Sådan verificerer du AI-chatbottens ægthed
Lær gennemprøvede metoder til at verificere AI-chatbottens ægthed i 2025. Opdag tekniske verifikationsteknikker, sikkerhedstjek og bedste praksis for at identif...
10 min læsning
Lær omfattende metoder til at måle AI-helpdesk chatbot nøjagtighed i 2025. Opdag præcision, recall, F1-scorer, brugertilfredshedsmålinger og avancerede evalueringsmetoder med FlowHunt.
Mål AI-helpdesk chatbot nøjagtighed ved hjælp af flere metrikker, herunder beregning af præcision og recall, forvekslingsmatricer, brugertilfredshedsscorer, løsningsrater og avancerede LLM-baserede evalueringsmetoder. FlowHunt tilbyder omfattende værktøjer til automatiseret nøjagtighedsvurdering og performanceovervågning.
At måle nøjagtigheden af en AI-helpdesk chatbot er afgørende for at sikre, at den leverer pålidelige og hjælpsomme svar på kundernes henvendelser. I modsætning til simple klassifikationsopgaver omfatter chatbot-nøjagtighed flere dimensioner, der skal vurderes samlet for at give et komplet billede af performance. Processen indebærer analyse af, hvor godt chatbotten forstår brugerens forespørgsler, giver korrekte oplysninger, effektivt løser problemer og opretholder brugertilfredshed gennem hele interaktionen. En omfattende strategi for nøjagtighedsmåling kombinerer kvantitative metrikker med kvalitativ feedback for at identificere styrker og områder, der kræver forbedring.
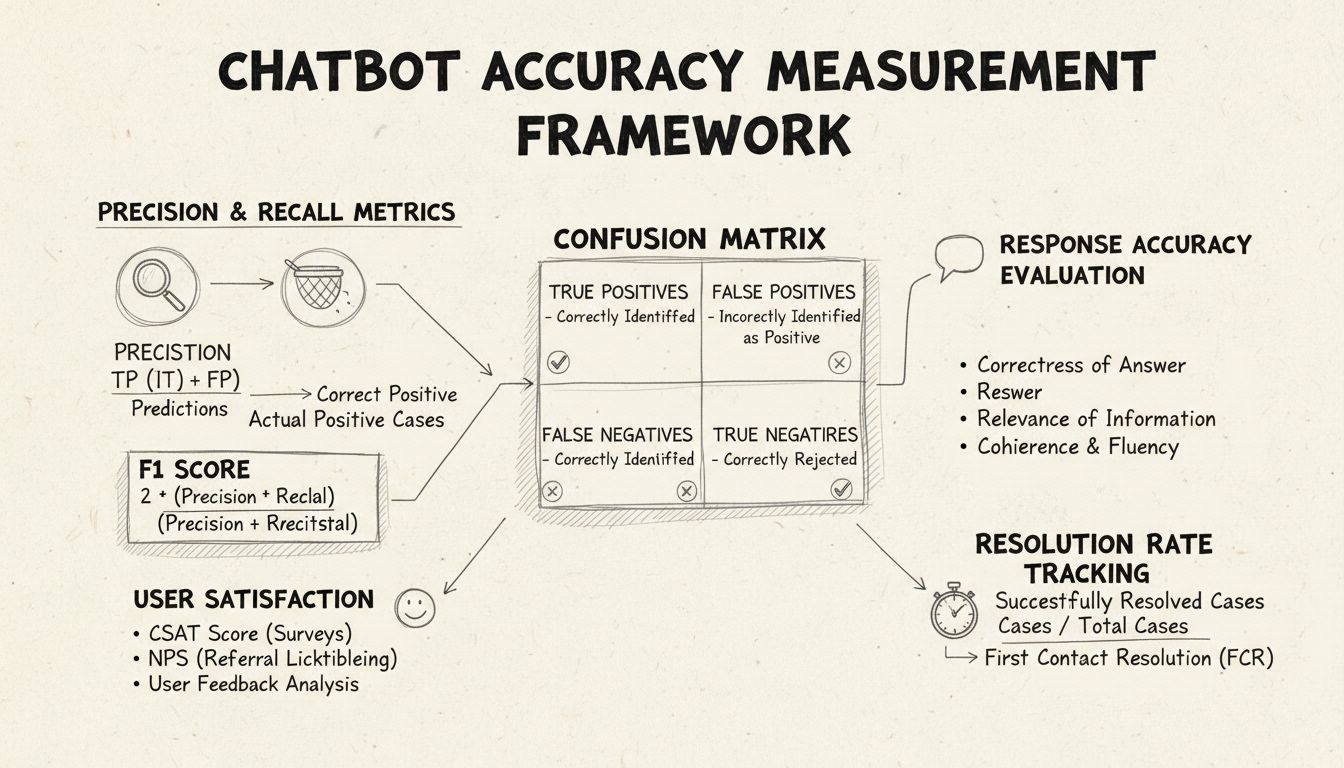
Præcision og recall er grundlæggende metrikker udledt fra forvekslingsmatricen, der måler forskellige aspekter af chatbot-performance. Præcision repræsenterer andelen af korrekte svar ud af alle de svar, chatbotten har givet, udregnet med formlen: Præcision = Sande Positiver / (Sande Positiver + Falske Positiver). Denne metrik svarer på spørgsmålet: “Når chatbotten giver et svar, hvor ofte er det korrekt?” En høj præcision indikerer, at chatbotten sjældent giver forkerte oplysninger, hvilket er afgørende for at opretholde brugerens tillid i helpdesk-sammenhænge.
