Générateur de plan de contenu SEO
Générez un plan de contenu optimisé pour le SEO en analysant les premiers résultats de recherche Google pour un mot-clé donné. Ce flux de travail utilise l'IA e...
4 min de lecture
Apprenez à configurer des plannings automatiques pour crawler des sites web, sitemaps, domaines, et chaînes YouTube afin de maintenir à jour la base de connaissances de votre Agent IA.
La fonctionnalité de planification de FlowHunt vous permet d’automatiser le crawling et l’indexation de sites web, sitemaps, domaines et chaînes YouTube. Cela garantit que la base de connaissances de votre Agent IA reste à jour avec du contenu frais, sans intervention manuelle.
Crawling automatisé :
Programmez des crawls récurrents quotidiens, hebdomadaires, mensuels ou annuels pour garder votre base de connaissances à jour.
Plusieurs types de crawl :
Choisissez entre le crawl de domaine, de sitemap, d’URL ou de chaîne YouTube selon votre source de contenu.
Options avancées :
Configurez le rendu du navigateur, le suivi des liens, la capture d’écrans, la rotation de proxy et le filtrage d’URL pour des résultats optimaux.
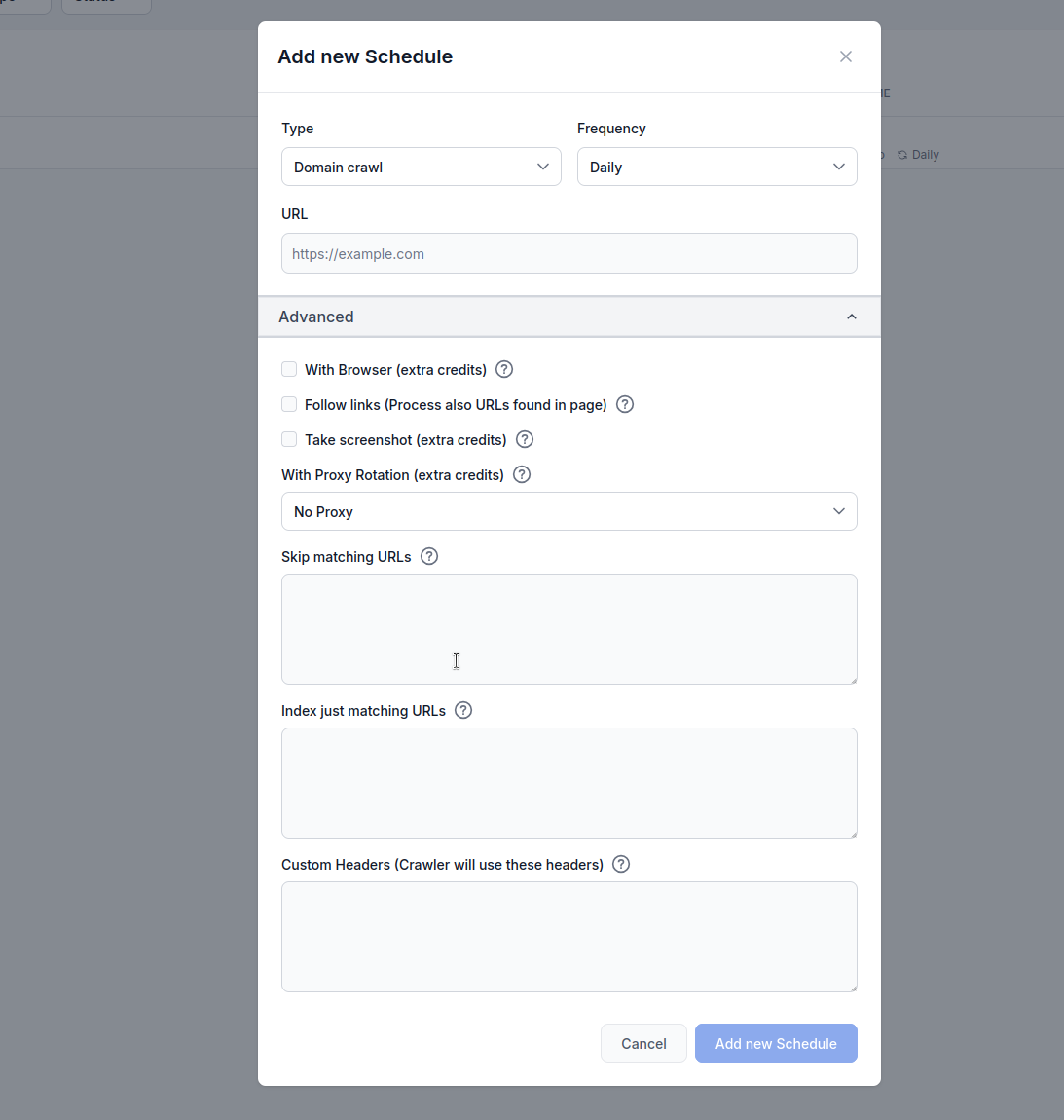
Type : Choisissez votre méthode de crawl :
Fréquence : Définissez la fréquence d’exécution du crawl :
URL : Saisissez l’URL cible, le domaine ou la chaîne YouTube à crawler
Avec navigateur (crédits supplémentaires) : À activer lors du crawl de sites riches en JavaScript nécessitant un rendu complet via navigateur. Cette option est plus lente et coûteuse, mais indispensable pour les sites qui chargent le contenu dynamiquement.
