Découvrez ce qu’est Google Gemini, son fonctionnement, et sa comparaison avec ChatGPT. Apprenez-en plus sur ses capacités multimodales, ses tarifs et ses applications concrètes pour 2025.
Qu'est-ce que le chatbot IA Google Gemini ?
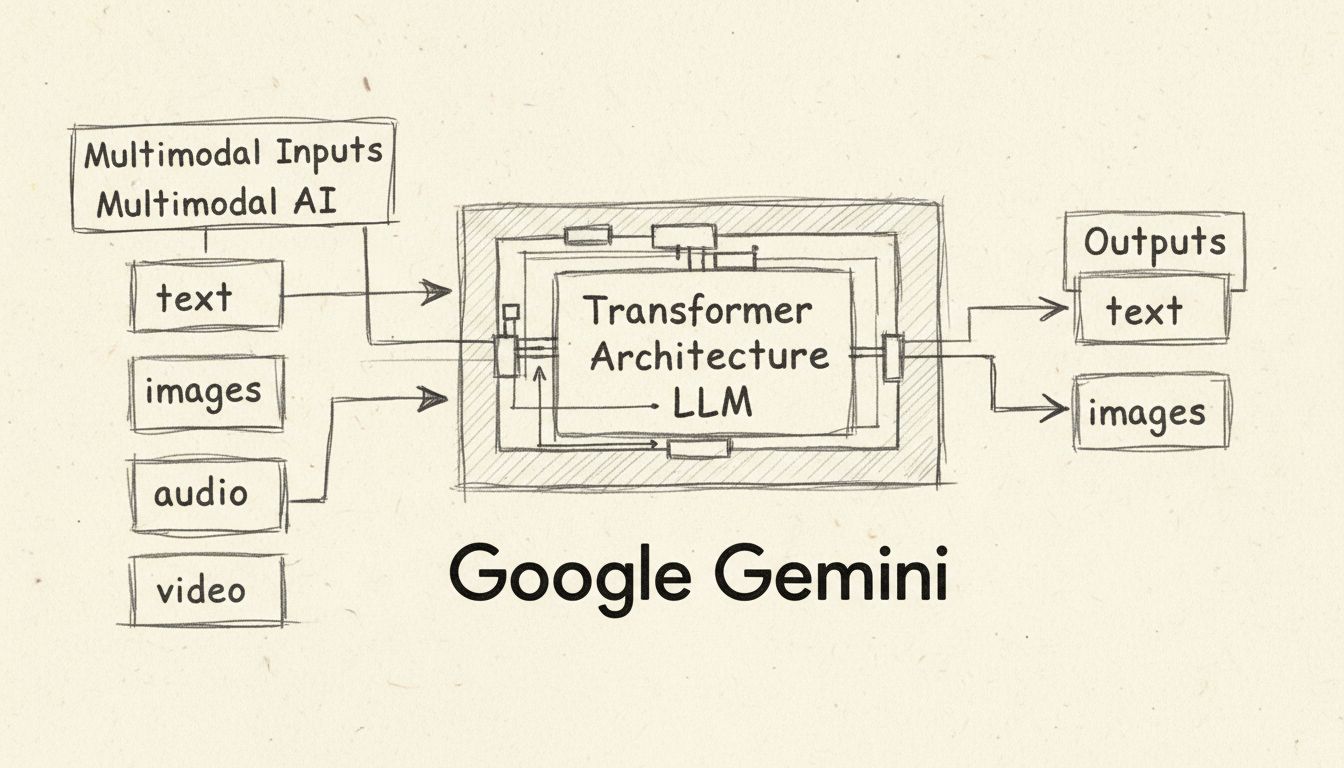
Google Gemini est un chatbot IA multimodal et un grand modèle de langage développé par Google DeepMind, capable de traiter et de générer du texte, des images, de l'audio et de la vidéo. Lancé en décembre 2023 et renommé depuis Bard en février 2024, Gemini alimente l'assistant IA de Google sur les téléphones Pixel, la recherche Google et les applications Workspace.
Comprendre Google Gemini : la nouvelle génération de chatbots IA
Google Gemini représente une avancée majeure en matière d’intelligence artificielle, changeant fondamentalement la manière dont les utilisateurs interagissent avec les outils propulsés par l’IA. Lancé initialement sous le nom de Bard en mars 2023, Google a rebaptisé son assistant IA en Gemini en février 2024, reflétant le grand modèle de langage (LLM) sous-jacent qui alimente la plateforme. Gemini n’est pas un simple chatbot : c’est une famille sophistiquée de modèles IA multimodaux développés par Google DeepMind, capables de comprendre et de générer du contenu sur plusieurs types de données simultanément. Cette capacité révolutionnaire distingue Gemini des outils IA de génération précédente, principalement axés sur les interactions textuelles. La plateforme a été intégrée dans tout l’écosystème Google, des smartphones Pixel à la recherche Google, en passant par les applications Workspace, ce qui en fait l’un des assistants IA les plus accessibles pour les particuliers comme pour les entreprises à travers le monde.
