Hur du verifierar AI-chatbotars äkthet
Lär dig beprövade metoder för att verifiera AI-chatbotars äkthet år 2025. Upptäck tekniska verifieringstekniker, säkerhetskontroller och bästa praxis för att id...
10 min läsning
Lär dig heltäckande metoder för att mäta noggrannheten hos AI-helpdeskchattbotar 2025. Upptäck precision, recall, F1-poäng, användarnöjdhetsmått och avancerade utvärderingstekniker med FlowHunt.
Mät noggrannheten hos AI-helpdeskchattbotar med hjälp av flera olika mått, inklusive precision och recall-beräkningar, förväxlingsmatris, användarnöjdhetspoäng, lösningsgrad och avancerade LLM-baserade utvärderingsmetoder. FlowHunt erbjuder heltäckande verktyg för automatiserad noggrannhetsbedömning och prestationsövervakning.
Att mäta noggrannheten hos en AI-helpdeskchattbot är avgörande för att säkerställa att den levererar pålitliga och hjälpsamma svar på kundfrågor. Till skillnad från enkla klassificeringsuppgifter omfattar chattbotens noggrannhet flera dimensioner som måste utvärderas tillsammans för att ge en fullständig bild av prestandan. Processen innebär att analysera hur väl chattboten förstår användarens frågor, ger korrekta upplysningar, löser problem effektivt och bibehåller användarnöjdhet genom hela interaktionen. En heltäckande strategi för noggrannhetsmätning kombinerar kvantitativa mått med kvalitativ återkoppling för att identifiera styrkor och förbättringsområden.
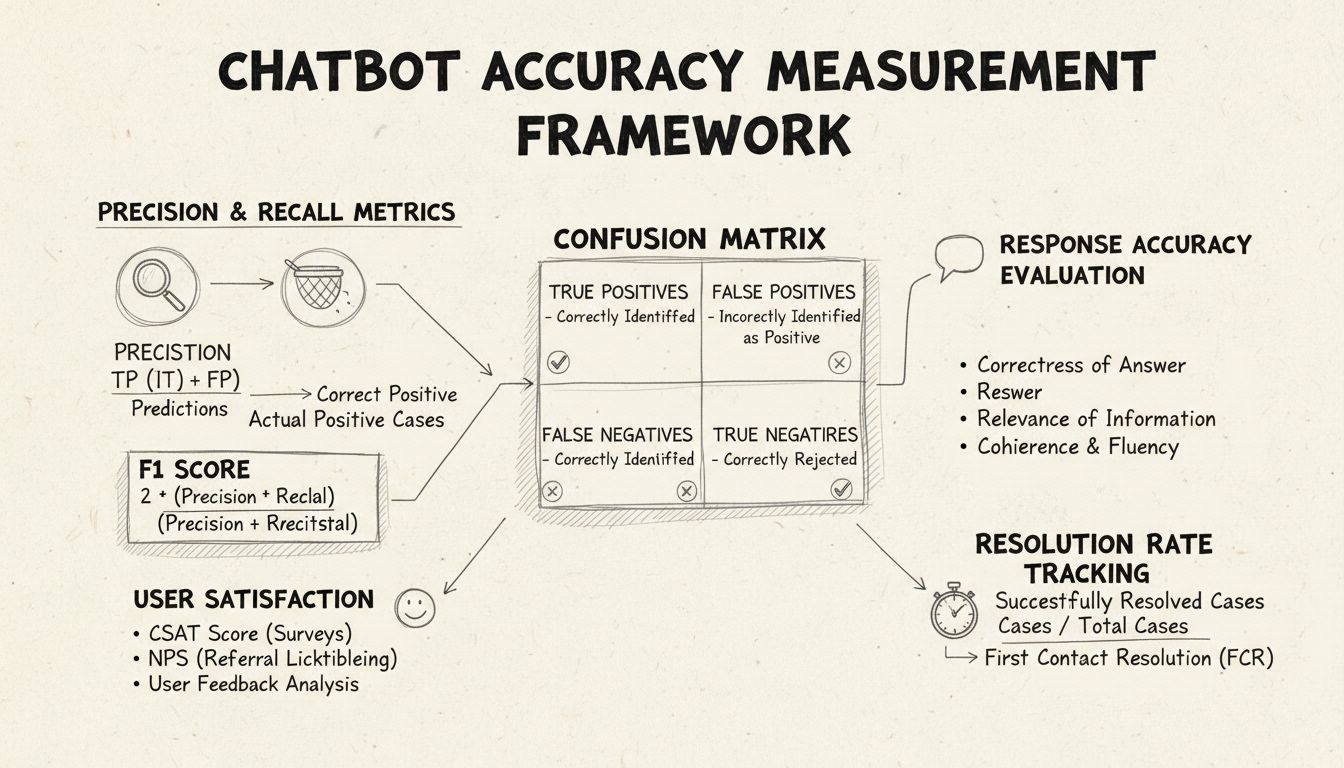
Precision och recall är grundläggande mått hämtade från förväxlingsmatrisen som mäter olika aspekter av chattbotens prestanda. Precision representerar andelen korrekta svar av alla svar chattboten har gett, beräknat med formeln: Precision = Sanna Positiv / (Sanna Positiv + Falska Positiv). Detta mått svarar på frågan: “När chattboten ger ett svar, hur ofta är det korrekt?” En hög precision betyder att chattboten sällan ger felaktig information, vilket är kritiskt för att bibehålla användarnas förtroende i helpdesksammanhang.
