Analyse des performances de Gemini 2.0 Thinking : une évaluation complète
Une évaluation complète de Gemini 2.0 Thinking, le modèle expérimental d’IA de Google, axée sur ses performances, la transparence de son raisonnement et ses applications pratiques sur les types de tâches fondamentaux.
AI
Gemini 2.0
Model Evaluation
AI Transparency
AI Reasoning
Content Generation
Summarization
Calculation
Comparison
Analytical Writing
Comparaison – Analyse et contraste de sujets complexes
Rédaction créative/analytique – Production d’analyses détaillées de scénarios
Pour chaque tâche, nous avons mesuré :
Temps de traitement
Qualité de la sortie
Approche de raisonnement
Modes d’utilisation des outils
Indicateurs de lisibilité
Tâche 1 : Performances en génération de contenu
Description de la tâche : Générer un article complet sur les fondamentaux de la gestion de projet, en mettant l’accent sur la définition des objectifs, du périmètre et de la délégation.
Analyse des performances :
Le processus de raisonnement visible de Gemini 2.0 Thinking est remarquable. Le modèle a démontré une approche systématique de recherche et de synthèse en plusieurs étapes sur deux variantes de la tâche :
Commencer par Wikipedia pour le contexte fondamental
Utiliser Google Search pour des détails spécifiques et des meilleures pratiques
Affiner les recherches en fonction des premières découvertes
Explorer des URL spécifiques pour approfondir l’information
Forces en traitement de l’information :
Dans la deuxième variante, identification avancée des sources et exploration de plusieurs URL pour obtenir des informations détaillées
Production de résultats très structurés avec une organisation hiérarchique claire (niveau de lecture équivalent à la 3e française)
Intégration de cadres spécifiques sur demande (SMART, OKRs, WBS, matrice RACI)
Équilibre efficace entre concepts théoriques et applications pratiques
Indicateurs d’efficacité :
Temps de traitement : 30 secondes (Variante 1) vs. 56 secondes (Variante 2)
La durée plus longue de la variante 2 correspond à des recherches plus poussées et à un résultat plus détaillé (710 vs. ~500 mots)
Note de performance :9/10
La génération de contenu obtient une note élevée grâce à la capacité du modèle à :
Effectuer des recherches multisource de façon autonome
Structurer l’information logiquement avec titres et sous-titres adaptés
Équilibrer théorie et cadres pratiques
Adapter la profondeur de recherche à la spécificité du prompt
Générer rapidement du contenu de qualité professionnelle (moins d’une minute)
La principale force de la version Thinking est la visibilité sur l’approche de recherche, montrant les outils utilisés à chaque étape, même si les énoncés de raisonnement explicites étaient affichés de façon inégale.
Prêt à développer votre entreprise?
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
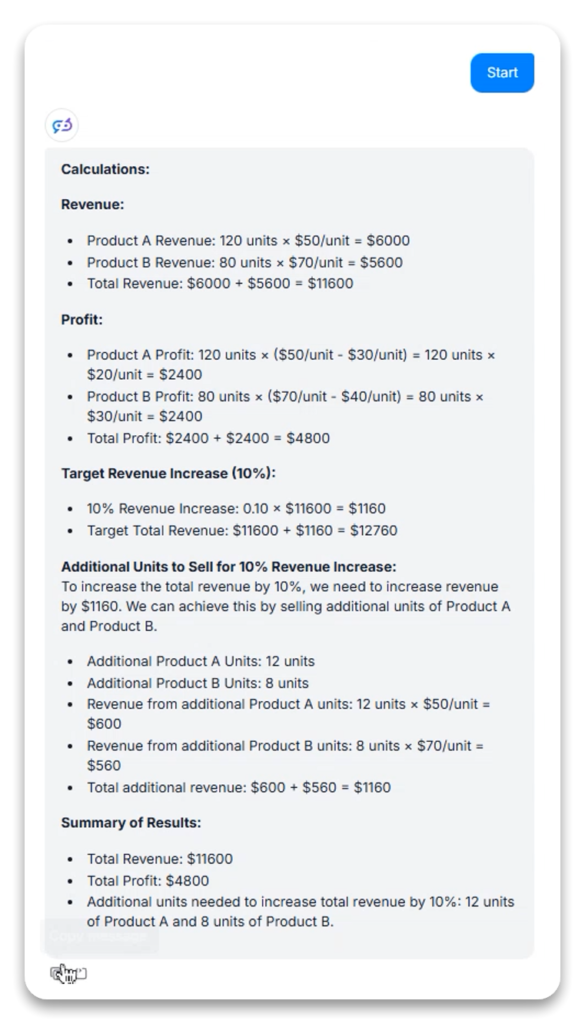
Description de la tâche : Résoudre un problème de calcul commercial comportant plusieurs volets liés au chiffre d’affaires, au bénéfice et à l’optimisation.
