Pianificazione di scansioni automatiche dei siti web
Scopri come impostare pianificazioni automatiche per la scansione di siti web, sitemap, domini e canali YouTube per mantenere aggiornata la knowledge base del tuo Agente AI.
Schedules
Crawling
AI Agent
Knowledge Base
Automation
Pianificazione di scansioni automatiche dei siti web:
Select section...
Come funziona la pianificazione
Opzioni di configurazione della pianificazione
Impostazioni di base
Opzioni avanzate di scansione
Filtraggio URL
Esempio: scansione di flowhunt.io saltando /blog
Esempio di inclusione di URL corrispondenti
Come creare una pianificazione
Best Practice
Utilizzo crediti
Risoluzione dei problemi comuni
La funzione Pianificazioni di FlowHunt ti permette di automatizzare la scansione e l’indicizzazione di siti web, sitemap, domini e canali YouTube. In questo modo la knowledge base del tuo Agente AI resta aggiornata con contenuti freschi senza interventi manuali.
Come funziona la pianificazione
Scansione automatica: Imposta scansioni ricorrenti che si eseguono ogni giorno, settimana, mese o anno per mantenere aggiornata la knowledge base.
Tipi di scansione multipli: Scegli tra scansione del dominio, scansione della sitemap, scansione di URL o scansione di canale YouTube in base alla fonte dei tuoi contenuti.
Opzioni avanzate: Configura rendering del browser, inseguimento dei link, screenshot, rotazione proxy e filtraggio degli URL per risultati ottimali.
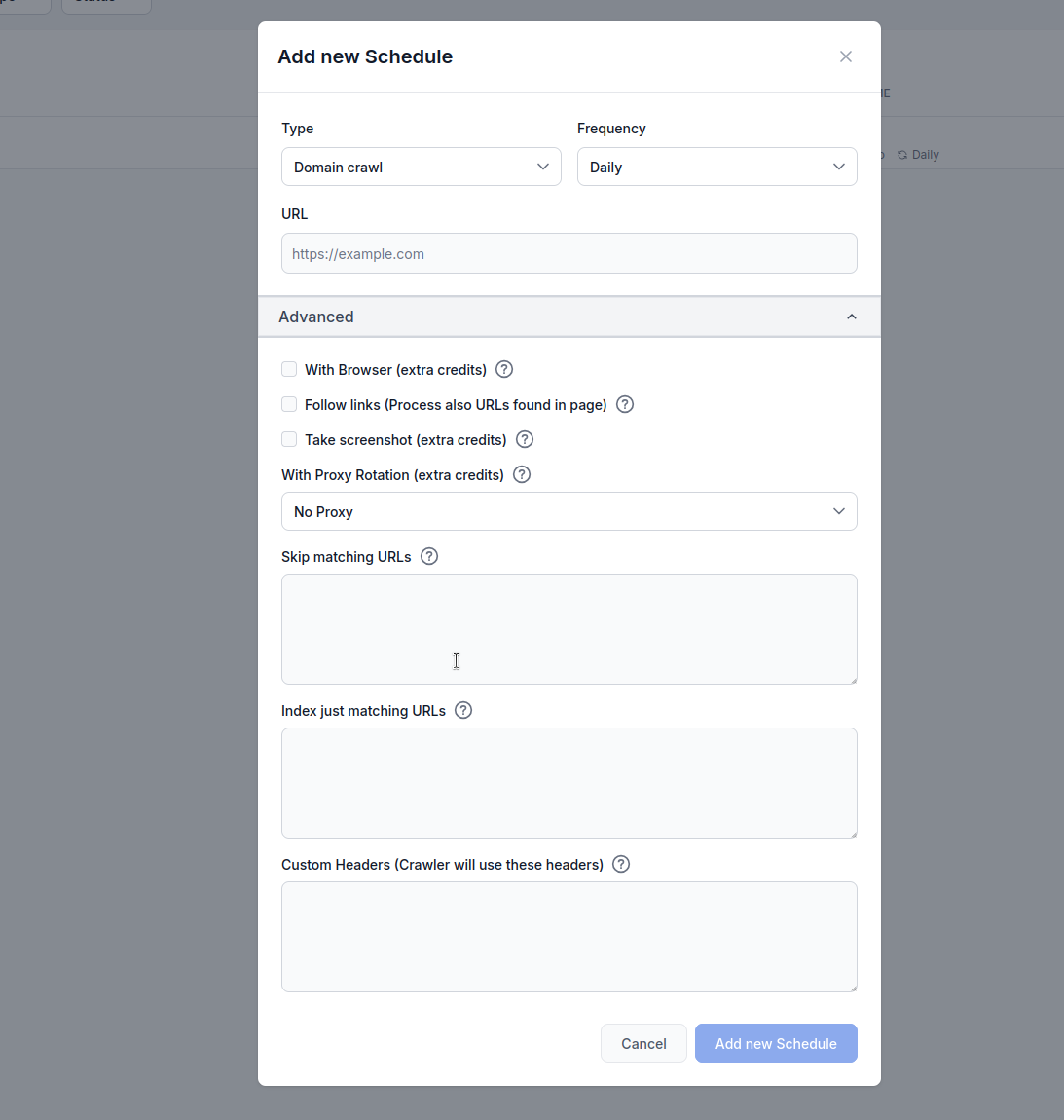
Opzioni di configurazione della pianificazione
Impostazioni di base
Tipo: Scegli il metodo di scansione:
Scansione dominio: Scansiona sistematicamente un intero dominio
Scansione sitemap: Usa la sitemap.xml del sito per una scansione efficiente
Scansione URL: Targetizza URL o pagine specifiche
Scansione canale YouTube: Indicizza i contenuti video dei canali YouTube
Frequenza: Imposta ogni quanto eseguire la scansione:
Giornaliera, Settimanale, Mensile o Annuale
URL: Inserisci l’URL di destinazione, dominio o canale YouTube da scansionare
Opzioni avanzate di scansione
Con Browser (crediti extra):
Attiva questa opzione quando scansioni siti web ricchi di JavaScript che richiedono il rendering completo del browser. È più lenta e costosa, ma necessaria per siti che caricano i contenuti in modo dinamico.
