Thành phần LLM Mistral là gì?
Thành phần LLM Mistral kết nối các mô hình Mistral với luồng của bạn. Trong khi Generator và Agent là nơi diễn ra quá trình tạo nội dung thực sự, các thành phần LLM cho phép bạn kiểm soát mô hình được sử dụng. Tất cả thành phần đều mặc định sử dụng ChatGPT-4. Bạn có thể kết nối thành phần này nếu muốn thay đổi mô hình hoặc kiểm soát nhiều hơn.
Lưu ý rằng việc kết nối một thành phần LLM là tùy chọn. Tất cả các thành phần sử dụng LLM đều mặc định có ChatGPT-4o. Các thành phần LLM cho phép bạn thay đổi mô hình và kiểm soát các thiết lập của mô hình.
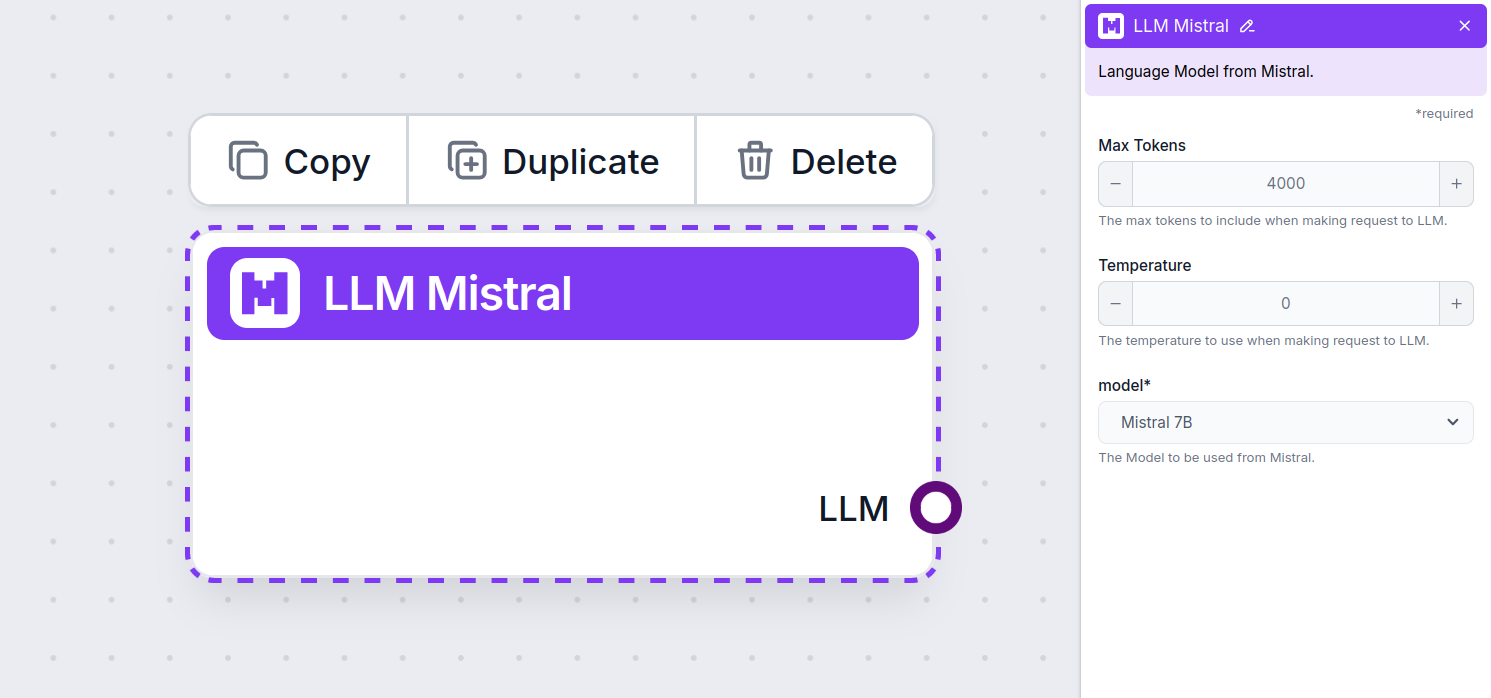
Thiết lập thành phần LLM Mistral
Max Tokens
Token đại diện cho các đơn vị văn bản riêng lẻ mà mô hình xử lý và sinh ra. Việc sử dụng token thay đổi tùy theo mô hình và một token có thể là từ, bán từ hoặc chỉ một ký tự. Các mô hình thường được tính phí theo triệu token.
