
LLM jako soudce pro hodnocení AI
Komplexní průvodce používáním velkých jazykových modelů jako soudců pro hodnocení AI agentů a chatbotů. Seznamte se s metodologií LLM jako soudce, osvědčenými p...
8 min čtení
AI
LLM
+10

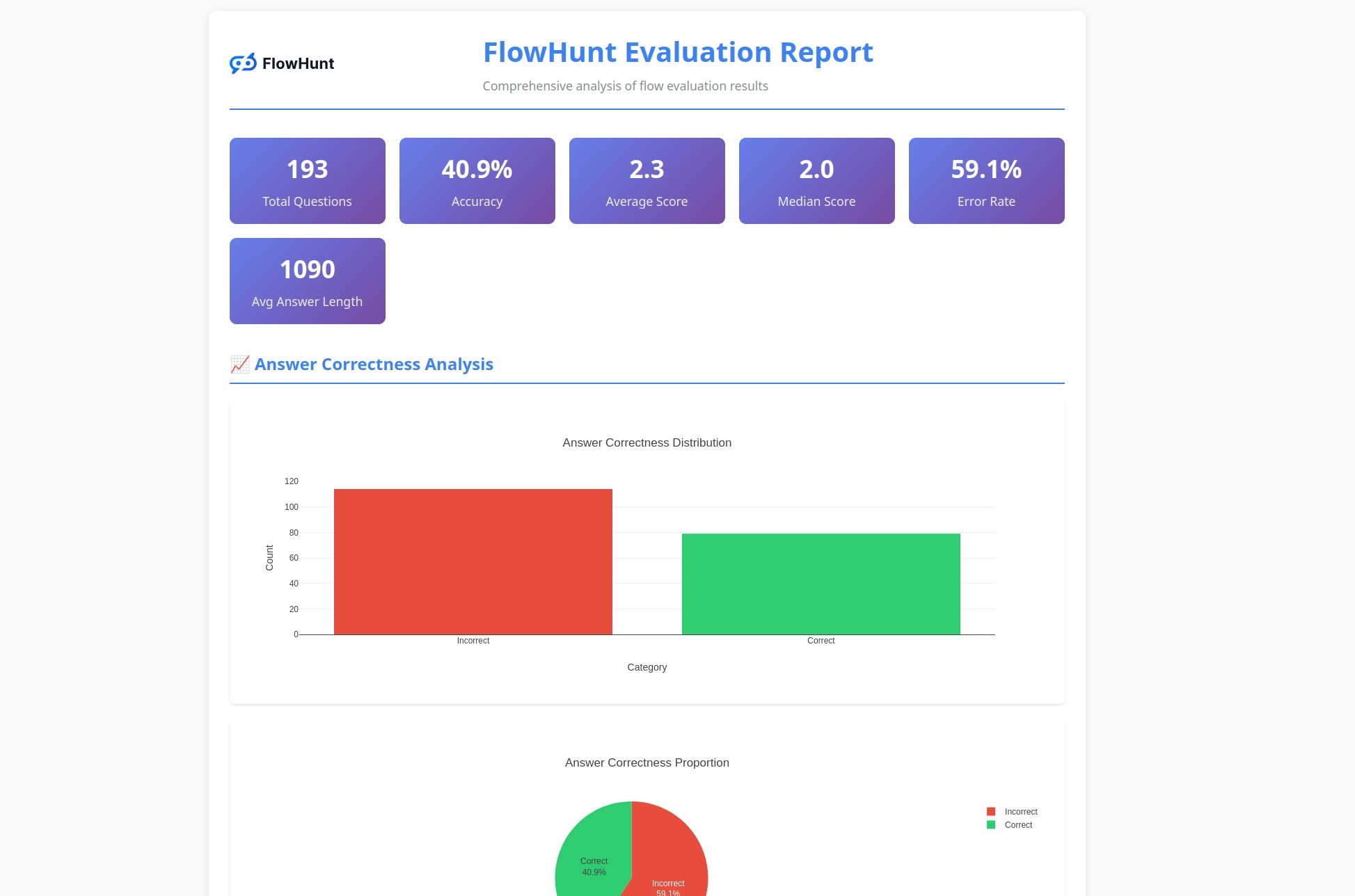
Nový open-source CLI nástroj od FlowHunt umožňuje komplexní hodnocení toků s LLM jako soudcem a poskytuje detailní reporty a automatizované posouzení kvality AI workflow.