Segui i link (crediti extra):
Processa ulteriori URL trovati all’interno delle pagine. Utile quando le sitemap non contengono tutti gli URL, ma può consumare molti crediti poiché scansiona anche i link scoperti.
Cattura screenshot (crediti extra):
Acquisisci screenshot visivi durante la scansione. Utile per siti senza og:images o che richiedono contesto visivo per l’elaborazione AI.
Con rotazione proxy (crediti extra):
Ruota gli indirizzi IP per ogni richiesta per evitare i Web Application Firewall (WAF) o sistemi anti-bot.
Filtraggio URL
Salta URL corrispondenti:
Inserisci stringhe (una per riga) per escludere dalla scansione gli URL che contengono questi pattern. Esempio:
/admin/
/login
.pdf
Esempio: scansione di flowhunt.io saltando /blog
Questo esempio spiega cosa succede quando usi la funzione Pianificazioni di FlowHunt per scansionare il dominio flowhunt.io impostando /blog come pattern di URL da saltare nelle impostazioni di filtraggio URL.
Configurazione
Tipo: Scansione dominio
URL:flowhunt.io
Frequenza: Settimanale
Filtraggio URL (Salta URL corrispondenti):/blog
Altre impostazioni: Default (senza rendering browser, senza inseguimento link, senza screenshot, senza rotazione proxy)
Cosa succede
Inizio scansione:
FlowHunt avvia una scansione dominio di flowhunt.io, targetizzando tutte le pagine accessibili del dominio (es. flowhunt.io, flowhunt.io/features, flowhunt.io/pricing, ecc.).
Applicazione filtraggio URL:
Il crawler valuta ogni URL scoperto rispetto al pattern di skip /blog.
Qualsiasi URL contenente /blog (es. flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/category) viene escluso dalla scansione.
Gli altri URL, come flowhunt.io/about, flowhunt.io/contact o flowhunt.io/docs, vengono scansionati perché non corrispondono al pattern /blog.
Esecuzione scansione:
Il crawler processa sistematicamente gli URL rimanenti su flowhunt.io, indicizzando i loro contenuti nella knowledge base del tuo Agente AI.
Poiché rendering browser, inseguimento link, screenshot e rotazione proxy sono disattivati, la scansione è leggera e si concentra solo sui contenuti statici degli URL non esclusi.
Risultato:
La knowledge base del tuo Agente AI si aggiorna con contenuti freschi da flowhunt.io, escludendo tutto ciò che è sotto il percorso /blog.
