Hva er LLM Mistral-komponenten?
LLM Mistral-komponenten kobler Mistral-modellene til din flow. Mens Generatorer og Agenter er der den faktiske magien skjer, lar LLM-komponenter deg kontrollere hvilken modell som brukes. Alle komponenter kommer med ChatGPT-4 som standard. Du kan koble til denne komponenten hvis du ønsker å endre modellen eller få mer kontroll over den.
Husk at tilkobling av en LLM-komponent er valgfritt. Alle komponenter som bruker en LLM kommer med ChatGPT-4o som standard. LLM-komponentene lar deg bytte modell og kontrollere modellinnstillinger.
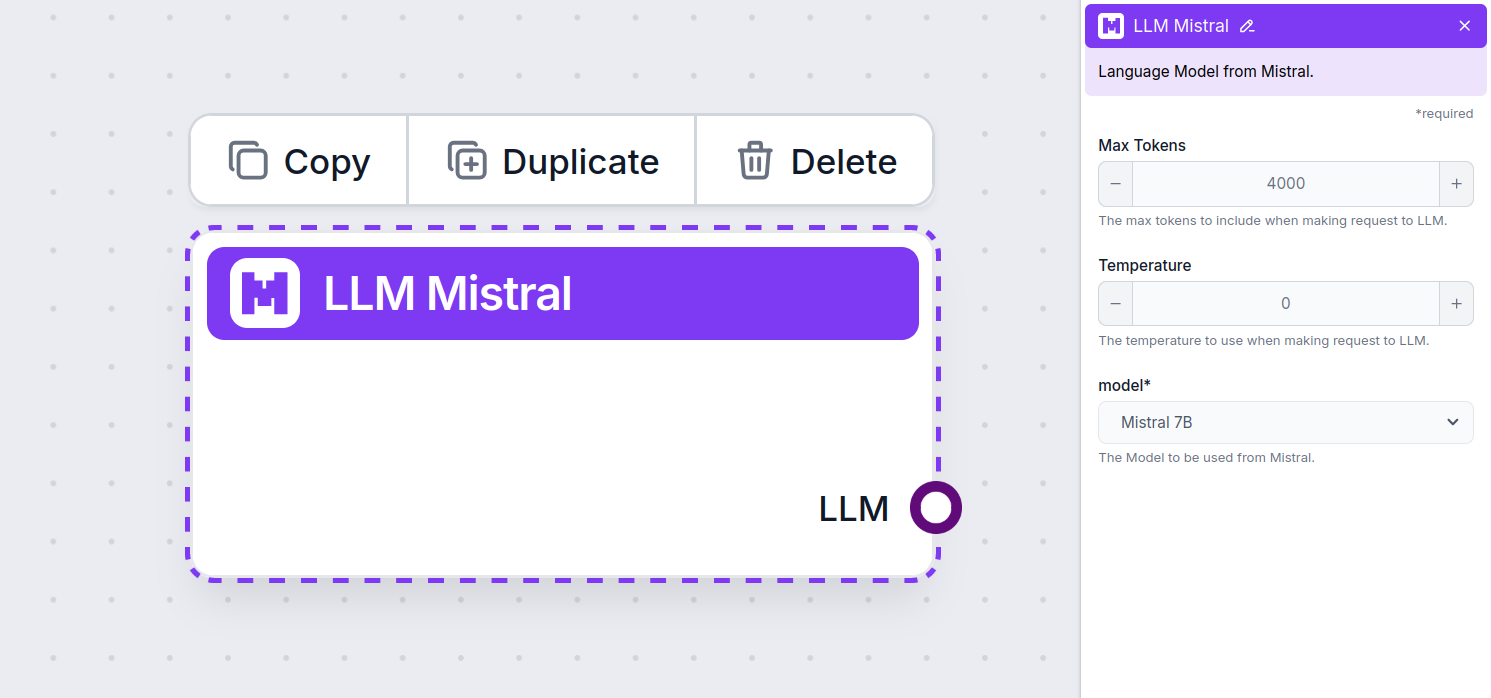
Innstillinger for LLM Mistral-komponenten
Maks tokens
Tokens representerer de individuelle enhetene av tekst som modellen prosesserer og genererer. Token-bruk varierer mellom modellene, og en enkelt token kan være alt fra ord eller delord til et enkelt tegn. Modeller prises vanligvis i millioner av tokens.
Innstillingen for maks tokens begrenser det totale antallet tokens som kan behandles i én enkelt interaksjon eller forespørsel, og sikrer at svarene genereres innenfor rimelige rammer. Standardgrensen er 4 000 tokens, som er optimal størrelse for å oppsummere dokumenter og flere kilder til å generere et svar.
Temperatur
Temperatur kontrollerer variasjonen i svarene, og går fra 0 til 1.
En temperatur på 0,1 gjør svarene svært presise, men potensielt repeterende og mangelfulle.
En høy temperatur på 1 tillater maksimal kreativitet i svarene, men øker risikoen for irrelevante eller til og med hallusinerte svar.
For eksempel er anbefalt temperatur for en kundeservicebot mellom 0,2 og 0,5. Dette nivået bør holde svarene relevante og til punktet, samtidig som det gir naturlig variasjon i responsene.
Modell
Dette er modellvelgeren. Her finner du alle støttede modeller fra Mistral. Vi støtter for øyeblikket følgende modeller:
- Mistral 7B – En språkmodell med 7,3 milliarder parametere som bruker transformers-arkitekturen, utgitt under Apache 2.0-lisensen. Til tross for at det er et mindre prosjekt, overgår den jevnlig Meta’s Llama 2-modell. Sjekk hvordan den presterte i våre tester.
