
FlowHunt 2.4.1 porta Claude, Grok, Llama e altro ancora
FlowHunt 2.4.1 introduce importanti nuovi modelli di IA, tra cui Claude, Grok, Llama, Mistral, DALL-E 3 e Stable Diffusion, ampliando le possibilità di sperimen...
2 min di lettura
AI
LLM
+7

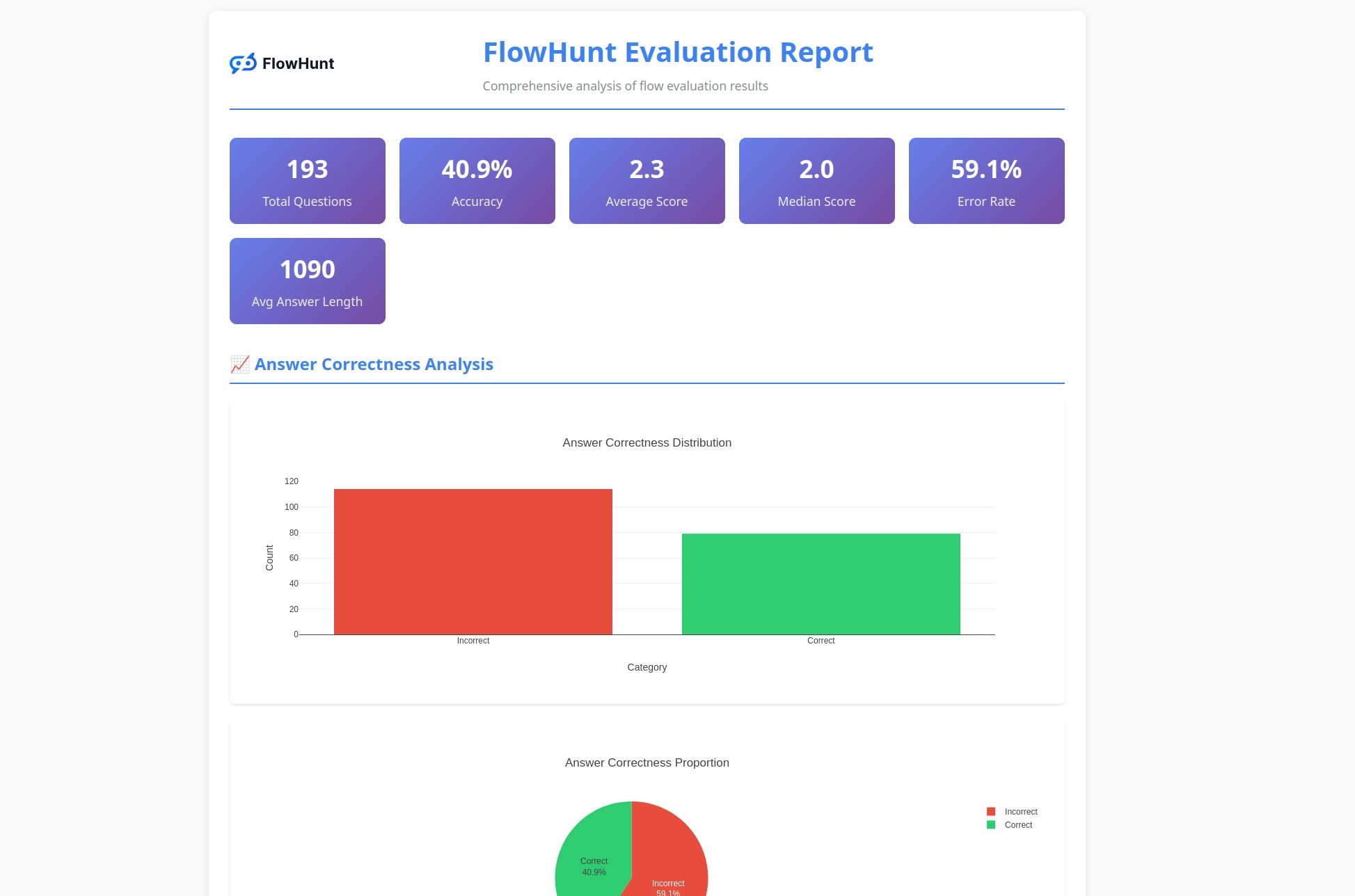
Il nuovo toolkit CLI open source di FlowHunt consente una valutazione completa dei flussi con LLM come Giudice, offrendo report dettagliati e valutazione automatica della qualità per i workflow AI.
