Sådan bygger du brugerdefinerede vidensbase-sider i Hugo fra LiveAgent-tickets
Lær, hvordan du automatiserer oprettelsen af vidensbase-artikler i Hugo direkte fra kundesupport-tickets ved hjælp af AI-agenter og GitHub-integration.
Automation
Knowledge Base
Hugo
GitHub
AI Agents
Customer Support
Kundesupportteams genererer værdifuld indsigt hver eneste dag gennem deres interaktioner med kunderne. Disse spørgsmål, bekymringer og løsninger repræsenterer en guldgrube af information, som kunne gavne hele din brugerbase, hvis det blev dokumenteret korrekt. Men det er tidskrævende, gentagende og ofte lavt prioriteret at omdanne support-tickets manuelt til færdige vidensbase-artikler. Hvad nu hvis du kunne automatisere hele denne proces og forvandle rå kundehenvendelser til professionelt formaterede, SEO-optimerede vidensbase-sider, der vises direkte på dit website? Det er præcis, hvad moderne automatiserings-workflows nu gør muligt. Ved at forbinde dit LiveAgent-ticketsystem med Hugo statisk site-generator og GitHub versionskontrol kan du skabe en sammenhængende pipeline, der automatisk omdanner kundespørgsmål til søgbart og tilgængeligt vidensbase-indhold. I denne omfattende guide gennemgår vi, hvordan du bygger dette kraftfulde automationssystem, den tekniske arkitektur bag det, samt de konkrete skridt til at implementere det i din egen organisation.
Forstå vidensbase-automatisering
En vidensbase er et centraliseret informationsdepot, der hjælper brugere med at finde svar på almindelige spørgsmål uden at skulle kontakte support. Traditionelle vidensbaser bygges manuelt—supportteams skriver artikler, formaterer dem, optimerer dem til søgemaskiner og udgiver dem gennem et CMS. Denne proces er arbejdskrævende og skaber flaskehalse, især for voksende virksomheder med hundredvis af daglige supporthenvendelser. Vidensbase-automatisering ændrer dette paradigme ved at bruge kunstig intelligens til at udtrække relevant information fra support-tickets, strukturere det efter foruddefinerede skabeloner og udgive det direkte på dit website. Automationssystemet fungerer som en intelligent mellemmand mellem dit supportteam og dit website, identificerer hvilke tickets der indeholder viden, som andre brugere kan have gavn af, og forvandler så den rå support-samtale til professionel dokumentation. Denne tilgang sparer ikke kun tid, men sikrer også ensartethed i formatering, struktur og SEO-optimering på tværs af alle vidensbase-artikler. Systemet kan konfigureres til at forstå din virksomheds kontekst, undgå dubleret indhold og opretholde en sammenhængende vidensbase, der vokser organisk, efterhånden som dit supportteam håndterer flere henvendelser.
Klar til at vokse din virksomhed?
Start din gratis prøveperiode i dag og se resultater inden for få dage.
Hvorfor vidensbase-automatisering er vigtig for din virksomhed
Forretningscasen for vidensbase-automatisering er både overbevisende og mangesidet. For det første reducerer den drastisk antallet af supporthenvendelser, fordi kunderne kan finde svar selv. Undersøgelser viser konsekvent, at kunder foretrækker selvbetjening, når det er muligt og effektivt, og en velfungerende vidensbase kan reducere antallet af support-tickets med 20-30%. For det andet forbedres kundetilfredsheden ved at give øjeblikkelige svar på almindelige spørgsmål uden ventetid. For det tredje giver det markante SEO-fordele—vidensbase-artikler bliver indekseret af søgemaskiner og kan drive organisk trafik til dit website, øge synligheden og tiltrække nye kunder, der finder dit indhold via søgning. For det fjerde indfanger det virksomhedsviden, som ellers ville gå tabt, hvis medarbejdere forlader organisationen. Hver supportinteraktion indeholder værdifuld kontekst og løsninger, som, når de dokumenteres, bliver en del af virksomhedens permanente viden. For det femte kan dit supportteam fokusere på komplekse og værdiskabende opgaver i stedet for at besvare de samme spørgsmål gentagne gange. Når du automatiserer oprettelsen af vidensbase-indhold fra support-tickets, skaber du i realiteten en kraftforstærker for din supportorganisation. Den tid, dit team bruger på at svare på spørgsmål, bliver til dokumenteret viden, der hjælper tusindvis af fremtidige kunder. Endelig giver det værdifuld indsigt i, hvad dine kunder kæmper med, hvilket kan informere produktudvikling, markedsføring og kundeuddannelse.