S radostí oznamujeme vydání FlowHunt CLI Toolkitu – našeho nového open-source příkazového nástroje, který má změnit způsob, jakým vývojáři hodnotí a testují AI toky. Tento výkonný nástroj přináší možnosti hodnocení toků na podnikové úrovni do open-source komunity, a to včetně pokročilého reportování a inovativní implementace „LLM jako soudce“.
FlowHunt CLI Toolkit představuje zásadní krok vpřed v testování a hodnocení AI workflow. Již nyní je dostupný na GitHubu a poskytuje vývojářům komplexní sadu nástrojů pro:
Toolkit je vyjádřením našeho závazku k transparentnosti a vývoji řízenému komunitou – pokročilé techniky hodnocení AI jsou tak dostupné vývojářům po celém světě.
Jednou z nejvíce inovativních vlastností našeho CLI toolkitu je implementace „LLM jako soudce“. Tento přístup využívá umělou inteligenci k vyhodnocení kvality a správnosti AI odpovědí – v podstatě hodnotí AI výkony jiné AI se sofistikovaným odůvodněním.
Unikátnost naší implementace spočívá v tom, že jsme samotné hodnoticí workflow vytvořili přímo ve FlowHunt. Tento meta-přístup ukazuje sílu a flexibilitu naší platformy a zároveň poskytuje robustní hodnoticí systém. Tok LLM jako soudce se skládá z několika propojených komponent:
1. Šablona promptu: Vytváří hodnoticí prompt se specifickými kritérii
2. Generátor strukturovaného výstupu: Vyhodnocuje prompt pomocí LLM
3. Parser dat: Formátuje strukturovaný výstup pro reportování
4. Chat výstup: Zobrazuje finální výsledky hodnocení
Jádrem systému LLM jako soudce je pečlivě navržený prompt, který zajišťuje konzistentní a spolehlivé hodnocení. Zde je základní šablona promptu, kterou používáme:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Tento prompt zaručuje, že LLM soudce poskytuje:
Začněte svou bezplatnou zkušební verzi ještě dnes a viďte výsledky během několika dní.
Naše workflow LLM jako soudce ukazuje sofistikovaný návrh AI workflow s využitím vizuálního builderu FlowHunt. Takto spolupracují jednotlivé komponenty:
Workflow začíná komponentou Chat Input, která přijímá hodnoticí požadavek obsahující jak skutečnou odpověď, tak referenční odpověď.
Komponenta Šablona promptu dynamicky sestaví hodnoticí prompt tím, že:
{target_response}{actual_response}Generátor strukturovaného výstupu zpracuje prompt pomocí vybraného LLM a vygeneruje strukturovaný výstup obsahující:
total_rating: Číselné skóre 1–4correctness: Binární klasifikace správně/špatněreasoning: Detailní vysvětlení hodnoceníKomponenta Parse Data formátuje strukturovaný výstup do čitelné podoby a Chat Output prezentuje finální výsledky hodnocení.
Systém LLM jako soudce přináší několik pokročilých funkcí, které jej činí mimořádně účinným pro hodnocení AI toků:
Na rozdíl od prostého porovnávání textů rozumí náš LLM soudce:
Škála 4 bodů umožňuje jemné rozlišení hodnocení:
Každé hodnocení obsahuje detailní odůvodnění, takže lze:
Získejte nejnovější tipy, trendy a nabídky zdarma.
CLI toolkit generuje detailní reporty, které poskytují akční poznatky o výkonnosti toků:
Připraveni začít hodnotit své AI workflow s profesionálními nástroji? Zde je postup:
Jednořádková instalace (doporučeno) pro macOS a Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Tímto se automaticky:
flowhunt do PATHManuální instalace:
# Naklonujte repozitář
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Instalace přes pip
pip install -e .