Recall, også kendt som sensitivitet, måler andelen af korrekte svar ud af alle de korrekte svar, chatbotten burde have givet, med formlen: Recall = Sande Positiver / (Sande Positiver + Falske Negativer). Denne metrik belyser, om chatbotten med succes identificerer og svarer på alle legitime kundeproblemer. I helpdesk-kontekster sikrer høj recall, at kunderne får hjælp til deres problemer i stedet for at få at vide, at chatbotten ikke kan hjælpe, når den faktisk kunne. Forholdet mellem præcision og recall skaber et naturligt trade-off: optimering af den ene reducerer ofte den anden, hvilket kræver omhyggelig balance afhængigt af dine specifikke forretningsprioriteter.
F1-scoren giver en samlet metrik, der balancerer både præcision og recall, udregnet som det harmoniske gennemsnit: F1 = 2 × (Præcision × Recall) / (Præcision + Recall). Denne metrik er især værdifuld, når du har brug for en samlet indikator for performance eller arbejder med ubalancerede datasæt, hvor én klasse er markant større end de andre. For eksempel, hvis din chatbot håndterer 1.000 rutineforespørgsler, men kun 50 komplekse eskalationer, forhindrer F1-scoren, at metrikken bliver skæv på grund af majoritetsklassen. F1-scoren går fra 0 til 1, hvor 1 repræsenterer perfekt præcision og recall, hvilket gør den intuitiv for interessenter at forstå den samlede chatbot-performance ved første øjekast.
Forvekslingsmatricen er et fundamentalt værktøj, der opdeler chatbot-performance i fire kategorier: Sande Positiver (korrekte svar på gyldige forespørgsler), Sande Negativer (korrekt afvisning af irrelevante spørgsmål), Falske Positiver (ukorrekte svar) og Falske Negativer (missede muligheder for at hjælpe). Denne matrix afslører specifikke mønstre i chatbot-fejl og muliggør målrettede forbedringer. Hvis matricen fx viser høje falske negativer på faktureringsforespørgsler, kan du identificere, at chatbot-trejningsdata mangler tilstrækkelige eksempler på fakturering og skal styrkes på dette område.
