Human-in-the-Loop Middleware i Python: Byg Sikker AI med Godkendelsesworkflows
Lær at implementere human-in-the-loop middleware i Python med LangChain for at tilføje godkendelse, redigering og afvisningsfunktioner til AI-agenter før værktøjseksekvering.
At bygge AI-agenter, der selvstændigt kan eksekvere værktøjer og tage handlinger, er kraftfuldt, men det indebærer iboende risici. Hvad sker der, når en agent beslutter at sende en e-mail med forkerte oplysninger, godkende en stor finansiel transaktion eller ændre kritiske databaseposter? Uden de rette sikkerhedsforanstaltninger kan autonome agenter forårsage betydelig skade, før nogen opdager det. Det er her, human-in-the-loop middleware bliver essentielt. I denne omfattende guide undersøger vi, hvordan du implementerer human-in-the-loop middleware i Python med LangChain, så du kan bygge AI-agenter, der stopper op for menneskelig godkendelse, før de udfører følsomme operationer. Du lærer at tilføje godkendelsesworkflows, implementere redigeringsmuligheder og håndtere afvisninger – alt imens du bevarer effektiviteten og intelligensen i dine autonome systemer.
Forstå AI-agentloops og værktøjseksekvering
Før vi dykker ned i human-in-the-loop middleware, er det vigtigt at forstå, hvordan AI-agenter grundlæggende fungerer. En AI-agent arbejder gennem et kontinuerligt loop, der gentages, indtil agenten beslutter, at opgaven er fuldført. Kernen i agentloopet består af tre primære komponenter: en sprogmodel, der ræsonnerer om næste skridt, et sæt værktøjer, agenten kan kalde for at handle, og et tilstandsstyringssystem, der holder styr på samtalehistorik og relevant kontekst. Agenten starter med at modtage en inputbesked fra en bruger, hvorefter sprogmodellen analyserer inputtet sammen med de tilgængelige værktøjer og beslutter, om der skal kaldes et værktøj eller gives et endeligt svar. Hvis modellen beslutter at kalde et værktøj, eksekveres det, og resultaterne tilføjes samtalehistorikken. Denne cyklus fortsætter – modelræsonnement, værktøjsvalg, værktøjseksekvering, resultatintegration – indtil modellen vurderer, at der ikke er behov for yderligere værktøjskald og giver et endeligt svar til brugeren.
Dette enkle, men kraftfulde mønster er blevet fundamentet for hundredvis af AI-agentframeworks de seneste år. Elegancen ved agentloopet ligger i dets fleksibilitet: Ved at ændre de værktøjer, der er tilgængelige for en agent, kan du få den til at udføre vidt forskellige opgaver. En agent med e-mailværktøjer kan håndtere kommunikation, en agent med databaseværktøjer kan forespørge og opdatere poster, og en agent med finansielle værktøjer kan behandle transaktioner. Men denne fleksibilitet introducerer også risiko. Fordi agentloopet arbejder autonomt, er der ingen indbygget mekanisme til at sætte på pause og spørge et menneske, om en bestemt handling faktisk bør udføres. Modellen kan beslutte at sende en e-mail, eksekvere en databaseforespørgsel eller godkende en finansiel transaktion, og når et menneske opdager det, er handlingen allerede udført. Det er her, begrænsningerne i det grundlæggende agentloop bliver tydelige i produktionsmiljøer.
Klar til at vokse din virksomhed?
Start din gratis prøveperiode i dag og se resultater inden for få dage.
Hvorfor menneskelig overvågning er vigtig i produktions-AI-systemer
Efterhånden som AI-agenter bliver mere kapable og implementeres i virkelige forretningsmiljøer, bliver behovet for menneskelig overvågning stadig vigtigere. Konsekvenserne af autonome agenthandlinger varierer dramatisk afhængigt af konteksten. Nogle værktøjskald er lavrisiko og kan køres med det samme uden menneskelig gennemgang – for eksempel at læse en e-mail eller hente oplysninger fra en database. Andre værktøjskald er højrisiko og potentielt irreversible, såsom at sende kommunikation på vegne af en bruger, overføre penge, slette poster eller indgå forpligtelser, der binder en organisation. I produktionssystemer kan det være meget dyrt, hvis en agent begår fejl ved en højrisikooperation. En forkert formuleret e-mail sendt til en forkert modtager kan skade forretningsrelationer. Et forkert godkendt budget kan føre til økonomiske tab. En databasesletning udført ved en fejl kan resultere i datatab, der tager timer eller dage at genskabe fra backup.