Siamo entusiasti di annunciare il rilascio del FlowHunt CLI Toolkit – il nostro nuovo strumento da riga di comando open source progettato per rivoluzionare il modo in cui gli sviluppatori valutano e testano i flussi AI. Questo potente toolkit porta capacità di valutazione di livello enterprise nella comunità open source, con reportistica avanzata e la nostra innovativa implementazione “LLM come Giudice”.
Il FlowHunt CLI Toolkit rappresenta un passo avanti significativo nel testing e nella valutazione dei workflow AI. Ora disponibile su GitHub , questo toolkit open source offre agli sviluppatori strumenti completi per:
Il toolkit incarna il nostro impegno verso la trasparenza e lo sviluppo guidato dalla comunità, rendendo le tecniche avanzate di valutazione AI accessibili agli sviluppatori di tutto il mondo.
Una delle funzionalità più innovative del nostro toolkit CLI è l’implementazione di “LLM come Giudice”. Questo approccio utilizza l’intelligenza artificiale per valutare la qualità e la correttezza delle risposte generate dagli AI – in sostanza, fa sì che un AI giudichi le performance di un altro AI con capacità di ragionamento sofisticate.
Ciò che rende unica la nostra implementazione è che abbiamo usato FlowHunt stesso per creare il flusso di valutazione. Questo approccio meta dimostra la potenza e la flessibilità della nostra piattaforma, offrendo al contempo un sistema di valutazione robusto. Il flusso LLM come Giudice è composto da diversi componenti interconnessi:
1. Prompt Template: Crea il prompt di valutazione con criteri specifici
2. Structured Output Generator: Elabora la valutazione tramite un LLM
3. Data Parser: Format il risultato strutturato per la reportistica
4. Chat Output: Presenta i risultati finali della valutazione
Al centro del nostro sistema LLM come Giudice c’è un prompt accuratamente realizzato che garantisce valutazioni coerenti e affidabili. Ecco il prompt template principale che utilizziamo:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Questo prompt assicura che il nostro giudice LLM fornisca:
Inizia oggi la tua prova gratuita e vedi i risultati in pochi giorni.
Il nostro flusso LLM come Giudice dimostra un design sofisticato dei workflow AI utilizzando il costruttore visuale dei flussi di FlowHunt. Ecco come i componenti lavorano insieme:
Il flusso inizia con un componente Chat Input che riceve la richiesta di valutazione contenente sia la risposta reale che quella di riferimento.
Il componente Prompt Template costruisce dinamicamente il prompt di valutazione:
{target_response}{actual_response}Il Structured Output Generator elabora il prompt tramite un LLM selezionato e genera un output strutturato che include:
total_rating: Punteggio numerico da 1 a 4correctness: Classificazione binaria corretto/erratoreasoning: Spiegazione dettagliata della valutazioneIl componente Parse Data formatta l’output strutturato in modo leggibile, e il componente Chat Output presenta i risultati finali della valutazione.
Il sistema LLM come Giudice offre diverse funzionalità avanzate che lo rendono particolarmente efficace per la valutazione dei flussi AI:
A differenza della semplice corrispondenza di stringhe, il nostro giudice LLM comprende:
La scala di valutazione a 4 punti offre un’analisi granulare:
Ogni valutazione include un ragionamento dettagliato, che permette di:
Ricevi gratuitamente gli ultimi consigli, tendenze e offerte.
Il toolkit CLI genera report dettagliati che forniscono insight utili sulle performance dei flussi:
Pronto a valutare i tuoi flussi AI con strumenti professionali? Ecco come iniziare:
Installazione One-Line (Consigliata) per macOS e Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Questo installerà automaticamente:
flowhunt al PATHInstallazione Manuale:
# Clona il repository
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Installa con pip
pip install -e .