Arkitekturen bag automatiseret vidensbase-generering
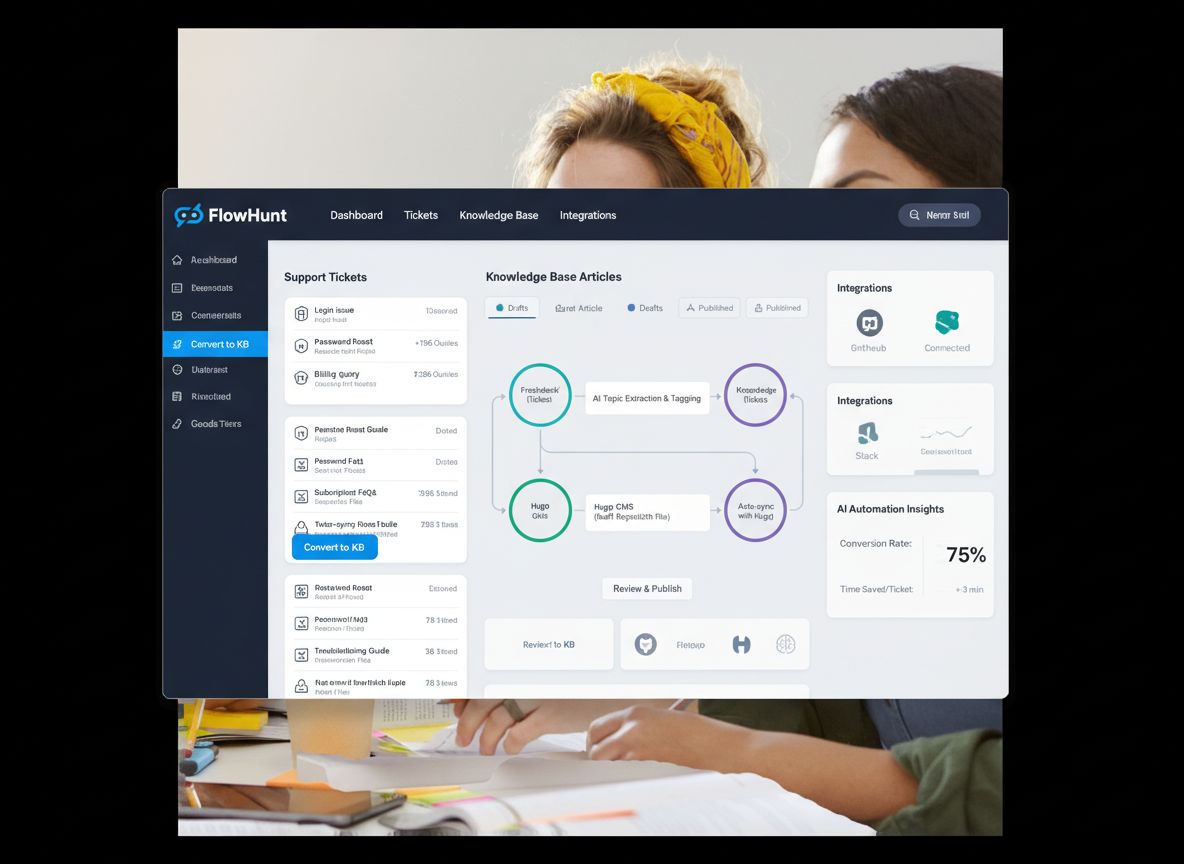
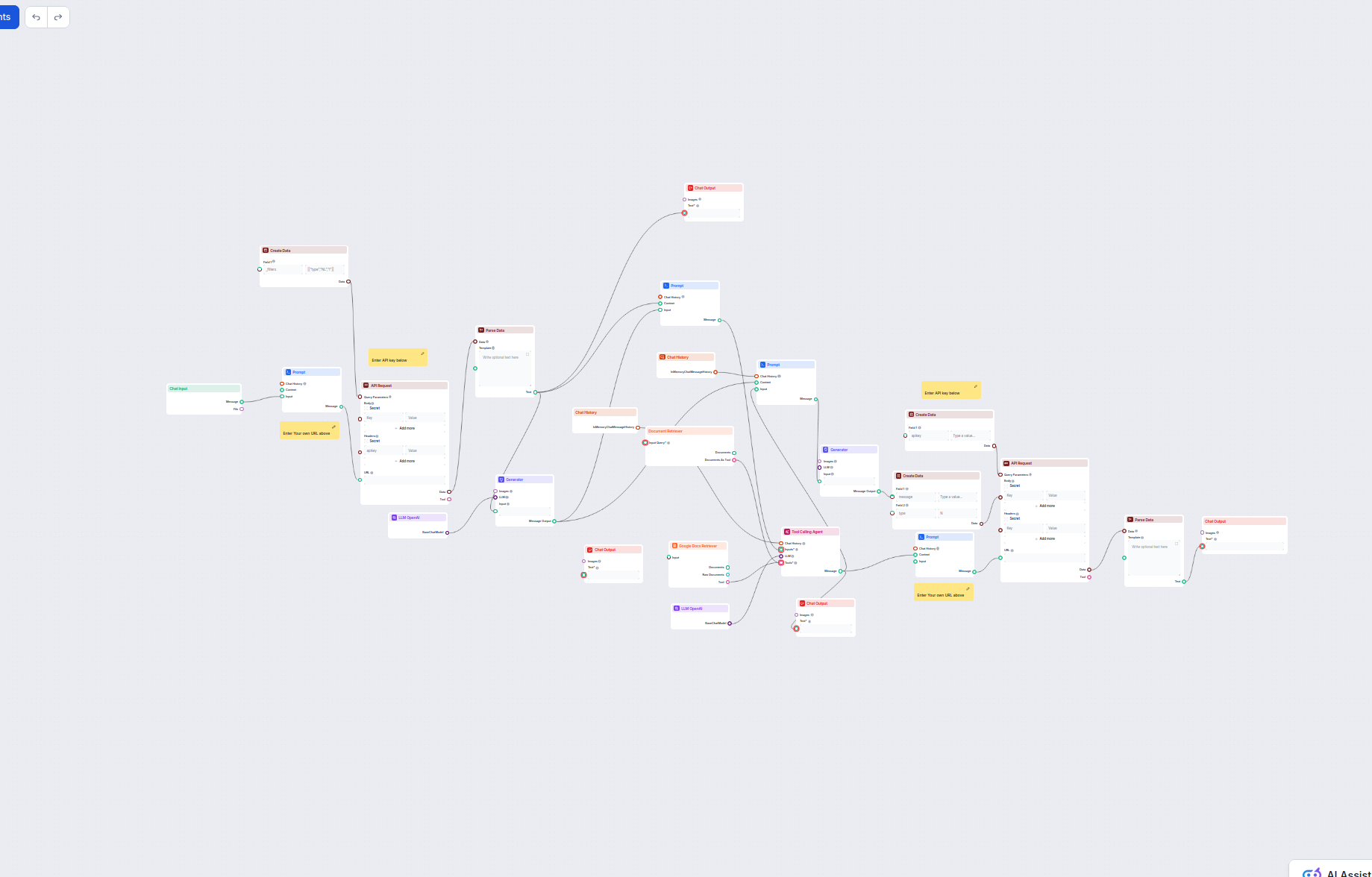
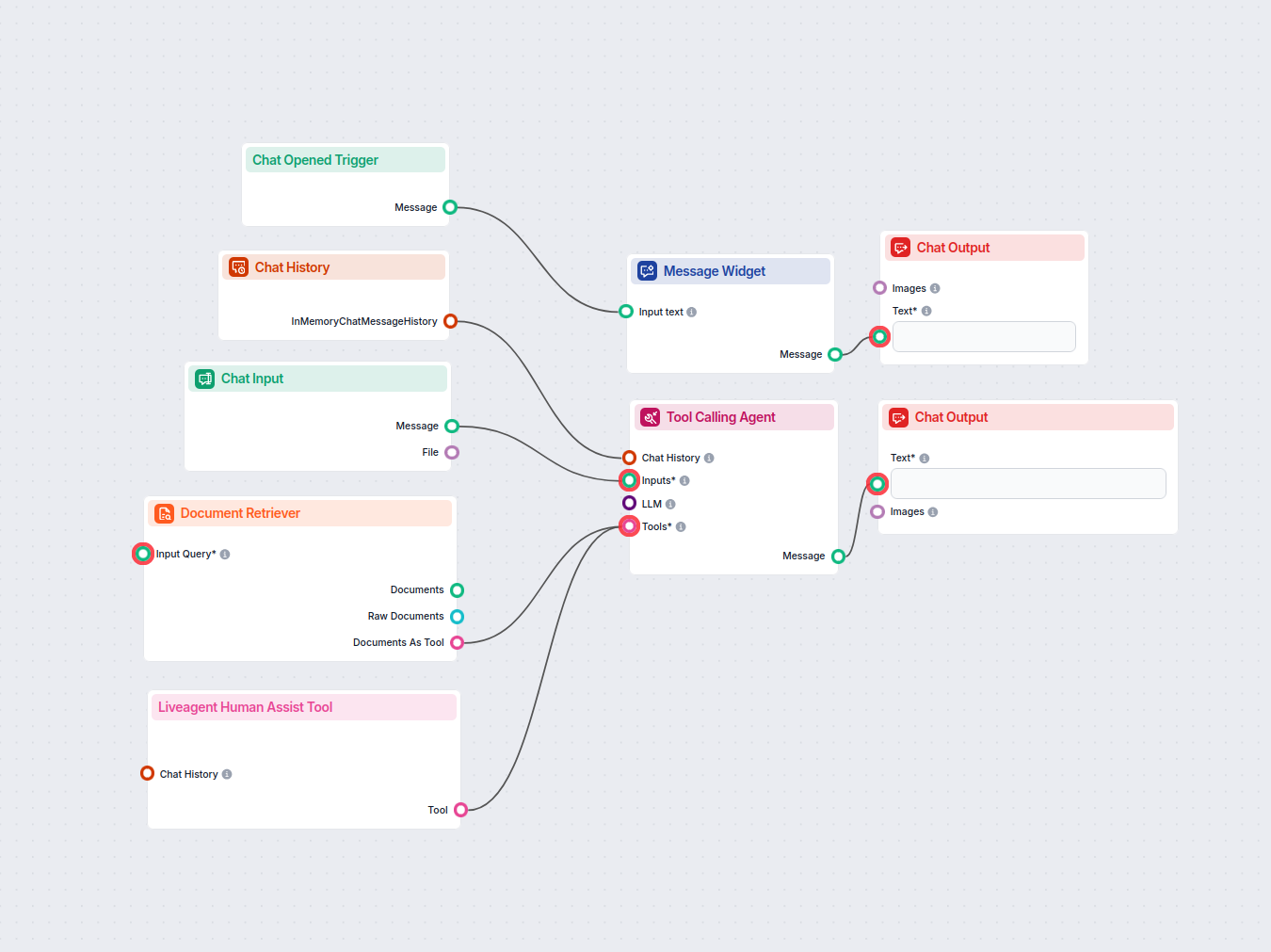
Opbygning af et automatiseret vidensbasesystem kræver, at flere værktøjer og platforme integreres i et sammenhængende workflow. Systemet består typisk af fire hovedkomponenter: et ticket-system (LiveAgent), en AI-agent der behandler tickets, et versionskontrolsystem (GitHub) og en statisk site-generator (Hugo). LiveAgent fungerer som kilde til kundehenvendelser og lagrer alle supportsamtaler med metadata som tags, kategorier og tidsstempler. AI-agenten er orkestratoren i hele processen—den modtager et ticket-ID, henter hele ticket-indholdet og samtalehistorikken, analyserer om det egner sig til udgivelse i vidensbasen, tjekker eksisterende viden for at undgå dubletter, genererer SEO-optimeret indhold i korrekt format og styrer GitHub-workflowet. GitHub fungerer som indholdsstyring og versionskontrol, hvilket muliggør gennemgang, godkendelse og historik over alle ændringer i vidensbasen. Hugo omsætter markdown-filerne i GitHub til et hurtigt, sikkert og SEO-venligt website. Denne arkitektur skaber en klar arbejdsdeling: LiveAgent står for support, AI-agenten for intelligens og beslutninger, GitHub for versionskontrol og samarbejde, og Hugo for præsentationen. Skønheden ved dette system er, at hver komponent kan vedligeholdes og opgraderes hver for sig uden at forstyrre resten.
