Stort sprogmodel (LLM)
En stor sprogmodel (LLM) er en type AI, der er trænet på enorme tekstmængder for at forstå, generere og manipulere menneskesprog. LLM'er bruger dyb læring og tr...
8 min læsning
AI
Large Language Model
+4

FlowHunt tester og rangerer førende LLMs – herunder GPT-4, Claude 3, Llama 3 og Grok – til indholdsforfatning, hvor der vurderes læsbarhed, tone, originalitet og brug af søgeord for at hjælpe dig med at vælge den bedste model til dine behov.
Large Language Models (LLMs) er banebrydende AI-værktøjer, der ændrer den måde, vi skaber og forbruger indhold på. Før vi går dybere ind i forskellene mellem de enkelte LLMs, bør du forstå, hvad der gør det muligt for disse modeller at skabe menneskelignende tekst så ubesværet.
LLMs er trænet på enorme datasæt, hvilket hjælper dem med at forstå kontekst, semantik og syntaks. Baseret på mængden af data kan de korrekt forudsige det næste ord i en sætning og samle ordene til forståeligt skrift. En af grundene til deres effektivitet er transformerarkitekturen. Denne self-attention-mekanisme bruger neurale netværk til at behandle tekstsyntaks og semantik. Det betyder, at LLMs kan håndtere en bred vifte af komplekse opgaver med lethed.
Large Language Models (LLMs) har forvandlet den måde, virksomheder griber indholdsskabelse an på. Med evnen til at producere personligt tilpasset og optimeret tekst genererer LLMs indhold som e-mails, landingssider og opslag på sociale medier ud fra menneskelige tekstbeskeder.
Her er, hvad LLMs kan hjælpe indholdsforfattere med:
Desuden ser fremtiden for LLMs lovende ud. Teknologiske fremskridt vil sandsynligvis forbedre deres nøjagtighed og multimodale evner. Denne udvidelse af anvendelsesmuligheder vil få stor betydning for forskellige brancher.
Start din gratis prøveperiode i dag og se resultater inden for få dage.
Her er et hurtigt overblik over de populære LLMs, vi vil teste:
| Model | Unikke styrker |
|---|---|
| GPT-4 | Alsidig i forskellige skrivestile |
| Claude 3 | Udmærker sig i kreative og kontekstuelle opgaver |
| Llama 3.2 | Kendt for effektiv tekstsammenfatning |
| Grok | Kendt for fokus på en afslappet og humoristisk tone |
Når du vælger en LLM, er det vigtigt at overveje dine behov for indholdsskabelse. Hver model byder på noget unikt – fra håndtering af komplekse opgaver til generering af AI-drevet kreativt indhold. Før vi tester dem, lad os kort opsummere hver enkelt for at se, hvordan den kan gavne din proces med indholdsskabelse.
Nøglefunktioner:
Performance-målinger:
Styrker:
Udfordringer:
Samlet set er GPT-4 et stærkt værktøj for virksomheder, der vil styrke deres indholdsskabelse og dataanalyse.
Nøglefunktioner:
Styrker:
Udfordringer:
Nøglefunktioner:
Styrker:
Udfordringer:
Llama 3 skiller sig ud som en robust og alsidig open-source LLM, der lover fremskridt inden for AI, men også præsenterer visse udfordringer for brugerne.
Nøglefunktioner:
Styrker:
Udfordringer:
Sammenfattende har xAI Grok interessante funktioner og fordelen af medieeksponering, men den står over for betydelige udfordringer i popularitet og ydeevne på det konkurrenceprægede LLM-marked.
Lad os springe direkte til testen. Vi rangerer modellerne ud fra et simpelt blogindlægs-output. Alle tests er udført i FlowHunt, hvor kun LLM-modellen er ændret.
Fokusområder:
Testprompt:
Skriv et blogindlæg med titlen “10 nemme måder at leve bæredygtigt uden at sprænge budgettet.” Tonen skal være praktisk og imødekommende med fokus på handlingsorienterede tips, der er realistiske for travle mennesker. Fremhæv “bæredygtighed på budget” som hovedsøgeord. Inkluder eksempler fra hverdagssituationer som indkøb, energiforbrug og personlige vaner. Afslut med en opmuntrende call-to-action, hvor læseren opfordres til at starte med ét tip i dag.
