
Databricks MCP-server
Databricks MCP-server kopplar AI-assistenter till Databricks-miljöer och möjliggör autonom utforskning, förståelse och interaktion med Unity Catalog-metadata oc...
4 min läsning
AI
MCP Server
+5
Koppla dina AI-agenter till Databricks för automatiserad SQL, jobbövervakning och arbetsflödesshantering med Databricks MCP-server i FlowHunt.
FlowHunt erbjuder ett extra säkerhetslager mellan dina interna system och AI-verktyg, vilket ger dig granulär kontroll över vilka verktyg som är tillgängliga från dina MCP-servrar. MCP-servrar som hostas i vår infrastruktur kan sömlöst integreras med FlowHunts chatbot samt populära AI-plattformar som ChatGPT, Claude och olika AI-redigerare.
Databricks MCP (Model Context Protocol) Server är ett specialverktyg som kopplar AI-assistenter till Databricks-plattformen och möjliggör sömlös interaktion med Databricks-resurser via naturliga språkliga gränssnitt. Servern fungerar som en brygga mellan stora språkmodeller (LLM:er) och Databricks API:er, vilket gör det möjligt för LLM:er att köra SQL-frågor, lista jobb, hämta jobbstatus och få detaljerad jobbinformation. Genom att exponera dessa möjligheter via MCP-protokollet ger Databricks MCP-servern utvecklare och AI-agenter möjlighet att automatisera dataflöden, hantera Databricks-jobb och effektivisera databasoperationer och därmed öka produktiviteten i datadrivna utvecklingsmiljöer.
Inga promptmallar beskrivs i repot.
Starta din kostnadsfria provperiod idag och se resultat inom några dagar.
Inga specifika resurser listas i repot.
Få de senaste tipsen, trenderna och erbjudandena gratis.
pip install -r requirements.txt..env-fil med dina Databricks-uppgifter.{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
Exempel på säkring av API-nycklar:
{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"],
"env": {
"DATABRICKS_HOST": "${DATABRICKS_HOST}",
"DATABRICKS_TOKEN": "${DATABRICKS_TOKEN}",
"DATABRICKS_HTTP_PATH": "${DATABRICKS_HTTP_PATH}"
}
}
}
}
.env-filen med Databricks-uppgifter.{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
.env med uppgifter.{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
.env.{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
Obs! Skydda alltid dina API-nycklar och hemligheter genom att använda miljövariabler som visas i konfigurationsexemplen ovan.
Använda MCP i FlowHunt
För att integrera MCP-servrar i ditt FlowHunt-arbetsflöde, börja med att lägga till MCP-komponenten i ditt flöde och koppla den till din AI-agent:

Klicka på MCP-komponenten för att öppna konfigurationspanelen. I systemets MCP-konfigurationssektion anger du dina MCP-serveruppgifter med detta JSON-format:
{
"databricks": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
När det är konfigurerat kan AI-agenten nu använda denna MCP som ett verktyg med tillgång till alla dess funktioner och möjligheter. Kom ihåg att byta ut “databricks” till det faktiska namnet på din MCP-server och ersätt URL:en med din egen MCP-serveradress.
| Sektion | Tillgänglig | Detaljer/Kommentarer |
|---|---|---|
| Översikt | ✅ | |
| Lista över prompts | ⛔ | Inga promptmallar angivna i repo |
| Lista över resurser | ⛔ | Inga specifika resurser definierade |
| Lista över verktyg | ✅ | 4 verktyg: run_sql_query, list_jobs, get_job_status, get_job_details |
| Säkring av API-nycklar | ✅ | Via miljövariabler i .env och config-JSON |
| Stöd för sampling (mindre viktigt vid utvärdering) | ⛔ | Ej nämnt |
| Rotstöd | ⛔ | Ej nämnt |
Utifrån tillgången till kärnfunktioner (verktyg, installations- och säkerhetsvägledning men inga resurser eller promptmallar) är Databricks MCP-servern effektiv för Databricks API-integration men saknar vissa avancerade MCP-primitiver. Jag skulle ge denna MCP-server 6 av 10 för övergripande fullständighet och nytta i MCP-ekosystemet.
| Har LICENSE | ⛔ (saknas) |
|---|---|
| Har minst ett verktyg | ✅ |
| Antal förgreningar | 13 |
| Antal stjärnor | 33 |
Databricks MCP-server är en brygga mellan AI-assistenter och Databricks, och exponerar Databricks-funktioner som SQL-exekvering och jobbhantering via MCP-protokollet för automatiserade arbetsflöden.
Den stöder exekvering av SQL-frågor, listning av alla jobb, hämtning av jobbstatusar samt att få detaljerad information om specifika Databricks-jobb.