Recall, även kallat känslighet, mäter andelen korrekta svar av alla de svar chattboten borde ha gett, med formeln: Recall = Sanna Positiv / (Sanna Positiv + Falska Negativ). Detta mått visar om chattboten framgångsrikt identifierar och svarar på alla legitima kundproblem. I helpdesk-kontext säkerställer hög recall att kunder får hjälp med sina problem istället för att få höra att chattboten inte kan hjälpa när den faktiskt skulle kunnat. Förhållandet mellan precision och recall innebär en naturlig avvägning: optimering för det ena minskar ofta det andra, vilket kräver en noggrann balans utifrån dina specifika affärsprioriteringar.
F1-poängen ger ett enda mått som balanserar både precision och recall, beräknat som det harmoniska medelvärdet: F1 = 2 × (Precision × Recall) / (Precision + Recall). Detta mått är särskilt värdefullt när du behöver en enhetlig prestationsindikator eller när du har obalanserade datamängder där en klass är betydligt större än de andra. Om din chattbot till exempel hanterar 1 000 rutinfrågor men bara 50 komplexa ärenden, förhindrar F1-poängen att måttet snedvrids av majoritetsklassen. F1-poängen varierar från 0 till 1, där 1 representerar perfekt precision och recall, vilket gör det lätt för intressenter att snabbt förstå chattbotens övergripande prestanda.
Förväxlingsmatrisen är ett grundläggande verktyg som bryter ner chattbotens prestanda i fyra kategorier: Sanna Positiv (korrekta svar på giltiga frågor), Sanna Negativ (korrekt nekad svar på frågor utanför botens område), Falska Positiv (felaktiga svar) och Falska Negativ (missade möjligheter att hjälpa). Den här matrisen avslöjar specifika mönster i chattbotens misslyckanden och möjliggör riktade förbättringar. Om matrisen till exempel visar många falska negativ för fakturafrågor kan du identifiera att chattbotens träningsdata saknar tillräckliga exempel på fakturafrågor och behöver förbättras inom det området.