Qu’est-ce qui distingue Gemini : des capacités IA multimodales
La caractéristique déterminante de Gemini est son architecture multimodale, ce qui signifie qu’il peut traiter et générer simultanément plusieurs types de données. Contrairement à ChatGPT, qui gère principalement des entrées et sorties textuelles, Gemini prend en charge nativement le texte, les images, l’audio et la vidéo, tant en entrée qu’en sortie. Cette capacité multimodale permet à Gemini de comprendre des informations visuelles complexes telles que des graphiques, des schémas et des photographies sans avoir besoin d’outils externes de reconnaissance optique de caractères (OCR). Le modèle peut analyser des notes manuscrites, des graphiques et des dessins techniques pour résoudre des problèmes complexes qui nécessiteraient plusieurs outils spécialisés dans les workflows traditionnels. De plus, Gemini prend en charge le traitement audio dans plus de 100 langues, offrant des capacités de reconnaissance vocale et de traduction en temps réel. La compréhension vidéo permet à Gemini d’analyser des séquences et de répondre à des questions sur le contenu vidéo, ce qui le rend précieux pour l’analyse et le résumé de contenus.
L’architecture du réseau de neurones basée sur le transformeur qui propulse Gemini a été spécifiquement améliorée pour gérer de longues séquences contextuelles sur différents types de données. Google DeepMind a mis en œuvre des mécanismes d’attention efficaces dans le décodeur transformeur, permettant au modèle de traiter de longs contextes, certaines versions supportant jusqu’à 2 millions de tokens—bien plus que la limite de 128 000 tokens de ChatGPT. Cette fenêtre de contexte élargie permet à Gemini d’analyser des livres entiers, de longs rapports ou des milliers de lignes de code en une seule interaction, offrant ainsi des réponses plus complètes et contextualisées.
Les variantes du modèle Gemini : choisir la version adaptée à vos besoins
Google propose plusieurs versions de Gemini, chacune optimisée pour des cas d’usage et des environnements de déploiement spécifiques. Comprendre ces variantes est essentiel pour sélectionner le modèle le plus approprié à vos besoins. Le Gemini 1.0 Nano est la plus petite version, conçue pour les applications mobiles embarquées, capable de fonctionner sur des appareils Android comme le Pixel 8 Pro sans connexion internet. Nano peut décrire des images, suggérer des réponses de chat, résumer des textes et transcrire la parole directement sur votre appareil. Le Gemini 1.0 Ultra est la version la plus puissante de la première génération, conçue pour des tâches très complexes, dont la programmation avancée, le raisonnement mathématique et la compréhension multimodale sophistiquée. Les versions Nano et Ultra offrent une fenêtre de contexte de 32 000 tokens.
Le Gemini 1.5 Pro plus récent est un modèle multimodal de taille moyenne qui offre un excellent compromis entre capacité et efficacité, avec une impressionnante fenêtre de contexte de 2 millions de tokens. Cette version utilise une architecture Mixture of Experts (MoE), où le modèle est divisé en réseaux spécialisés plus petits qui s’activent selon le type d’entrée, ce qui améliore la rapidité et réduit les coûts de calcul. Gemini 1.5 Flash est une version allégée créée par distillation de connaissances, où les acquis de Gemini 1.5 Pro ont permis de concevoir un modèle plus compact et efficace. Flash conserve une fenêtre de contexte de 1 million de tokens, tout en offrant une faible latence, idéale pour les applications nécessitant rapidité et efficacité. Le tout récent Gemini 2.0 Flash, sorti en décembre 2024, est deux fois plus rapide que le 1.5 Pro et intègre de nouvelles capacités, telles que l’entrée/sortie multimodale, la compréhension de longs contextes et le streaming audio natif.