Ud over de umiddelbare operationelle risici er der også overholdelses- og lovgivningsmæssige hensyn. Mange brancher har strenge krav om, at visse typer beslutninger skal involvere menneskelig vurdering og godkendelse. Finansielle institutioner skal have menneskelig overvågning af transaktioner over visse grænser. Sundhedssystemer skal have menneskelig gennemgang af visse automatiserede beslutninger. Advokatfirmaer skal sikre, at kommunikation er gennemgået, før den sendes på vegne af klienter. Disse krav er ikke blot bureaukratisk overflødighed – de eksisterer, fordi konsekvenserne af fuldt autonome beslutninger i disse domæner kan være alvorlige. Derudover giver menneskelig overvågning en feedbackmekanisme, der hjælper med at forbedre agenten over tid. Når et menneske gennemgår en agents foreslåede handling og enten godkender eller foreslår ændringer, kan denne feedback bruges til at forfine agentens prompts, justere dets værktøjsvalg eller genoptræne de underliggende modeller. Dette skaber en positiv spiral, hvor agenten bliver mere pålidelig og bedre tilpasset organisationens specifikke behov og risikotolerance.
Hvad er Human-in-the-Loop Middleware?
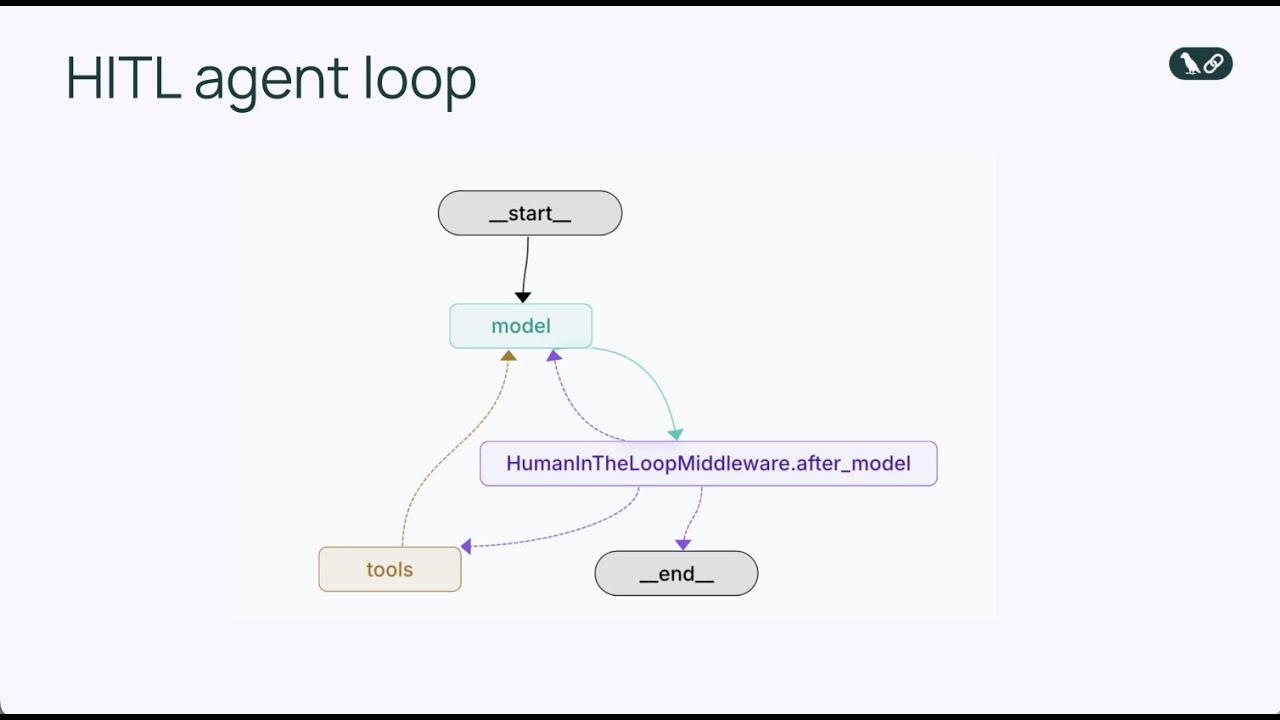
Human-in-the-loop middleware er en specialiseret komponent, der afbryder agentloopet på et kritisk tidspunkt: lige før et værktøj eksekveres. I stedet for at lade agenten køre et værktøjskald med det samme, sætter middleware eksekveringen på pause og præsenterer den foreslåede handling for et menneske til gennemgang. Mennesket har så flere muligheder for at reagere. De kan godkende handlingen, så den udføres præcis som agenten foreslog. De kan redigere handlingen ved at ændre parametre (f.eks. ændre e-mail-modtageren eller tilpasse beskedindholdet), før eksekvering tillades. Eller de kan afvise handlingen helt, sende feedback tilbage til agenten om, hvorfor handlingen var upassende, og bede den overveje en anden tilgang. Denne tredelte beslutningsmekanisme – godkend, redigér, afvis – giver en fleksibel ramme, der kan tilpasses forskellige former for menneskelig overvågning.