Tilmeld dig vores nyhedsbrev
Få de seneste tips, trends og tilbud gratis.
Sådan muliggør FlowHunt vidensbase-automatisering
FlowHunt leverer det orkestreringslag, der binder alle disse systemer sammen i et sammenhængende workflow. I stedet for at kræve specialudvikling eller komplekse integrationer, kan du visuelt designe automationsflowet i FlowHunt og forbinde LiveAgent, GitHub og Hugo via et enkelt og intuitivt interface. Platformen håndterer autentificering, fejlhåndtering, retry-logik og al den tekniske kompleksitet, som ellers ville kræve betydelige udviklingsressourcer. Med FlowHunt kan du oprette sofistikerede automatiserings-workflows uden at skrive kode, hvilket gør vidensbase-automatisering tilgængelig for teams uden dedikerede udviklere. Platformen tilbyder også hukommelse og kontekststyring, så din automation lærer af tidligere eksekveringer og træffer intelligente beslutninger om, hvornår der skal oprettes nye artikler kontra opdatering af eksisterende. FlowHunts integration med GitHub muliggør automatisk oprettelse af pull requests, så dit team kan gennemgå genereret indhold, før det udgives. Denne “menneske-i-loopet”-tilgang sikrer kvalitet og bevarer samtidig effektiviteten fra automatiseringen.
Det komplette workflow: Trin-for-trin proces
Automatiseret vidensbase-generering følger en nøje tilrettelagt sekvens af trin, hvor hvert trin bygger videre på det foregående for at skabe en komplet, produktionsklar vidensbase-artikel. Det er essentielt at forstå denne proces for at kunne implementere den effektivt i din organisation.
Trin et: Ticket-hentning og validering
Workflowet starter, når du angiver et ticket-ID fra dit LiveAgent-system. AI-agenten henter straks hele ticket-indholdet, inklusive emnelinje, brødtekst, alle tags samt hele samtalehistorikken mellem kunden og supportteamet. Denne grundige indsamling sikrer, at AI’en har al nødvendig kontekst for at kunne generere præcist og relevant indhold. Agenten validerer også, om ticketten indeholder tilstrækkelig information og egner sig til udgivelse i vidensbasen. For eksempel, hvis din organisation modtager mange demo-bookings, kan systemet konfigureres til automatisk at springe disse tickets over, da de ikke indeholder viden, som andre brugere kan have gavn af. Dette filtreringstrin forhindrer, at din vidensbase fyldes med administrativt eller transaktionelt indhold, der ikke giver værdi for dine brugere.
Trin to: Dubletdetektion via hukommelse
Før der genereres nyt indhold, tjekker systemet sin hukommelse for, om der allerede er oprettet en lignende vidensbase-artikel. Dette hukommelsessystem er en af de vigtigste funktioner, da det forhindrer oprettelse af dublet- eller næsten-dublet-artikler, som vil forvirre brugerne og skade din SEO. AI-agenten søger i tidligere tickets og genererede artikler for at finde lignende emner. Hvis der findes et match, kan den enten opdatere den eksisterende artikel med ny information eller springe oprettelsen over, alt efter din konfiguration. Hvis der ikke findes et lignende emne, tilføjer agenten denne ticket til hukommelsen, så den fremover kan refereres til. Denne hukommelsesbaserede tilgang betyder, at systemet bliver klogere over tid—efterhånden som du behandler flere tickets, opbygger systemet et omfattende kort over din vidensbase og kan træffe stadig mere intelligente beslutninger om indholdsoprettelse og opdateringer.
Trin tre: Analyse af vidensbase-struktur
Systemet undersøger herefter dit eksisterende vidensbase-repository for at forstå, hvordan indhold er struktureret, formateret og organiseret. Dette trin er afgørende for konsistens på tværs af alle artikler. AI-agenten analyserer eksisterende markdown-filer, frontmatter-formater, overskriftsstrukturer og indholdsmønstre for at forstå din vidensbases konventioner. Den ser på, hvordan artikler kategoriseres, hvilke metadata der medtages, hvordan billeder refereres, og hvilke SEO-elementer der er til stede. Ved at analysere dit eksisterende indhold lærer systemet dine stil- og strukturkrav, så nye artikler smelter sammen med den eksisterende vidensbase og ikke skiller sig ud som åbenlyst automatiseret indhold.
