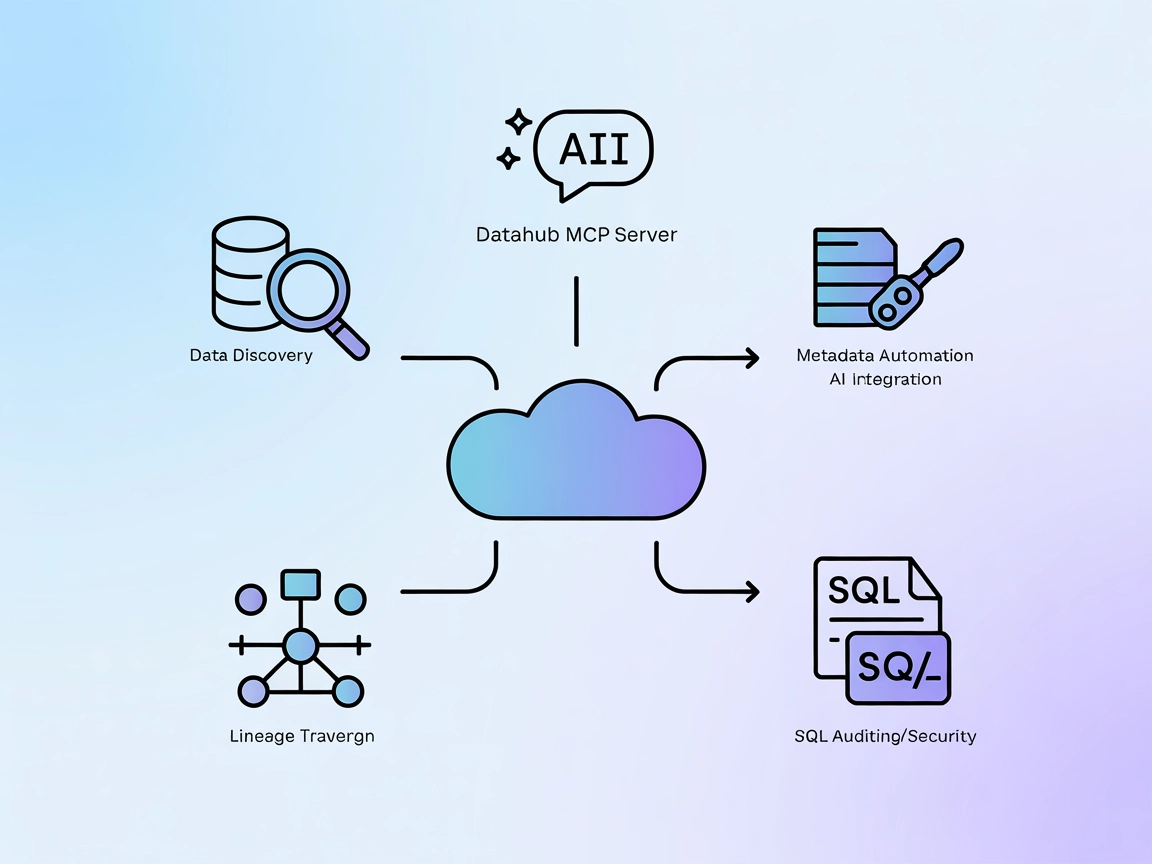
Integración del Servidor MCP de DataHub
El Servidor MCP de DataHub conecta los agentes de IA de FlowHunt con la plataforma de metadatos DataHub, permitiendo descubrimiento avanzado de datos, análisis ...