La scansione viene eseguita settimanalmente, così la knowledge base resta aggiornata con le nuove o aggiornate pagine (al di fuori di /blog) senza intervento manuale.
Indicizza solo URL corrispondenti:
Inserisci stringhe (una per riga) per scansionare solo gli URL che contengono questi pattern. Esempio:
/blog/
/articles/
/knowledge/
Esempio di inclusione di URL corrispondenti
Configurazione
Tipo: Scansione dominio
URL:flowhunt.io
Frequenza: Settimanale
Filtraggio URL (Indicizza solo URL corrispondenti):
/blog/
/articles/
/knowledge/
Altre impostazioni: Default (senza rendering browser, senza inseguimento link, senza screenshot, senza rotazione proxy)
Inizio scansione:
FlowHunt avvia una scansione dominio di flowhunt.io, targetizzando tutte le pagine accessibili del dominio (es. flowhunt.io, flowhunt.io/blog, flowhunt.io/articles, ecc.).
Applicazione filtraggio URL:
Il crawler valuta ogni URL scoperto rispetto ai pattern di indicizzazione /blog/, /articles/ e /knowledge/.
Soltanto gli URL che contengono questi pattern (es. flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guide) sono inclusi nella scansione.
Gli altri URL, come flowhunt.io/about, flowhunt.io/pricing o flowhunt.io/contact, sono esclusi perché non corrispondono ai pattern specificati.
Esecuzione scansione:
Il crawler processa solo gli URL che corrispondono a /blog/, /articles/ o /knowledge/, indicizzando i loro contenuti nella knowledge base del tuo Agente AI.
Poiché rendering browser, inseguimento link, screenshot e rotazione proxy sono disattivati, la scansione è leggera e si concentra solo sui contenuti statici degli URL inclusi.
Risultato:
La knowledge base del tuo Agente AI viene aggiornata con i contenuti freschi delle pagine di flowhunt.io sotto i percorsi /blog/, /articles/ e /knowledge/.
La scansione viene eseguita settimanalmente, così la knowledge base resta aggiornata con nuove o aggiornate pagine all’interno di queste sezioni senza intervento manuale.
Header personalizzati:
Aggiungi header HTTP personalizzati per le richieste di scansione. Il formato è HEADER=Valore (uno per riga):
Questa funzione è molto utile per adattare le scansioni alle esigenze specifiche di determinati siti web. Abilitando header personalizzati, gli utenti possono autenticare le richieste per accedere a contenuti riservati, simulare specifici comportamenti del browser o rispettare le policy API o di accesso di un sito. Ad esempio, impostando un header Authorization puoi ottenere accesso a pagine protette, mentre uno User-Agent personalizzato può aiutare a evitare il rilevamento come bot o garantire compatibilità con siti che limitano certi crawler. Questa flessibilità permette una raccolta dati più accurata e completa, facilitando l’indicizzazione di contenuti rilevanti nella knowledge base dell’Agente AI nel rispetto delle policy di sicurezza o accesso del sito.
MYHEADER=Qualsiasi valore
Authorization=Bearer token123
User-Agent=Custom crawler
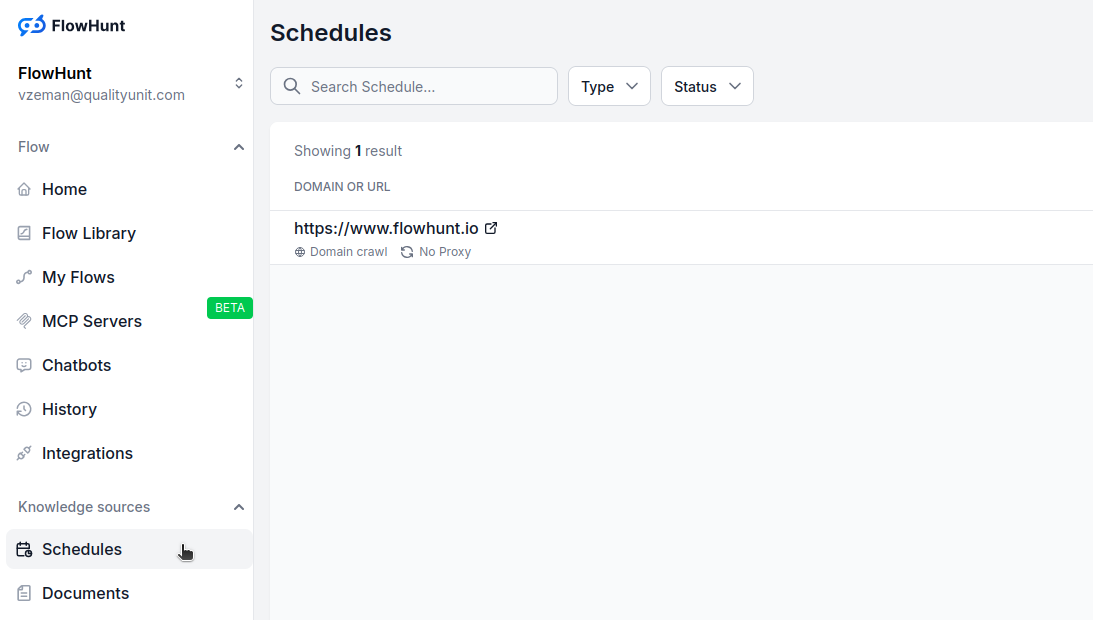
