
カスタムナレッジベースを追加してAIの幻覚を減らす
FlowHuntのスケジュール機能を使ってAIの幻覚を減らし、チャットボットの回答精度を確保しましょう。利点、実践的なユースケース、導入手順を詳しく解説します。...
1 分で読める
AI
Chatbot
+4
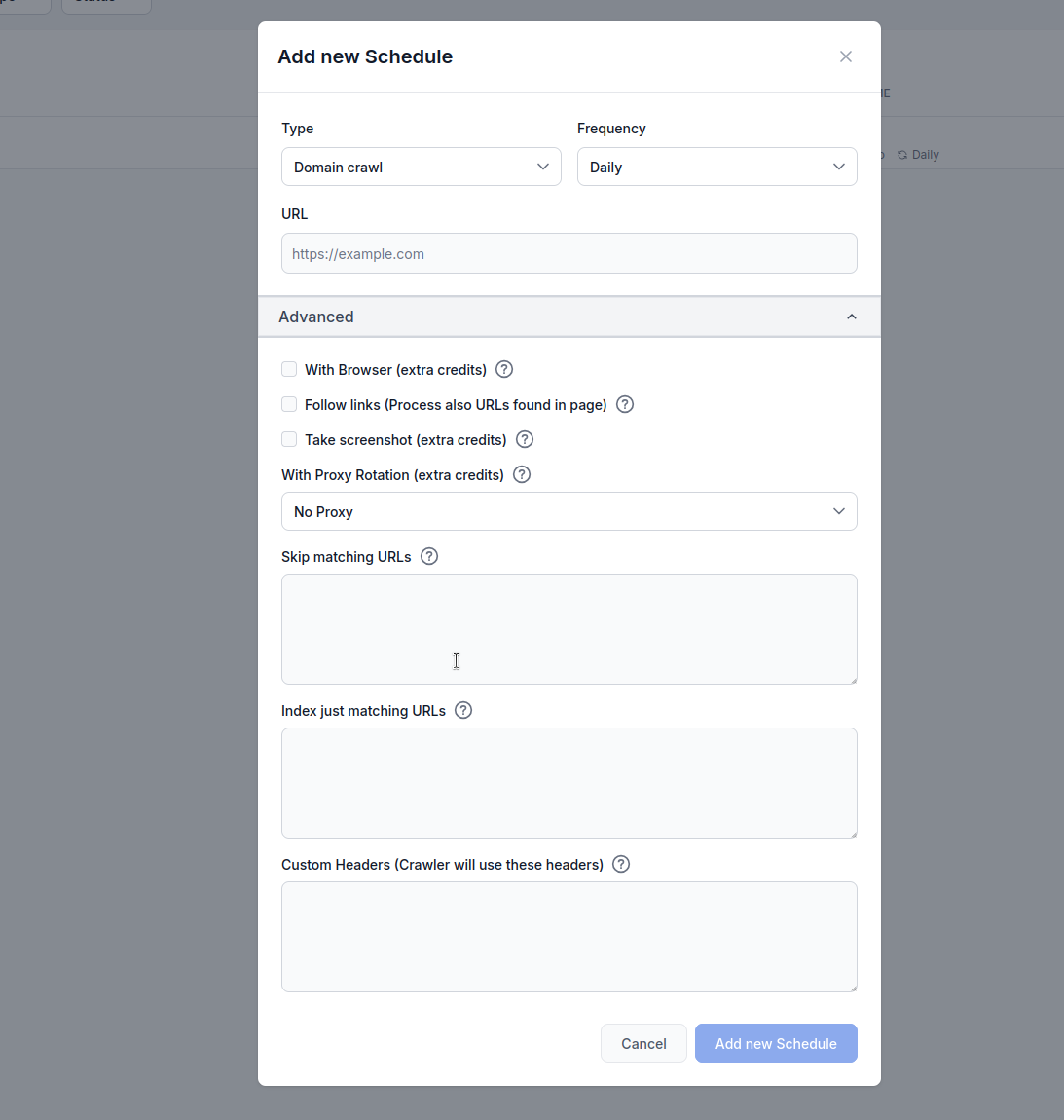
ウェブサイト、サイトマップ、ドメイン、YouTubeチャンネルの自動クロールスケジュールを設定し、AIエージェントのナレッジベースを常に最新に保つ方法をご紹介します。
FlowHuntのスケジュール機能を使えば、ウェブサイト、サイトマップ、ドメイン、YouTubeチャンネルのクロールとインデックス化を自動化できます。これにより、AIエージェントのナレッジベースは手動での作業なしでも常に最新のコンテンツで保たれます。
自動クロール:
日次・週次・月次・年次の定期クロールを設定し、ナレッジベースを常に最新に保てます。
複数のクロールタイプ:
コンテンツソースに応じて、ドメインクロール、サイトマップクロール、URLクロール、YouTubeチャンネルクロールから選択できます。
高度なオプション:
ブラウザレンダリング、リンク追跡、スクリーンショット、プロキシローテーション、URLフィルタリングなどの設定が可能です。
タイプ: クロール方法を選択します。
頻度: クロールを実行する間隔を設定します。
URL: クロール対象となるURL、ドメイン、またはYouTubeチャンネルを入力
ブラウザ使用(追加クレジット消費):
JavaScriptを多用したサイトなど、フルブラウザレンダリングが必要な場合に有効化します。処理は遅く高コストですが、動的なコンテンツの取得に必須です。
リンク追跡(追加クレジット消費):
ページ内で発見された追加URLもクロールします。サイトマップに全URLが含まれていない場合に便利ですが、発見リンクを巡回するため大量のクレジットを消費します。
スクリーンショット取得(追加クレジット消費):
クロール時にビジュアルスクリーンショットを取得します。og:imageがないサイトやAI処理時にビジュアルコンテキストが必要な場合に有効です。
プロキシローテーション使用(追加クレジット消費):
各リクエストでIPアドレスを変更し、WAFやボット対策を回避します。
一致するURLをスキップ:
これらの文字列(1行につき1つ)を含むURLをクロール対象から除外します。例:
/admin/
/login
.pdf
この例では、FlowHuntのスケジュール機能でflowhunt.ioドメインをクロールし、URLフィルタリング設定の「一致するURLをスキップ」に/blogを指定した場合の動作を説明します。
設定内容
flowhunt.io/blog動作の流れ
クロール開始:
flowhunt.ioのドメインクロールを開始し、ドメイン内の全てのアクセス可能なページ(例: flowhunt.io, flowhunt.io/features, flowhunt.io/pricingなど)をターゲットとします。URLフィルタリングの適用:
/blogと照合します。/blogを含むすべてのURL(例: flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/categoryなど)はクロール対象外となります。flowhunt.io/about, flowhunt.io/contact, flowhunt.io/docsなど他のURLは/blogに一致しないためクロールされます。クロール実行:
結果:
/blog配下を除くflowhunt.ioの新しいコンテンツでAIエージェントのナレッジベースが更新されます。/blog以外の新規・更新ページが対象)。一致するURLのみをインデックス:
