Transformador
Un modelo transformador es un tipo de red neuronal específicamente diseñada para manejar datos secuenciales, como texto, voz o datos de series temporales. A dif...
3 min de lectura
Transformer
Neural Networks
+3
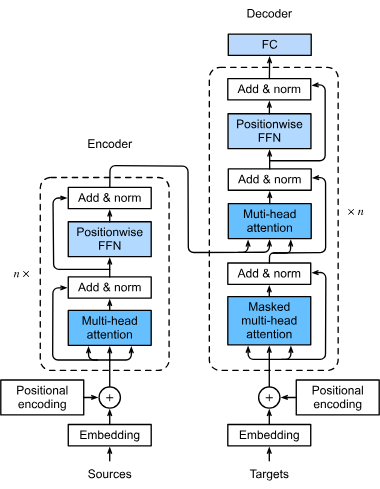
Los transformadores son redes neuronales innovadoras que aprovechan la autoatención para el procesamiento paralelo de datos, impulsando modelos como BERT y GPT en PLN, visión y más allá.
El primer paso en la cadena de procesamiento de un modelo transformador implica convertir palabras o tokens de una secuencia de entrada en vectores numéricos, conocidos como embeddings. Estos embeddings capturan significados semánticos y son cruciales para que el modelo entienda las relaciones entre los tokens. Esta transformación es esencial ya que permite que el modelo procese datos de texto en una forma matemática.
Los transformadores no procesan datos de manera secuencial de forma inherente; por ello, se utiliza la codificación posicional para inyectar información sobre la posición de cada token en la secuencia. Esto es vital para mantener el orden de la secuencia, lo cual es crucial para tareas como la traducción de idiomas donde el contexto puede depender del orden de las palabras.
El mecanismo de atención de múltiples cabezas es un componente sofisticado de los transformadores que permite al modelo enfocarse en diferentes partes de la secuencia de entrada simultáneamente. Al calcular múltiples puntuaciones de atención, el modelo puede captar diversas relaciones y dependencias en los datos, mejorando su capacidad para comprender y generar patrones de datos complejos.
Los transformadores suelen seguir una arquitectura codificador-decodificador:
Tras el mecanismo de atención, los datos pasan por redes neuronales feedforward, que aplican transformaciones no lineales a los datos, ayudando al modelo a aprender patrones complejos. Estas redes procesan aún más los datos para refinar la salida generada por el modelo.
Estas técnicas se incorporan para estabilizar y acelerar el proceso de entrenamiento. La normalización de capas asegura que las salidas permanezcan dentro de un cierto rango, facilitando el entrenamiento eficiente del modelo. Las conexiones residuales permiten que los gradientes fluyan a través de las redes sin desvanecerse, lo que mejora el entrenamiento de redes neuronales profundas.
Los transformadores operan sobre secuencias de datos, que pueden ser palabras en una oración u otra información secuencial. Aplican autoatención para determinar la relevancia de cada parte de la secuencia respecto a las demás, permitiendo que el modelo se enfoque en los elementos cruciales que afectan la salida.
En la autoatención, cada token de la secuencia se compara con todos los demás para calcular puntuaciones de atención. Estas puntuaciones indican la importancia de cada token en el contexto de los demás, permitiendo que el modelo se centre en las partes más relevantes de la secuencia. Esto es fundamental para comprender el contexto y significado en tareas de lenguaje.
Estos son los bloques de construcción de un modelo transformador, compuestos por capas de autoatención y feedforward. Se apilan múltiples bloques para formar modelos de aprendizaje profundo capaces de captar patrones complejos en los datos. Este diseño modular permite que los transformadores escalen eficientemente con la complejidad de la tarea.
Los transformadores son más eficientes que las RNN y las CNN debido a su capacidad de procesar secuencias completas a la vez. Esta eficiencia permite escalar hasta modelos muy grandes, como GPT-3, que tiene 175 mil millones de parámetros. La escalabilidad de los transformadores les permite manejar grandes cantidades de datos de manera efectiva.
Los modelos tradicionales tienen dificultades con las dependencias a largo alcance debido a su naturaleza secuencial. Los transformadores superan esta limitación mediante la autoatención, que puede considerar todas las partes de la secuencia simultáneamente. Esto los hace especialmente eficaces para tareas que requieren comprender el contexto en largas secuencias de texto.
Aunque inicialmente fueron diseñados para PLN, los transformadores se han adaptado a diversas aplicaciones, incluyendo visión por computadora, plegamiento de proteínas e incluso pronóstico de series temporales. Esta versatilidad demuestra la amplia aplicabilidad de los transformadores en diferentes dominios.
Los transformadores han mejorado significativamente el rendimiento de tareas de PLN como traducción, resumen y análisis de sentimientos. Modelos como BERT y GPT son ejemplos destacados que aprovechan la arquitectura transformadora para comprender y generar texto similar al humano, estableciendo nuevos referentes en PLN.
En la traducción automática, los transformadores sobresalen al comprender el contexto de las palabras dentro de una oración, permitiendo traducciones más precisas en comparación con métodos anteriores. Su capacidad para procesar frases completas a la vez permite traducciones más coherentes y contextualizadas.
Los transformadores pueden modelar las secuencias de aminoácidos en proteínas, ayudando en la predicción de estructuras proteicas, lo cual es crucial para el descubrimiento de fármacos y la comprensión de procesos biológicos. Esta aplicación destaca el potencial de los transformadores en la investigación científica.
Al adaptar la arquitectura transformadora, es posible predecir valores futuros en datos de series temporales, como la previsión de demanda eléctrica, analizando secuencias pasadas. Esto abre nuevas posibilidades para los transformadores en campos como finanzas y gestión de recursos.