Version du modèle
Fenêtre de contexte
Idéal pour
Fonctionnalités clés
Gemini 1.0 Nano
32 000 tokens
Tâches mobiles embarquées
Léger, sans connexion requise
Gemini 1.0 Ultra
32 000 tokens
Raisonnement complexe & code
Modèle le plus puissant de 1ère génération
Gemini 1.5 Pro
2 millions de tokens
Applications entreprise
Architecture Mixture of Experts
Gemini 1.5 Flash
1 million de tokens
Applications critiques en rapidité
Distillation de connaissances, faible latence
Gemini 2.0 Flash
Contexte étendu
Applications les plus récentes
2x plus rapide, streaming multimodal
Comment fonctionne Gemini : la base technique
Gemini fonctionne grâce à une architecture de modèle transformeur, un design de réseau de neurones que Google a lui-même inventé en 2017. Le système repose sur trois mécanismes principaux : des encodeurs transforment les séquences d’entrée en représentations numériques appelées embeddings qui capturent la signification sémantique et la position des tokens ; un mécanisme d’auto-attention permet au modèle de se concentrer sur les tokens les plus importants, quelle que soit leur position dans la séquence ; et des décodeurs exploitent ce mécanisme d’attention et les embeddings de l’encodeur pour générer la séquence de sortie la plus probable statistiquement. Contrairement aux modèles GPT classiques qui ne traitent que des entrées textuelles, Gemini accepte des séquences entrelacées d’audio, d’images, de texte et de vidéo, et peut produire des sorties texte et images entrelacées.
L’entraînement de Gemini a impliqué des jeux de données massifs, multilingues et multimodaux couvrant texte, images, audio et vidéo. Google DeepMind a utilisé des techniques avancées de filtrage pour optimiser la qualité de l’entraînement et garantir que le modèle apprend à partir de sources d’information variées et de haute qualité. Pendant la phase d’entraînement comme d’inférence, Gemini bénéficie des dernières puces d’accélération de Google, les TPU (Tensor Processing Unit) Trillium (sixième génération de TPU Google Cloud), qui offrent de meilleures performances, une latence réduite et des coûts moindres par rapport aux générations précédentes. Ces processeurs spécialisés sont nettement plus écoénergétiques, ce qui rend Gemini plus durable et économique à grande échelle.
L’intégration de Gemini dans l’écosystème Google
Google a intégré de façon stratégique Gemini dans toute sa suite de produits, rendant l’assistance IA disponible dans les outils du quotidien. Sur les téléphones Google Pixel, Gemini est l’assistant IA par défaut, remplaçant Google Assistant. L’utilisateur peut activer Gemini sur n’importe quelle application, y compris Chrome, pour poser des questions sur le contenu affiché, résumer des pages web ou obtenir des informations complémentaires sur des images. Le Pixel 8 Pro a été le premier appareil conçu pour faire tourner Gemini Nano, permettant des traitements IA embarqués, sans connexion au cloud. Dans la recherche Google, Gemini alimente les AI Overviews, qui fournissent des réponses détaillées et contextuelles en haut des résultats de recherche. Ces synthèses décomposent des sujets complexes en explications accessibles, aidant les utilisateurs à comprendre rapidement des thèmes complexes. Les utilisateurs de 13 ans et plus aux États-Unis peuvent accéder aux AI Overviews, avec une extension progressive aux personnes de 18 ans et plus au Royaume-Uni, en Inde, au Mexique, au Brésil, en Indonésie et au Japon.
Dans Google Workspace, Gemini apparaît dans le panneau latéral de Docs pour aider à la rédaction et à la correction de contenu, dans Gmail pour rédiger des emails et suggérer des réponses, et dans d’autres applications comme Google Maps pour fournir des synthèses de lieux ou de zones. Les développeurs Android peuvent exploiter Gemini Nano via la capacité système AICore, afin de créer des applications intelligentes avec IA embarquée. Le service Vertex AI de Google Cloud donne accès à Gemini Pro pour les développeurs souhaitant bâtir des applications personnalisées, tandis que le Google AI Studio propose un outil web pour prototyper et développer avec Gemini.
Tarification et accessibilité : offres gratuites et premium
Gemini propose des offres tarifaires flexibles pour répondre à tous les besoins et budgets. La version gratuite donne accès à Gemini avec le modèle 1.5 Flash et une fenêtre de contexte de 32 000 tokens, idéale pour les utilisateurs quotidiens et ceux qui souhaitent explorer les capacités de l’IA. Les utilisateurs doivent avoir au moins 13 ans (18 en Europe) et un compte Google personnel pour accéder à la version gratuite. Gemini Advanced coûte 20 $ par mois et donne accès au puissant modèle 1.5 Pro avec sa fenêtre de 2 millions de tokens, ainsi qu’à des fonctionnalités avancées comme Deep Research, la génération d’images avec Nano Banana Pro et la création de vidéos. Cet abonnement inclut également 100 crédits IA par mois pour la génération vidéo dans Flow et Whisk.