Analyse des performances :
Sur les deux variantes, le modèle a démontré de solides capacités de raisonnement mathématique :
Décomposition : Fractionnement des problèmes complexes en sous-calculs logiques (chiffre d’affaires par produit → chiffre d’affaires total → coût par produit → coût total → bénéfice par produit → bénéfice total)
Optimisation : Dans la première variante, lorsqu’il s’agissait de déterminer le nombre d’unités supplémentaires nécessaires pour une hausse de 10 % du chiffre d’affaires, le modèle a explicitement indiqué sa stratégie d’optimisation (priorité aux produits à prix élevé pour minimiser le total des unités)
Vérification : Dans la deuxième variante, le modèle a vérifié le résultat en calculant si la solution proposée (12 unités de A, 8 unités de B) atteignait bien le chiffre d’affaires supplémentaire requis
Forces en traitement mathématique :
Précision des calculs, aucune erreur mathématique
Explication transparente, étape par étape, facilitant la vérification
Utilisation efficace du formatage (puces, titres clairs) pour organiser les étapes
Approches de solution différentes entre variantes, preuve de flexibilité
Indicateurs d’efficacité :
Temps de traitement : 19 secondes (Variante 1) vs. 23 secondes (Variante 2)
Performance constante malgré des approches différentes
Note de performance :9,5/10
Le calcul obtient une excellente note grâce à :
Précision parfaite des calculs
Documentation claire et séquentielle du processus
Multiplicité des approches, preuve de flexibilité
Temps de traitement efficace
Présentation et vérification efficaces des résultats
La capacité « Thinking » a pris tout son sens dans la première variante où le modèle a détaillé ses hypothèses et sa stratégie d’optimisation, offrant une transparence sur sa prise de décision souvent absente des modèles standards.
Tâche 3 : Performances en synthèse
Description de la tâche : Résumer les principaux enseignements d’un article sur le raisonnement de l’IA en 100 mots.
Analyse des performances :
Le modèle a fait preuve d’une efficacité remarquable en synthèse, sur les deux variantes :
Vitesse de traitement : Synthèse réalisée en environ 3 secondes dans les deux cas
Respect de la contrainte de longueur : Résumés générés bien en dessous de la limite de 100 mots (70-71 mots)
Sélection du contenu : Identification et inclusion des aspects les plus significatifs du texte source
Densité d’information : Maintien d’une forte densité tout en restant cohérent
Points forts en synthèse :
Rapidité exceptionnelle (3 secondes)
Respect parfait des contraintes de longueur
Conservation des concepts techniques clés
Maintien d’un fil logique malgré une compression importante
Couverture équilibrée des différentes sections du document source
Indicateurs d’efficacité :
Temps de traitement : ~3 secondes dans les deux variantes
Longueur des résumés : 70-71 mots (dans la limite)
Taux de compression : réduction d’environ 85-90 % par rapport à la source
Note de performance :10/10
La synthèse obtient la note maximale grâce à :
Temps de traitement extraordinairement rapide
Respect parfait des contraintes
Excellente priorisation de l’information
Cohérence forte malgré une forte compression
Performance constante sur les deux variantes
Fait intéressant, pour cette tâche, la fonctionnalité « Thinking » n’a pas affiché de raisonnement explicite, suggérant que le modèle emploie peut-être une démarche plus intuitive pour la synthèse qu’une démarche pas-à-pas.
Rejoignez notre newsletter
Recevez gratuitement les derniers conseils, tendances et offres.
Tâche 4 : Performances en comparaison
Description de la tâche : Comparer l’impact environnemental des véhicules électriques et des voitures à hydrogène sur plusieurs critères.
Analyse des performances :
Le modèle a adopté des approches différentes entre les deux variantes, avec des variations notables sur le temps de traitement et l’exploitation des sources :
Variante 1 : S’appuie principalement sur Google Search, terminé en 20 secondes
Variante 2 : Utilise Google Search suivi d’un crawling d’URL pour des infos approfondies, terminé en 46 secondes
Points forts de l’analyse comparative :
Cadres de comparaison bien structurés avec organisation catégorielle claire
Perspective équilibrée sur les avantages et limites des deux technologies
Intégration de données chiffrées (pourcentages d’efficacité, temps de ravitaillement)
Niveau technique adapté (niveau de lecture 1ère/terminale)
Dans la variante 2, attribution correcte de la source (article Earth.org)
Différences de traitement de l’information :
Résultat variante 1 : 461 mots ; variante 2 : 362 mots
La variante 2 a montré une utilisation plus forte de sources précises
Lisibilité similaire pour les deux (niveau 1ère/terminale)
Note de performance :8,5/10
La tâche de comparaison obtient une note solide grâce à :
Cadres comparatifs bien structurés
Analyse équilibrée des avantages/inconvénients
Précision technique et profondeur adaptée
Organisation claire par critères pertinents
Adaptation de la stratégie de recherche selon le besoin
La fonctionnalité « Thinking » était visible dans les logs d’utilisation des outils, montrant l’approche séquentielle du modèle : recherche large, puis ciblage d’URL pour approfondir. Cette transparence permet de comprendre les sources mobilisées pour la comparaison.