Ověření instalace:
flowhunt --help
flowhunt --version
1. Autentizace Nejprve se přihlaste ke svému FlowHunt API:
flowhunt auth
2. Výpis vašich toků
flowhunt flows list
3. Hodnocení toku Vytvořte CSV soubor s testovacími daty:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Spusťte hodnocení s LLM jako soudcem:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Dávkové spouštění toků
flowhunt batch-run your-flow-id input.csv --output-dir results/
Systém hodnocení poskytuje komplexní analýzu:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Funkce zahrnují:
CLI toolkit je plně integrován s platformou FlowHunt a umožňuje vám:
Vydání našeho CLI toolkitu znamená víc než jen nový nástroj – představuje vizi budoucnosti vývoje AI, kde:
Kvalita je měřitelná: Pokročilé hodnoticí techniky umožňují kvantifikovat a porovnávat výkon AI.
Testování je automatizované: Komplexní testovací frameworky snižují ruční práci a zvyšují spolehlivost.
Transparentnost je standardem: Detailní odůvodnění a reporty zpřehledňují a usnadňují ladění AI chování.
Komunita pohání inovaci: Open-source nástroje umožňují společný rozvoj a sdílení poznatků.
Tím, že FlowHunt CLI Toolkit vydáváme jako open-source, potvrzujeme náš závazek k:
FlowHunt CLI Toolkit s LLM jako soudcem představuje významný pokrok ve schopnostech hodnotit AI workflow. Spojením sofistikované logiky hodnocení s komplexním reportováním a otevřenou dostupností dáváme vývojářům do rukou nástroj pro tvorbu lepších a spolehlivějších AI systémů.
Meta-přístup využití FlowHunt pro hodnocení toků vytvářených ve FlowHunt dokazuje vyspělost a flexibilitu naší platformy a zároveň přináší silný nástroj širší AI komunitě.
Ať už stavíte jednoduché chatboty nebo komplexní multi-agentní systémy, FlowHunt CLI Toolkit vám poskytne potřebnou infrastrukturu pro hodnocení kvality, spolehlivosti i kontinuálního zlepšování.
Připraveni pozvednout hodnocení svých AI workflow? Navštivte náš GitHub repozitář , začněte s FlowHunt CLI Toolkit ještě dnes a zažijte sílu LLM jako soudce na vlastní kůži.
Budoucnost vývoje AI je tady – a je open source.
FlowHunt CLI Toolkit je open-source příkazový nástroj pro hodnocení AI toků s komplexními reportovacími možnostmi. Obsahuje funkce jako hodnocení LLM jako soudce, analýzu správných/špatných výsledků a detailní výkonnostní metriky.
LLM jako soudce využívá sofistikovaný AI tok postavený ve FlowHunt ke zhodnocení dalších toků. Porovnává skutečné odpovědi s referenčními, poskytuje hodnocení, posouzení správnosti a detailní odůvodnění pro každé zhodnocení.
FlowHunt CLI Toolkit je open-source a dostupný na GitHubu na https://github.com/yasha-dev1/flowhunt-toolkit. Můžete jej klonovat, přispívat a volně používat pro své potřeby hodnocení AI toků.
Toolkit generuje komplexní reporty včetně rozboru správných/špatných výsledků, hodnocení LLM jako soudce s body a odůvodněním, výkonnostní metriky a detailní analýzu chování toků napříč různými testovacími případy.
Ano! Tok LLM jako soudce je vytvořen na platformě FlowHunt a lze jej přizpůsobit pro různé hodnoticí scénáře. Můžete měnit šablonu promptu i kritéria hodnocení dle vlastních potřeb.
Yasha je talentovaný softwarový vývojář specializující se na Python, Javu a strojové učení. Yasha píše technické články o AI, inženýrství promptů a vývoji chatbotů.

Vytvářejte a hodnoťte sofistikované AI workflow na platformě FlowHunt. Začněte tvořit toky, které dokážou hodnotit jiné toky, ještě dnes.
Komplexní průvodce používáním velkých jazykových modelů jako soudců pro hodnocení AI agentů a chatbotů. Seznamte se s metodologií LLM jako soudce, osvědčenými p...
Toky jsou mozkem všeho v FlowHunt. Naučte se je vytvářet pomocí vizuálního builderu bez kódu – od umístění prvního komponentu až po integraci na web, nasazení c...

Tento článek vysvětluje, jak propojit FlowHunt s Langfuse pro komplexní observabilitu, sledovat výkon AI workflow a využívat dashboardy Langfuse k monitorování ...