
FlowHunt 2.4.1 bringer Claude, Grok, Llama og mere
FlowHunt 2.4.1 introducerer store nye AI-modeller, herunder Claude, Grok, Llama, Mistral, DALL-E 3 og Stable Diffusion, hvilket udvider dine muligheder for eksp...
2 min læsning
AI
LLM
+7

FlowHunts nye open source CLI-værktøj muliggør omfattende flow-evaluering med LLM som Dommer, og tilbyder detaljeret rapportering og automatiseret kvalitetsvurdering af AI-arbejdsgange.
Vi er glade for at kunne annoncere lanceringen af FlowHunt CLI Toolkit – vores nye open source kommandolinjeværktøj, der er designet til at revolutionere, hvordan udviklere evaluerer og tester AI-flows. Dette kraftfulde toolkit bringer enterprise-grade flow-evalueringsmuligheder til open source-fællesskabet, komplet med avanceret rapportering og vores innovative “LLM som Dommer”-implementering.
FlowHunt CLI Toolkit repræsenterer et markant skridt fremad inden for test og evaluering af AI-arbejdsgange. Værktøjet er nu tilgængeligt på GitHub , og dette open source-toolkit giver udviklere omfattende værktøjer til:
Værktøjet er et udtryk for vores engagement i gennemsigtighed og fællesskabsdrevet udvikling, og gør avancerede AI-evalueringsmetoder tilgængelige for udviklere verden over.
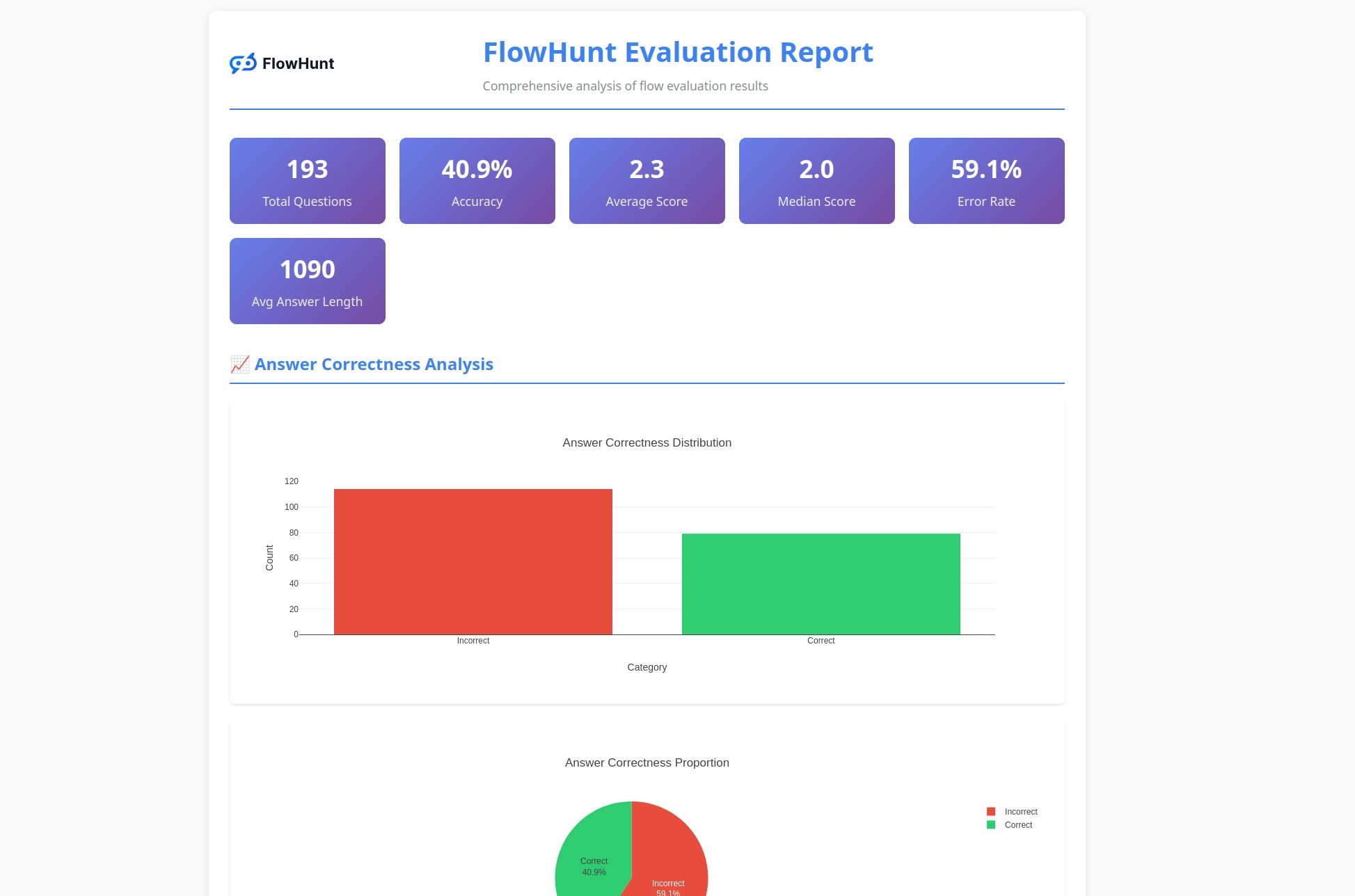
En af de mest innovative funktioner i vores CLI-toolkit er implementeringen af “LLM som Dommer”. Denne tilgang bruger kunstig intelligens til at evaluere kvaliteten og korrektheden af AI-genererede svar – altså lader vi AI vurdere AI’s præstation med sofistikerede begrundelsesmuligheder.
Det unikke ved vores implementering er, at vi brugte FlowHunt selv til at skabe evaluerings-flowet. Denne meta-tilgang demonstrerer platformens styrke og fleksibilitet, samtidig med at den leverer et robust evalueringssystem. LLM som Dommer-flowet består af flere sammenhængende komponenter:
1. Prompt-skabelon: Udarbejder evalueringsprompten med specifikke kriterier
2. Struktur-outputgenerator: Behandler evalueringen med en LLM
3. Dataparsing: Formaterer det strukturerede output til rapportering