| Metrik | Definition | Beregning | Forretningsmæssig betydning |
|---|---|---|---|
| Sande Positiver (TP) | Korrekte svar på gyldige forespørgsler | Optalt direkte | Skaber kundetillid |
| Sande Negativer (TN) | Korrekt afvisning af irrelevante spørgsmål | Optalt direkte | Forhindrer misinformation |
| Falske Positiver (FP) | Forkerte svar givet | Optalt direkte | Skader troværdighed |
| Falske Negativer (FN) | Missede muligheder for at hjælpe | Optalt direkte | Sænker tilfredshed |
| Præcision | Kvalitet af positive forudsigelser | TP / (TP + FP) | Pålidelighedsmetrik |
| Recall | Dækning af egentlige positive | TP / (TP + FN) | Komplethedsmetrik |
| Nøjagtighed | Samlet korrekthed | (TP + TN) / Total | Generel performance |
Svarnøjagtighed måler, hvor ofte chatbotten leverer faktuelt korrekte oplysninger, der direkte adresserer brugerens forespørgsel. Dette går ud over simpel mønstergenkendelse ved at vurdere, om indholdet er korrekt, aktuelt og passende for konteksten. Manuelle gennemgange involverer, at menneskelige evalueringer vurderer et tilfældigt udsnit af samtaler og sammenligner chatbot-svar med en foruddefineret vidensbase af korrekte svar. Automatiserede sammenligningsmetoder kan implementeres med NLP-teknikker til at matche svar med forventede svar i dit system, men kræver omhyggelig kalibrering for at undgå falske negativer, når chatbotten leverer korrekte svar med andre formuleringer end referencesvaret.
Svarrelevans vurderer, om chatbotens svar faktisk adresserer det, brugeren spurgte om, også selvom svaret ikke er helt korrekt. Denne dimension opfanger situationer, hvor chatbotten leverer hjælpsomme oplysninger, der – selvom det ikke er det præcise svar – bringer samtalen tættere på en løsning. NLP-baserede metoder som cosinus-lighed kan måle semantisk lighed mellem brugerens spørgsmål og chatbot-svaret, hvilket giver en automatiseret relevansscore. Brugerfeedback-mekanismer, fx thumbs-up/thumbs-down efter hver interaktion, tilbyder direkte relevansvurdering fra de vigtigste – dine kunder. Disse feedbacksignaler bør løbende indsamles og analyseres for at identificere mønstre i, hvilke forespørgsler chatbotten håndterer godt kontra dårligt.
Kundetilfredshedsscore (CSAT) måler brugertilfredshed med chatbot-interaktioner via direkte spørgeskemaer – typisk på en skala fra 1-5 eller en simpel tilfredshedsvurdering. Efter hver interaktion bliver brugeren bedt om at vurdere deres tilfredshed, hvilket giver øjeblikkelig feedback på, om chatbotten opfyldte deres behov. CSAT-scorer over 80% indikerer generelt stærk performance, mens scorer under 60% signalerer væsentlige problemer, der kræver undersøgelse. Fordelen ved CSAT er dens enkelhed og tydelighed – brugerne angiver eksplicit, om de er tilfredse – men den kan påvirkes af faktorer ud over chatbot-nøjagtighed, såsom problemets kompleksitet eller brugerens forventninger.
Net Promoter Score måler sandsynligheden for, at brugerne vil anbefale chatbotten til andre, udregnet ved at spørge: “Hvor tilbøjelig er du til at anbefale denne chatbot til en kollega?” på en skala fra 0-10. Respondenter, der svarer 9-10, er promotere, 7-8 er passive, og 0-6 er detraktorer. NPS = (Promotere - Detraktorer) / Samlet antal respondenter × 100. Denne metrik korrelerer stærkt med langsigtet kundeloyalitet og giver indsigt i, om chatbotten skaber positive oplevelser, brugerne ønsker at dele. En NPS over 50 anses for fremragende, mens negativ NPS indikerer alvorlige performanceproblemer.
Sentimentanalyse undersøger den følelsesmæssige tone i brugermeddelelser før og efter chatbot-interaktioner for at vurdere tilfredshed. Avancerede NLP-teknikker klassificerer beskeder som positive, neutrale eller negative og afslører, om brugerne bliver mere tilfredse eller frustrerede under samtalen. Et positivt sentiment-skifte indikerer, at chatbotten med succes løste bekymringer, mens negative skift antyder, at chatbotten måske har frustreret brugerne eller ikke opfyldt deres behov. Denne metrik opfanger emotionelle dimensioner, som traditionelle nøjagtighedsmålinger overser, og giver værdifuld kontekst til forståelse af brugeroplevelsens kvalitet.