Verifica Installazione:
flowhunt --help
flowhunt --version
1. Autenticazione
Per prima cosa, autenticati con la tua API FlowHunt:
flowhunt auth
2. Elenca i Tuoi Flussi
flowhunt flows list
3. Valuta un Flusso
Crea un file CSV con i tuoi dati di test:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Esegui la valutazione con LLM come Giudice:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Esecuzione Batch dei Flussi
flowhunt batch-run your-flow-id input.csv --output-dir results/
Il sistema di valutazione offre un’analisi completa:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Le funzionalità includono:
Il toolkit CLI si integra perfettamente con la piattaforma FlowHunt, permettendoti di:
Il rilascio del nostro toolkit CLI rappresenta più di un semplice nuovo strumento – è una visione per il futuro dello sviluppo AI dove:
La Qualità è Misurabile: Tecniche di valutazione avanzate rendono le performance AI quantificabili e confrontabili.
Il Testing è Automatizzato: Framework di testing completi riducono il lavoro manuale e migliorano l’affidabilità.
La Trasparenza è lo Standard: Ragionamenti e report dettagliati rendono il comportamento dell’AI comprensibile e debugabile.
La Comunità Guida l’Innovazione: Strumenti open source favoriscono il miglioramento collaborativo e la condivisione delle conoscenze.
Rendendo open source il FlowHunt CLI Toolkit, dimostriamo il nostro impegno per:
Il FlowHunt CLI Toolkit con LLM come Giudice rappresenta un avanzamento significativo nelle capacità di valutazione dei flussi AI. Combinando logiche di valutazione sofisticate, reportistica completa e accessibilità open source, stiamo dando agli sviluppatori la possibilità di costruire sistemi AI migliori e più affidabili.
L’approccio meta di usare FlowHunt per valutare i flussi FlowHunt dimostra la maturità e la flessibilità della nostra piattaforma, offrendo al contempo uno strumento potente per tutta la comunità di sviluppo AI.
Che tu stia costruendo semplici chatbot o sistemi multi-agente complessi, il FlowHunt CLI Toolkit fornisce l’infrastruttura di valutazione di cui hai bisogno per garantire qualità, affidabilità e miglioramento continuo.
Pronto a portare la valutazione dei tuoi flussi AI al livello successivo? Visita il nostro repository GitHub per iniziare oggi con il FlowHunt CLI Toolkit e scopri la potenza di LLM come Giudice.
Il futuro dello sviluppo AI è qui – ed è open source.
Il FlowHunt CLI Toolkit è uno strumento da riga di comando open source per valutare i flussi AI con funzionalità di reportistica completa. Include caratteristiche come la valutazione LLM come Giudice, analisi dei risultati corretti/errati e metriche di performance dettagliate.
LLM come Giudice utilizza un flusso AI sofisticato costruito all'interno di FlowHunt per valutare altri flussi. Confronta le risposte reali con le risposte di riferimento, fornendo valutazioni, giudizi di correttezza e ragionamenti dettagliati per ogni valutazione.
Il FlowHunt CLI Toolkit è open source e disponibile su GitHub all'indirizzo https://github.com/yasha-dev1/flowhunt-toolkit. Puoi clonarlo, contribuire e usarlo liberamente per le tue esigenze di valutazione dei flussi AI.
Il toolkit genera report completi, includendo la suddivisione tra risultati corretti/errati, valutazioni LLM come Giudice con punteggi e ragionamenti, metriche di performance e analisi dettagliata del comportamento dei flussi su diversi casi di test.
Sì! Il flusso LLM come Giudice è costruito utilizzando la piattaforma di FlowHunt e può essere adattato a diversi scenari di valutazione. Puoi modificare il template del prompt e i criteri di valutazione secondo le tue esigenze specifiche.
Yasha è un talentuoso sviluppatore software specializzato in Python, Java e machine learning. Yasha scrive articoli tecnici su AI, prompt engineering e sviluppo di chatbot.

Crea e valuta workflow AI sofisticati con la piattaforma di FlowHunt. Inizia oggi a creare flussi che possono giudicare altri flussi.
FlowHunt 2.4.1 introduce importanti nuovi modelli di IA, tra cui Claude, Grok, Llama, Mistral, DALL-E 3 e Stable Diffusion, ampliando le possibilità di sperimen...

FlowHunt introduce importanti aggiornamenti tra cui server MCP personalizzati, login SSO per clienti enterprise, integrazione Odoo, nuovi modelli AI (Grok 4 e K...
Integra FlowHunt con MCP Discovery per automatizzare l'introspezione dei server MCP, generare documentazione multi-formato e ottimizzare i flussi di lavoro CI/C...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.