4. Chat-output: Præsenterer de endelige evalueringsresultater
Kernen i vores LLM som Dommer-system er en omhyggeligt udformet prompt, der sikrer ensartede og pålidelige evalueringer. Her er den centrale prompt-skabelon, vi bruger:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Denne prompt sikrer, at vores LLM-dommer leverer:
Start din gratis prøveperiode i dag og se resultater inden for få dage.
Vores LLM som Dommer-flow demonstrerer sofistikeret AI-arbejdsgangsdesign gennem FlowHunts visuelle flow-builder. Sådan arbejder komponenterne sammen:
Flowet starter med en Chat Input-komponent, der modtager evalueringsanmodningen med både faktiske og reference-svar.
Prompt-skabelonen bygger dynamisk evalueringsprompten ved at:
{target_response}-pladsen{actual_response}-pladsenStruktur-outputgeneratoren behandler prompten med en valgt LLM og genererer struktureret output med:
total_rating: Numerisk score fra 1-4correctness: Binær korrekt/ukorrekt-klassificeringreasoning: Detaljeret forklaring på evalueringenParse Data-komponenten formaterer det strukturerede output til et læsbart format, og Chat Output-komponenten præsenterer de endelige evalueringsresultater.
LLM som Dommer-systemet tilbyder en række avancerede muligheder, der gør det særligt effektivt til AI flow-evaluering:
I modsætning til simpel strengsammenligning forstår vores LLM-dommer:
Den 4-punktsskala giver granulær evaluering:
Hver evaluering indeholder detaljeret begrundelse, hvilket gør det muligt at:
Få de seneste tips, trends og tilbud gratis.
CLI-toolkit’et genererer detaljerede rapporter, der giver konkrete indsigter i flow-præstation:
Klar til at evaluere dine AI-flows med professionelle værktøjer? Sådan kommer du i gang:
One-line installation (anbefalet) til macOS og Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Dette vil automatisk:
flowhunt-kommandoen til din PATHManuel installation:
# Klon repository
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Installer med pip
pip install -e .