Los modelos BERT están diseñados para comprender el contexto de una palabra analizando las palabras circundantes, lo que los hace altamente efectivos para tareas que requieren entender las relaciones entre palabras en una oración. Este enfoque bidireccional permite que BERT capture el contexto de manera más efectiva que los modelos unidireccionales.
Los modelos GPT son autorregresivos, generando texto al predecir la siguiente palabra en una secuencia basada en las palabras anteriores. Se usan ampliamente en aplicaciones como autocompletado de texto y generación de diálogos, demostrando su capacidad para producir texto similar al humano.
Inicialmente desarrollados para PLN, los transformadores se han adaptado a tareas de visión por computadora. Los Vision Transformers procesan datos de imágenes como secuencias, permitiéndoles aplicar técnicas de transformadores a entradas visuales. Esta adaptación ha impulsado los avances en reconocimiento y procesamiento de imágenes.
El entrenamiento de grandes modelos de transformadores requiere recursos computacionales sustanciales, a menudo involucrando grandes conjuntos de datos y hardware potente como GPUs. Esto representa un desafío en términos de costo y accesibilidad para muchas organizaciones.
A medida que los transformadores se vuelven más prevalentes, cuestiones como el sesgo en los modelos de IA y el uso ético del contenido generado por IA adquieren cada vez más importancia. Los investigadores trabajan en métodos para mitigar estos problemas y garantizar un desarrollo responsable de la IA, resaltando la necesidad de marcos éticos en la investigación en IA.
La versatilidad de los transformadores sigue abriendo nuevas vías de investigación y aplicación, desde mejorar chatbots impulsados por IA hasta optimizar el análisis de datos en campos como la salud y las finanzas. El futuro de los transformadores promete posibilidades emocionantes de innovación en diversas industrias.
En conclusión, los transformadores representan un avance significativo en la tecnología de IA, ofreciendo capacidades sin precedentes en el procesamiento de datos secuenciales. Su arquitectura innovadora y eficiencia han establecido un nuevo estándar en el campo, impulsando las aplicaciones de IA a nuevos niveles. Ya sea en la comprensión del lenguaje, la investigación científica o el procesamiento de datos visuales, los transformadores continúan redefiniendo lo que es posible en el ámbito de la inteligencia artificial.
Los transformadores han revolucionado el campo de la inteligencia artificial, particularmente en el procesamiento y comprensión del lenguaje natural. El artículo “AI Thinking: A framework for rethinking artificial intelligence in practice” de Denis Newman-Griffis (publicado en 2024) explora un novedoso marco conceptual llamado AI Thinking. Este marco modela las decisiones clave y consideraciones involucradas en el uso de la IA desde diferentes perspectivas disciplinares, abordando competencias en la motivación del uso de IA, la formulación de métodos de IA y la ubicación de la IA en contextos sociotécnicos. Su objetivo es unir disciplinas académicas y redefinir el futuro de la IA en la práctica. Leer más .
Otra contribución significativa se observa en “Artificial intelligence and the transformation of higher education institutions” de Evangelos Katsamakas et al. (publicado en 2024), que utiliza un enfoque de sistemas complejos para mapear los mecanismos de retroalimentación causal de la transformación de la IA en las instituciones de educación superior (HEIs). El estudio analiza las fuerzas que impulsan la transformación de la IA y su impacto en la creación de valor, enfatizando la necesidad de que las HEIs se adapten a los avances tecnológicos en IA gestionando, a la vez, la integridad académica y los cambios en el empleo. Leer más .
En el ámbito del desarrollo de software, el artículo “Can Artificial Intelligence Transform DevOps?” de Mamdouh Alenezi y colegas (publicado en 2022) examina la intersección entre la IA y DevOps. El estudio destaca cómo la IA puede mejorar la funcionalidad de los procesos DevOps, facilitando una entrega de software eficiente. Subraya las implicaciones prácticas para desarrolladores de software y empresas al aprovechar la IA para transformar las prácticas DevOps. Leer más
Los transformadores son una arquitectura de red neuronal introducida en 2017 que utiliza mecanismos de autoatención para el procesamiento paralelo de datos secuenciales. Han revolucionado la inteligencia artificial, particularmente en el procesamiento de lenguaje natural y la visión por computadora.
A diferencia de las RNN y las CNN, los transformadores procesan todos los elementos de una secuencia simultáneamente usando autoatención, lo que permite mayor eficiencia, escalabilidad y la capacidad de capturar dependencias a largo alcance.
Los transformadores se usan ampliamente en tareas de PLN como traducción, resumen y análisis de sentimientos, así como en visión por computadora, predicción de estructuras de proteínas y pronóstico de series temporales.
Entre los modelos destacados de transformadores se encuentran BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) y Vision Transformers para el procesamiento de imágenes.
Los transformadores requieren recursos computacionales significativos para entrenar y desplegar. También plantean consideraciones éticas como el posible sesgo en los modelos de IA y el uso responsable del contenido generado por IA.
Chatbots inteligentes y herramientas de IA bajo un mismo techo. Conecta bloques intuitivos para convertir tus ideas en Flujos automatizados.
Un modelo transformador es un tipo de red neuronal específicamente diseñada para manejar datos secuenciales, como texto, voz o datos de series temporales. A dif...
Un Transformador Generativo Preentrenado (GPT) es un modelo de IA que aprovecha técnicas de aprendizaje profundo para producir texto que imita de cerca la escri...
La Generación de Texto con Modelos de Lenguaje de Gran Tamaño (LLMs) se refiere al uso avanzado de modelos de aprendizaje automático para producir texto similar...