Dokument
Din chatbot kan omedelbart få tillgång till och använda dokument, HTML-sidor och till och med YouTube-videor för att anpassa din unika kontext. Perfekt för att ...
2 min läsning
AI Chatbot
Knowledge Management
+3
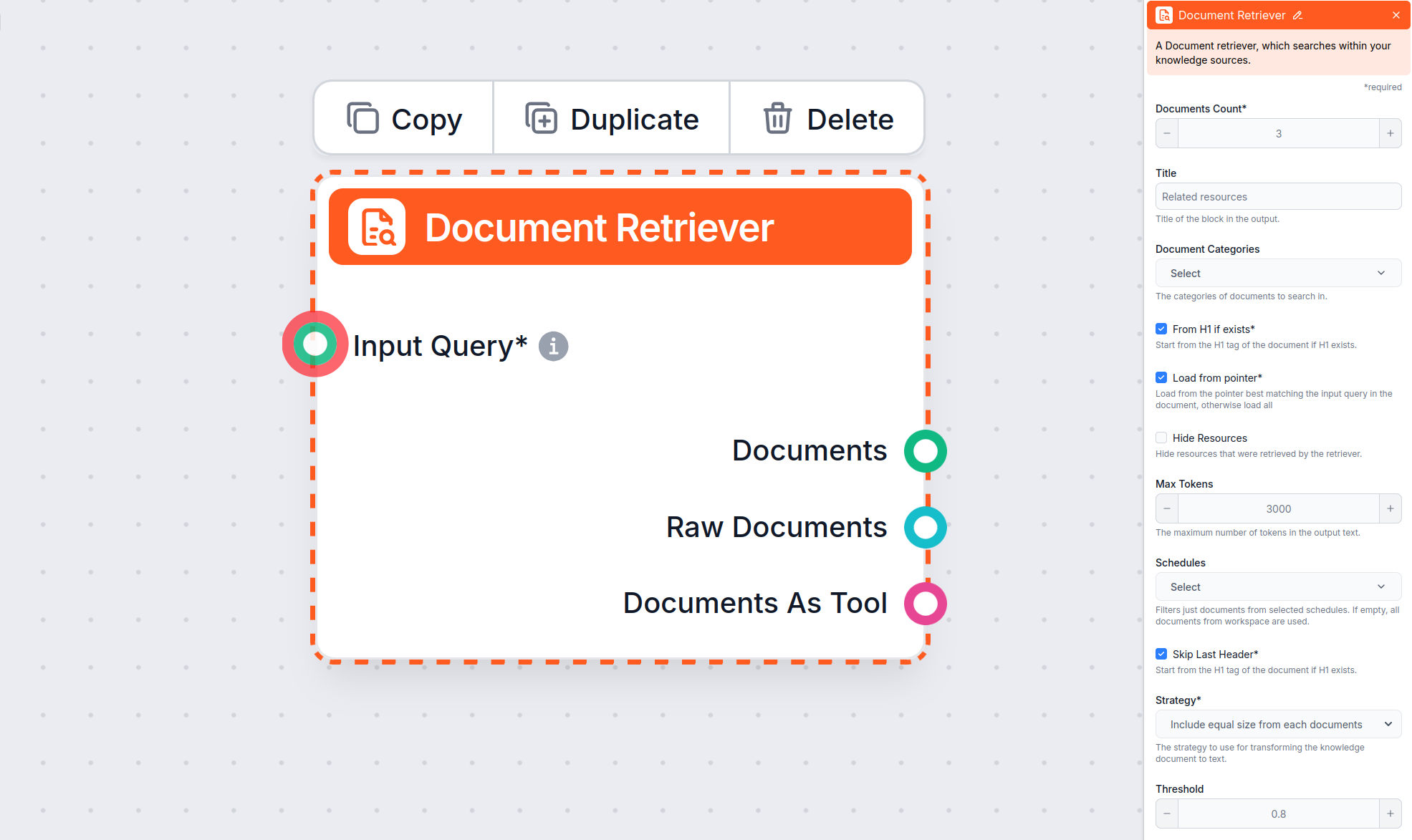
Lär dig hur du ställer in parametrarna ‘Från H1 om det finns’, ‘Ladda från pekare’ och ‘Hoppa över sista rubriken’.
Document Retriever-komponenten låter chatboten hämta kunskap från källor du har angett i Dokument och Scheman. Denna komponents roll är att styra hämtningen, och flera parametrar påverkar hur komponenten hämtar information från dessa dokument.
Alternativet Från H1 om det finns instruerar retrievern att börja extrahera innehåll från den H1-rubrik den hittar (vanligtvis artikelns huvudrubrik).
Vad händer?
