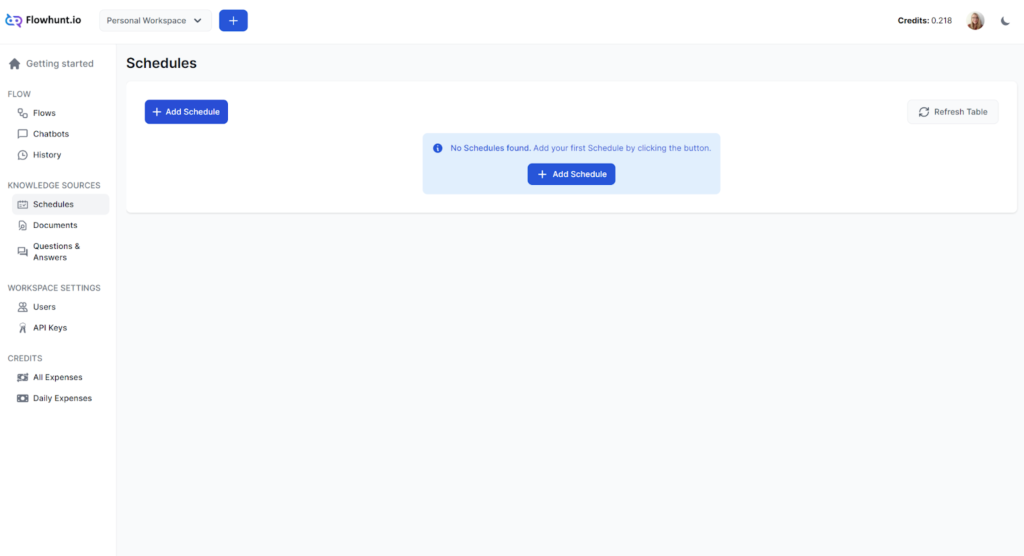
Tidsplaner
Tidsplan-funktionen i FlowHunt lader dig periodisk crawle domæner og YouTube-kanaler, så dine chatbots og flows altid er opdaterede med den nyeste information. ...
3 min læsning
AI
Schedules
+4
Lær, hvordan du opsætter automatiske tidsplaner for at crawle websites, sitemaps, domæner og YouTube-kanaler, så din AI Agent-vidensbase altid er opdateret.
FlowHunts Tidsplan-funktion gør det muligt at automatisere crawling og indeksering af websites, sitemaps, domæner og YouTube-kanaler. Dette sikrer, at din AI Agent-vidensbase forbliver opdateret med nyt indhold uden manuel indsats.
Automatiseret crawling:
Opsæt tilbagevendende crawls, der kører dagligt, ugentligt, månedligt eller årligt for at holde din vidensbase opdateret.
Flere crawl-typer:
Vælg mellem domæne-crawl, sitemap-crawl, URL-crawl eller YouTube-kanal-crawl afhængigt af din indholdskilde.
Avancerede muligheder:
Konfigurer browser-rendering, linkfølgning, skærmbilleder, proxy-rotation og URL-filtrering for optimale resultater.