Verificér installationen:
flowhunt --help
flowhunt --version
1. Autentificering
Først skal du autentificere med din FlowHunt API:
flowhunt auth
2. List dine flows
flowhunt flows list
3. Evaluer et flow Opret en CSV-fil med dine testdata:
flow_input,expected_output
"Hvad er 2+2?","4"
"Hvad er hovedstaden i Frankrig?","Paris"
Kør evaluering med LLM som Dommer:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Batchkør flows
flowhunt batch-run your-flow-id input.csv --output-dir results/
Evalueringssystemet giver omfattende analyse:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Funktioner inkluderer:
CLI-toolkit’et integrerer problemfrit med FlowHunt-platformen, så du kan:
Lanceringen af vores CLI-toolkit er mere end blot et nyt værktøj – det er en vision for fremtidens AI-udvikling, hvor:
Kvalitet kan måles: Avancerede evalueringsmetoder gør AI-ydelse målbar og sammenlignelig.
Test er automatiseret: Omfattende testframeworks reducerer manuelt arbejde og øger pålideligheden.
Gennemsigtighed er standard: Detaljeret begrundelse og rapportering gør AI-adfærd forståelig og let at fejlfinde.
Fællesskabet driver innovation: Open source-værktøjer muliggør samarbejdende forbedring og vidensdeling.
Ved at open source FlowHunt CLI Toolkit viser vi vores engagement i:
FlowHunt CLI Toolkit med LLM som Dommer markerer en betydelig fremgang inden for AI flow-evalueringsmuligheder. Ved at kombinere avanceret evalueringslogik med omfattende rapportering og open source-tilgængelighed, giver vi udviklere mulighed for at bygge bedre og mere pålidelige AI-systemer.
Meta-tilgangen med at bruge FlowHunt til at evaluere FlowHunt-flows demonstrerer modenheden og fleksibiliteten i vores platform, samtidig med at det leverer et stærkt værktøj til det bredere AI-udviklingsfællesskab.
Uanset om du bygger simple chatbots eller komplekse multi-agent-systemer, leverer FlowHunt CLI Toolkit den evalueringsinfrastruktur, du har brug for, så du sikrer kvalitet, pålidelighed og kontinuerlig forbedring.
Klar til at løfte din AI flow-evaluering? Besøg vores GitHub-repository for at komme i gang med FlowHunt CLI Toolkit i dag, og oplev styrken ved LLM som Dommer selv.
Fremtiden for AI-udvikling er her – og den er open source.
FlowHunt CLI Toolkit er et open source kommandolinjeværktøj til evaluering af AI-flows med omfattende rapporteringsfunktioner. Det indeholder funktioner som LLM som Dommer-evaluering, korrekt/ukorrekt resultat-analyse og detaljerede performance-målinger.
LLM som Dommer bruger et sofistikeret AI-flow bygget i FlowHunt til at evaluere andre flows. Det sammenligner faktiske svar med referencesvar og giver bedømmelser, korrekthedsvurderinger og detaljerede begrundelser for hver evaluering.
FlowHunt CLI Toolkit er open source og tilgængelig på GitHub på https://github.com/yasha-dev1/flowhunt-toolkit. Du kan frit klone, bidrage til og bruge det til dine AI flow-evalueringsbehov.
Værktøjet genererer omfattende rapporter, herunder korrekt/ukorrekt resultatopdeling, LLM som Dommer-evalueringer med bedømmelser og begrundelser, performance-målinger og detaljeret analyse af flow-adfærd på tværs af forskellige testcases.
Ja! LLM som Dommer-flowet er bygget med FlowHunts platform og kan tilpasses til forskellige evalueringsscenarier. Du kan ændre prompt-skabelonen og evalueringskriterierne, så de passer til dine specifikke behov.
Yasha er en talentfuld softwareudvikler med speciale i Python, Java og maskinlæring. Yasha skriver tekniske artikler om AI, prompt engineering og udvikling af chatbots.

Byg og evaluer avancerede AI-arbejdsgange med FlowHunts platform. Start med at skabe flows, der kan bedømme andre flows i dag.
FlowHunt 2.4.1 introducerer store nye AI-modeller, herunder Claude, Grok, Llama, Mistral, DALL-E 3 og Stable Diffusion, hvilket udvider dine muligheder for eksp...
Flows er hjernen bag det hele i FlowHunt. Lær at bygge dem med en visuel no-code builder, fra at placere den første komponent til integration på hjemmesider, ud...

En omfattende guide til at bruge Large Language Models som dommere ved evaluering af AI-agenter og chatbots. Lær om LLM som dommer-metodologi, best practices fo...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.