| Mått | Definition | Beräkning | Affärspåverkan |
|---|---|---|---|
| Sanna Positiv (TP) | Korrekta svar på giltiga frågor | Räknas direkt | Bygger kundförtroende |
| Sanna Negativ (TN) | Korrekt nekad svar på utomstående frågor | Räknas direkt | Förhindrar felinformation |
| Falska Positiv (FP) | Felaktiga svar | Räknas direkt | Skadar trovärdighet |
| Falska Negativ (FN) | Missade möjligheter att hjälpa | Räknas direkt | Minskar nöjdhet |
| Precision | Kvalitet på positiva förutsägelser | TP / (TP + FP) | Tillförlitlighetsmått |
| Recall | Täckning av verkliga positiva | TP / (TP + FN) | Fullständighetsmått |
| Noggrannhet | Övergripande korrekthet | (TP + TN) / Totalt | Allmän prestanda |
Svarsnoggrannhet mäter hur ofta chattboten ger faktamässigt korrekta uppgifter som direkt besvarar användarens fråga. Detta går bortom enkel mönsterigenkänning och utvärderar om innehållet är korrekt, aktuellt och lämpligt i sammanhanget. Manuella granskningsprocesser innebär att mänskliga utvärderare granskar ett slumpmässigt urval av konversationer och jämför chattbotens svar mot en fördefinierad kunskapsbas med korrekta svar. Automatiska jämförelsemetoder kan implementeras med hjälp av NLP-tekniker för att matcha svar mot förväntade svar i ditt system, även om dessa måste kalibreras noggrant för att undvika falska negativ när chattboten ger korrekt information med annan formulering än referenssvaret.
Svarsrelevans utvärderar om chattbotens svar faktiskt adresserar vad användaren frågade, även om svaret inte är helt korrekt. Denna dimension fångar situationer där chattboten ger hjälpsam information som, även om den inte är exakt rätt, för samtalet närmare en lösning. NLP-baserade metoder som cosinuslikhet kan mäta den semantiska likheten mellan användarens fråga och chattbotens svar och ge ett automatiserat relevansbetyg. Användarfeedback, exempelvis tummen upp/ner efter varje interaktion, ger direkt relevansbedömning från de som betyder mest – dina kunder. Dessa feedbacksignaler bör samlas in kontinuerligt och analyseras för att identifiera mönster där chattboten hanterar vissa frågetyper bättre eller sämre.
Customer Satisfaction Score (CSAT) mäter användarnöjdhet med chattbotinteraktioner via direkta enkäter, vanligtvis med en 1-5-skala eller enkla nöjdhetsbetyg. Efter varje interaktion får användaren betygsätta sin upplevelse, vilket ger omedelbar återkoppling på om chattboten motsvarade förväntningarna. CSAT över 80 % indikerar generellt stark prestanda, medan värden under 60 % signalerar betydande problem som kräver åtgärd. Fördelen med CSAT är dess enkelhet och direkthet – användaren anger tydligt om den är nöjd – men resultaten kan påverkas av andra faktorer än chattbotens noggrannhet, som ärendets komplexitet eller användarens förväntningar.
Net Promoter Score mäter sannolikheten att användare rekommenderar chattboten till andra, beräknat genom att fråga “Hur sannolikt är det att du rekommenderar denna chattbot till en kollega?” på en skala 0–10. Svarande med 9–10 är promotors, 7–8 passiva och 0–6 är kritiker. NPS = (Promotors - Kritiker) / Totalt antal svarande × 100. Detta mått korrelerar starkt med långsiktig kundlojalitet och ger insikt i om chattboten skapar positiva upplevelser som användare vill dela. En NPS över 50 anses vara utmärkt, medan negativ NPS indikerar allvarliga prestandaproblem.
Sentimentanalys undersöker den känslomässiga tonen i användarmeddelanden före och efter chattbotinteraktioner för att mäta nöjdhet. Avancerade NLP-tekniker klassificerar meddelanden som positiva, neutrala eller negativa och visar om användare blir mer nöjda eller frustrerade under samtalets gång. En positiv sentimentförändring visar att chattboten lyckades lösa problem, medan negativ förändring tyder på att användaren blev frustrerad eller inte fick behovet tillgodosett. Detta mått fångar känslomässiga dimensioner som traditionella noggrannhetsmått missar och ger värdefull kontext för att förstå användarupplevelsen.
