 sekúnd výrazne znižujú spokojnosť. Čas vybavenia meria celkové trvanie od začiatku kontaktu používateľa po vyriešenie problému alebo eskaláciu, čo poskytuje pohľad na efektivitu chatbota. Kratšie časy vybavenia znamenajú, že chatbot rýchlo pochopí a vyrieši problém, dlhšie časy naznačujú potrebu viacerých kôl objasňovania alebo ťažkosti so zložitejšími otázkami. Tieto metriky by sa mali sledovať samostatne pre rôzne kategórie problémov, keďže zložité technické otázky prirodzene vyžadujú viac času na vybavenie než jednoduché FAQ otázky.
LLM ako sudca predstavuje sofistikovaný prístup hodnotenia, kde jeden veľký jazykový model hodnotí kvalitu výstupov iného AI systému. Táto metodológia je obzvlášť účinná na hodnotenie odpovedí chatbota naprieč viacerými rozmermi kvality súčasne, ako je presnosť, relevantnosť, súdržnosť, plynulosť, bezpečnosť, úplnosť či tón. Výskumy ukazujú, že LLM sudcovia môžu dosiahnuť až 85 % zhodu s ľudským hodnotením, čím predstavujú škálovateľnú alternatívu k manuálnemu hodnoteniu. Prístup zahŕňa definovanie konkrétnych kritérií hodnotenia, vytvorenie detailných promptov s príkladmi, poskytnutie sudcovi pôvodnej otázky používateľa aj odpovede chatbota a získanie štruktúrovaných skóre alebo detailnej spätnej väzby.
Proces LLM ako sudca typicky používa dva prístupy: hodnotenie jedného výstupu, kde sudca hodnotí jednotlivú odpoveď buď bez referencie (bez správnej odpovede), alebo porovnaním s očakávanou odpoveďou, a párové porovnanie, kde sudca porovnáva dve odpovede a vyberá lepšiu. Táto flexibilita umožňuje hodnotenie absolútneho výkonu aj relatívne zlepšenia pri testovaní rôznych verzií alebo nastavení chatbota. Platforma FlowHunt podporuje implementáciu LLM ako sudcu cez vizuálne rozhranie, integráciu s poprednými LLM ako ChatGPT a Claude a cez CLI nástroje na pokročilé reporty a automatizované hodnotenia.
Okrem základných výpočtov presnosti detailná analýza konfúznej matice odhaľuje konkrétne vzory zlyhaní chatbota. Skúmaním, ktoré typy otázok produkujú falošné pozitíva a ktoré falošné negatíva, môžete identifikovať systémové slabiny. Napríklad, ak matica ukáže, že chatbot často zamieňa otázky o fakturácii za technickú podporu, odhaľuje to nevyváženosť tréningových dát alebo problém s rozpoznávaním zámeru v oblasti fakturácie. Vytváranie samostatných konfúznych matíc pre rôzne kategórie problémov umožňuje cielené zlepšenia namiesto všeobecného pretrénovania modelu.
A/B testovanie porovnáva rôzne verzie chatbota, aby sa určilo, ktorá je lepšia podľa kľúčových metrík. Môže ísť o testovanie rôznych šablón odpovedí, konfigurácií znalostnej bázy alebo základných jazykových modelov. Náhodným smerovaním časti prevádzky na každú verziu a porovnaním metrík ako FCR, CSAT alebo presnosť odpovedí môžete robiť rozhodnutia na základe dát o tom, ktoré vylepšenia implementovať. A/B testovanie by malo trvať dostatočne dlho, aby zachytilo prirodzenú variabilitu otázok používateľov a zabezpečilo štatistickú významnosť výsledkov.
FlowHunt poskytuje integrovanú platformu na tvorbu, nasadenie a hodnotenie AI helpdesk chatbotov s pokročilými možnosťami merania presnosti. Vizuálny builder platformy umožňuje aj netechnickým používateľom vytvárať sofistikované chatbotové toky, pričom AI komponenty sa integrujú s poprednými jazykovými modelmi ako ChatGPT a Claude. Nástroj na hodnotenie FlowHunt podporuje implementáciu metodológie LLM ako sudca, vďaka čomu si môžete definovať vlastné kritériá hodnotenia a automaticky posudzovať výkon chatbota naprieč celou konverzačnou databázou.
Na implementáciu komplexného merania presnosti s FlowHunt začnite definovaním konkrétnych kritérií hodnotenia v súlade s obchodnými cieľmi – či už uprednostňujete presnosť, rýchlosť, spokojnosť používateľov alebo mieru vyriešenia problémov. Nakonfigurujte hodnotiaci LLM s detailnými promptmi, ktoré špecifikujú spôsob hodnotenia odpovedí vrátane konkrétnych príkladov kvalitných a nekvalitných odpovedí. Nahrajte svoju konverzačnú databázu alebo pripojte živú prevádzku a následne spustite hodnotenia na generovanie detailných reportov o výkone naprieč všetkými metrikami. Dashboard FlowHunt poskytuje prehľad o výkone chatbota v reálnom čase, čo umožňuje rýchlu identifikáciu problémov a overenie zlepšení.
Vytvorte východiskové meranie pred implementovaním zlepšení, aby ste mali referenčný bod na hodnotenie vplyvu zmien. Zberajte merania priebežne, nie len periodicky, aby ste rýchlo odhalili pokles výkonu v dôsledku driftu dát alebo zastarania modelu. Implementujte spätnoväzobné slučky, kde hodnotenia a opravy používateľov automaticky vstupujú do tréningového procesu a neustále zvyšujú presnosť chatbota. Segmentujte metriky podľa kategórie problému, typu používateľa a časového obdobia, aby ste identifikovali konkrétne oblasti vyžadujúce pozornosť namiesto spoliehania sa iba na agregované štatistiky.
Zabezpečte, aby vaša hodnotiaca dátová sada reprezentovala skutočné používateľské otázky a očakávané odpovede, vyhýbajte sa umelým testovacím prípadom, ktoré nereflektujú reálne používanie. Pravidelne validujte automatizované metriky porovnaním s ľudským hodnotením, napríklad manuálnym hodnotením vzorky konverzácií, aby ste zabezpečili kalibráciu meracieho systému na skutočnú kvalitu. Dokumentujte svoju metodológiu merania a definície metrík jasne, čím zabezpečíte konzistentné hodnotenie v čase a zrozumiteľnú komunikáciu výsledkov pre zainteresovaných. Nakoniec stanovte cieľové hodnoty pre každú metriku v súlade s obchodnými cieľmi, čím vytvoríte zodpovednosť za neustále zlepšovanie a jasné ciele pre optimalizačné úsilie.
Pokročilá AI automatizačná platforma FlowHunt vám pomôže vytvoriť, nasadiť a vyhodnotiť výkonné helpdesk chatboty s integrovanými nástrojmi na meranie presnosti a hodnotenie pomocou LLM.
Získajte komplexné stratégie testovania AI chatbotov vrátane funkčných, výkonnostných, bezpečnostných a použiteľnostných testov. Objavte najlepšie postupy, nást...
Ovládnite AI chatbot prompty s naším komplexným sprievodcom. Naučte sa CARE framework, techniky prompt engineeringu a najlepšie postupy pre kvalitnejšie AI odpo...
Zistite najlepšie spôsoby, ako v roku 2025 oslovovať AI chatbot asistentov. Objavte formálne, neformálne a hravé štýly komunikácie, názvoslovie a ako efektívne ...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.