Førstekontaktløsningsraten måler procentdelen af kundeproblemer, som chatbotten løser uden behov for eskalering til menneskelige agenter. Denne metrik har direkte indflydelse på operationel effektivitet og kundetilfredshed, da kunder foretrækker, at problemer løses med det samme frem for at blive videresendt. FCR-rater over 70% indikerer stærk chatbot-performance, mens rater under 50% antyder, at chatbotten mangler viden eller evne til at håndtere almindelige henvendelser. Opfølgning på FCR pr. problemkategori afslører, hvilke typer problemer chatbotten håndterer godt, og hvilke der kræver menneskelig indgriben, hvilket guider træning og forbedring af vidensbasen.
Eskaleringsraten måler, hvor ofte chatbotten overdrager samtaler til menneskelige agenter, mens fallback-frekvensen sporer, hvor ofte chatbotten falder tilbage på generiske svar som “Jeg forstår ikke” eller “Vær venlig at omformulere dit spørgsmål.” Høje eskaleringsrater (over 30%) tyder på, at chatbotten mangler viden eller selvtillid i mange scenarier, mens høje fallback-rater antyder dårlig hensigtsgenkendelse eller utilstrækkelige træningsdata. Disse metrikker identificerer specifikke huller i chatbot-evner, som kan løses gennem udvidelse af vidensbase, model-genoptræning eller forbedret naturlig sprogforståelse.
Svartid måler, hvor hurtigt chatbotten svarer på brugermeddelelser – typisk målt i millisekunder til sekunder. Brugere forventer næsten øjeblikkelige svar; forsinkelser over 3-5 sekunder påvirker tilfredsheden markant. Håndteringstid måler den samlede varighed fra en bruger starter kontakten, til problemet er løst eller eskaleret, hvilket giver indsigt i chatbot-effektivitet. Kortere håndteringstider viser, at chatbotten hurtigt forstår og løser problemer, mens længere tider kan antyde, at chatbotten kræver flere afklaringsrunder eller kæmper med komplekse forespørgsler. Disse metrikker bør spores separat for forskellige problemkategorier, da komplekse tekniske problemer naturligt kræver længere håndteringstid end simple FAQ-spørgsmål.
LLM As a Judge repræsenterer en sofistikeret evalueringsmetode, hvor én stor sprogmodel vurderer kvaliteten af et andet AI-systems output. Denne metode er særlig effektiv til at evaluere chatbot-svar på tværs af flere kvalitetsdimensioner samtidig, såsom nøjagtighed, relevans, sammenhæng, flydende sprog, sikkerhed, fuldstændighed og tone. Forskning viser, at LLM-dommere kan opnå op til 85% overensstemmelse med menneskelige evalueringer, hvilket gør dem til et skalerbart alternativ til manuel gennemgang. Metoden indebærer at definere specifikke evalueringskriterier, formulere detaljerede dommer-prompter med eksempler, give dommeren både den oprindelige brugerforespørgsel og chatbot-svaret samt modtage strukturerede scorer eller detaljeret feedback.
LLM As a Judge-processen benytter typisk to evalueringsmetoder: evaluering af enkeltoutput, hvor dommeren scorer et individuelt svar enten uden reference (referenceløs evaluering) eller ved sammenligning med et forventet svar (referencebaseret), og parvis sammenligning, hvor dommeren sammenligner to outputs for at finde det bedste. Denne fleksibilitet muliggør evaluering af både absolut performance og relative forbedringer ved test af forskellige chatbot-versioner eller -konfigurationer. FlowHunt-platformen understøtter LLM As a Judge-implementering via sin drag-and-drop-grænseflade, integration med førende LLM’er som ChatGPT og Claude samt CLI-værktøj til avanceret rapportering og automatiserede evalueringer.
Ud over basale nøjagtighedsberegninger afslører detaljeret analyse af forvekslingsmatricen specifikke mønstre i chatbot-fejl. Ved at undersøge, hvilke typer forespørgsler der skaber falske positiver kontra falske negativer, kan du identificere systematiske svagheder. Hvis matricen fx viser, at chatbotten ofte fejlklassificerer faktureringsspørgsmål som teknisk support, afslører det en ubalance i træningsdata eller et hensigtsgenkendelsesproblem specifikt for faktureringsdomænet. Oprettelse af separate forvekslingsmatricer for forskellige problemkategorier muliggør målrettede forbedringer frem for generel model-genoptræning.