- Mistral 8x7B (Mixtral) – Denne modellen bruker en sparse mixture of experts-arkitektur, bestående av åtte distinkte grupper av “eksperter”, totalt 46,7 milliarder parametere. Hver token bruker opptil 12,9 milliarder parametere, og tilbyr ytelse som matcher eller overgår LLaMA 2 70B og GPT-3.5 på de fleste benchmarks. Se eksempler på output.
- Mistral Large – En høyytelses språkmodell med 123 milliarder parametere og en kontekstlengde på 128 000 tokens. Den er flytende på flere språk, inkludert programmeringsspråk, og viser konkurransedyktig ytelse sammenlignet med modeller som LLaMA 3.1 405B, spesielt på programmeringsrelaterte oppgaver. Les mer her.
Hvordan legge til LLM Mistral i din flow
Du vil merke at alle LLM-komponenter kun har et output-håndtak. Input går ikke gjennom komponenten, da den kun representerer modellen, mens selve genereringen skjer i AI-agenter og Generatorer.
LLM-håndtaket er alltid lilla. LLM input-håndtaket finnes på enhver komponent som bruker AI til å generere tekst eller prosessere data. Du kan se alternativene ved å klikke på håndtaket:
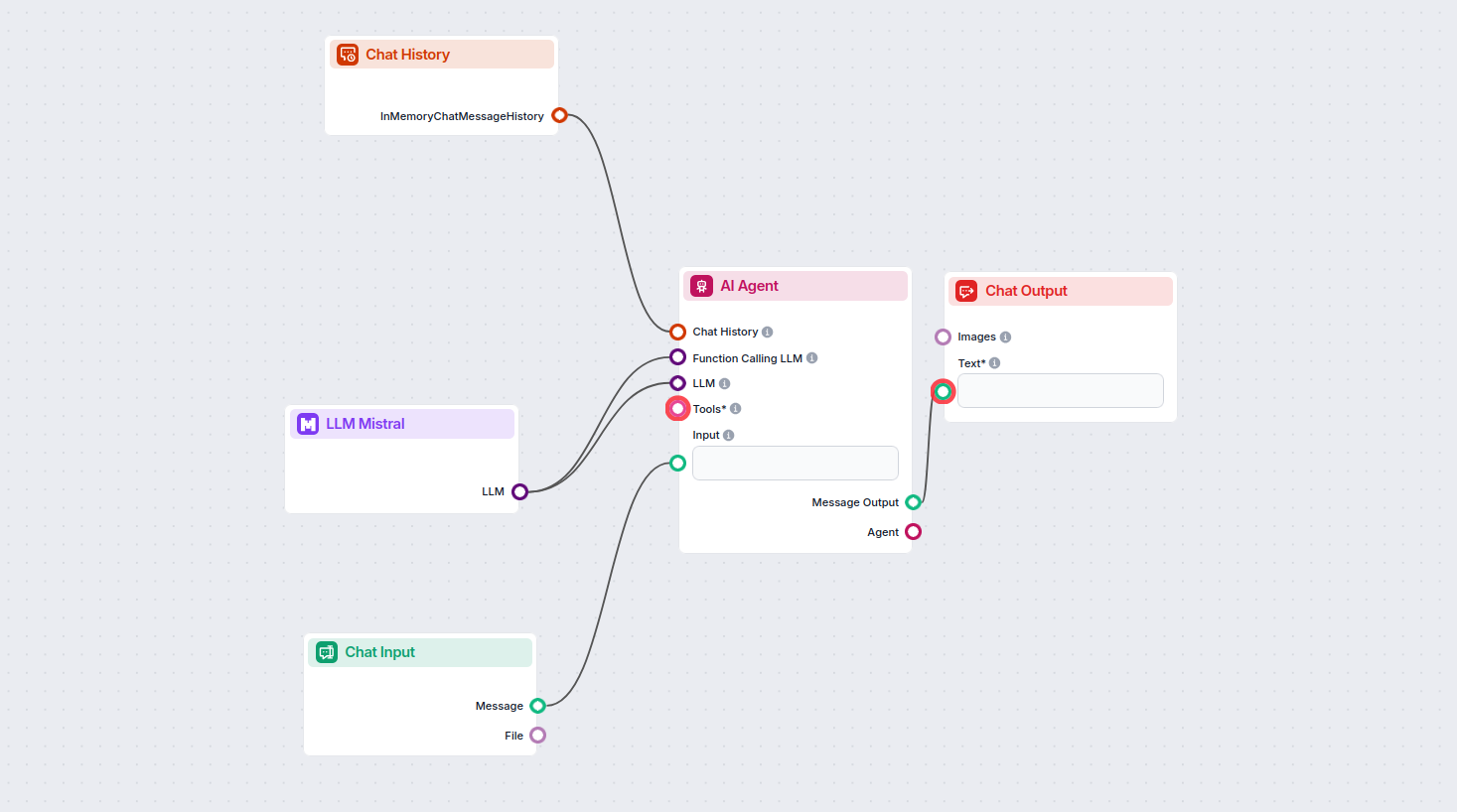
Dette gir deg mulighet til å lage alle slags verktøy. La oss se komponenten i aksjon. Her er en enkel AI Agent Chatbot Flow som bruker Mistral 7B-modellen til å generere svar. Du kan tenke på det som en grunnleggende Mistral-chatbot.
Denne enkle Chatbot Flow inkluderer:
- Chat input: Representerer meldingen en bruker sender i chatten.
- Chat history: Sikrer at chatboten kan huske og ta hensyn til tidligere svar.
- Chat output: Representerer chatbotens endelige svar.
- AI Agent: En autonom AI-agent som genererer svar.
- LLM Mistral: Tilkoblingen til Mistral’s tekstgenereringsmodeller.