First Contact Resolution (FCR) mäter andelen kundproblem som löses av chattboten utan att eskaleras till mänskliga agenter. Detta mått påverkar både operativ effektivitet och kundnöjdhet, eftersom kunder föredrar att få sina ärenden lösta direkt. FCR över 70 % indikerar stark chattbotprestanda, medan värden under 50 % tyder på att chattboten saknar tillräcklig kunskap eller förmåga att hantera vanliga ärenden. Att följa upp FCR per ärendekategori visar vilka problemtyper chattboten hanterar väl och vilka som kräver mänskligt ingripande, vilket vägleder träning och förbättring av kunskapsbasen.
Eskaleringsgrad mäter hur ofta chattboten lämnar över samtal till mänskliga agenter, medan fallback-frekvensen anger hur ofta boten ger generiska standardsvar som “Jag förstår inte” eller “Var god formulera om din fråga.” Höga eskaleringsgrader (över 30 %) tyder på att chattboten saknar kunskap eller självförtroende i många situationer, medan hög fallback-frekvens antyder dålig avsiktsigenkänning eller bristfällig träningsdata. Dessa mått identifierar specifika luckor i chattbotens förmågor som kan åtgärdas genom att utöka kunskapsbasen, omträna modellen eller förbättra förståelsen av naturligt språk.
Svarstid mäter hur snabbt chattboten svarar på användarens meddelanden, vanligtvis i millisekunder till sekunder. Användare förväntar sig omedelbara svar; fördröjningar över 3–5 sekunder påverkar nöjdheten negativt. Hanteringstid mäter den totala tiden från att användaren kontaktar chattboten tills ärendet är löst eller eskalerat, vilket ger insikt i chattbotens effektivitet. Kortare hanteringstid visar att chattboten snabbt förstår och löser problem, medan längre tider antyder att boten behöver flera förtydliganden eller har svårt med komplexa frågor. Dessa mått bör följas separat per ärendekategori, eftersom tekniskt komplexa problem naturligt tar längre tid än enkla FAQ-frågor.
LLM As a Judge är en sofistikerad utvärderingsmetod där en stor språkmodell bedömer kvaliteten på en annan AI:s svar. Denna metodik är särskilt effektiv för att utvärdera chattbotens svar utifrån flera kvalitetsdimensioner samtidigt, såsom korrekthet, relevans, koherens, flyt, säkerhet, fullständighet och ton. Forskning visar att LLM-domare kan uppnå upp till 85 % överensstämmelse med mänskliga utvärderingar, vilket gör dem till ett skalbart alternativ till manuell granskning. Metoden innebär att man definierar specifika utvärderingskriterier, skapar detaljerade domaruppmaningar med exempel, ger domaren både användarens ursprungliga fråga och chattbotens svar, och får strukturerade poäng eller detaljerad återkoppling.
LLM As a Judge-processen använder vanligtvis två utvärderingsmetoder: individuell utvärdering, där domaren poängsätter ett enskilt svar antingen utan referens (referenslös utvärdering) eller genom jämförelse med ett förväntat svar (referensbaserad utvärdering), och parvis jämförelse, där domaren jämför två svar för att avgöra vilket som är bäst. Denna flexibilitet möjliggör utvärdering av både absolut prestanda och relativa förbättringar vid test av olika chattbotversioner eller konfigurationer. FlowHunt:s plattform stöder LLM As a Judge-implementationer via sitt dra-och-släpp-gränssnitt, integration med ledande LLM:er som ChatGPT och Claude, samt CLI-verktyg för avancerad rapportering och automatiska utvärderingar.
Utöver grundläggande noggrannhetsberäkningar avslöjar detaljerad analys av förväxlingsmatrisen specifika mönster i chattbotens misslyckanden. Genom att undersöka vilka frågetyper som ger falska positiv respektive falska negativ kan du identifiera systematiska svagheter. Om matrisen till exempel visar att chattboten ofta felklassificerar fakturafrågor som tekniska supportärenden tyder detta på en obalans i träningsdata eller problem med avsiktsigenkänning inom fakturaområdet. Att skapa separata förväxlingsmatriser för olika ärendekategorier möjliggör riktade förbättringar istället för generell modellomträning.