Exempel på användningsfall:
Du vill bara hämta själva guiden, utan någon webbplatsnavigering eller sidhuvud som finns på din webbplats.
Obs:
Från H1 om det finns är aktiverad i Document Retriever-komponenten som standard.
Alternativet Ladda från pekare ger dig mer precision genom att låta Document Retriever ladda endast data från en pekare i den eventuellt längre artikeln.
Vad händer?
Vad är en “pekare”?
En pekare är vanligtvis en unik sträng eller rubrik som finns i dokumentet (till exempel en H2 eller en specifik fras eller avsnittsnamn).
Exempel på användningsfall:
Du vill hoppa över inledande avsnitt och hämta information för ett specifikt relevant avsnitt i en potentiellt lång artikel eller ett dokument (t.ex. från “Steg 4: Lägg till en livechat-knapp” i en installationsguide).
Alternativet Hoppa över sista rubriken är användbart för att ignorera den sista rubriken i dokumentet, som ofta upprepas eller används för navigering eller sidfotsändamål.
Vad händer?
Exempel på användningsfall:
Du vill undvika att Document Retriever laddar en sidfotsnavigationsrubrik (såsom “Andra artiklar” längst ner på en hjälpsida), så att endast huvudinnehållet bearbetas.
Obs:
Hoppa över sista rubriken kan hjälpa med dokument som automatiskt genererar sidfötter eller upprepade navigeringselement. Om du dock inte har sådana avsnitt kan användning av denna parameter innebära att en del av artikeln med giltig information inte hämtas. Därför rekommenderas att du låter detta alternativ vara omarkerat tills det finns en giltig anledning att aktivera det.
Parametern Max tokens låter dig styra det maximala antalet tokens (ord och skiljetecken, som räknas av den underliggande AI-modellen) som Document Retriever kommer att ge ut från den extraherade texten.
Vad händer?
Standardvärde:
Standardvärdet är vanligtvis 3000 tokens, men vid behov kan du justera detta.
Exempel på användningsfall:
Om du bearbetar långa dokument hjälper det att ange ett lägre värde för Max tokens att hålla svaren kortfattade. För bästa resultat överväg dock att aktivera parametern “Ladda från pekare”. Det säkerställer att den extraherade texten börjar vid det mest relevanta avsnittet i dokumentet, snarare än från början, så att du får en fokuserad och hanterbar informationsmängd inom din angivna token-gräns. Denna kombination är särskilt användbar när du vill ha kortfattade, kontextuellt relevanta utdrag från stora källor.
Obs:
Om du märker att information kapas, prova att öka värdet för Max tokens. Om du tvärtom vill ha kortare, mer fokuserade utdrag, minska parametern Max tokens.
När Document Retriever hittar flera relevanta dokument avgör parametern Strategi hur de slås ihop till en enda textutdata för din chatbot, med hänsyn till gränsen för “Max tokens”.
Två strategi-alternativ:
Inkludera lika mycket från varje dokument:
Token-gränsen delas jämnt. Till exempel, med tre dokument och en gräns på 3 000 tokens får varje upp till 1 000 tokens. Detta säkerställer att alla källor bidrar lika mycket, vilket är användbart när du vill ha ett balanserat svar som hämtar från flera dokument.
Sammanfoga dokument, fyll från första upp till token-gränsen:
Dokument läggs till i ordning efter relevans tills token-gränsen nås. Det mest relevanta dokumentet fyller utrymmet först; om det finns plats kvar läggs mindre relevanta dokument till i ordning. Om första dokumentet är långt kan det använda hela gränsen själv.
Hur väljer man?
Obs:
Dessa strategier påverkar endast hur texten konstrueras från de hämtade dokumenten innan den skickas vidare till nästa steg (t.ex. AI-generering). De ändrar inte vilka dokument som hämtas – endast hur deras innehåll slås ihop och trimmas för att passa inom inställningen Max tokens.
