
Serveur MCP MongoDB
Le serveur MCP MongoDB permet une intégration transparente entre les assistants IA et les bases de données MongoDB, autorisant la gestion directe de la base, l’...
5 min de lecture
AI
MCP
+5
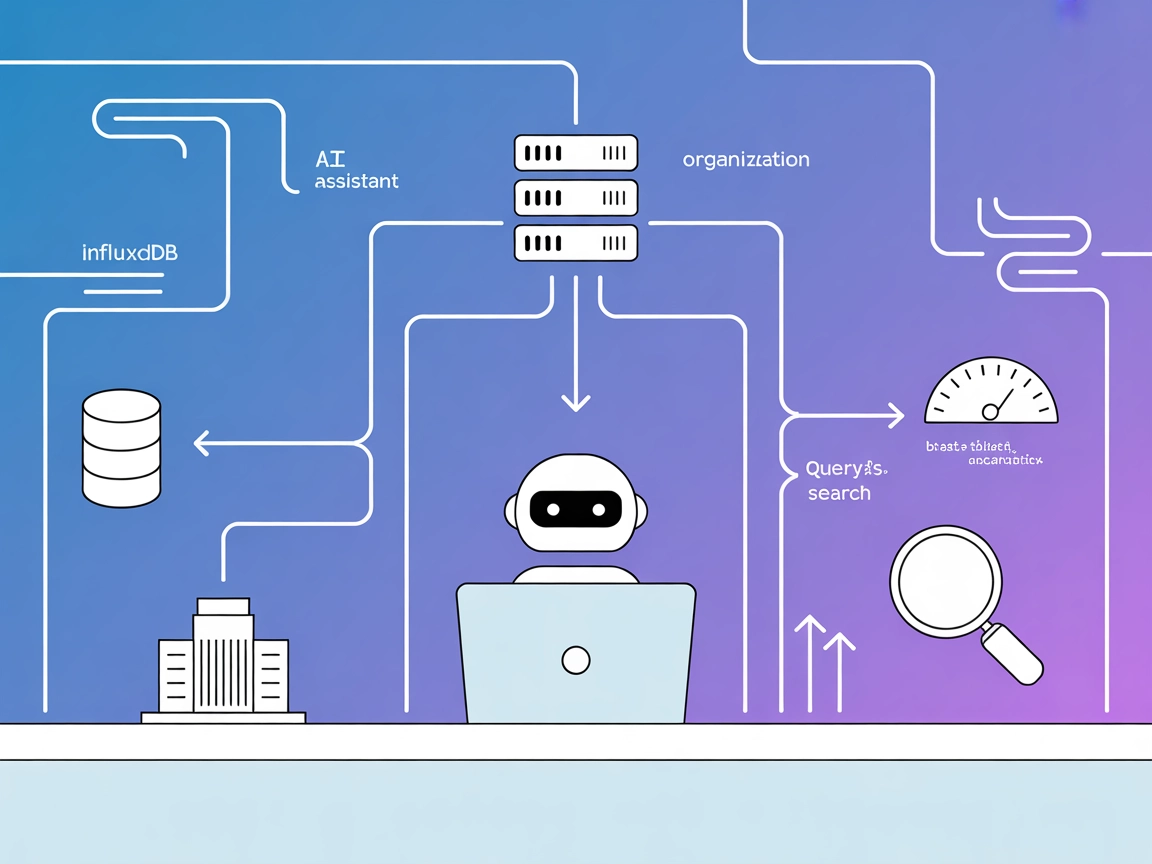
Connectez vos flux FlowHunt à InfluxDB pour l’analytique temps réel des séries temporelles, l’ingestion automatisée de données et la gestion de base de données—exploitez l’IA pour des analyses automatisées et intelligentes.
FlowHunt fournit une couche de sécurité supplémentaire entre vos systèmes internes et les outils d'IA, vous donnant un contrôle granulaire sur les outils accessibles depuis vos serveurs MCP. Les serveurs MCP hébergés dans notre infrastructure peuvent être intégrés de manière transparente avec le chatbot de FlowHunt ainsi qu'avec les plateformes d'IA populaires comme ChatGPT, Claude et divers éditeurs d'IA.
Le serveur MCP InfluxDB est un serveur Model Context Protocol (MCP) conçu pour fournir un accès fluide à une instance InfluxDB via l’API OSS v2 d’InfluxDB. Il agit comme un outil intermédiaire connectant les assistants IA aux données de séries temporelles stockées dans InfluxDB, permettant des workflows améliorés pour les développeurs et les systèmes IA. Grâce à son interface standardisée, le serveur expose à la fois des ressources (telles que les organisations, buckets et mesures) et des outils (comme l’interrogation et l’écriture de données), permettant aux clients IA d’exécuter des requêtes, de gérer des buckets de données, ou d’intégrer de l’analytique temporelle dans leurs applications. Cette intégration robuste garantit que les développeurs peuvent automatiser la gestion des données, rationaliser leurs processus de développement et enrichir l’intelligence de leurs applications en exploitant des données en temps réel et historiques d’InfluxDB.
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
influxdb://orgs) : Affiche toutes les organisations présentes dans l’instance InfluxDB.influxdb://buckets) : Montre tous les buckets avec leurs métadonnées associées.influxdb://bucket/{bucketName}/measurements) : Liste toutes les mesures d’un bucket spécifié.influxdb://query/{orgName}/{fluxQuery}) : Exécute une requête Flux et retourne les résultats sous forme de ressource.Recevez gratuitement les derniers conseils, tendances et offres.
Assurez-vous que Node.js est installé sur votre machine.