Suivre les liens (crédits supplémentaires) : Crawl également les URLs additionnelles trouvées dans les pages. Utile si le sitemap n’inclut pas toutes les URLs, mais peut consommer beaucoup de crédits car il parcourt tous les liens découverts.
Prendre une capture d’écran (crédits supplémentaires) : Capture des captures d’écran lors du crawl. Pratique pour les sites sans og:images ou nécessitant un contexte visuel pour le traitement IA.
Avec rotation de proxy (crédits supplémentaires) : Fait tourner les adresses IP pour chaque requête afin d’éviter la détection par les firewalls applicatifs (WAF) ou systèmes anti-bot.
Ignorer les URLs correspondantes : Saisissez des chaînes (une par ligne) pour exclure du crawl les URLs contenant ces motifs. Exemple :
/admin/
/login
.pdf
Cet exemple explique ce qu’il se passe lorsque vous utilisez la fonction de planification de FlowHunt pour crawler le domaine flowhunt.io tout en indiquant /blog comme motif d’URL à ignorer dans les paramètres de filtrage.
Paramètres de configuration
flowhunt.io/blogDéroulement
Début du crawl :
flowhunt.io, ciblant toutes les pages accessibles du domaine (ex : flowhunt.io, flowhunt.io/features, flowhunt.io/pricing, etc.).Application du filtrage d’URL :
/blog./blog (ex : flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/category) est exclue du crawl.flowhunt.io/about, flowhunt.io/contact ou flowhunt.io/docs sont crawlées car elles ne correspondent pas au motif /blog.Exécution du crawl :
flowhunt.io, indexant leur contenu dans la base de connaissances de votre Agent IA.Résultat :
flowhunt.io, en excluant tout ce qui se trouve sous le chemin /blog./blog) sans intervention manuelle.Indexer uniquement les URLs correspondantes : Saisissez des chaînes (une par ligne) pour ne crawler que les URLs contenant ces motifs. Exemple :
/blog/
/articles/
/knowledge/
Paramètres de configuration
flowhunt.io/blog/
/articles/
/knowledge/
Début du crawl :
flowhunt.io, ciblant toutes les pages accessibles du domaine (ex : flowhunt.io, flowhunt.io/blog, flowhunt.io/articles, etc.).Application du filtrage d’URL :
/blog/, /articles/ et /knowledge/.flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guide) sont incluses dans le crawl.flowhunt.io/about, flowhunt.io/pricing ou flowhunt.io/contact, sont exclues car elles ne correspondent pas aux motifs définis.Exécution du crawl :
/blog/, /articles/ ou /knowledge/, indexant leur contenu dans la base de connaissances de votre Agent IA.Résultat :
flowhunt.io situées sous /blog/, /articles/ et /knowledge/.En-têtes personnalisés :
Ajoutez des en-têtes HTTP personnalisés pour les requêtes de crawl. Format : HEADER=Valeur (un par ligne) :
Cette fonctionnalité est très utile pour adapter les crawls aux exigences spécifiques d’un site web. En activant les en-têtes personnalisés, les utilisateurs peuvent authentifier les requêtes pour accéder à du contenu restreint, imiter le comportement d’un navigateur particulier ou se conformer à une API ou politique d’accès du site. Par exemple, définir l’en-tête Authorization peut donner accès à des pages protégées, tandis qu’un User-Agent personnalisé peut aider à éviter la détection de bots ou garantir la compatibilité avec des sites restreignant certains crawlers. Cette flexibilité permet une collecte de données plus précise et exhaustive, facilitant l’indexation de contenu pertinent pour la base de connaissances d’un Agent IA tout en respectant les protocoles de sécurité ou d’accès du site.
MYHEADER=Any value
Authorization=Bearer token123
User-Agent=Custom crawler
Allez dans Plannings sur votre tableau de bord FlowHunt
Cliquez sur “Ajouter un nouveau planning”
Configurez les paramètres de base :
Déployez les options avancées si besoin :
Cliquez sur “Ajouter un nouveau planning” pour activer
Pour la plupart des sites web :
Pour les sites riches en JavaScript :
Pour les sites volumineux :
Pour l’e-commerce ou le contenu dynamique :
Les fonctionnalités avancées consomment des crédits supplémentaires :
Surveillez votre consommation de crédits et ajustez les plannings selon vos besoins et votre budget.
Échecs de crawl :
Trop/pas assez de pages :
Contenu manquant :
Générez un plan de contenu optimisé pour le SEO en analysant les premiers résultats de recherche Google pour un mot-clé donné. Ce flux de travail utilise l'IA e...

Découvrez comment générer automatiquement des pages de glossaire complètes et optimisées pour le SEO grâce aux agents IA et à l’automatisation des workflows dan...

Transformez vos idées de blog en plans structurés et exploitables grâce à notre Générateur de Plan de Blog alimenté par l'IA. Cet outil intelligent combine la r...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.