Denna artikel fokuserar på att konfigurera parametrarna ‘Från H1 om det finns’, ‘Ladda från pekare’, ‘Hoppa över sista rubriken’ och ‘Max tokens’, men Document Retriever erbjuder även ytterligare parametrar som hjälper till att styra hur dokument väljs och hämtas:
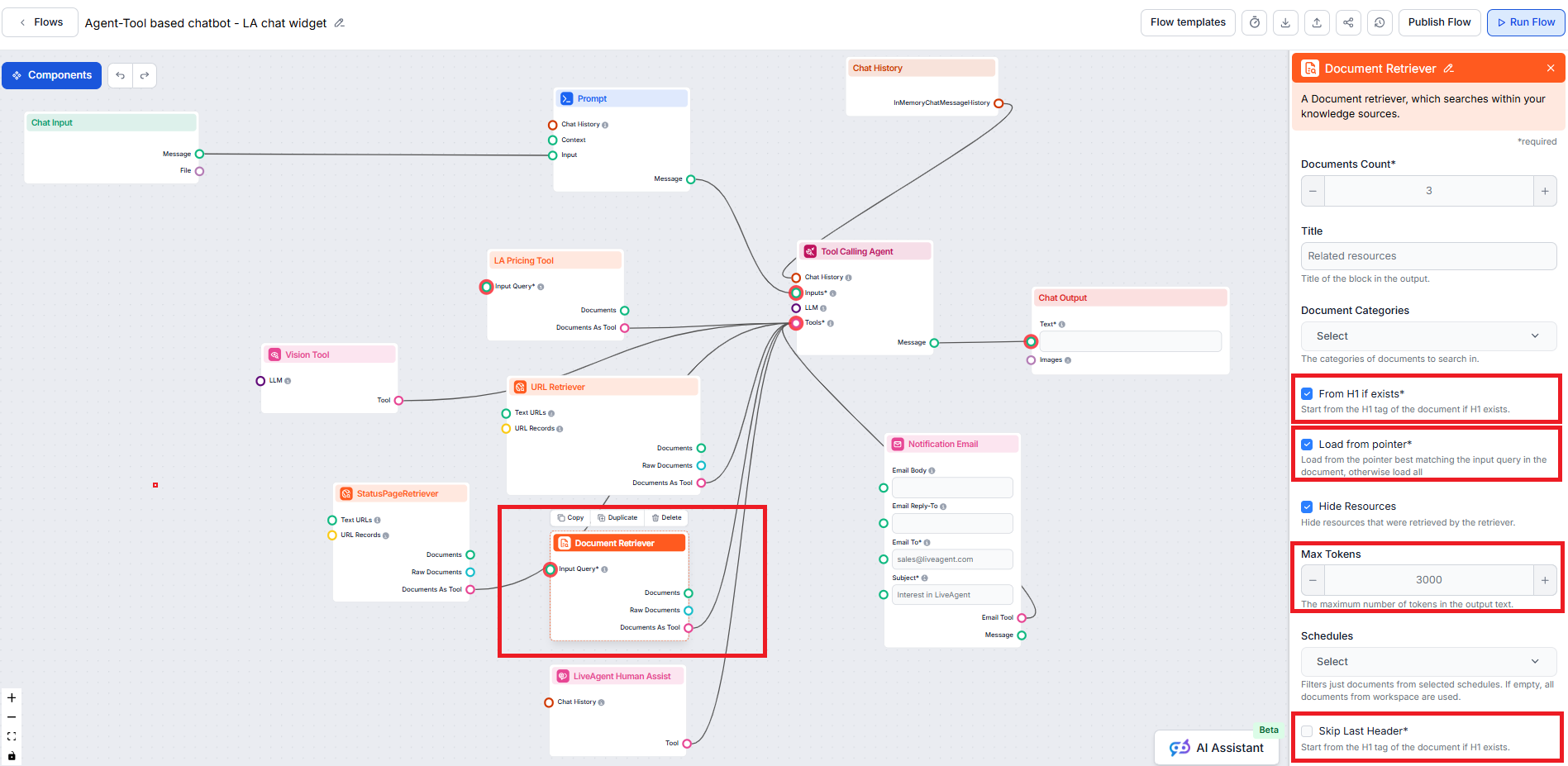
Denna inställning begränsar antalet dokument som flödet ska hämta, vilket säkerställer att resultaten förblir relevanta och att svar genereras snabbt.
Denna valfria inställning gör det möjligt att begränsa hämtningen till en eller flera kategorier som du har skapat i avsnittet Dokument i Kunskapskällor.
Detta låter dig inkludera eller dölja en separat sektion, före det faktiska chatbotsvaret, med en lista över resurser som hämtats av retrievern. För integration med LiveAgent måste detta vara markerat, då denna sektion inte stöds och inte visas korrekt i LiveAgent-chatbotwidgeten.
Låter dig begränsa hämtningen till ett eller flera scheman du har angett för att crawla eller uppdatera innehåll i Kunskapskällor.
Styr hur nära de hämtade dokumenten måste matcha inmatningsfrågan, med hjälp av ett relevansvärde (från 0 till 1). Till exempel rekommenderas ett tröskelvärde på 0,7–0,8 för mycket relevanta svar. Högre tröskelvärden ger mer precisa träffar, medan lägre kan inkludera mindre relevanta dokument.
Exempel:
Om du anger ett tröskelvärde på 0,6 och har fyra artiklar med relevanspoäng på 0,8, 0,65, 0,5 och 0,9, kommer endast de över 0,6 (dvs. 0,8, 0,65 och 0,9) att användas för extrahering.
