MCPデータベースサーバー
MCPデータベースサーバーは、SQLite、SQL Server、PostgreSQL、MySQLなどの主要データベースへの安全でプログラム的なアクセスをAIアシスタントや自動化ツールに提供します。ブリッジとして機能し、コンテキスト認識ワークフローやAI搭載アプリケーションが効率的に構造化データを照会・管理・操作できる...
1 分で読める
AI
Database
+4
FlowHuntは、お客様の内部システムとAIツールの間に追加のセキュリティレイヤーを提供し、MCPサーバーからアクセス可能なツールをきめ細かく制御できます。私たちのインフラストラクチャーでホストされているMCPサーバーは、FlowHuntのチャットボットや、ChatGPT、Claude、さまざまなAIエディターなどの人気のAIプラットフォームとシームレスに統合できます。
InfluxDB MCPサーバーは、InfluxDB OSS API v2を用いてInfluxDBインスタンスへのシームレスなアクセスを提供するModel Context Protocol(MCP)サーバーです。AIアシスタントとInfluxDBに保存された時系列データをつなぐ仲介ツールとして機能し、開発者やAIシステムのワークフローを強化します。標準化されたインターフェースを通じて、組織・バケット・計測値などのリソースや、クエリ・データ書き込みなどのツールを公開。データベースのクエリ実行、バケット管理、時系列分析のアプリケーション組み込みなど、多様なタスクがAIクライアントから実行可能です。この強力な統合により、開発者はデータ処理の自動化、開発プロセスの効率化、リアルタイムおよび過去データを活用したアプリの知能化を実現できます。
influxdb://orgs): InfluxDBインスタンス内のすべての組織を表示。influxdb://buckets): すべてのバケットとそのメタデータを表示。influxdb://bucket/{bucketName}/measurements): 指定バケット内の全計測値を一覧表示。influxdb://query/{orgName}/{fluxQuery}): Fluxクエリを実行し、結果をリソースとして返却。最新のヒント、トレンド、お得な情報を無料で入手。
お使いのマシンにNode.jsがインストールされていることを確認してください。
Windsurfの設定ファイル(例: windsurf.jsonなど)を開きます。
mcpServersオブジェクトにInfluxDB MCPサーバーを追加します:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
ファイルを保存し、Windsurfを再起動します。
MCPサーバー一覧にInfluxDB MCPサーバーが表示されていることを確認してください。
APIキーのセキュリティ
機密値は環境変数として設定しましょう。例:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
],
"env": {
"INFLUXDB_TOKEN": "${INFLUXDB_TOKEN_ENV}"
}
}
}
}
Node.jsが未インストールの場合はインストールします。
Claudeの設定ファイルを探します。
mcpServersにInfluxDB MCPサーバーを追加:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
保存してClaudeを再起動。
Claudeのインターフェースでセットアップを確認。
APIキーのセキュリティ
(Windsurfの例を参照)
Node.jsがインストールされていることを確認。
Cursorの設定または設定ファイルを開く。
以下でInfluxDB MCPサーバーを追加:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
保存し、Cursorを再起動。
MCPサーバーの接続状況を確認。
APIキーのセキュリティ
(Windsurfの例を参照)
Node.jsがインストールされていることを確認。
Clineの設定ファイルを編集。
mcpServersに以下を挿入:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
保存してClineを再起動。
Cline上でサーバーが稼働していることを検証。
APIキーのセキュリティ
(Windsurfの例を参照)
FlowHuntでMCPを利用するには
FlowHuntのワークフローにMCPサーバーを統合するには、まずMCPコンポーネントをフローに追加し、AIエージェントに接続します。

MCPコンポーネントをクリックして設定パネルを開きます。システムMCP設定欄に、以下のJSON形式でMCPサーバー情報を挿入してください:
{
"influxdb-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
設定が完了すると、AIエージェントはこのMCPをツールとして利用でき、すべての機能にアクセス可能になります。influxdb-mcpは実際のMCPサーバー名に、URL部分はご自身のMCPサーバーURLに置き換えてください。
| セクション | 対応状況 | 詳細・備考 |
|---|---|---|
| 概要 | ✅ | README.mdで提供 |
| プロンプト一覧 | ✅ | flux-query-examples, line-protocol-guide |
| リソース一覧 | ✅ | orgs, buckets, bucket measurements, Fluxクエリ |
| ツール一覧 | ✅ | write-data, query-data, create-bucket, create-org |
| APIキーのセキュリティ | ✅ | 設定欄に環境変数例あり |
| サンプリング対応(評価では重要度低) | ⛔ | ドキュメント記載なし |
上記内容より、このMCPサーバーはInfluxDB統合の主要機能について十分なドキュメントが用意されています。リソースやツールの公開、プロンプトテンプレート、セットアップガイドも明確です。ただし、rootsやsamplingなど高度なMCP機能の記載はなく、一部ワークフローでの拡張性に制限があります。
InfluxDBの時系列データや自動化タスクに対して非常に実用的かつ堅牢なMCPサーバーです。開発者向けの実用性は高評価ですが、MCPの上級機能に関する説明は不足しています。
| LICENSE取得済み | ✅(MIT) |
|---|---|
| ツールが1つ以上ある | ✅ |
| フォーク数 | 6 |
| スター数 | 13 |
FlowHunt(または他のAIアシスタント)とInfluxDBデータベースをつなぎ、標準化されたMCPインターフェースを通じて時系列データのクエリ・書き込み・管理が可能になります。これにより分析・自動化・ワークフローの強化が実現します。
組織、バケット、バケット内の計測値などを公開し、Fluxクエリも直接サポート。データ書き込み(ラインプロトコル)、データクエリ、バケットや組織の作成が可能です。
「write-data」ツールを使えばラインプロトコルで自動取り込み、「query-data」ツールで高度なFluxクエリが実行できます——いずれもFlowHuntフロー内で利用可能です。
はい。APIトークンやシークレットは環境変数として保存し、設定ファイルに直書きしないことで安全性を確保できます。
AIによる時系列分析、自動IoTテレメトリーパイプライン、組織やバケットのデータベース管理、動的なデータ探索——すべてFlowHunt内で実現できます。
このサーバーではrootsやsamplingは現時点でドキュメント化されていませんが、InfluxDB統合の主要機能は十分にサポートされています。
MCPデータベースサーバーは、SQLite、SQL Server、PostgreSQL、MySQLなどの主要データベースへの安全でプログラム的なアクセスをAIアシスタントや自動化ツールに提供します。ブリッジとして機能し、コンテキスト認識ワークフローやAI搭載アプリケーションが効率的に構造化データを照会・管理・操作できる...