Ouvrez le fichier de configuration Windsurf (ex : windsurf.json ou équivalent).
Ajoutez le serveur MCP InfluxDB dans l’objet mcpServers :
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Enregistrez le fichier et redémarrez Windsurf.
Vérifiez que le serveur MCP InfluxDB apparaît bien dans la liste des serveurs MCP.
Sécurisation des clés API
Définissez les valeurs sensibles comme variables d’environnement. Exemple :
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
],
"env": {
"INFLUXDB_TOKEN": "${INFLUXDB_TOKEN_ENV}"
}
}
}
}
Installez Node.js si ce n’est pas déjà fait.
Localisez le fichier de configuration de Claude.
Ajoutez le serveur MCP InfluxDB dans mcpServers :
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Enregistrez les modifications et redémarrez Claude.
Confirmez l’installation via l’interface Claude.
Sécurisation des clés API
(Voir l’exemple Windsurf ci-dessus.)
Vérifiez que Node.js est présent.
Ouvrez les paramètres ou le fichier de configuration de Cursor.
Ajoutez le serveur MCP InfluxDB ainsi :
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Enregistrez et redémarrez Cursor.
Vérifiez la connectivité du serveur MCP.
Sécurisation des clés API
(Voir l’exemple Windsurf ci-dessus.)
Assurez-vous que Node.js est installé.
Modifiez le fichier de configuration de Cline.
Insérez ce qui suit sous mcpServers :
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Enregistrez le fichier et redémarrez Cline.
Vérifiez que le serveur est actif dans Cline.
Sécurisation des clés API
(Voir l’exemple Windsurf ci-dessus.)
Utilisation du MCP dans FlowHunt
Pour intégrer des serveurs MCP dans votre workflow FlowHunt, commencez par ajouter le composant MCP à votre flux et connectez-le à votre agent IA :

Cliquez sur le composant MCP pour ouvrir le panneau de configuration. Dans la section de configuration système MCP, insérez les détails de votre serveur MCP avec ce format JSON :
{
"influxdb-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Une fois configuré, l’agent IA peut utiliser ce MCP comme outil avec accès à toutes ses fonctions et capacités. Pensez à remplacer “influxdb-mcp” par le nom réel de votre serveur MCP et l’URL par celle de votre propre serveur.
| Section | Disponibilité | Détails/Remarques |
|---|---|---|
| Aperçu | ✅ | Présent dans le README.md |
| Liste des prompts | ✅ | flux-query-examples, line-protocol-guide |
| Liste des ressources | ✅ | orgs, buckets, mesures de bucket, requête Flux |
| Liste des outils | ✅ | write-data, query-data, create-bucket, create-org |
| Sécurisation des clés API | ✅ | Exemple de variable d’environnement dans la section configuration |
| Prise en charge du sampling (moins important) | ⛔ | Non mentionné dans la documentation |
Sur la base de ce qui précède, ce serveur MCP est bien documenté pour ses fonctionnalités principales d’intégration InfluxDB. Il expose clairement les ressources et outils, inclut des modèles de prompt et fournit de bonnes instructions d’installation. Cependant, des fonctionnalités MCP avancées telles que roots et sampling ne sont pas documentées, ce qui limite légèrement son extensibilité pour certains workflows.
C’est un serveur MCP robuste et pratique pour InfluxDB, avec une utilité claire pour la gestion des données temporelles et les tâches d’automatisation. Il obtient une excellente note pour l’usage développeur, même s’il manque de documentation sur les fonctionnalités MCP avancées.
| Dispose d’une LICENCE | ✅ (MIT) |
|---|---|
| Au moins un outil | ✅ |
| Nombre de forks | 6 |
| Nombre d’étoiles | 13 |
Il fait le lien entre FlowHunt (ou d’autres assistants IA) et une base de données InfluxDB, vous permettant d’interroger, d’écrire et de gérer des données de séries temporelles via une interface MCP standardisée—pour l’analytique, l’automatisation et l’amélioration des workflows.
Il expose les organisations, les buckets, les mesures de bucket et prend en charge les requêtes Flux directes. Les outils incluent l’écriture de données (line protocol), la requête de données, la création de buckets et la création d’organisations.
Utilisez l’outil 'write-data' pour l’ingestion automatisée au format line protocol, ou l’outil 'query-data' pour les requêtes Flux avancées—tous accessibles via les flux FlowHunt.
Oui, il est recommandé d’utiliser des variables d’environnement pour stocker les tokens API ou secrets, afin que les identifiants ne soient jamais codés en dur dans les fichiers de configuration.
Analytique IA sur les séries temporelles, pipelines IoT automatisés, gestion de base de données pour organisations/buckets, et exploration dynamique de données—directement dans FlowHunt.
Roots et sampling ne sont pas documentés pour ce serveur actuellement, mais toutes les fonctionnalités principales d’intégration InfluxDB sont pleinement prises en charge.
Automatisez les workflows de données de séries temporelles et donnez à vos agents IA un accès direct à InfluxDB grâce au serveur MCP InfluxDB dans FlowHunt.
Le serveur MCP MongoDB permet une intégration transparente entre les assistants IA et les bases de données MongoDB, autorisant la gestion directe de la base, l’...
Le Serveur de Base de Données MCP permet un accès sécurisé et programmatique aux bases de données populaires comme SQLite, SQL Server, PostgreSQL et MySQL pour ...
Intégrez FlowHunt avec le serveur MCP InfluxDB pour automatiser la gestion des données temporelles, rationaliser l'organisation des ressources et exploiter des ...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.