Middleware fungerer ved at ændre det normale agentloop og tilføje et ekstra beslutningspunkt. I det grundlæggende agentloop er rækkefølgen: model kalder værktøjer → værktøjer eksekverer → resultater returnerer til model. Med human-in-the-loop middleware bliver rækkefølgen: model kalder værktøjer → middleware afbryder → menneske gennemgår → menneske beslutter (godkend/redigér/afvis) → hvis godkendt eller redigeret, eksekverer værktøjet → resultater returnerer til model. Denne indsættelse af et menneskeligt beslutningspunkt bryder ikke agentloopet; tværtimod styrker det det ved at tilføje en sikkerhedsventil. Middleware er konfigurerbar, så du præcist kan angive, hvilke værktøjer der skal udløse menneskelig gennemgang, og hvilke værktøjer der kan køre automatisk. Du vil måske afbryde på alle e-mail-sendeværktøjer, men lade skrivebeskyttede database-forespørgsler køre uden gennemgang. Denne granulære kontrol sikrer, at du tilføjer menneskelig overvågning præcis, hvor det er nødvendigt, uden at skabe unødvendige flaskehalse ved lavrisikooperationer.
Tilmeld dig vores nyhedsbrev
Få de seneste tips, trends og tilbud gratis.
De tre svarstyper: Godkendelse, Redigering og Afvisning
Når human-in-the-loop middleware afbryder en agents værktøjseksekvering, har den menneskelige gennemgår tre primære måder at svare på, som hver tjener et forskelligt formål i godkendelsesworkflowet. Forståelsen af disse tre svarstyper er afgørende for at designe effektive human-in-the-loop-systemer.
Godkendelse er den simpleste svartype. Når et menneske gennemgår et foreslået værktøjskald og vurderer, at det er passende og bør gennemføres præcis som agenten foreslog, giver de en godkendelsesbeslutning. Dette signalerer til middleware, at værktøjet skal eksekveres med de præcise parametre, agenten angav. I konteksten af en e-mailassistent betyder godkendelse, at e-mailudkastet ser godt ud og skal sendes til den specificerede modtager med det angivne emne og brødtekst. Godkendelse er den nemmeste vej – det tillader agentens foreslåede handling at fortsætte uden ændring. Dette er passende, når agenten har udført sit arbejde godt, og den menneskelige gennemgår er enig i handlingen. Godkendelsesbeslutninger træffes typisk hurtigt, hvilket er vigtigt, da du ikke ønsker, at menneskelig gennemgang bliver en flaskehals, der forsinker hele workflowet.