Trin fire: GitHub-grenstyring
For at opretholde ren versionskontrol og muliggøre korrekte gennemgangs-workflows opretter systemet en ny eller bruger en eksisterende GitHub-gren til vidensbase-opdateringen. I stedet for at oprette en ny gren for hver ticket, håndterer systemet grene intelligent for at holde dit repository organiseret. Hvis der allerede findes en gren til vidensbase-opdateringer, bruges den, og den nye fil tilføjes dertil. Denne tilgang forhindrer gren-proliferation og gør det muligt at samle flere opdateringer i én pull request til gennemgang. Gren-navngivningen er typisk beskrivende, såsom “knowledge-base-updates” eller “kb-automation”, så teamet let kan forstå formålet.
Trin fem: Indholdsgenerering og formatering
Når al kontekst er samlet, genererer AI-agenten vidensbase-artiklen. Det genererede indhold indeholder et korrekt formateret frontmatter-afsnit med metadata som titel, beskrivelse, nøgleord, tags, kategorier, udgivelsesdato og call-to-action-elementer. Artikelens brødtekst følger et struktureret format, der både er læsevenligt og SEO-venligt. Typisk indgår en hovedoverskrift, flere H2-sektioner med spørgsmål som overskrifter (fx “Hvad er dette?”, “Hvorfor skal vi gøre det?” og “Hvordan gør vi det?”) samt detaljerede svar i afsnit og punktform. Denne struktur er optimeret til featured snippets og andre søgemaskinefunktioner, der belønner klar, spørgsmål-svar-formatering. Indholdet skrives i markdown-format, som er standard for Hugo og de fleste statiske site generators, hvilket sikrer kompatibilitet og nem redigering.
Trin seks: Filoprettelse og commit
Systemet opretter en ny markdown-fil i din vidensbase-mappe med et passende filnavn baseret på artikelens emne. Filnavnet er typisk “slugificeret” (små bogstaver, bindestreger i stedet for mellemrum) for at følge webstandarder. Filen indeholder hele frontmatteren og brødteksten fra det forrige trin. Når filen er oprettet, committer systemet ændringerne til GitHub-grenen med en beskrivende commit-besked, der refererer til det oprindelige ticket-ID. Denne commit-besked skaber en permanent reference mellem vidensbase-artiklen og den oprindelige kundehenvendelse, hvilket sikrer sporbarhed og kontekst.
Trin syv: Pull request-oprettelse og gennemgang
Til sidst opretter systemet en pull request fra vidensbase-grenen til din hovedgren. Denne pull request indeholder en beskrivelse af ændringerne, ticket-ID’et der udløste oprettelsen, og anden relevant kontekst. Pull requesten fungerer som checkpoint, hvor dit team kan gennemgå det genererede indhold, foretage nødvendige redigeringer, sikre at artiklen lever op til kvaliteten og passer til din vidensbase-strategi. Dette menneskelige review er vigtigt—selvom AI-genereret indhold generelt er af høj kvalitet, sikrer menneskelig vurdering nøjagtighed, brand-konsistens og relevans. Når teamet godkender pull requesten, kan den flettes til hovedgrenen, hvilket får Hugo til at genopbygge websitet og udgive den nye artikel.
Praktisk implementering: Find og brug ticket-ID’er
For at bruge dette automations-workflow skal du identificere det korrekte ticket-ID fra dit LiveAgent-system. LiveAgent viser ticket-ID’er to steder. Først i selve LiveAgent-interfacet, hvor du ser etiketten “Ticket” med ID’et tydeligt vist. Du kan kopiere ID’et direkte herfra. For det andet, og ofte mere bekvemt, kan du finde ticket-ID’et i URL’en på ticketsiden. Når du åbner en ticket i LiveAgent, vil URL’en indeholde en parameter som “ID=12345” til sidst. Dette ID er nøjagtigt det, du skal bruge i automationsflowet. Når du har ticket-ID’et, indtaster du det blot i FlowHunt-workflowet, og hele processen starter automatisk. Systemet henter ticketten, analyserer den, tjekker for dubletter, genererer artiklen, opretter GitHub-gren og pull request og giver dit team besked til gennemgang. Hele processen tager typisk få sekunder til minutter, afhængigt af ticket-kompleksitet og størrelsen på din eksisterende vidensbase.