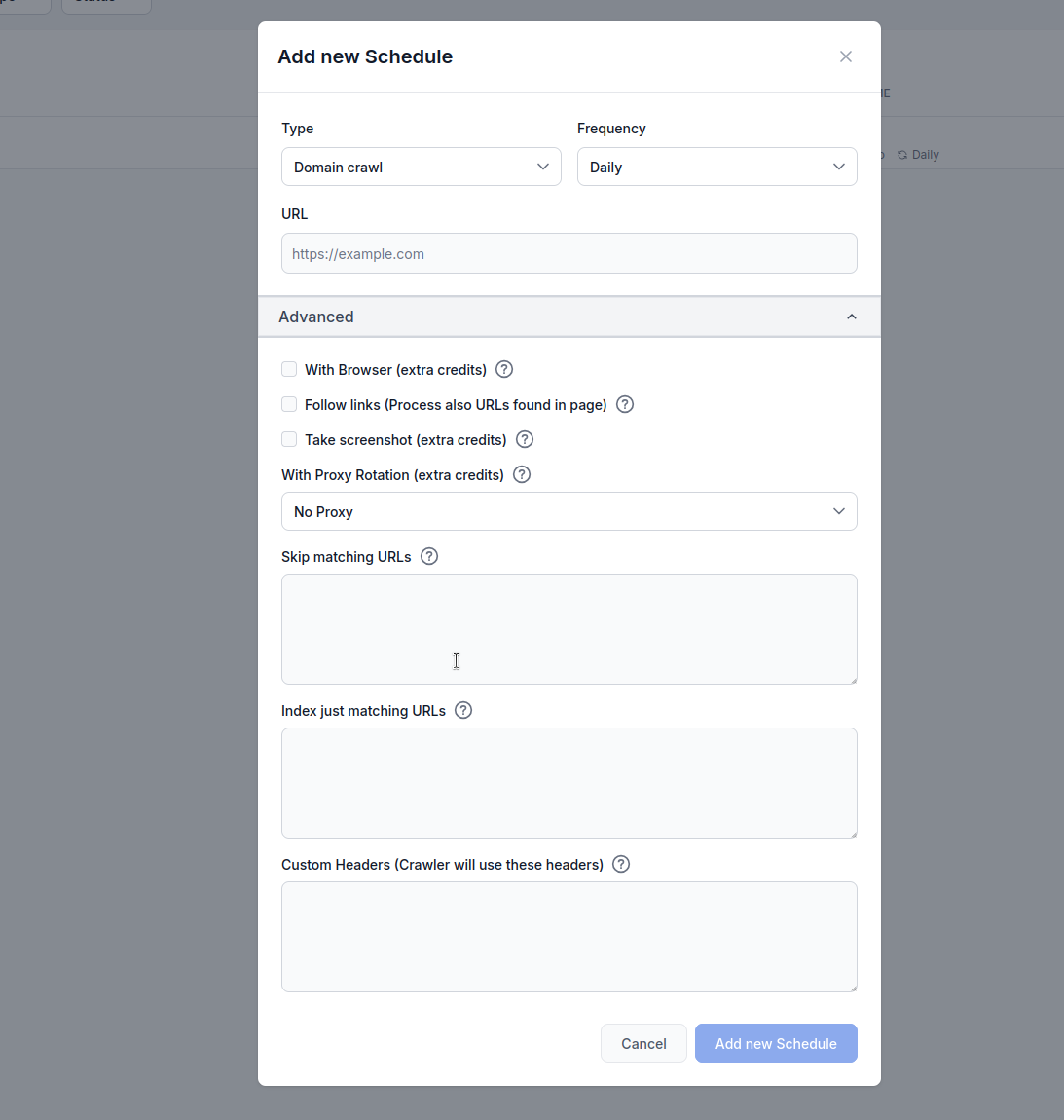
Type: Vælg din crawl-metode:
Frekvens: Angiv hvor ofte crawlen skal køre:
URL: Indtast mål-URL, domæne eller YouTube-kanal, der skal crawles
Med browser (ekstra credits): Aktivér ved crawling af JavaScript-tunge hjemmesider, der kræver fuld browser-rendering. Denne mulighed er langsommere og dyrere, men nødvendig for sider, der loader indhold dynamisk.
Følg links (ekstra credits): Behandl yderligere URLs fundet på siderne. Nyttigt, når sitemaps ikke indeholder alle URLs, men kan bruge mange credits, da den crawler opdagede links.
Tag skærmbillede (ekstra credits): Tag visuelle skærmbilleder under crawling. Hjælpsomt for hjemmesider uden og:image eller hvor visuel kontekst er nødvendig for AI-behandling.
Med proxy-rotation (ekstra credits): Roter IP-adresser for hver anmodning for at undgå opdagelse af Web Application Firewalls (WAF) eller anti-botsystemer.
Spring matchende URLs over: Indtast strenge (én pr. linje) for at udelukke URLs, der indeholder disse mønstre, fra crawling. Eksempel:
/admin/
/login
.pdf
Dette eksempel forklarer, hvad der sker, når du bruger FlowHunts Tidsplan-funktion til at crawle flowhunt.io-domænet, mens /blog er indsat som et matchende URL-mønster, der skal springes over i URL-filtreringen.