Redigering er en mere nuanceret svartype, der anerkender, at agentens generelle tilgang er korrekt, men at nogle detaljer skal justeres før eksekvering. Når et menneske giver et redigeringssvar, afviser de ikke agentens beslutning om at handle; de finjusterer blot detaljerne for, hvordan handlingen skal udføres. I en e-mailsituation kan redigering betyde at ændre modtagerens e-mailadresse, justere emnelinjen, så den bliver mere professionel, eller tilpasse brødteksten for at tilføje yderligere kontekst eller fjerne potentielt problematiske formuleringer. Kendetegnet ved et redigeringssvar er, at det ændrer værktøjsparametrene, mens samme værktøjskald bevares. Agenten besluttede at sende en e-mail, og mennesket er enig i, at det er den rigtige handling, men vil justere, hvad e-mailen siger eller hvem den sendes til. Efter at mennesket har givet sine rettelser, eksekveres værktøjet med de ændrede parametre, og resultaterne returneres til agenten. Denne tilgang er særligt værdifuld, fordi den lader agenten foreslå handlinger, mens mennesker kan finjustere dem på baggrund af deres ekspertviden eller organisationskontekst, som agenten måske ikke har.
Afvisning er den mest markante svartype, fordi den ikke blot stopper den foreslåede handling fra at blive udført, men også sender feedback tilbage til agenten om, hvorfor handlingen var upassende. Når et menneske afviser et værktøjskald, siger de, at agentens forslag slet ikke bør udføres, og de giver vejledning om, hvordan agenten bør overveje en ny tilgang. I e-maileksemplet kan afvisning ske, når agenten foreslår at sende en e-mail, der godkender en stor budgetanmodning uden tilstrækkelig information eller begrundelse. Mennesket afviser denne handling og sender en besked tilbage til agenten, der forklarer, at der er brug for flere detaljer, før godkendelse kan gives. Denne afvisningsbesked bliver en del af agentens kontekst, og agenten kan derefter reflektere over feedbacken og foreslå en revideret tilgang. Agenten kan derefter foreslå en anden e-mail, der beder om flere oplysninger om budgetforslaget, før der tages stilling. Afvisningssvar er afgørende for at forhindre agenten i at foreslå den samme uhensigtsmæssige handling igen og igen. Ved at give klar feedback om, hvorfor en handling blev afvist, hjælper du agenten med at lære og forbedre sin beslutningstagning.
Implementering af Human-in-the-Loop Middleware: Et praktisk eksempel
Lad os gennemgå en konkret implementering af human-in-the-loop middleware med LangChain og Python. Eksemplet er en e-mailassistent – et praktisk scenarie, der demonstrerer værdien af menneskelig overvågning og samtidig er let at forstå. E-mailassistenten får mulighed for at sende e-mails på vegne af en bruger, og vi tilføjer human-in-the-loop middleware for at sikre, at alle e-mails gennemgås før afsendelse.
Først skal vi definere det e-mailværktøj, vores agent skal bruge. Dette værktøj tager tre parametre: en modtagers e-mailadresse, en emnelinje og e-mailens brødtekst. Værktøjet er simpelt – det repræsenterer selve handlingen at sende en e-mail. I en reel implementering kunne det integrere med en e-mailtjeneste som Gmail eller Outlook, men til demonstration kan vi holde det simpelt. Her er grundstrukturen:
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Send en e-mail til den specificerede modtager."""returnf"Email sendt til {recipient} med emnet '{subject}'"
Dernæst opretter vi en agent, der bruger dette e-mailværktøj. Vi bruger GPT-4 som sprogmodel og giver et systemprompt, der fortæller agenten, at den er en hjælpsom e-mailassistent. Agenten initialiseres med e-mailværktøjet og er klar til at svare på brugerforespørgsler:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Du er en hjælpsom e-mailassistent for Sydney. Du kan sende e-mails på vegne af brugeren.")
På dette tidspunkt har vi en grundlæggende agent, der kan sende e-mails. Men der er ingen menneskelig overvågning – agenten kan sende e-mails uden nogen gennemgang. Nu tilføjer vi human-in-the-loop middleware. Implementeringen er bemærkelsesværdigt simpel og kræver blot to kodelinjer:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Du er en hjælpsom e-mailassistent for Sydney. Du kan sende e-mails på vegne af brugeren.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
Ved at tilføje HumanInTheLoopMiddleware og angive interrupt_on={"send_email": True} fortæller vi agenten at sætte på pause før eksekvering af alle send_email-kald og vente på menneskelig godkendelse. Værdien True betyder, at alle send_email-kald udløser en afbrydelse med standardkonfiguration. Hvis vi ønskede mere detaljeret kontrol, kunne vi angive, hvilke beslutningstyper der er tilladt (godkend, redigér, afvis) eller give brugerdefinerede beskrivelser for afbrydelsen.