Bemærk: Flow er begrænset til kun at skabe output på cirka 500 ord. Hvis du synes, outputtet virker forhastet eller ikke går i dybden, er det med vilje.
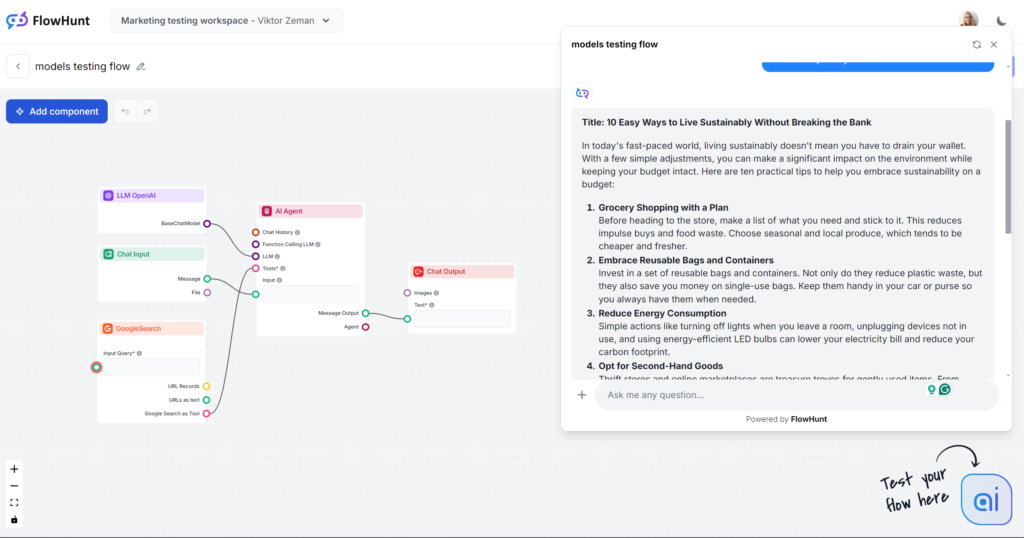
Hvis dette var en blindtest, ville åbningssætningen “In today’s fast-paced world…” straks afsløre modellen. Du kender sikkert denne models skrivestil, da det ikke kun er det mest populære valg, men også kernen i de fleste tredjeparts AI-skriveværktøjer. GPT-4o er altid et sikkert valg til generelt indhold, men vær forberedt på vaghed og ordrigdom.
Tone og sprog
Ser man bort fra den smertefuldt brugte åbningssætning, gjorde GPT-4o præcis det, vi forventede. Man vil ikke snyde nogen til at tro, at et menneske har skrevet det, men det er stadig et nogenlunde struktureret indlæg, der uden tvivl følger prompten. Tonen er faktisk praktisk og imødekommende og fokuserer straks på handlingsorienterede tips i stedet for vage udsagn.
Brug af søgeord
GPT-4o klarede sig godt i søgeordstesten. Ikke alene brugte den det angivne hovedsøgeord, men også beslægtede fraser og andre relevante søgeord.
Læsbarhed
På Flesch-Kincaid-skalaen ligger dette output på 10.-12. klassetrin (forholdsvis svært) med scoren 51,2. Ét point lavere placerer det på universitetsniveau. Med så kort output har selve ordet “bæredygtighed” sandsynligvis en mærkbar effekt på læsbarheden. Der er dog stadig plads til forbedring.