Använd alltid miljövariabler, till exempel genom att lägga dem i en `.env`-fil eller konfigurera dem i din MCP-serverinstallation, istället för att hårdkoda känslig information.
Ja, lägg bara till MCP-komponenten i ditt flöde, konfigurera den med dina Databricks MCP-serveruppgifter, så kan dina AI-agenter få åtkomst till alla stödda Databricks-funktioner.
Baserat på tillgängliga verktyg, installationsvägledning och säkerhetsstöd, men utan resurser och promptmallar, får denna MCP-server 6 av 10 för fullständighet i MCP-ekosystemet.
Automatisera SQL-frågor, övervaka jobb och hantera Databricks-resurser direkt från konversationsbaserade AI-gränssnitt. Integrera Databricks MCP-server i dina FlowHunt-flöden för nästa nivå av produktivitet.
Databricks MCP-server kopplar AI-assistenter till Databricks-miljöer och möjliggör autonom utforskning, förståelse och interaktion med Unity Catalog-metadata oc...
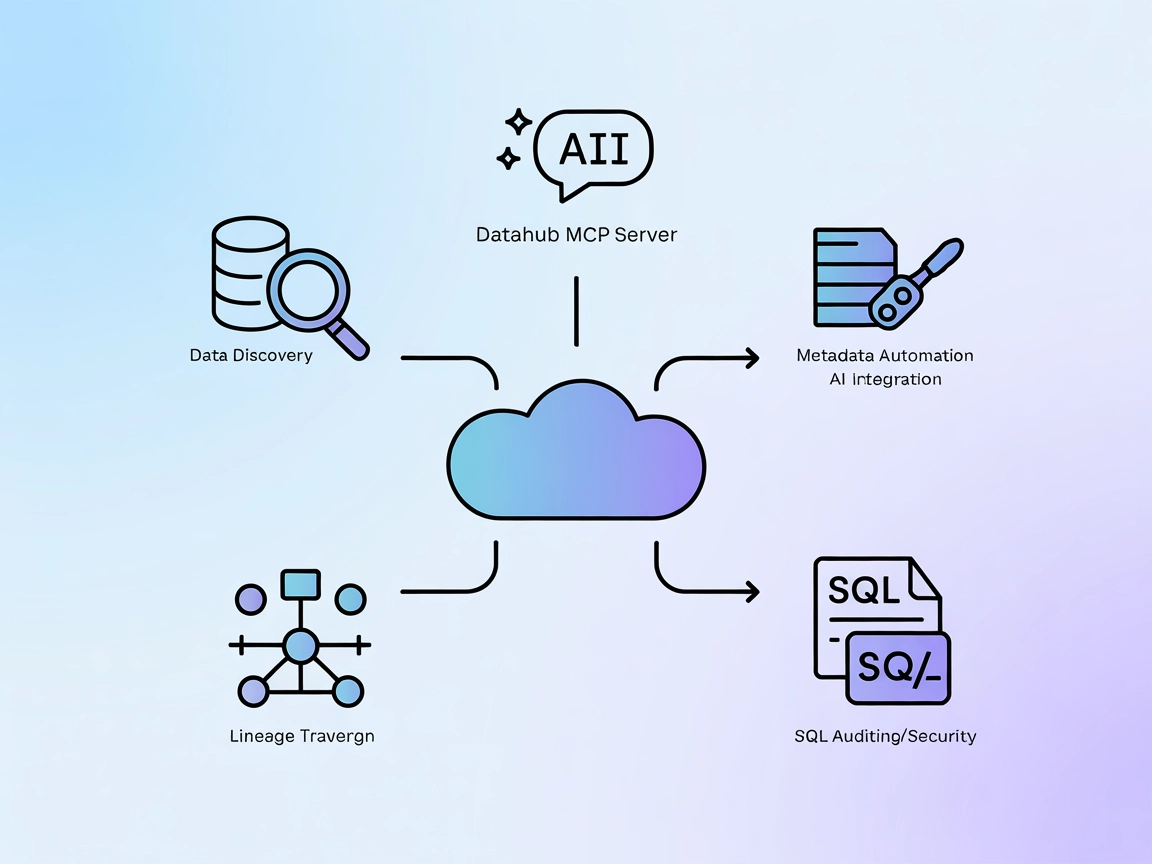
DataHub MCP Server fungerar som en brygga mellan FlowHunt AI-agenter och DataHub-metadata-plattformen, vilket möjliggör avancerad datadiscovery, linjeanalys, au...
Databricks Genie MCP-server möjliggör för stora språkmodeller att interagera med Databricks-miljöer via Genie API, med stöd för konversationell datautforskning,...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.