Test af middleware med lavrisikoscenarier
Når middleware er på plads, lad os teste det i et lavrisiko e-mailscenarie. Forestil dig en bruger, der beder agenten om at svare på en uformel e-mail fra en kollega, Alice, der foreslår kaffe i næste uge. Agenten behandler forespørgslen og beslutter at sende et venligt svar. Sådan forløber det:
Brugeren sender en besked: “Svar venligst på Alices e-mail om at drikke kaffe i næste uge.”
Agentens sprogmodel behandler dette og beslutter at kalde send_email-værktøjet med parametre som recipient=“alice@example.com
”, subject=“Kaffe i næste uge?”, body=“Jeg vil meget gerne drikke kaffe med dig i næste uge!”
Før e-mailen faktisk bliver sendt, afbryder middleware værktøjskaldet og rejser en afbrydelse.
Den menneskelige gennemgår ser den foreslåede e-mail og vurderer den. E-mailen ser passende ud – den er venlig, professionel og opfylder brugerens ønske.
Mennesket godkender handlingen ved at give en godkendelsesbeslutning.
Middleware tillader værktøjet at blive eksekveret, og e-mailen bliver sendt.
Dette workflow demonstrerer godkendelsesvejen. Den menneskelige gennemgang tilføjer et sikkerhedslag uden væsentlig forsinkelse. Ved lavrisikooperationer som denne sker godkendelsen typisk hurtigt, fordi agentens forslag er rimeligt og ikke kræver ændringer.
Test af middleware med højrisikoscenarier: Edit-svaret
Lad os nu overveje et mere betydningsfuldt scenarie, hvor redigering bliver værdifuld. Forestil dig, at agenten modtager en anmodning om at svare på en e-mail fra en startup-partner, der beder brugeren om at godkende et ingeniørbudget på 1 million USD for Q1. Dette er en højrisikobeslutning, der kræver omhyggelig overvejelse. Agenten kunne foreslå en e-mail som: “Jeg har gennemgået og godkendt forslaget om et ingeniørbudget på 1 million USD for Q1.”
Når denne foreslåede e-mail når den menneskelige gennemgår via middleware-afbrydelsen, indser mennesket, at dette er en betydelig økonomisk forpligtelse, som ikke bør godkendes uden grundig gennemgang. Mennesket ønsker ikke at afvise hele idéen om at svare på e-mailen, men vil tilpasse svaret, så det er mere forsigtigt. Mennesket giver et redigeringssvar, der ændrer e-mailens brødtekst til f.eks.: “Tak for forslaget. Jeg vil gerne gennemgå detaljerne grundigere, før jeg kan give endelig godkendelse. Kan du sende mig en opdeling af, hvordan budgettet vil blive fordelt?”
Sådan ser et edit-svar ud i kode:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Q1 Ingeniørbudgetforslag",
"body": "Tak for forslaget. Jeg vil gerne gennemgå detaljerne grundigere, før jeg kan give endelig godkendelse. Kan du sende mig en opdeling af, hvordan budgettet vil blive fordelt?" }
}
}
Når middleware modtager dette edit-svar, eksekveres værktøjet med de ændrede parametre. E-mailen sendes med den menneskeligt reviderede tekst, som er mere passende for en stor økonomisk beslutning. Dette demonstrerer styrken ved edit-svaret: Det lader mennesker udnytte agentens evne til at udarbejde udkast, mens det sikrer, at det endelige output afspejler menneskelig dømmekraft og organisationsstandarder.
Test af middleware med afvisning og feedback
Afvisningssvartypen er særligt stærk, fordi den ikke bare stopper en upassende handling, men også giver feedback, der hjælper agenten med at forbedre sin ræsonnering. Lad os tage endnu et scenarie med samme højrisiko-budget-e-mail. Antag, at agenten foreslår en e-mail som: “Jeg har gennemgået og godkendt ingeniørbudgettet på 1 million USD for Q1.”