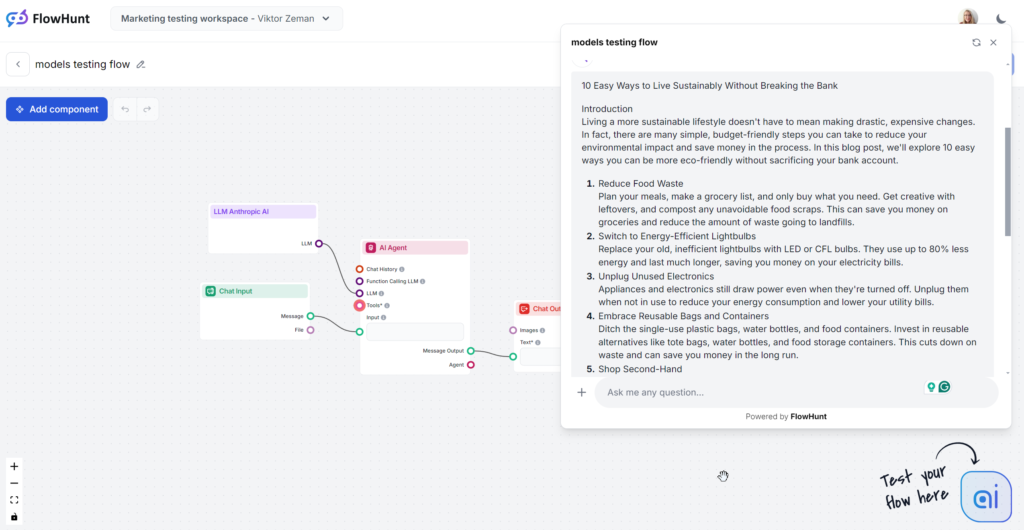
Den analyserede Claude-output er den mellemste Sonnet-model, som rygtes at være det bedste valg til indhold. Indholdet læses godt og er mærkbart mere menneskeligt end GPT-4o eller Llama. Claude er den perfekte løsning til rent og enkelt indhold, der leverer information effektivt uden at være så ordrig som GPT eller så prangende som Grok.
Tone og sprog
Claude skiller sig ud med sine enkle, relaterbare og menneskelignende svar. Tonen er praktisk og imødekommende og fokuserer straks på handlingsorienterede tips frem for vage udsagn.
Brug af søgeord
Claude var den eneste model, der ignorerede søgeordsdelen af prompten og kun brugte det 1 ud af 3 gange. Når søgeordet blev inkluderet, var det i konklusionen, og brugen føltes lidt tvunget.
Læsbarhed
Claude’s Sonnet scorede højt på Flesch-Kincaid-skalaen og placerede sig på 8.-9. klassetrin (almindeligt engelsk), kun et par point efter Grok. Hvor Grok ændrede hele tonen og vokabulariet for at opnå dette, brugte Claude et lignende ordforråd som GPT-4o. Hvad gjorde læsbarheden så god? Kortere sætninger, hverdagsord og intet vagt indhold.
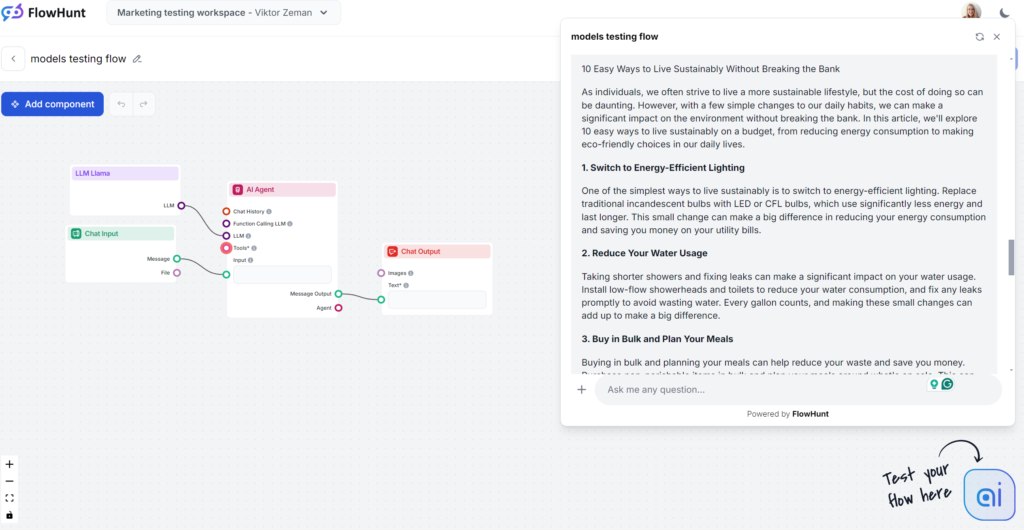
Llamas stærkeste punkt var brugen af søgeord. Omvendt var skrivestilen uinspireret og lidt ordrig, men stadig mindre kedelig end GPT-4o. Llama er som GPT-4o’s fætter – et sikkert indholdsvalg med en lidt ordrig og vag skrivestil. Det er et godt valg, hvis du generelt kan lide OpenAI-modellernes skrivestil, men vil undgå de klassiske GPT-fraser.