Pour les entreprises, Google propose Gemini Business à 20 $ par utilisateur et par mois (engagement annuel) ou 24 $ par mois (paiement mensuel), destiné aux TPE et PME. Gemini Enterprise coûte 30 $ par utilisateur et par mois en engagement annuel, avec des tarifs personnalisés disponibles via l’équipe commerciale Google pour les grands déploiements. Les développeurs peuvent accéder à Gemini via une API gratuite à usage limité, permettant de tester et prototyper avant de souscrire à une offre payante. L’abonnement Google AI Pro à 21,99 $ par mois donne un accès complet à Gemini 3 Pro, Deep Research et à la génération vidéo avec Veo 3.1, tandis que la formule Google AI Ultra à 274,99 $ par mois offre un accès maximal à toutes les fonctionnalités, y compris Deep Think et les capacités d’agent Gemini.
Gemini vs ChatGPT : comparaison complète
En comparant Gemini à ChatGPT, plusieurs différences majeures apparaissent, influant sur leur pertinence selon les usages. Les capacités multimodales constituent une distinction majeure : Gemini a été conçu dès le départ comme un modèle multimodal, prenant en charge texte, images, audio et vidéo, tandis que ChatGPT s’est d’abord concentré sur le texte puis a ajouté la prise en charge de l’image avec GPT-4. La longueur de la fenêtre de contexte est un autre critère important : Gemini 1.5 Pro prend en charge 2 millions de tokens contre 128 000 pour ChatGPT, ce qui permet à Gemini de traiter beaucoup plus d’informations en une seule interaction. La disponibilité développeur diffère sensiblement : ChatGPT est accessible via l’API d’OpenAI et a été licencié à Microsoft pour une intégration dans Bing, tandis que Gemini est principalement disponible via l’écosystème et les services Google.
Sur le plan des performances, Gemini Ultra dépasse ChatGPT dans plusieurs domaines comme GSM8K pour le raisonnement mathématique, HumanEval pour la génération de code et MMLU pour la compréhension du langage naturel, où Gemini Ultra a même surpassé les performances humaines expertes. Toutefois, ChatGPT reste meilleur sur le benchmark HellaSwag pour le raisonnement de bon sens et l’inférence en langage naturel. L’intégration est plus poussée pour Gemini chez les utilisateurs de l’écosystème Google, car il est profondément intégré à la recherche, à Workspace et aux appareils Pixel, alors que ChatGPT nécessite un accès distinct via la plateforme OpenAI ou l’intégration Bing de Microsoft. Les deux plateformes partagent des préoccupations concernant les hallucinations et les biais, bien que des mesures de sécurité aient été mises en place pour limiter ces risques.
Applications concrètes et cas d’usage
Les capacités polyvalentes de Gemini permettent de nombreuses applications pratiques, tous secteurs confondus. En développement logiciel, Gemini comprend, explique et génère du code dans les principaux langages (Python, Java, C++, Go). Le système AlphaCode 2 de Google utilise une version personnalisée de Gemini Pro pour résoudre des problèmes de programmation compétitive en informatique théorique et mathématiques complexes. Pour la création et l’analyse de contenu, Gemini peut résumer de longs documents, générer du contenu créatif et analyser des documents visuels sans outils externes. La capacité d’analyse de malwares permet aux professionnels de la sécurité d’utiliser Gemini 1.5 Pro pour identifier des fichiers ou extraits de code malveillants et générer des rapports détaillés, tandis que Gemini Flash permet une dissection rapide et à grande échelle des malwares.
La traduction linguistique exploite la capacité multilingue de Gemini pour traduire entre plus de 100 langues avec une précision proche de l’humain. Dans l’éducation, Gemini aide les étudiants à décomposer des sujets complexes, à créer des supports d’apprentissage et à fournir un accompagnement personnalisé grâce à la fonction Learning Coach Gem. Les applications de business intelligence bénéficient de la capacité de Gemini à analyser graphiques, schémas et visuels complexes pour extraire des insights à partir de données métier. La fonctionnalité Gems permet aux utilisateurs de créer des experts IA personnalisés sur n’importe quel sujet, avec des options prêtes à l’emploi comme coach d’apprentissage, partenaire de brainstorming ou éditeur de textes. Project Astra, l’initiative d’agent universel IA de Google, s’appuie sur les modèles Gemini pour créer des agents capables de traiter, mémoriser et comprendre des informations multimodales en temps réel, illustrant le potentiel d’assistants IA autonomes.