5 min de lectura
AI
Metadata
+6
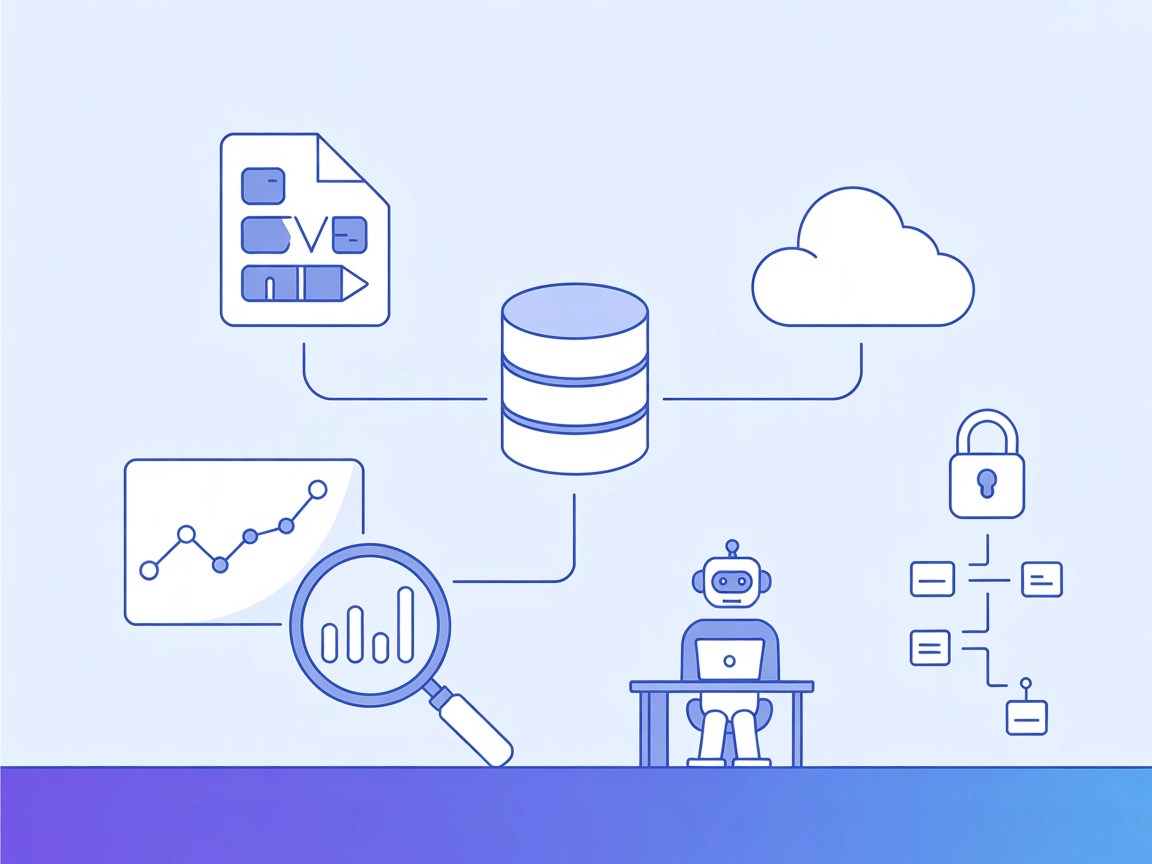
Conecta tu agente de IA a conjuntos de datos externos para un potente análisis de datos, informes y visualización con el Servidor MCP de Exploración de Datos.
FlowHunt proporciona una capa de seguridad adicional entre tus sistemas internos y las herramientas de IA, dándote control granular sobre qué herramientas son accesibles desde tus servidores MCP. Los servidores MCP alojados en nuestra infraestructura pueden integrarse perfectamente con el chatbot de FlowHunt, así como con plataformas de IA populares como ChatGPT, Claude y varios editores de IA.
El Servidor MCP de Exploración de Datos es una herramienta versátil diseñada para conectar asistentes de IA con conjuntos de datos externos para análisis interactivo de datos. Actuando como un asistente personal de Ciencia de Datos, empodera a los usuarios—especialmente a desarrolladores y analistas—para explorar conjuntos de datos complejos y extraer información accionable con facilidad. Al permitir que los agentes de IA accedan a archivos CSV locales y definan temas de exploración, el servidor simplifica tareas como resumir tendencias, generar informes analíticos y visualizar datos. Su integración con las principales plataformas de IA lo convierte en un componente valioso para consultas a bases de datos, conversaciones basadas en datos y automatización de flujos de trabajo, todo mientras permite interacciones seguras y fluidas con los datos proporcionados por el usuario.
csv_path (ruta local del archivo) y el topic (tema de la exploración).Comienza tu prueba gratuita hoy y ve resultados en días.
Obtén los últimos consejos, tendencias y ofertas gratis.
{
"mcpServers": {
"data-exploration": {
"command": "python",
"args": ["setup.py"]
}
}
}
python setup.py
csv_path, topic).{
"mcpServers": {
"data-exploration": {
"command": "python",
"args": ["setup.py"]
}
}
}
{
"mcpServers": {
"data-exploration": {
"command": "python",
"args": ["setup.py"]
}
}
}
Si el servidor requiere claves API, establécelas mediante variables de entorno para mayor seguridad:
{
"mcpServers": {
"data-exploration": {
"command": "python",
"args": ["setup.py"],
"env": {
"API_KEY": "${API_KEY}"
},
"inputs": {
"api_key": "${API_KEY}"
}
}
}
}
Reemplaza "API_KEY" por el nombre real de tu variable de entorno.