Tone og sprog
Llama-genererede artikler minder meget om dem fra GPT-4o. Ordrigheden og vagheden er sammenlignelig, men tonen er praktisk og imødekommende.
Brug af søgeord
Meta vinder søgeordstesten. Llama brugte søgeordet flere gange – også i introduktionen – og inkluderede naturligt beslægtede fraser og andre relevante søgeord.
Læsbarhed
På Flesch-Kincaid-skalaen ligger outputtet på 10.-12. klassetrin (forholdsvis svært) med scoren 53,4, kun lidt bedre end GPT-4o (51,2). Med så kort output har selve ordet “bæredygtighed” sandsynligvis en mærkbar effekt på læsbarheden. Der er stadig plads til forbedring.
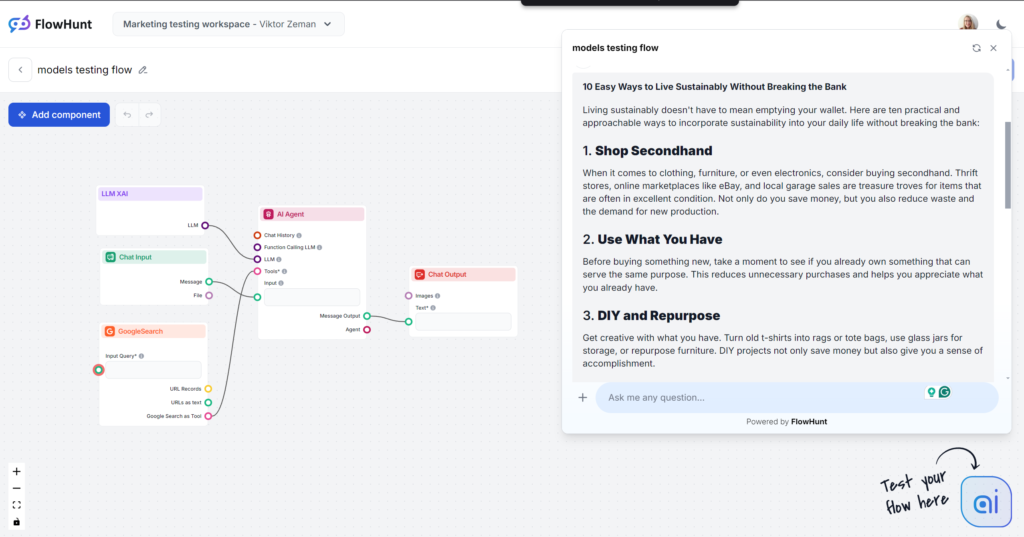
Grok var en stor overraskelse, især på tone og sprog. Med en meget naturlig og afslappet tone føltes det, som om du fik hurtige tips fra en nær ven. Hvis afslappet og frisk er din skrivestil, er Grok bestemt valget for dig.
Tone og sprog
Outputtet læses rigtig godt. Sproget er naturligt, sætningerne er korte, og Grok bruger idiomer effektivt. Modellen holder sig til sin primære tone og skubber grænserne for menneskelignende tekst. Bemærk: Groks afslappede tone er ikke altid et godt valg til B2B- og SEO-drevet indhold.
Brug af søgeord
Grok brugte det ønskede søgeord, men kun i konklusionen. Andre modeller placerede søgeordene bedre og tilføjede flere relevante søgeord, mens Grok fokuserede mere på sprogets flow.
Læsbarhed
Med det lette sprog bestod Grok Flesch-Kincaid-testen med bravur. Den scorede 61,4, hvilket svarer til 7.-8. klassetrin (almindeligt engelsk). Det er optimalt for at gøre emner tilgængelige for den brede befolkning. Dette store spring i læsbarhed er næsten mærkbart.
Få de seneste tips, trends og tilbud gratis.
LLMs’s styrke afhænger af kvaliteten af træningsdata, som til tider kan være biased eller unøjagtige og føre til spredning af misinformation. Det er afgørende at faktatjekke og kvalitetssikre AI-genereret indhold for retfærdighed og inklusion. Når du eksperimenterer med forskellige modeller, skal du huske, at hver model har sin egen tilgang til dataprivatliv og begrænsning af skadeligt output.