Tâche 5 : Performances en rédaction créative/analytique
Description de la tâche : Analyser les changements environnementaux et les impacts sociétaux dans un monde où les véhicules électriques auraient totalement remplacé les moteurs à combustion.
Analyse des performances :
Sur les deux variantes, le modèle a démontré de fortes capacités d’analyse sans affichage visible de l’utilisation d’outils :
Couverture complète : Tous les aspects demandés sont traités (urbanisme, qualité de l’air, infrastructures énergétiques, impact économique)
Organisation structurée : Contenu bien organisé avec un fil logique et des titres de section clairs
Analyse nuancée : Considération des bénéfices et des défis pour une perspective équilibrée
Intégration interdisciplinaire : Connexion réussie des facteurs environnementaux, sociaux, économiques et technologiques
Forces en génération de contenu :
Adaptation du ton (formulation plus conversationnelle dans la variante 2)
Longueur et richesse du contenu exceptionnelles (1829 mots dans la variante 2)
Excellente lisibilité (niveau 1ère/terminale)
Intégration de considérations nuancées (enjeux d’équité, défis de mise en œuvre)
Indicateurs d’efficacité :
Temps de traitement : 43 secondes (Variante 1) vs. 39 secondes (Variante 2)
Nombre de mots : ~543 (Variante 1) vs. 1829 (Variante 2)
Note de performance :9/10
La rédaction créative/analytique obtient une excellente note grâce à :
Couverture complète de tous les aspects demandés
Longueur et niveau de détail impressionnants
Équilibre entre vision optimiste et défis pragmatiques
Fortes connexions interdisciplinaires
Rapidité malgré la complexité de l’analyse
Pour cette tâche, l’aspect « Thinking » était moins visible dans les logs, suggérant que le modèle s’appuie davantage sur sa propre synthèse de connaissances internes que sur des outils externes.
Évaluation globale des performances
D’après notre évaluation complète, Gemini 2.0 Thinking démontre des capacités impressionnantes sur des tâches variées, avec comme caractéristique distinctive la visibilité sur sa démarche de résolution de problèmes :
Type de tâche
Note
Points forts clés
Axes d’amélioration
Génération de contenu
9/10
Recherche multisource, organisation structurée
Cohérence de l’affichage du raisonnement
Calcul
9,5/10
Précision, vérification, clarté des étapes
Affichage complet du raisonnement partout
Synthèse
10/10
Rapidité, respect des contraintes, priorisation
Transparence sur le processus de sélection
Comparaison
8,5/10
Cadres structurés, analyse équilibrée
Cohérence d’approche, temps de traitement
Créatif/Analytique
9/10
Ampleur de la couverture, niveau de détail, interdisciplinaire
Transparence sur l’utilisation des outils
Global
9,2/10
Efficacité, qualité des résultats, visibilité du processus
Cohérence du raisonnement, clarté du choix d’outil
L’avantage « Thinking »
Ce qui distingue Gemini 2.0 Thinking des modèles IA classiques est son approche expérimentale consistant à exposer ses processus internes. Principaux avantages :
Transparence sur l’utilisation des outils – L’utilisateur voit quand et pourquoi le modèle mobilise Wikipedia, Google Search ou le crawling d’URL
Aperçus du raisonnement – Sur certaines tâches, notamment les calculs, le modèle détaille explicitement sa démarche et ses hypothèses
Résolution séquentielle – Les logs révèlent une approche séquentielle des tâches complexes, construisant la compréhension progressivement
Stratégie de recherche visible – Le processus montre comment le modèle affine ses recherches à partir des premiers résultats
Bénéfices de cette transparence :
Confiance accrue grâce à la visibilité du processus
Valeur pédagogique, permettant d’observer une résolution experte
Potentiel de débogage si les résultats ne sont pas à la hauteur
Apport en recherche sur les schémas de raisonnement IA
Applications pratiques
Gemini 2.0 Thinking se montre particulièrement prometteur pour les applications nécessitant :
Recherche et synthèse – Recherche et organisation efficaces d’informations multisources
Démonstrations pédagogiques – Démarche de raisonnement visible, précieuse pour enseigner la résolution de problèmes
Analyse complexe – Forte capacité d’analyse interdisciplinaire avec méthodologie transparente
Travail collaboratif – La transparence du raisonnement permet aux humains de mieux comprendre et enrichir le travail du modèle
La rapidité, la qualité et la visibilité du processus rendent ce modèle particulièrement adapté aux contextes professionnels où comprendre le « pourquoi » des conclusions IA compte autant que les résultats.