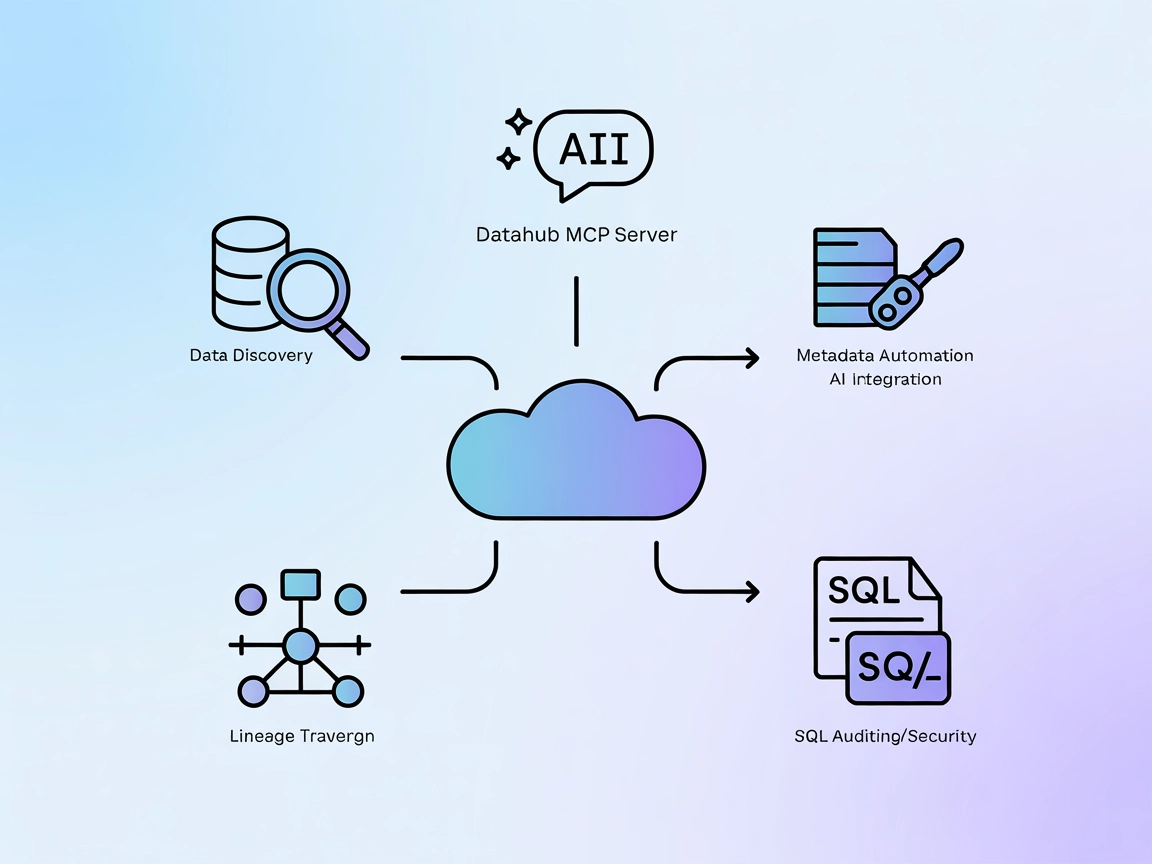
DataHub MCPサーバーは、FlowHuntのAIエージェントとDataHubメタデータプラットフォームを橋渡しし、高度なデータ探索、リネージ分析、自動メタデータ取得、AI駆動ワークフローとのシームレスな統合を実現します。...

Snowflake MCPサーバーは、Model Context Protocol(MCP)を介して高度なツールとリソースを公開し、SnowflakeデータベースとのシームレスなAI駆動のインタラクションを可能にします。SQLクエリの実行、スキーマ管理、インサイトの自動化、データワークフローの効率化を、標準化されたMC...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.