Uso del MCP en FlowHunt
Para integrar servidores MCP en tu flujo de trabajo de FlowHunt, comienza agregando el componente MCP a tu flujo y conectándolo con tu agente de IA:

Haz clic en el componente MCP para abrir el panel de configuración. En la sección de configuración del sistema MCP, inserta los detalles de tu servidor MCP usando este formato JSON:
{
"data-exploration": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Una vez configurado, el agente de IA podrá usar este MCP como una herramienta con acceso a todas sus funciones y capacidades. Recuerda cambiar “data-exploration” por el nombre real de tu servidor MCP y la URL por la de tu propio servidor MCP.
| Sección | Disponibilidad | Detalles/Notas |
|---|---|---|
| Resumen | ✅ | Basado en README.md y descripción del repositorio |
| Lista de Prompts | ✅ | Plantilla de prompt “explore-data” documentada |
| Lista de Recursos | ✅ | Archivo CSV, conjuntos de datos de Kaggle, informes, visualizaciones |
| Lista de Herramientas | ⛔ | No se encontró una lista explícita de herramientas |
| Protección de claves API | ✅ | Ejemplo proporcionado, aunque no mencionado en el repositorio |
| Soporte de muestreo (menos relevante) | ⛔ | No se encontró evidencia |
Según la documentación y el contenido del repositorio disponibles, este servidor MCP es muy adecuado para tareas de exploración y análisis de datos. Sin embargo, la ausencia de una lista clara de herramientas y de soporte explícito de muestreo o raíces limita ligeramente su flexibilidad para flujos de trabajo agentivos avanzados. Aun así, para su propósito principal, ofrece gran utilidad y pasos de integración claros.
| Tiene una LICENCIA | ✅ (MIT) |
|---|---|
| Tiene al menos una herramienta | ⛔ |
| Número de Forks | 40 |
| Número de Stars | 389 |
El Servidor MCP de Exploración de Datos permite que los asistentes de IA accedan y analicen conjuntos de datos externos, como archivos CSV y conjuntos de datos de Kaggle, para ofrecer análisis de datos interactivos, informes y visualizaciones.
Puedes usar archivos CSV locales, integrarte con conjuntos de datos públicos de Kaggle y generar informes analíticos y visualizaciones basados en tus datos.
Agrega el componente MCP en tu flujo de trabajo de FlowHunt, abre el panel de configuración e inserta los detalles del servidor MCP usando el formato JSON proporcionado. Reemplaza la URL y el nombre del servidor según corresponda a tu configuración.
Sí, puede generar al instante resúmenes e informes ejecutivos a partir de archivos CSV en bruto, ahorrando un tiempo significativo de análisis manual.
El servidor está diseñado para manejar grandes conjuntos de datos de manera eficiente, pero el rendimiento dependerá de tu hardware y de la complejidad de las tareas de análisis.
Impulsa tus flujos de trabajo con análisis de datos interactivo y visualización. Conecta tu agente de IA al Servidor MCP de Exploración de Datos para obtener información en tiempo real de tus conjuntos de datos.
El Servidor MCP de DataHub conecta los agentes de IA de FlowHunt con la plataforma de metadatos DataHub, permitiendo descubrimiento avanzado de datos, análisis ...
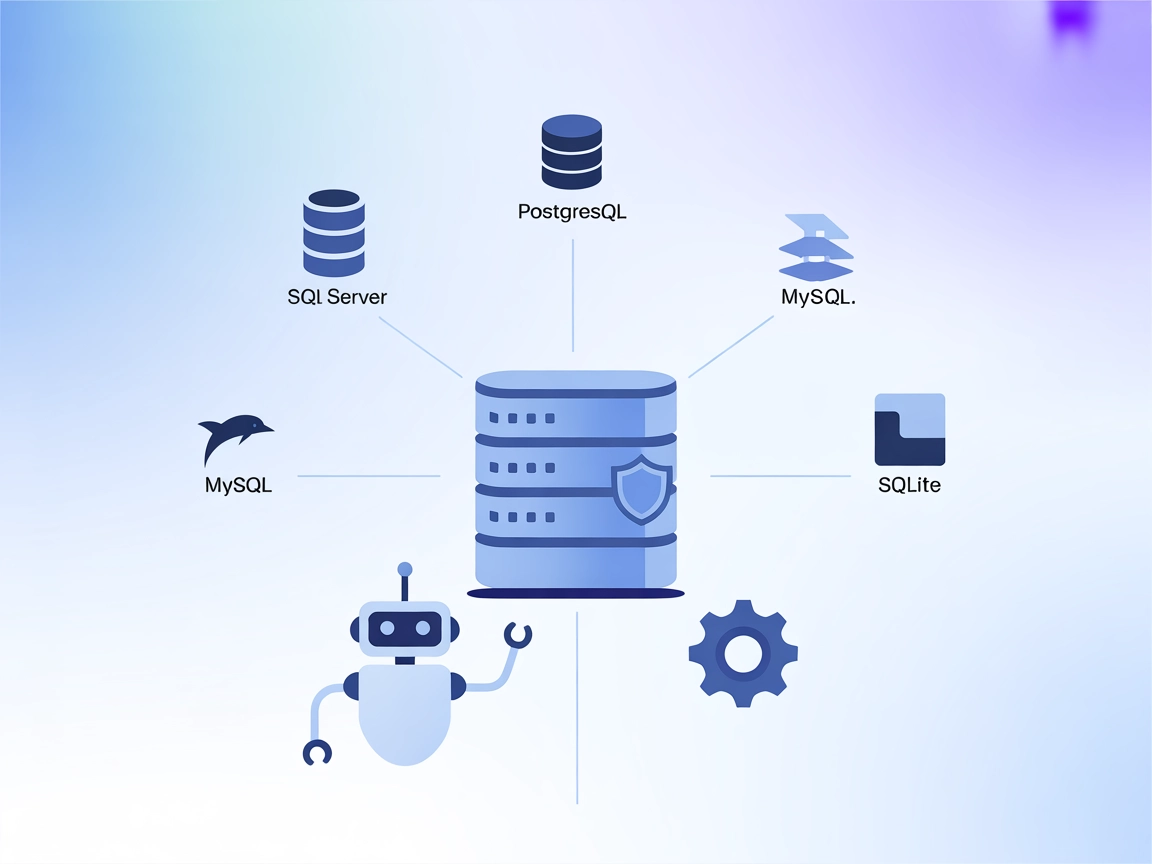
El Servidor de Base de Datos MCP permite el acceso seguro y programático a bases de datos populares como SQLite, SQL Server, PostgreSQL y MySQL para asistentes ...