For at styre etisk brug bør organisationer etablere rammer for dataprivatliv, bias-reduktion og indholdsmoderation. Dette inkluderer løbende dialog mellem AI-udviklere, forfattere og juridiske eksperter. Overvej disse etiske bekymringer:
Valget af LLM bør etisk matche organisationens indholdspolitik. Både open source- og proprietære modeller bør vurderes for potentiel misbrug.
Bias, unøjagtighed og hallucinationer er fortsat store problemer i AI-genereret indhold. Takket være indbyggede retningslinjer resulterer det ofte i vage, lavværdige output fra LLMs. Virksomheder har ofte brug for ekstra træning og sikkerhedsforanstaltninger for at håndtere disse problemer. For små virksomheder er der sjældent tid eller ressourcer til specialtræning. Et alternativ er at tilføje disse evner ved at bruge generelle modeller via tredjepartsværktøjer som FlowHunt.
FlowHunt lader dig tilføje specifik viden, internetadgang og nye evner til klassiske basismodeller. På den måde kan du vælge den rette model til opgaven uden begrænsninger fra basismodellen eller utallige abonnementer.
En anden stor udfordring er modellernes kompleksitet. Med milliarder af parametre kan de være svære at håndtere, forstå og fejlfinde. FlowHunt giver dig meget mere kontrol end almindelige tekstprompter til chat nogensinde kan. Du kan tilføje individuelle evner som blokke og justere dem, så du skaber dit bibliotek af færdige AI-værktøjer.
Fremtiden for sprogmodeller (LLMs) i indholdsforfatning er lovende og spændende. Efterhånden som modellerne udvikler sig, lover de større nøjagtighed og mindre bias i indholdsgenereringen. Det betyder, at forfattere vil kunne skabe pålidelig, menneskelignende tekst med AI-genereret indhold.
LLMs vil ikke kun håndtere tekst, men også blive dygtige til multimodal indholdsskabelse. Det inkluderer både tekst og billeder, hvilket styrker kreativt indhold til forskellige brancher. Med større og bedre datasæt vil LLMs skabe mere pålideligt indhold og forfine skrivestile.
Men indtil videre kan LLMs ikke gøre dette selv, og disse evner er fordelt mellem forskellige virksomheder og modeller, der alle kæmper om din opmærksomhed og dine penge. FlowHunt samler dem alle og lader
GPT-4 er den mest populære og alsidige til generelt indhold, men Metas Llama tilbyder en friskere skrivestil. Claude 3 er bedst til rent, simpelt indhold, mens Grok udmærker sig med en afslappet, menneskelig tone. Det bedste valg afhænger af dine indholdsmål og stilpræferencer.
Overvej læsbarhed, tone, originalitet, brug af søgeord, og hvordan hver model matcher dine indholdsbehov. Vej også styrker som kreativitet, genrealsidighed eller integrationsmuligheder, og vær opmærksom på udfordringer som bias, ordrigdom eller ressourcekrav.
FlowHunt lader dig teste og sammenligne flere førende LLMs i ét miljø, hvilket giver dig kontrol over output og gør det muligt at finde den bedste model til din specifikke indholdsarbejdsgang uden flere abonnementer.
Ja. LLMs kan videreføre bias, generere misinformation og rejse bekymringer om databeskyttelse. Det er vigtigt at faktatjekke AI-output, vurdere modeller for etisk overensstemmelse og opstille rammer for ansvarlig brug.
Fremtidige LLMs vil byde på forbedret nøjagtighed, mindre bias og multimodal indholdsgenerering (tekst, billeder osv.), så forfattere kan skabe mere pålideligt og kreativt indhold. Samlede platforme som FlowHunt vil gøre adgang til disse avancerede muligheder lettere.
Oplev top LLMs side om side og forbedr dit workflow for indholdsforfatning med FlowHunt’s samlede platform.
En stor sprogmodel (LLM) er en type AI, der er trænet på enorme tekstmængder for at forstå, generere og manipulere menneskesprog. LLM'er bruger dyb læring og tr...
Tekstgenerering med store sprogmodeller (LLM'er) refererer til den avancerede brug af maskinlæringsmodeller til at producere menneskelignende tekst ud fra promp...
Sprogdtektering i store sprogmodeller (LLM'er) er processen, hvorved disse modeller identificerer sproget i inputteksten, hvilket muliggør nøjagtig behandling t...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.