これらの文字列(1行につき1つ)を含むURLのみをクロールします。例:
/blog/
/articles/
/knowledge/
設定内容
flowhunt.io/blog/
/articles/
/knowledge/
クロール開始:
flowhunt.ioのドメインクロールを開始し、ドメイン内の全てのアクセス可能なページ(例: flowhunt.io, flowhunt.io/blog, flowhunt.io/articlesなど)をターゲットとします。URLフィルタリングの適用:
/blog/, /articles/, /knowledge/のいずれかが含まれるか照合します。flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guideなど)のみクロール対象となります。flowhunt.io/about, flowhunt.io/pricing, flowhunt.io/contactなど、指定パターンに一致しないURLはクロール対象外となります。クロール実行:
/blog/, /articles/, /knowledge/に一致したURLのみを処理し、AIエージェントのナレッジベース用にコンテンツをインデックス化します。結果:
/blog/, /articles/, /knowledge/配下の新しいコンテンツでAIエージェントのナレッジベースが更新されます。カスタムヘッダー:
クロールリクエスト用のカスタムHTTPヘッダーを追加します。HEADER=値 の形式で1行ごとに記入してください。
この機能は、特定のウェブサイト要件に合わせてクロールを調整するのに大変便利です。カスタムヘッダーを有効にすることで、認証が必要なコンテンツへのアクセス、特定のブラウザ動作の模倣、APIやサイトのアクセスルールへの準拠などが可能になります。たとえば、Authorizationヘッダーを設定すれば保護ページへアクセスでき、User-Agentをカスタムにすればボット判定を回避したり、特定のクローラーを制限するサイトでも互換性を保てます。この柔軟性により、AIエージェントのナレッジベース構築に必要なコンテンツを、サイトのセキュリティやアクセス規則を遵守しながら正確かつ包括的に収集できます。
MYHEADER=Any value
Authorization=Bearer token123
User-Agent=Custom crawler
FlowHuntダッシュボードで「スケジュール」へ移動
「新しいスケジュールを追加」をクリック
基本設定を構成:
必要に応じて「詳細オプション」を展開:
**「新しいスケジュールを追加」をクリックして有効化
一般的なウェブサイトの場合:
JavaScript依存サイトの場合:
大型サイトの場合:
EC・動的コンテンツの場合:
高度な機能は追加クレジットを消費します:
クレジット使用量を監視し、ニーズや予算に応じてスケジュールを調整しましょう。
クロール失敗:
対象ページが多すぎる/少なすぎる:
コンテンツが取得できない:
FlowHuntのスケジュール機能を使ってAIの幻覚を減らし、チャットボットの回答精度を確保しましょう。利点、実践的なユースケース、導入手順を詳しく解説します。...
FlowHuntのスケジュール機能では、ドメインやYouTubeチャンネルを定期的にクロールし、チャットボットやフローを常に最新情報で保つことができます。クロールの種類や頻度をカスタマイズして自動化し、AIによるやり取りが常に正確かつ関連性のあるものになるようにしましょう。...
フローはFlowHuntの頭脳です。ノーコードのビジュアルビルダーで、最初のコンポーネントの配置からWebサイトへの統合、チャットボットの展開、テンプレートの活用まで、フローの作り方を学びましょう。...