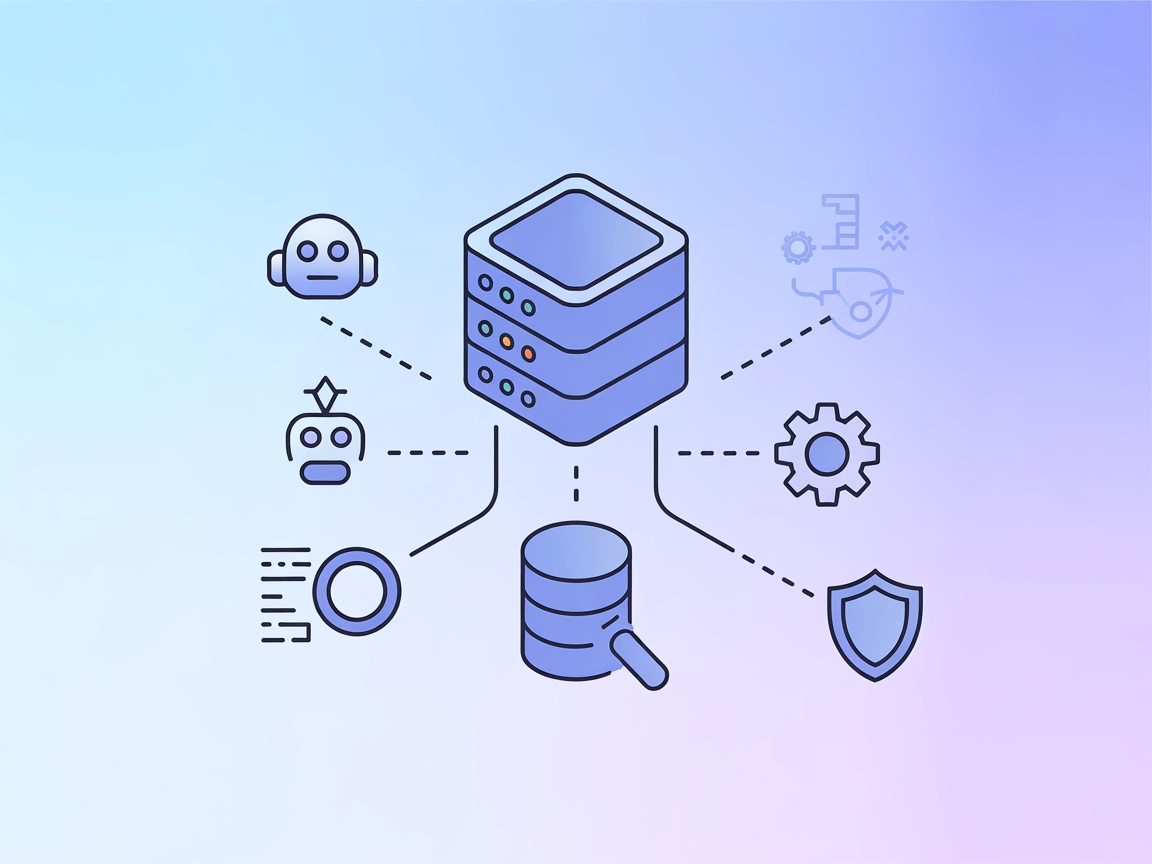
El Servidor MCP de OpenSearch permite la integración fluida de OpenSearch con FlowHunt y otros agentes de IA, permitiendo el acceso programático a funciones de ...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.