Thiết lập max tokens giới hạn tổng số token có thể được xử lý trong một lần tương tác hoặc yêu cầu, đảm bảo phản hồi được sinh ra trong phạm vi hợp lý. Giới hạn mặc định là 4.000 token, đây là kích thước tối ưu để tóm tắt tài liệu và nhiều nguồn nhằm tạo ra câu trả lời.
Temperature
Temperature kiểm soát mức độ biến đổi của câu trả lời, trong khoảng từ 0 đến 1.
Nhiệt độ 0.1 sẽ khiến phản hồi rất đi thẳng vào vấn đề nhưng có thể lặp lại và thiếu sáng tạo.
Nhiệt độ cao 1 cho phép sự sáng tạo tối đa trong câu trả lời nhưng có nguy cơ tạo ra những phản hồi không liên quan hoặc thậm chí là ảo tưởng.
Ví dụ, nhiệt độ khuyến nghị cho chatbot dịch vụ khách hàng là từ 0.2 đến 0.5. Mức này giúp câu trả lời vừa sát chủ đề vừa có độ tự nhiên.
Model
Đây là nơi chọn mô hình. Tại đây, bạn sẽ thấy tất cả các mô hình của Mistral được hỗ trợ. Hiện tại, chúng tôi hỗ trợ các mô hình sau:
- Mistral 7B – Mô hình ngôn ngữ 7,3 tỷ tham số sử dụng kiến trúc transformers, phát hành theo giấy phép Apache 2.0. Dù là dự án nhỏ hơn, nhưng mô hình này thường vượt trội hơn Llama 2 của Meta. Xem kết quả thử nghiệm của chúng tôi.
- Mistral 8x7B (Mixtral) – Mô hình này áp dụng kiến trúc mixture of experts thưa, gồm 8 nhóm “chuyên gia” riêng biệt, tổng cộng 46,7 tỷ tham số. Mỗi token sử dụng tối đa 12,9 tỷ tham số, mang lại hiệu năng tương đương hoặc vượt LLaMA 2 70B và GPT-3.5 trên hầu hết các benchmark. Xem ví dụ đầu ra.
- Mistral Large – Mô hình ngôn ngữ hiệu suất cao với 123 tỷ tham số và độ dài ngữ cảnh 128.000 token. Thành thạo nhiều ngôn ngữ, bao gồm cả ngôn ngữ lập trình, và thể hiện hiệu suất cạnh tranh với các mô hình như LLaMA 3.1 405B, đặc biệt trong các tác vụ liên quan đến lập trình. Tìm hiểu thêm tại đây.
Cách thêm LLM Mistral vào luồng của bạn
Bạn sẽ thấy rằng tất cả các thành phần LLM chỉ có tay cầm đầu ra. Dữ liệu đầu vào không đi qua thành phần này, vì nó chỉ đại diện cho mô hình, còn quá trình sinh nội dung diễn ra ở AI Agents và Generators.