Den menneskelige gennemgår ser dette og indser, at det er alt for forhastet. En forpligtelse på 1 million USD bør ikke godkendes uden omfattende gennemgang, dialog med interessenter og forståelse af budgetdetaljerne. Mennesket ønsker ikke bare at redigere e-mailen; de vil afvise denne tilgang og bede agenten overveje det på ny. Mennesket giver et afvisningssvar med feedback:
reject_decision = {
"type": "reject",
"message": "Jeg kan ikke godkende dette budget uden flere oplysninger. Udarbejd venligst en e-mail, hvor du beder om en detaljeret opdeling af forslaget, herunder hvordan midlerne vil blive fordelt på de forskellige ingeniørteams og hvilke specifikke leverancer, der forventes."}
Når middleware modtager dette afvisningssvar, eksekveres værktøjet ikke. I stedet sendes afvisningsbeskeden tilbage til agenten som en del af samtalekonteksten. Agenten ser nu, at den foreslåede handling blev afvist, og forstår hvorfor. Agenten kan derefter reflektere over denne feedback og foreslå en anden tilgang. I dette tilfælde kan agenten foreslå en ny e-mail, hvor der bedes om flere detaljer om budgetforslaget, hvilket er et mere passende svar på en stor økonomisk anmodning. Mennesket kan derefter gennemgå dette reviderede forslag og enten godkende, redigere yderligere eller afvise igen om nødvendigt.
Denne iterative proces – foreslå, gennemgå, afvis med feedback, foreslå igen – er en af de mest værdifulde aspekter ved human-in-the-loop middleware. Det skaber et samarbejdende workflow, hvor agentens hurtighed og ræsonnement kombineres med menneskelig dømmekraft og domæneekspertise.
Supercharge dit workflow med FlowHunt
Oplev hvordan FlowHunt automatiserer dine AI-indholds- og SEO-workflows – fra research og indholdsgenerering til publicering og analyse – alt samlet ét sted.
Avanceret konfiguration: Granulær kontrol over afbrydelser
Selvom den grundlæggende implementering af human-in-the-loop middleware er simpel, tilbyder LangChain mere avancerede konfigurationsmuligheder, så du præcist kan styre, hvordan og hvornår afbrydelser opstår. En vigtig mulighed er at angive, hvilke beslutningstyper der er tilladt for hvert værktøj. Du vil f.eks. måske tillade godkendelse og redigering for e-mailafsendelser, men ikke afvisning. Eller du vil tillade alle tre beslutningstyper for finansielle transaktioner, men kun godkendelse for skrivebeskyttede databaseforespørgsler.
Her er et eksempel på mere granulær konfiguration:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Auto-godkend, ingen afbrydelse"delete_record": {
"allowed_decisions": ["approve", "reject"] # Ingen redigering af sletninger }
}
)
]
)
I denne konfiguration vil e-mailafsendelser afbrydes og tillade alle tre beslutningstyper. Læseoperationer køres automatisk uden afbrydelse. Sletteoperationer afbrydes, men tillader ikke redigering – mennesket kan kun godkende eller afvise, ikke ændre sletteparametrene. Denne granulære kontrol sikrer, at du tilføjer menneskelig overvågning præcis, hvor det er nødvendigt, uden at skabe unødvendige flaskehalse ved lavrisikooperationer.
En anden avanceret funktion er muligheden for at give brugerdefinerede beskrivelser til afbrydelser. Som standard giver middleware en generisk beskrivelse som “Værktøjseksekvering kræver godkendelse.” Du kan tilpasse dette for at give mere kontekstspecifik information:
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"],
"description": "Afsendelse af e-mails kræver menneskelig godkendelse før eksekvering" }
}
)
Vigtige implementeringsovervejelser: Checkpointere og tilstandsstyring
Et kritisk aspekt ved implementering af human-in-the-loop middleware, som er let at overse, er behovet for en checkpointer. En checkpointer er en mekanisme, der gemmer agentens tilstand på afbrydelsestidspunktet, så workflowet kan genoptages senere. Dette er essentielt, fordi menneskelig gennemgang ikke sker øjeblikkeligt – der kan gå tid mellem, at afbrydelsen sker, og mennesket giver sin beslutning. Uden en checkpointer ville agentens tilstand gå tabt under denne forsinkelse, og du ville ikke kunne genoptage workflowet korrekt.