Konfigurationsindstillinger
flowhunt.io/blogHvad sker der
Crawl-initiering:
flowhunt.io og målretter alle tilgængelige sider på domænet (fx flowhunt.io, flowhunt.io/features, flowhunt.io/pricing osv.).URL-filtrering anvendt:
/blog./blog (fx flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/category), udelades fra crawlen.flowhunt.io/about, flowhunt.io/contact eller flowhunt.io/docs, crawles, da de ikke matcher /blog-mønstret.Crawl-udførelse:
flowhunt.io og indekserer deres indhold til din AI Agent-vidensbase.Resultat:
flowhunt.io, undtagen alt under /blog-stien./blog) uden manuel indsats.Indekser kun matchende URLs: Indtast strenge (én pr. linje) for kun at crawle URLs, der indeholder disse mønstre. Eksempel:
/blog/
/articles/
/knowledge/
Konfigurationsindstillinger
flowhunt.io/blog/
/articles/
/knowledge/
Crawl-initiering:
flowhunt.io og målretter alle tilgængelige sider på domænet (fx flowhunt.io, flowhunt.io/blog, flowhunt.io/articles osv.).URL-filtrering anvendt:
/blog/, /articles/ og /knowledge/.flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guide), inkluderes i crawlen.flowhunt.io/about, flowhunt.io/pricing eller flowhunt.io/contact, udelades, da de ikke matcher de angivne mønstre.Crawl-udførelse:
/blog/, /articles/ eller /knowledge/, og indekserer deres indhold til din AI Agent-vidensbase.Resultat:
flowhunt.io-sider under stierne /blog/, /articles/ og /knowledge/.Brugerdefinerede headers:
Tilføj brugerdefinerede HTTP-headers til crawl-anmodninger. Formatér som HEADER=Værdi (én pr. linje):
Denne funktion er særdeles nyttig til at tilpasse crawls til specifikke hjemmesidekrav. Ved at aktivere brugerdefinerede headers kan brugere autentificere anmodninger for at få adgang til begrænset indhold, efterligne bestemte browseradfærd eller overholde en hjemmesides API- eller adgangspolitikker. For eksempel kan en Authorization-header give adgang til beskyttede sider, mens en brugerdefineret User-Agent kan hjælpe med at undgå bot-detektion eller sikre kompatibilitet med sider, der begrænser visse crawlers. Denne fleksibilitet sikrer mere nøjagtig og omfattende datainhentning, hvilket gør det lettere at indeksere relevant indhold til en AI Agent-vidensbase og samtidig overholde en hjemmesides sikkerheds- eller adgangsprotokoller.
MYHEADER=Enhver værdi
Authorization=Bearer token123
User-Agent=Custom crawler
Start din gratis prøveperiode i dag og se resultater inden for få dage.
Navigér til Tidsplaner i dit FlowHunt-dashboard
Klik på “Tilføj ny tidsplan”
Konfigurer grundindstillinger:
Udvid Avancerede muligheder om nødvendigt:
Klik på “Tilføj ny tidsplan” for at aktivere
For de fleste websites:
For JavaScript-tunge sider:
For store sites:
For e-handel eller dynamisk indhold:
Få de seneste tips, trends og tilbud gratis.
Avancerede funktioner bruger ekstra credits:
Overvåg dit credit-forbrug og justér tidsplaner efter behov og budget.
Crawl-fejl:
For mange/få sider:
Manglende indhold:
Tidsplan-funktionen i FlowHunt lader dig periodisk crawle domæner og YouTube-kanaler, så dine chatbots og flows altid er opdaterede med den nyeste information. ...
Forvandl din indholdsstrategi med vores AI-drevne Indholdsplanlægger, der kombinerer avancerede AI-funktioner med realtids Google-research. Skab datadrevne, str...

Integrer FlowHunt med Calendly for at automatisere mødeplanlægning, håndtere aftaler og synkronisere kalendere ubesværet med AI-drevne arbejdsgange.