Tay cầm LLM luôn có màu tím. Tay cầm đầu vào LLM được tìm thấy trên bất kỳ thành phần nào sử dụng AI để sinh văn bản hoặc xử lý dữ liệu. Bạn có thể xem các tùy chọn bằng cách nhấp vào tay cầm:
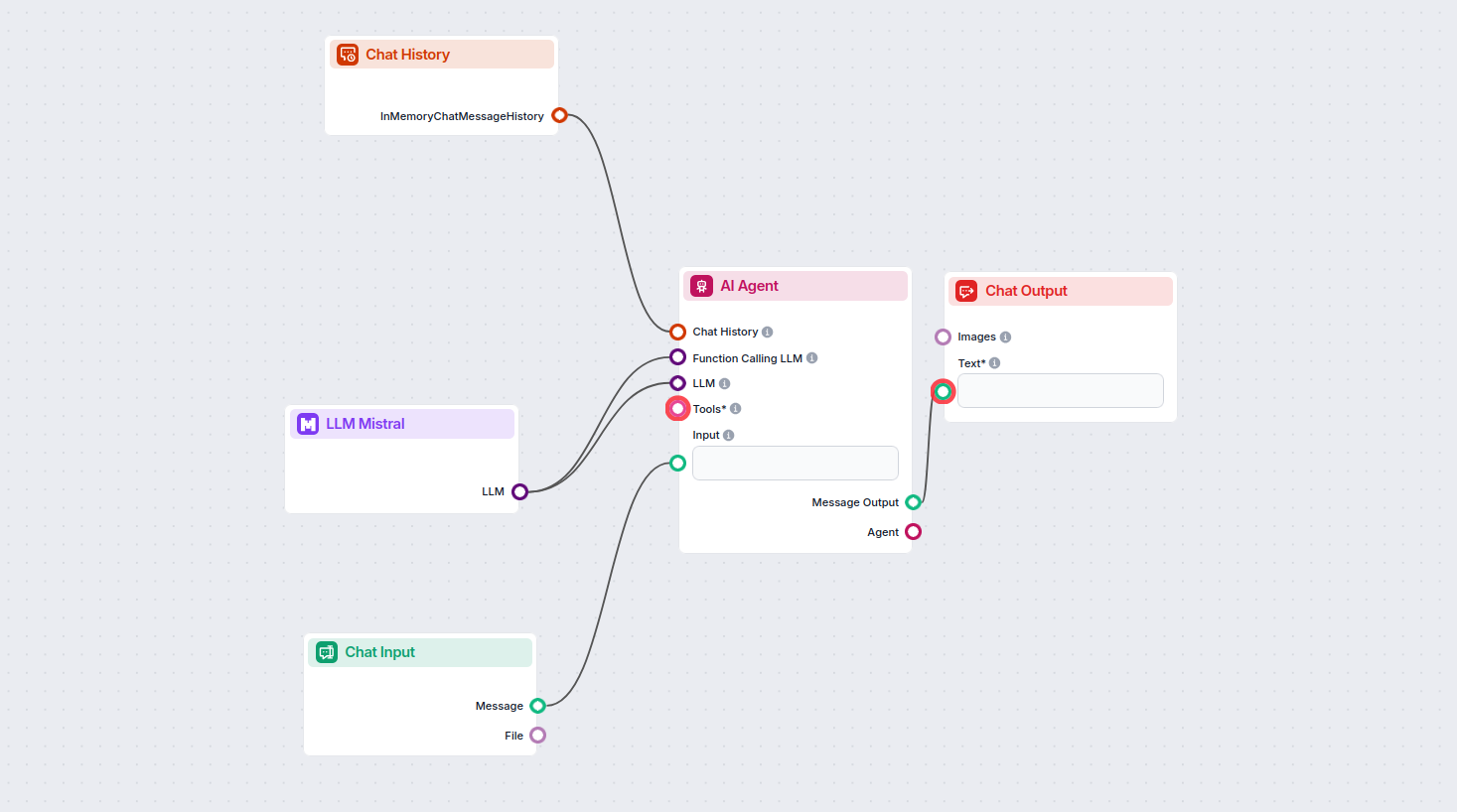
Điều này cho phép bạn tạo ra nhiều loại công cụ khác nhau. Hãy xem thành phần này hoạt động như thế nào. Dưới đây là luồng Chatbot AI Agent đơn giản sử dụng mô hình Mistral 7B để sinh phản hồi. Bạn có thể xem nó như một chatbot Mistral cơ bản.
Luồng Chatbot đơn giản này bao gồm:
- Chat input: Đại diện cho tin nhắn người dùng gửi trong chat.
- Chat history: Đảm bảo chatbot có thể nhớ và xét đến các phản hồi trước đó.
- Chat output: Đại diện cho phản hồi cuối cùng của chatbot.
- AI Agent: AI agent tự động sinh phản hồi.
- LLM Mistral: Kết nối với các mô hình tạo văn bản của Mistral.