A/B-testning jämför olika versioner av chattboten för att avgöra vilken som presterar bäst på nyckelmått. Detta kan innebära test av olika svarsmallar, kunskapsbasinställningar eller underliggande språkmodeller. Genom att slumpmässigt styra en del av trafiken till varje version och jämföra mått som FCR, CSAT och svarsnoggrannhet kan du fatta datadrivna beslut kring vilka förbättringar som ska införas. A/B-testning bör pågå tillräckligt länge för att fånga naturliga variationer i användarfrågor och säkerställa statistisk signifikans i resultaten.
FlowHunt erbjuder en integrerad plattform för att bygga, lansera och utvärdera AI-helpdeskchattbotar med avancerade möjligheter till noggrannhetsmätning. Plattformens visuella byggare gör det möjligt för icke-tekniska användare att skapa sofistikerade chattbotflöden, medan AI-komponenterna integreras med ledande språkmodeller som ChatGPT och Claude. FlowHunt:s utvärderingsverktyg stödjer implementering av LLM As a Judge-metodiken, så att du kan definiera egna utvärderingskriterier och automatiskt bedöma chattbotens prestanda över hela din konversationsdatamängd.
För att implementera heltäckande noggrannhetsmätning med FlowHunt, börja med att definiera utvärderingskriterier som är i linje med affärsmålen – oavsett om du prioriterar noggrannhet, snabbhet, användarnöjdhet eller lösningsgrad. Konfigurera plattformens bedömande LLM med detaljerade uppmaningar som anger hur svar ska utvärderas, inklusive konkreta exempel på högkvalitativa och sämre svar. Ladda upp din konversationsdata eller koppla in live-trafik och kör sedan utvärderingar för att ta fram detaljerade rapporter som visar prestanda inom samtliga mått. FlowHunt:s dashboard ger realtidsöversikt över chattbotens prestation, vilket möjliggör snabb identifiering av problem och validering av förbättringar.
Fastställ en grundnivå innan du inför förbättringar för att skapa en referenspunkt för att utvärdera förändringarnas effekt. Samla in mätdata kontinuerligt istället för periodvis så att du tidigt kan upptäcka prestandaförsämring på grund av datadrift eller modellförfall. Implementera feedbackloopar där användarbetyg och korrigeringar automatiskt återförs till träningsprocessen, så att chattbotens noggrannhet ständigt förbättras. Segmentera mått per ärendekategori, användartyp och tidsperiod för att identifiera specifika förbättringsområden istället för att endast förlita dig på aggregatstatistik.
Säkerställ att din utvärderingsdata representerar verkliga användarfrågor och förväntade svar, och undvik konstlade testfall som inte speglar faktisk användning. Validera regelbundet automatiska mått mot mänsklig bedömning genom att låta utvärderare manuellt granska ett urval konversationer, så att ditt mätsystem förblir kalibrerat mot verklig kvalitet. Dokumentera din mätmetodik och definitionerna av måtten tydligt, så att utvärderingen blir konsekvent över tid och resultaten kan kommuniceras tydligt till intressenter. Sätt slutligen prestationsmål för varje mått i linje med affärsmålen, så att du får ett ansvarstagande för kontinuerlig förbättring och tydliga mål för optimeringsarbetet.
FlowHunt:s avancerade AI-automationsplattform hjälper dig att skapa, lansera och utvärdera högpresterande helpdeskchattbotar med inbyggda verktyg för noggrannhetsmätning och LLM-baserad utvärdering.
Lär dig beprövade metoder för att verifiera AI-chatbotars äkthet år 2025. Upptäck tekniska verifieringstekniker, säkerhetskontroller och bästa praxis för att id...
Lär dig omfattande strategier för testning av AI-chattbotar, inklusive funktionella tester, prestanda-, säkerhets- och användbarhetstester. Upptäck bästa praxis...
Lär dig hur AI-chattbotar kan luras genom prompt engineering, adversarial inputs och kontextförvirring. Förstå chattbots sårbarheter och begränsningar år 2025....
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.