Conclusion
Gemini 2.0 Thinking représente une orientation expérimentale intéressante dans le développement de l’IA, misant non seulement sur la qualité des résultats mais surtout sur la transparence du processus. Ses performances sur notre batterie de tests montrent de solides capacités en recherche, calcul, synthèse, comparaison et rédaction créative/analytique, avec des résultats particulièrement exceptionnels en synthèse (10/10).
L’approche « Thinking » fournit des aperçus précieux sur la façon dont le modèle s’attaque à différents problèmes, même si la transparence varie sensiblement selon le type de tâche. Cette hétérogénéité reste le principal axe d’amélioration : une uniformité accrue dans la présentation du raisonnement renforcerait la valeur pédagogique et collaborative du modèle.
Au global, avec un score composite de 9,2/10, Gemini 2.0 Thinking apparaît comme un système IA très performant, avec l’avantage supplémentaire de la visibilité sur le processus, ce qui le rend particulièrement pertinent pour les usages où la compréhension du cheminement intellectuel compte autant que la réponse finale.
Questions fréquemment posées
Qu'est-ce que Gemini 2.0 Thinking ?
Gemini 2.0 Thinking est un modèle d’IA expérimental développé par Google qui expose ses processus de raisonnement, offrant ainsi une transparence sur la façon dont il résout des problèmes sur diverses tâches telles que la génération de contenu, le calcul, la synthèse et la rédaction analytique.
Qu'est-ce qui différencie Gemini 2.0 Thinking des autres modèles d'IA ?
Sa transparence unique du «xa0raisonnementxa0» permet aux utilisateurs de visualiser l’utilisation des outils, les étapes du raisonnement et les stratégies de résolution de problèmes, augmentant ainsi la confiance et la valeur pédagogique, en particulier dans les contextes de recherche et de collaboration.
Comment Gemini 2.0 Thinking a-t-il été évalué dans cette analyse ?
Le modèle a été testé sur cinq types de tâches clés : génération de contenu, calcul, synthèse, comparaison et rédaction créative/analytique, avec des métriques telles que le temps de traitement, la qualité de la sortie et la visibilité du raisonnement.
Quels sont les principaux points forts de Gemini 2.0 Thinking ?
Parmi ses atouts : la recherche multisource, une grande précision de calcul, une synthèse rapide, des comparaisons bien structurées, une analyse approfondie et une visibilité exceptionnelle sur le processus.
Quels aspects doivent être améliorés dans Gemini 2.0 Thinking ?
Le modèle gagnerait à afficher une transparence plus constante dans la présentation de son raisonnement pour tous les types de tâches et à fournir des journaux d'utilisation des outils plus clairs dans chaque scénario.
Arshia est ingénieure en workflows d'IA chez FlowHunt. Avec une formation en informatique et une passion pour l’IA, elle se spécialise dans la création de workflows efficaces intégrant des outils d'IA aux tâches quotidiennes, afin d’accroître la productivité et la créativité.
Arshia Kahani
Ingénieure en workflows d'IA
Prêt à découvrir un raisonnement IA transparent ?
Découvrez comment la visibilité des processus et le raisonnement avancé de Gemini 2.0 Thinking peuvent faire progresser vos solutions d’IA. Réservez une démo ou essayez FlowHunt dès aujourd’hui.
Gemini 2.0 Flash-Litexa0: la rapidité rencontre la performance dans la dernière IA de Google
Découvrez comment Gemini 2.0 Flash-Lite de Google se comporte dans la création de contenu, les calculs, la synthèse et les tâches créatives. Notre analyse appro...
Aperçu de Gemini 2.5 Proxa0: Analyse des performances sur des tâches clés
Une revue complète de l’aperçu de Gemini 2.5 Pro de Google, évaluant ses performances réelles sur cinq tâches clés, dont la génération de contenu, les calculs d...
Llama 4 Scout AIxa0: Analyse des performances sur plusieurs tâches
Une analyse approfondie des performances du modèle Llama 4 Scout AI de Meta sur cinq tâches variées, révélant des capacités impressionnantes en génération de co...
5 min de lecture
AI
Llama 4
+8
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.