
AI-agenter: Sådan tænker GPT 4o
Udforsk tankeprocesserne hos AI-agenter i denne omfattende evaluering af GPT-4o. Opdag, hvordan den præsterer på opgaver som indholdsgenerering, problemløsning ...
7 min læsning
AI
GPT-4o
+6

Et dybdegående kig på GPT-4.1’s ydeevne på tværs af standard AI-opgaver, med fokus på dens ræsonnement, effektivitet, praktiske anvendelser og ensartede outputkvalitet.
OpenAIs GPT-4.1 repræsenterer et betydeligt fremskridt inden for AI-evner med forbedringer i ræsonnement, værktøjsudnyttelse og outputkvalitet. Denne analyse undersøger GPT-4.1’s ydeevne på tværs af fem fundamentale opgavetyper for at give indsigt i dens praktiske evner og begrænsninger.
Følgende analyse er baseret på dokumenteret ydeevne fra GPT-4.1 på fem standard benchmark-opgaver:
For hver opgave vurderer vi GPT-4.1’s tilgang til problemløsning, værktøjsbrug, behandlingstid og outputkvalitet.
Da GPT-4.1 blev bedt om at generere indhold om bedste praksis for uddelegering af projektledelse, viste den en strømlinet tilgang:
Denne præstation antyder, at GPT-4.1 prioriterer effektivitet i indholdsgenerering og hurtigt bevæger sig fra informationsindsamling til syntese uden at afsløre mellemregninger.
Start din gratis prøveperiode i dag og se resultater inden for få dage.
Beregningen testede GPT-4.1’s evne til at løse et flerleddet forretningsproblem med omsætning, profit og strategisk planlægning.
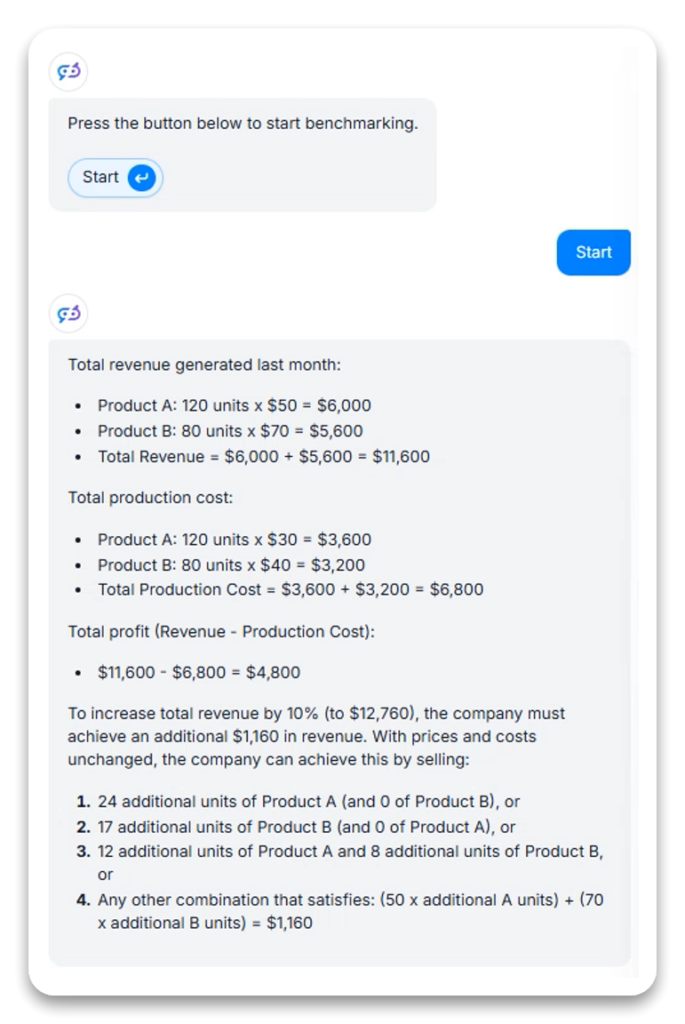
GPT-4.1’s tilgang til matematisk ræsonnement synes at fokusere på praktiske forretningsanvendelser frem for abstrakte matematiske relationer og leverer specifikke løsninger frem for generaliserede ligninger.
Opsummeringsopgaven afslørede GPT-4.1’s effektivitet i informationsdestillering:
Denne præstation viser GPT-4.1’s evne til hurtigt at udtrække og konsolidere essentiel information uden eksplicit ræsonnement for ligetil tekstbehandling.
Få de seneste tips, trends og tilbud gratis.
Ved sammenligningen mellem el- og brintdrevne køretøjer brugte GPT-4.1 sin mest omfattende researchproces:
Denne præstation peger på, at GPT-4.1 afsætter væsentlig mere behandlingstid til opgaver, der kræver dybdegående research og nuanceret sammenligning, hvor omfattende informationsindsamling prioriteres over hastighed.