LangChain tilbyder flere checkpointer-muligheder. Til udvikling og test kan du bruge en in-memory checkpointer:
Til produktionssystemer vil du typisk bruge en persistent checkpointer, der gemmer tilstanden i en database eller på filsystemet, så afbrydelser kan genoptages, selv hvis applikationen genstartes. Checkpointeren opretholder en komplet log over agentens tilstand for hvert trin, inklusiv samtalehistorik, værktøjskald og resultater. Når et menneske afgiver en beslutning (godkend, redigér, afvis), bruger middleware checkpointeren til at hente den gemte tilstand, anvende den menneskelige beslutning og genoptage agentloopet.
Virkelige anvendelser og brugsscenarier
Human-in-the-loop middleware kan bruges i et bredt udvalg af virkelige scenarier, hvor autonome agenter skal handle, men handlingerne kræver menneskelig overvågning. I finanssektoren kan agenter, der behandler transaktioner, godkender lån eller håndterer investeringer, bruge human-in-the-loop middleware for at sikre, at værdifulde beslutninger bliver gennemgået, før de udføres. I sundhedssektoren kan agenter, der anbefaler behandling eller tilgår patientjournaler, bruge middleware til at sikre overholdelse af privatlivsregler og kliniske protokoller. I jura kan agenter, der udarbejder kommunikation eller tilgår fortrolige dokumenter, bruge middleware for at sikre advokatgennemgang. I kundeservice kan agenter, der udsteder refusioner, træffer forpligtende beslutninger eller eskalerer sager, bruge middleware for at sikre overholdelse af virksomhedspolitikker.
Ud over disse branchespecifikke anvendelser er human-in-the-loop middleware værdifuldt i ethvert scenarie, hvor prisen for en agens fejl er betydelig. Dette inkluderer indholdsmoderering, hvor agenter kan fjerne brugerindhold, HR-systemer hvor agenter kan træffe ansættelsesbeslutninger, og supply chain-systemer hvor agenter kan bestille varer eller justere lager. Fælles for disse anvendelser er, at agentens forslag har reelle konsekvenser, og disse konsekvenser er store nok til at kræve menneskelig gennemgang før eksekvering.
Sammenligning med alternative tilgange
Det er værd at overveje, hvordan human-in-the-loop middleware adskiller sig fra alternative tilgange til at tilføje menneskelig overvågning til agentsystemer. Et alternativ er at lade mennesker gennemgå alle agentens outputs efter eksekvering, men denne metode har betydelige begrænsninger. Når et menneske gennemgår en handling, er den allerede udført, og det kan være svært eller umuligt at fortryde. En e-mail er allerede sendt, en databasepost er slettet, eller en transaktion er gennemført. Human-in-the-loop middleware forhindrer disse uigenkaldelige handlinger i at ske fra starten.
Et andet alternativ er at lade mennesker manuelt udføre alle opgaver, som agenter kunne klare, men det underminerer formålet med agenter. Agenter er værdifulde, fordi de kan håndtere rutineopgaver hurtigt og effektivt, så mennesker kan fokusere på beslutninger på et højere niveau. Målet med human-in-the-loop middleware er at finde balancen: lade agenter klare rutinearbejdet, men stoppe op for menneskelig gennemgang, når indsatsen er høj.
En tredje mulighed er at implementere guardrails eller valideringsregler, der forhindrer agenter i at tage uhensigtsmæssige handlinger. For eksempel kan du lave en regel, der forbyder agenter at sende e-mails til adresser uden for din organisation eller slette poster uden eksplicit bekræftelse. Guardrails er værdifulde og bør bruges sammen med human-in-the-loop middleware, men de har begrænsninger. Guardrails er typisk regelbaserede og kan ikke tage højde for alle tænkelige upassende handlinger. En agent kan overholde alle dine regler, men stadig foreslå en handling, der ikke er passende i en given kontekst. Menneskelig dømmekraft er mere fleksibel og situationsbestemt end regelbaserede guardrails, hvilket gør human-in-the-loop middleware så værdifuldt.
Best practices for implementering af human-in-the-loop workflows
Når du implementerer human-in-the-loop middleware i dine applikationer, kan flere best practices sikre, at dit system både er effektivt og sikkert. For det første bør du være strategisk omkring, hvilke værktøjer der kræver afbrydelser. At afbryde på hvert eneste værktøjskald vil skabe flaskehalse og nedsætte workflowet. Fokuser i stedet afbrydelser på værktøjer, der er dyre, risikable eller har store konsekvenser, hvis de udføres forkert. Læseoperationer kræver typisk ikke afbrydelse. Skrivende operationer, der ændrer data eller foretager eksterne handlinger, gør som regel.