Om svaret från chatboten inte innehåller information som du är säker på att chatboten har tillgång till i dina dokument eller scheman, prova att kontrollera konversationshistoriken med alternativet “Utförlig” för att se detaljerade loggar över om Document Retriever användes och vilka dokument som hämtades. Justera vid behov dina inställningar och prompt baserat på dessa loggar.
Din chatbot kan omedelbart få tillgång till och använda dokument, HTML-sidor och till och med YouTube-videor för att anpassa din unika kontext. Perfekt för att ...
Förvandla enkelt innehållet i dina PDF-filer eller presentationsbilder till strukturerade, högpresterande bloggidéer med hjälp av AI. Ladda upp ditt dokument oc...
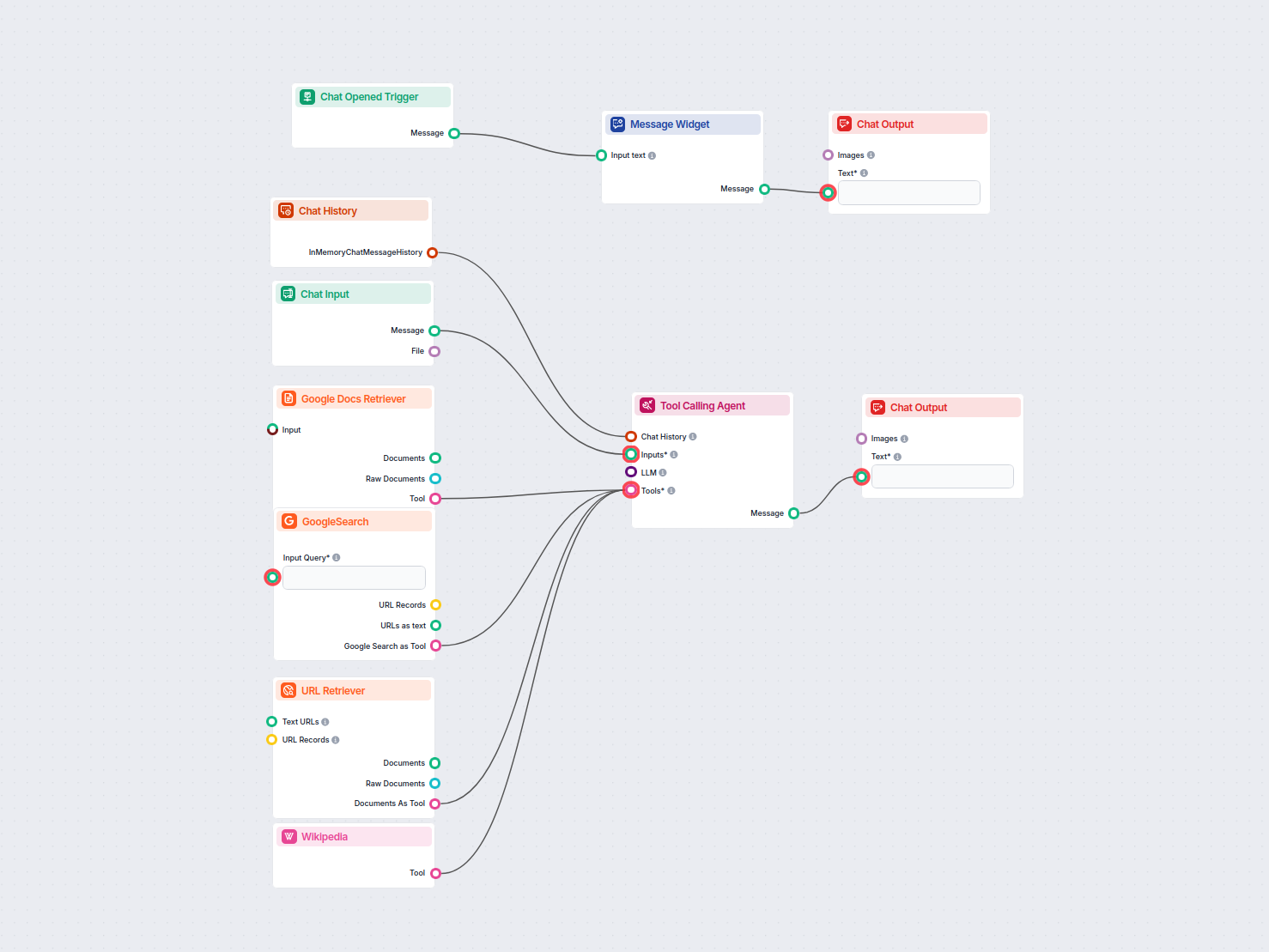
Detta AI-drivna arbetsflöde extraherar specifik information från ett Google-dokument och utvidgar sedan informationen genom att forska i källor som Google Sök, ...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.