A/B-test sammenligner forskellige versioner af chatbotten for at afgøre, hvilken der klarer sig bedst på nøglemetrikker. Det kan indebære test af forskellige svartemplates, vidensbasekonfigurationer eller underliggende sprogmodeller. Ved tilfældigt at dirigere en del af trafikken til hver version og sammenligne metrikker som FCR-rate, CSAT-scoring og svarnøjagtighed kan du træffe datadrevne beslutninger om, hvilke forbedringer der skal implementeres. A/B-test bør køre i tilstrækkelig lang tid til at opfange naturlig variation i brugerforespørgsler og sikre statistisk signifikans af resultaterne.
FlowHunt tilbyder en integreret platform til at bygge, implementere og evaluere AI-helpdesk chatbots med avancerede nøjagtighedsmålingsfunktioner. Platformens visuelle builder gør det muligt for ikke-tekniske brugere at oprette sofistikerede chatbot-flows, mens AI-komponenterne integrerer med førende sprogmodeller som ChatGPT og Claude. FlowHunts evalueringsværktøj understøtter implementering af LLM As a Judge-metodologi, så du kan definere brugerdefinerede evalueringskriterier og automatisk vurdere chatbot-performance på tværs af hele din samtaledatasæt.
For at implementere omfattende nøjagtighedsmåling med FlowHunt, begynd med at definere dine specifikke evalueringskriterier i overensstemmelse med forretningsmål – hvad enten du prioriterer nøjagtighed, hastighed, brugertilfredshed eller løsningsrater. Konfigurer platformens vurderende LLM med detaljerede prompts, der præciserer, hvordan svar skal evalueres, inklusiv konkrete eksempler på gode og dårlige svar. Upload dit samtaledatasæt eller tilslut live trafik, og kør evalueringer for at generere detaljerede rapporter, der viser performance på alle metrikker. FlowHunts dashboard giver realtidsindsigt i chatbot-performance, hvilket muliggør hurtig identifikation af problemer og validering af forbedringer.
Etabler en baseline-måling før implementering af forbedringer for at skabe et referencepunkt, når du skal vurdere effekten af ændringer. Indsaml målinger løbende i stedet for periodisk, så du tidligt kan opdage performance-forringelser på grund af datadrift eller modelnedbrydning. Implementér feedbacksløjfer, hvor brugerbedømmelser og rettelser automatisk føres tilbage i træningsprocessen og løbende forbedrer chatbot-nøjagtigheden. Segmentér metrikker efter problemkategori, brugertype og tidsperiode for at identificere specifikke områder, der kræver opmærksomhed, frem for kun at bruge aggregerede statistikker.
Sørg for, at dit evalueringsdatasæt repræsenterer rigtige brugerforespørgsler og forventede svar – undgå kunstige testcases, der ikke afspejler faktisk brug. Valider regelmæssigt automatiske metrikker mod menneskelig vurdering ved at lade evaluatører manuelt gennemgå et udsnit af samtaler, så dit målesystem forbliver kalibreret til faktisk kvalitet. Dokumentér tydeligt din målemetode og metrikdefinitioner, så evalueringen er konsistent over tid og resultaterne kan kommunikeres klart til interessenter. Fastlæg endelig performancemål for hver metrik i overensstemmelse med forretningsmål, så der skabes ansvarlighed for løbende forbedring og klare mål for optimeringsarbejdet.
FlowHunts avancerede AI-automationsplatform hjælper dig med at skabe, implementere og evaluere high-performance helpdesk chatbots med indbyggede nøjagtighedsmålingsværktøjer og LLM-baserede evalueringsmuligheder.
Lær gennemprøvede metoder til at verificere AI-chatbottens ægthed i 2025. Opdag tekniske verifikationsteknikker, sikkerhedstjek og bedste praksis for at identif...
Lær omfattende teststrategier for AI-chatbots, herunder funktionelle, ydelses-, sikkerheds- og brugervenlighedstest. Opdag bedste praksis, værktøjer og rammer, ...
Opdag de bedste AI chatbot-platforme med indbygget A/B-testning. Sammenlign Dialogflow, Botpress, ManyChat, Intercom og flere. Lær, hvordan du optimerer chatbot...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.