Den kreative skriveopgave viste GPT-4.1’s tilgang til fantasifuld indholdsskabelse:
GPT-4.1’s kreative skrivning synes at bygge på systematisk research og organisering, før selve den kreative proces udfoldes, hvilket antyder et analytisk grundlag for de fantasifulde opgaver.
Analysen på tværs af de fem opgaver afslører flere gennemgående mønstre i, hvordan GPT-4.1 angriber forskellige problemtyper:
GPT-4.1 viser sjældent sin interne ræsonnementproces, men i stedet:
Denne tilgang prioriterer effektivitet, men mindsker gennemsigtigheden i, hvordan konklusionerne opnås.
Behandlingstiden varierer markant afhængigt af opgavens kompleksitet:
Dette antyder intelligent ressourceallokering efter opgavens krav.
På trods af variationer i behandlingsmetoder leverer GPT-4.1 ensartet høj outputkvalitet på tværs af opgavetyper:
Ved opgaver, der kræver specialviden, gør GPT-4.1 følgende:
Disse ydelseskarakteristika peger på flere optimale anvendelsesscenarier for GPT-4.1:
Modellens hurtige behandling af simple opgaver gør den velegnet til:
Villigheden til at bruge længere tid på informationsindsamling antyder potentiale til:
Fokus på praktisk anvendelse og flere løsningsveje giver værdi til:
GPT-4.1 demonstrerer en balanceret tilgang på tværs af forskellige opgavetyper, med særlige styrker inden for effektiv informationsbehandling og praktisk anvendelse. Dens evne til at tilpasse behandlingstiden efter opgavekompleksitet og samtidig opretholde konsekvent outputkvalitet gør den velegnet til en bred vifte af forretnings- og professionelle formål.
Modellens “black box”-tilgang til ræsonnement—hvor handlinger vises, men ikke mellemregninger—repræsenterer både en begrænsning i gennemsigtighed og en fordel i effektivitet. For de fleste praktiske anvendelser ser outputkvalitet og relevans dog ud til at opveje den reducerede synlighed i ræsonnementet.
Efterhånden som organisationer i stigende grad integrerer AI i arbejdsgange, placerer GPT-4.1’s kombination af effektivitet, tilpasningsevne og outputkvalitet sig som et værdifuldt værktøj for vidensarbejdere på tværs af brancher—særligt for dem, der prioriterer praktiske resultater over procesgennemsigtighed.
GPT-4.1 udmærker sig ved effektiv informationsbehandling, ensartet outputkvalitet og praktisk anvendelse på tværs af indholdsgenerering, beregninger, opsummering, sammenlignende analyse og kreativ skrivning. Den tilpasser behandlingstiden efter opgavens kompleksitet og leverer handlingsrettede, velstrukturerede resultater.
Ja, GPT-4.1 anvender ofte en 'black-box'-tilgang—den viser handlinger og output, men afslører ikke sine interne ræsonnementstrin. Selvom dette øger effektiviteten, reducerer det gennemsigtigheden i, hvordan konklusionerne nås.
GPT-4.1 er ideel til effektivitetskirtiske opgaver som indholdsproduktion, opsummering, rutineprægede forretningsberegninger, kladder til kreativ skrivning samt forskningsintensive opgaver som sammenlignende analyse, markedsundersøgelser og strategisk beslutningsstøtte.
Ved komplekse forsknings- og sammenligningsopgaver bruger GPT-4.1 betydeligt mere behandlingstid og udnytter sekventiel værktøjsbrug (som søgning og URL-crawling) til at indsamle og syntetisere information, hvilket sikrer omfattende og afbalancerede outputs.
Arshia er AI Workflow Engineer hos FlowHunt. Med en baggrund inden for datalogi og en passion for AI, specialiserer han sig i at skabe effektive workflows, der integrerer AI-værktøjer i daglige opgaver og øger produktivitet og kreativitet.

Oplev styrken ved AI-modeller som GPT-4.1 i dit workflow. Byg chatbots, automatisér opgaver og accelerér din forretning med FlowHunt.
Udforsk tankeprocesserne hos AI-agenter i denne omfattende evaluering af GPT-4o. Opdag, hvordan den præsterer på opgaver som indholdsgenerering, problemløsning ...

Udforsk de vigtigste funktioner, teknologiske fremskridt og virkelige konsekvenser af GPT-5. Denne guide dækker dens styrker, begrænsninger, prisfastsættelse, e...

Udforsk de avancerede evner hos GPT 4 Vision Preview AI Agent. Dette dybdegående indlæg afslører, hvordan den går ud over tekstgenerering og viser dens evner in...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.