Come creare una pianificazione
Vai su Pianificazioni nella dashboard di FlowHunt
Clicca su “Aggiungi nuova pianificazione”
Configura le impostazioni di base:
Seleziona il tipo di scansione (Dominio/Sitemap/URL/YouTube)
Imposta la frequenza (Giornaliera/Settimanale/Mensile/Annuale)
Inserisci l’URL di destinazione
Espandi le opzioni avanzate se necessario:
Abilita il rendering browser per siti pesanti in JS
Configura l’inseguimento link per una scansione più completa
Imposta le regole di filtraggio URL
Aggiungi header personalizzati se richiesto
Clicca su “Aggiungi nuova pianificazione” per attivare
Best Practice
Per la maggior parte dei siti web:
Inizia con una scansione Sitemap o Dominio di base
Usa inizialmente le impostazioni predefinite
Aggiungi opzioni avanzate solo se necessario
Per siti pesanti in JavaScript:
Abilita l’opzione “Con Browser”
Valuta di catturare screenshot per contenuti visivi
Potresti aver bisogno della rotazione proxy se bloccato
Per siti di grandi dimensioni:
Usa il filtraggio URL per focalizzarti sui contenuti rilevanti
Imposta una frequenza adeguata per bilanciare aggiornamento e consumo crediti
Monitora il consumo crediti con le funzioni avanzate
Per e-commerce o contenuti dinamici:
Usa frequenza Giornaliera o Settimanale
Abilita l’inseguimento link per le pagine prodotto
Valuta header personalizzati per contenuti autenticati
Utilizzo crediti
Le funzioni avanzate consumano crediti aggiuntivi:
Il rendering browser aumenta tempo e costo di elaborazione
L’inseguimento link moltiplica le pagine scansionate
Gli screenshot aggiungono carico visivo
La rotazione proxy aggiunge overhead di rete
Monitora il consumo crediti e regola le pianificazioni in base alle tue esigenze e al budget.
Risoluzione dei problemi comuni
Errori di scansione:
Abilita “Con Browser” per siti dipendenti da JavaScript
Aggiungi “Con rotazione proxy” se bloccato da WAF
Controlla gli header personalizzati per l’autenticazione
Troppe/Poche pagine:
Usa “Salta URL corrispondenti” per escludere contenuti non desiderati
Usa “Indicizza solo URL corrispondenti” per concentrarti su sezioni specifiche
Regola le impostazioni di inseguimento link
Contenuti mancanti:
Abilita “Segui i link” se la sitemap è incompleta
Verifica che le regole di filtraggio URL non siano troppo restrittive
Controlla che l’URL di destinazione sia accessibile
Come Generare Pagine Glossario Ottimizzate SEO con l’IA in FlowHunt
Scopri come generare automaticamente pagine glossario complete e ottimizzate per la SEO utilizzando agenti IA e automazione dei flussi di lavoro in FlowHunt. Da...
Trasforma la tua strategia di contenuti con il nostro Pianificatore di Contenuti potenziato dall'Intelligenza Artificiale che combina capacità AI avanzate con r...
Distribuisci un agente AI intelligente che crea e pubblica automaticamente articoli sul blog, aggiorna le pagine con nuovi contenuti, gestisce i caricamenti mul...
4 min di lettura
AI
Wix
+3
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.