Få turbo på dit workflow med FlowHunt
Oplev hvordan FlowHunt automatiserer din vidensbase fra support-tickets — fra ticket-analyse og indholdsgenerering til GitHub-integration og Hugo-publicering — alt i ét sammenhængende workflow.
Når du har det grundlæggende workflow på plads, er der flere avancerede konfigurationer, som kan optimere systemet til dine specifikke behov. Du kan sætte systemet op til at ignorere bestemte ticket-typer baseret på tags, kategorier eller nøgleord. For eksempel kan du vælge at springe alle tickets med tagget “fakturering” eller “konto-specifik” over, da disse typisk ikke indeholder viden, der kan generaliseres. Du kan også sætte grænser for artikelkvalitet eller -længde—hvis en ticket er for kort eller mangler detaljer, kan systemet springe den over og vente på mere udførlig information. Hukommelsessystemet kan konfigureres til at bruge forskellige match-algoritmer, fra simpel nøgleords-match til avanceret semantisk lignende-analyse. Du kan desuden tilpasse frontmatter og indholdsstruktur, så det matcher dine krav, tilføje specialfelter eller ændre artikel-opbygningen. Nogle organisationer tilføjer ekstra metadata som sværhedsgrad, målgruppe eller relaterede artikler. Du kan også konfigurere systemet til automatisk at tilføje billeder til artikler ved at generere dem med AI eller hente dem fra dit billedbibliotek. Systemet kan sættes til automatisk at oprette artikler på flere sprog, hvis du har et internationalt publikum. Endelig kan du konfigurere notifikationer og godkendelser—for eksempel at kræve, at bestemte teammedlemmer godkender artikler i visse kategorier, før de udgives.
Virkeligt eksempel: WordPress-integration-fejl
Lad os tage et praktisk eksempel fra workflowet i aktion. En kunde indsender en support-ticket om en fejl i WordPress-integrationen, de oplever. Ticketten indeholder fejlmeddelelser, skærmbilleder og en detaljeret beskrivelse af, hvad kunden har prøvet. Supportteamet svarer med fejlsøgningstrin og løser til sidst problemet. Denne ticket er nu et perfekt emne for vidensbase-automatisering. Når ticket-ID’et gives til workflowet, henter systemet hele samtalen, analyserer den og tjekker sin hukommelse. Da der ikke findes en tidligere artikel om WordPress-integrationsfejl, tilføjer systemet dette emne til hukommelsen og fortsætter med artikelgenereringen. Systemet undersøger din eksisterende vidensbase og opdager, at du har et særligt format for tekniske fejlsøgningsartikler, med sektioner for symptomer, årsager, løsninger og forebyggelse. Den genererede artikel følger dette format og skaber en omfattende vejledning til WordPress-integrationsfejl, som vil hjælpe fremtidige kunder med at løse det samme problem selv. Artiklen oprettes på en GitHub-gren, der genereres en pull request, dit team gennemgår den, foretager nødvendige tilpasninger og fletter den. Inden for få minutter er artiklen live på dit website, indekseret af søgemaskiner og klar til at hjælpe kunder. Næste gang nogen søger på “WordPress integration fejl” eller oplever dette problem, finder de din vidensbase-artikel og løser det uden at kontakte support.
Mål på succes og ROI
For at retfærdiggøre investeringen i vidensbase-automatisering er det vigtigt at måle effekten. Vigtige målepunkter inkluderer faldet i antallet af support-tickets på emner, der dækkes af vidensbase-artikler, stigningen i organisk trafik fra søgemaskiner, den tid dit supportteam sparer, og forbedring i kundetilfredshed. Du kan måle, hvor mange kunder der tilgår vidensbase-artikler før de kontakter support, hvor mange support-tickets der refererer til artikler, og hvor mange kunder der angiver, at de fandt svar i vidensbasen. Du kan også vurdere kvaliteten af genererede artikler via brugerengagement som tid på siden, scroll-dybde og bounce rate. Artikler, som brugerne finder værdifulde, vil have højere engagement. Du kan desuden følge antallet af oprettede artikler, den sparede tid sammenlignet med manuel oprettelse, og besparelser i supportomkostninger. De fleste organisationer oplever, at vidensbase-automatisering betaler sig selv hjem i løbet af de første måneder via lavere supportomkostninger og øget kundetilfredshed.