Limites et enjeux de Gemini
Malgré ses capacités avancées, Gemini présente plusieurs limites importantes à connaître. Les hallucinations IA restent un enjeu : Gemini peut parfois générer des informations incorrectes et les présenter comme exactes. Ce phénomène a notamment été relevé dans les AI Overviews, où le système a parfois proposé des conseils étranges ou inexacts. Les biais dans les données d’entraînement peuvent produire des résultats biaisés si certaines populations sont sous-représentées ou si les données comportent des préjugés. En février 2024, Google a suspendu la génération d’images dans Gemini après que le système ait produit des représentations historiques inexactes ou biaisées, par exemple en montrant des soldats nazis noirs ou asiatiques, ce qui a ensuite été corrigé.
Les limitations de compréhension contextuelle font que Gemini ne saisit pas toujours toutes les nuances des instructions complexes, ce qui peut entraîner des réponses incomplètes ou hors sujet. Il existe aussi des contraintes d’originalité et de créativité, en particulier dans la version gratuite, qui peine avec les prompts complexes à étapes multiples nécessitant un raisonnement subtil. Des enjeux de propriété intellectuelle ont émergé, Google ayant été condamné en France pour avoir entraîné Gemini sur des articles d’actualité sans l’accord des éditeurs. Enfin, la récence des données d’entraînement est une limite : les connaissances de Gemini s’arrêtent à une certaine date et peuvent ne pas inclure les développements les plus récents. Il est donc conseillé de vérifier les informations cruciales auprès de sources fiables, notamment pour les usages sensibles.
L’avenir de Gemini et de l’automatisation IA
Google continue de faire évoluer Gemini avec des mises à jour régulières et de nouvelles fonctionnalités. La sortie de Gemini 2.0 Flash en décembre 2024 a apporté de nettes améliorations, avec un modèle deux fois plus rapide que le 1.5 Pro tout en maintenant la qualité. Gemini Live permet des conversations naturelles et mains libres avec l’assistant IA, offrant 10 voix différentes et la possibilité de mettre en pause ou reprendre la conversation à tout moment. La fonctionnalité Deep Research permet de rechercher sur des centaines de sites, d’analyser les résultats et de rédiger des rapports détaillés, agissant comme un assistant de recherche personnalisé. Canvas offre un espace collaboratif pour les projets d’écriture et de programmation, tandis que les Gems permettent de créer des experts IA spécialisés pour des tâches ou domaines spécifiques.
À l’avenir, Google prévoit d’étendre la disponibilité de Gemini à l’échelle mondiale, avec l’objectif d’atteindre plus d’un milliard d’utilisateurs d’ici fin 2025. L’entreprise développe également des versions spécialisées de Gemini pour certains secteurs, avec des capacités renforcées pour la santé, la finance ou la recherche scientifique. L’intégration avec des technologies émergentes comme la réalité augmentée ou la robotique avancée ouvre de nouvelles perspectives pour les workflows assistés par IA. Pour les entreprises qui souhaitent exploiter l’automatisation IA à grande échelle, des plateformes comme FlowHunt fournissent des solutions professionnelles pour intégrer Gemini et d’autres modèles IA dans des workflows automatisés, permettant de maximiser la valeur de l’IA tout en gardant le contrôle et la sécurité des processus.
Automatisez vos workflows IA avec FlowHunt
FlowHunt est la principale plateforme d'automatisation IA qui vous aide à concevoir, déployer et gérer des workflows intelligents. Contrairement aux autres outils IA, FlowHunt offre des capacités d'automatisation de niveau entreprise pour intégrer Gemini et d'autres modèles IA dans vos processus métiers, sans effort.
Google I/O 2025xa0: le nouveau Google natif à l’IA
Découvrez les principales annonces de la Google I/O 2025, dont Gemini 2.5 Flash, Project Astra, Android XR, les agents IA dans Android Studio, Gemini Nano, Gemm...
Gemini Flash 2.0xa0: IA avec rapidité et précision
Gemini Flash 2.0 établit de nouveaux standards en IA avec des performances, une rapidité et des capacités multimodales améliorées. Découvrez son potentiel dans ...
Gemini 3 Flash : le modèle d'IA révolutionnaire qui surpasse Pro pour une fraction du coût
Découvrez pourquoi Gemini 3 Flash de Google révolutionne l'IA avec des performances supérieures, des coûts réduits et des vitesses accrues—surpassant même Gemin...
16 min de lecture
AI Models
Google Gemini
+3
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.