For det andet: Giv klare oplysninger til de menneskelige gennemgåere. Når en afbrydelse sker, skal mennesket forstå, hvilken handling agenten foreslår og hvorfor. Sørg for, at dine afbrydelsesbeskrivelser er tydelige og giver relevant kontekst. Hvis agenten foreslår at sende en e-mail, vis hele e-mailindholdet. Hvis agenten vil slette en post, vis hvilken post og hvorfor. Jo mere kontekst, jo hurtigere og mere præcise beslutninger.
For det tredje: Gør godkendelsesprocessen så gnidningsfri som muligt. Mennesker godkender hurtigere, hvis processen er enkel og ikke kræver omfattende navigation eller dataindtastning. Giv tydelige knapper eller valgmuligheder for godkend, redigér og afvis. Hvis redigering er tilladt, gør det let for mennesker at ændre relevante parametre uden at skulle forstå kode eller datastrukturer.
For det fjerde: Brug afvisningsfeedback strategisk. Når du afviser en agents forslag, giv klar feedback om, hvorfor handlingen var upassende, og hvad agenten skal gøre i stedet. Denne feedback hjælper agenten med at lære og forbedre sin beslutningstagning. Over tid bør agenten, når den modtager feedback, blive bedre kalibreret til din organisations standarder og risikotolerance.
For det femte: Overvåg og analyser afbrydelsesmønstre. Hold øje med, hvilke værktøjer der oftest afbrydes, hvilke beslutninger (godkend, redig
Ofte stillede spørgsmål
Human-in-the-loop middleware er en komponent, der sætter AI-agentens eksekvering på pause før kørsel af specifikke værktøjer, så mennesker kan godkende, redigere eller afvise den foreslåede handling. Det tilføjer et ekstra sikkerhedslag til dyre eller risikable operationer.
Brug det til operationer med høj risiko, som f.eks. at sende e-mails, finansielle transaktioner, database-skrivninger eller enhver værktøjseksekvering, der kræver compliance-overvågning eller kan have store konsekvenser, hvis det udføres forkert.
De tre hovedsvarstyper er: Godkendelse (eksekvér værktøjet som foreslået), Redigering (justér værktøjsparametrene før eksekvering) og Afvisning (afvis eksekvering og send feedback tilbage til modellen for revision).
Importer HumanInTheLoopMiddleware fra langchain.agents.middleware, konfigurer det med de værktøjer, du vil afbryde på, og giv det til din agentoprettelsesfunktion. Du skal også bruge en checkpointer for at bevare tilstanden under afbrydelser.
Arshia er AI Workflow Engineer hos FlowHunt. Med en baggrund inden for datalogi og en passion for AI, specialiserer han sig i at skabe effektive workflows, der integrerer AI-værktøjer i daglige opgaver og øger produktivitet og kreativitet.
Arshia Kahani
AI Workflow Engineer
Automatisér dine AI-workflows sikkert med FlowHunt
Byg intelligente agenter med indbyggede godkendelsesworkflows og menneskelig overvågning. FlowHunt gør det nemt at implementere human-in-the-loop automatisering til dine forretningsprocesser.
Byg udvidelige AI-agenter: En dybdegående gennemgang af middleware-arkitektur
Lær hvordan LangChain 1.0's middleware-arkitektur revolutionerer agentudvikling og gør det muligt for udviklere at bygge kraftfulde, udvidelige deep agents med ...
Human-in-the-Loop (HITL) er en AI- og maskinlæringstilgang, der integrerer menneskelig ekspertise i træning, justering og anvendelse af AI-systemer, hvilket øge...
Forståelse af Human in the Loop for Chatbots: Styrkelse af AI med menneskelig ekspertise
Opdag vigtigheden og anvendelsen af Human in the Loop (HITL) i AI-chatbots, hvor menneskelig ekspertise forbedrer AI-systemer for øget nøjagtighed, etiske stand...
6 min læsning
AI
Chatbots
+5
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.