Konklusion
Automatisering af vidensbase-oprettelse fra LiveAgent-tickets er en markant mulighed for at forbedre effektiviteten i kundesupport, styrke dit websites SEO og skabe en værdifuld ressource, der gavner dine kunder længe efter den oprindelige supportinteraktion. Ved at forbinde LiveAgent, GitHub, Hugo og AI-drevet automatisering gennem FlowHunt skaber du et system, der automatisk forvandler rå kundehenvendelser til færdige, professionelle vidensbase-artikler. Workflowet er ligetil—angiv et ticket-ID, og systemet klarer alt fra indholdsgenerering til GitHub-integration og oprettelse af pull requests. Hukommelsessystemet sikrer, at du ikke opretter dublet-indhold, mens det menneskelige review bevarer kvalitet og brand-konsistens. Efterhånden som vidensbasen vokser, bliver den en stadig mere værdifuld ressource, der reducerer supportomkostninger, forbedrer kundetilfredshed og driver organisk trafik til dit website. Implementeringen er tilgængelig for teams uden dyb teknisk ekspertise, så denne kraftfulde automatisering kan bruges af organisationer i alle størrelser.
Ofte stillede spørgsmål
Hvad er en LiveAgent-ticket?
En LiveAgent-ticket er en kundesupport-forespørgsel eller -henvendelse, der er logget i LiveAgent-ticketsystemet. Hver ticket indeholder et emne, en brødtekst, tags og hele samtalehistorikken, som kan bruges til at generere vidensbase-indhold.
Hvordan finder jeg mit ticket-ID i LiveAgent?
Du kan finde dit ticket-ID på to måder: (1) Kig efter etiketten 'Ticket' med ID'et vist i LiveAgent-interfacet, eller (2) Tjek URL'en til sidst, hvor der står 'ID=dit-ticket-id'. Kopiér dette ID, så du kan bruge det i automationsflowet.
Kan flowet ignorere bestemte typer af tickets?
Ja, flowet kan konfigureres til at ignorere specifikke ticket-typer. For eksempel kan du sætte det op til at springe demo-bookingsforespørgsler over for at undgå at oprette dublerede vidensbase-sider for lignende emner.
Hvad sker der, hvis der allerede findes en lignende vidensbase-artikel?
Flowet bruger hukommelse til at tjekke, om et lignende emne tidligere er blevet behandlet. Hvis der findes et match, opdateres den eksisterende artikel om nødvendigt, eller oprettelsen springes over for at undgå dubletter.
Hvordan integrerer flowet med GitHub?
Flowet opretter eller bruger en eksisterende GitHub-gren, genererer en markdown-fil med korrekt frontmatter, committer ændringerne og opretter en pull request til gennemgang, før den flettes til hovedgrenen.
Arshia er AI Workflow Engineer hos FlowHunt. Med en baggrund inden for datalogi og en passion for AI, specialiserer han sig i at skabe effektive workflows, der integrerer AI-værktøjer i daglige opgaver og øger produktivitet og kreativitet.
Arshia Kahani
AI Workflow Engineer
Automatiser oprettelsen af din vidensbase
Forvandl kundesupport-tickets til SEO-optimerede vidensbase-artikler automatisk med FlowHunts AI-drevne workflows.
Sådan automatiserer du besvarelse af tickets i LiveAgent med FlowHunt
Lær hvordan du integrerer FlowHunt AI-flows med LiveAgent for automatisk at besvare kundetickets ved hjælp af intelligente automationsregler og API-integration....
AI-kundesupportagent med vidensbase og API-berigelse
Dette AI-drevne workflow automatiserer kundesupport ved at kombinere intern vidensbasesøgning, Google Docs-videnshentning, API-integration og avanceret sprogmod...
Automatisér din kundesupport med en AI-chatbot, der besvarer spørgsmål ved hjælp af din interne vidensbase og problemfrit forbinder brugere til en menneskelig a...
3 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.