Flows
Flows zijn het brein achter alles in FlowHunt. Leer hoe je ze bouwt met een no-code visuele builder: van het plaatsen van het eerste component tot website-integ...
2 min lezen
AI
No-Code
+4

De nieuwe open-source CLI toolkit van FlowHunt maakt uitgebreide flow-evaluatie mogelijk met LLM als Rechter, en biedt gedetailleerde rapportages en geautomatiseerde kwaliteitsbeoordeling voor AI-workflows.
We zijn verheugd om de release aan te kondigen van de FlowHunt CLI Toolkit – onze nieuwe open-source command-line tool die is ontworpen om de manier waarop ontwikkelaars AI-flows evalueren en testen te vernieuwen. Deze krachtige toolkit brengt enterprise-grade flow evaluatie naar de open-source community, compleet met geavanceerde rapportages en onze innovatieve “LLM als Rechter” implementatie.
De FlowHunt CLI Toolkit betekent een grote stap vooruit in het testen en evalueren van AI-workflows. Nu beschikbaar op GitHub , biedt deze open-source toolkit ontwikkelaars uitgebreide tools voor:
De toolkit onderstreept onze toewijding aan transparantie en community-gedreven ontwikkeling, zodat geavanceerde AI-evaluatietechnieken toegankelijk zijn voor ontwikkelaars wereldwijd.
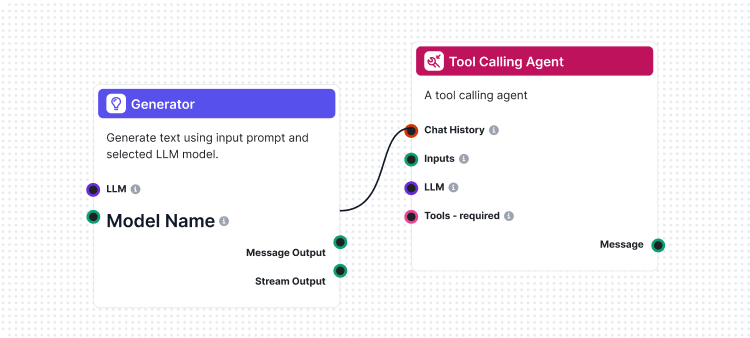
Een van de meest innovatieve functies van onze CLI toolkit is de implementatie van “LLM als Rechter”. Deze aanpak gebruikt kunstmatige intelligentie om de kwaliteit en juistheid van AI-gegenereerde antwoorden te beoordelen – feitelijk AI die AI-prestaties beoordeelt met geavanceerde redeneercapaciteiten.
Wat onze implementatie uniek maakt, is dat we FlowHunt zelf gebruikten om de evaluatie-flow te creëren. Deze meta-aanpak toont de kracht en flexibiliteit van ons platform, terwijl het een robuust evaluatiesysteem biedt. De LLM als Rechter-flow bestaat uit verschillende onderling verbonden componenten:
1. Prompt-template: Stelt de evaluatieprompt samen met specifieke criteria
2. Gestructureerde Output Generator: Verwerkt de evaluatie via een LLM
3. Data Parser: Formatteert de gestructureerde output voor rapportage
4. Chat Output: Presenteert de uiteindelijke evaluatieresultaten
Centraal in ons LLM als Rechter-systeem staat een zorgvuldig opgestelde prompt die zorgt voor consistente en betrouwbare evaluaties. Hier is de kernprompt die we gebruiken:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Deze prompt zorgt ervoor dat onze LLM-rechter het volgende levert:
Start vandaag uw gratis proefperiode en zie binnen enkele dagen resultaten.
Onze LLM als Rechter-flow toont geavanceerde AI-workflowontwerp met behulp van FlowHunt’s visuele flowbuilder. Zo werken de onderdelen samen:
De flow start met een Chat Input component die het evaluatieverzoek ontvangt met zowel het werkelijke antwoord als het referentieantwoord.
De Prompt-template component bouwt dynamisch de evaluatieprompt door:
{target_response} placeholder te plaatsen{actual_response} placeholder te plaatsenDe Gestructureerde Output Generator verwerkt de prompt met een geselecteerde LLM en genereert gestructureerde output die bevat:
total_rating: Numerieke score van 1-4correctness: Binaire correct/onjuist classificatiereasoning: Gedetailleerde uitleg van de evaluatieDe Parse Data component formatteert de gestructureerde output naar een leesbaar formaat, en de Chat Output component presenteert de uiteindelijke evaluatieresultaten.
Het LLM als Rechter-systeem biedt diverse geavanceerde mogelijkheden die het bijzonder effectief maken voor AI flow evaluatie:
In tegenstelling tot eenvoudige stringvergelijking begrijpt onze LLM-rechter:
De 4-puntsschaal biedt een verfijnde evaluatie:
Elke evaluatie bevat een gedetailleerde redenatie, waardoor je:
Ontvang gratis de nieuwste tips, trends en aanbiedingen.
De CLI toolkit genereert gedetailleerde rapportages die bruikbare inzichten bieden in de flow-prestaties:
Klaar om je AI-flows te evalueren met professionele tools? Zo ga je van start:
One-Line installatie (Aanbevolen) voor macOS en Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Dit zal automatisch:
flowhunt commando aan je PATH toevoegenHandmatige installatie:
# Clone de repository
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Installeer met pip
pip install -e .
Installatie verifiëren:
flowhunt --help
flowhunt --version
1. Authenticatie
Authenticeer eerst met je FlowHunt API:
flowhunt auth
2. Lijst je flows op
flowhunt flows list
3. Evalueer een flow Maak een CSV-bestand aan met je testdata:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Voer evaluatie uit met LLM als Rechter:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Batch-uitvoering van flows
flowhunt batch-run your-flow-id input.csv --output-dir results/
Het evaluatiesysteem biedt uitgebreide analyse:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Functies zijn onder andere:
De CLI toolkit integreert naadloos met het FlowHunt-platform, zodat je:
De uitgave van onze CLI toolkit is meer dan alleen een nieuw hulpmiddel – het is een visie voor de toekomst van AI-ontwikkeling, waarin:
Kwaliteit Meetbaar Is: Geavanceerde evaluatietechnieken maken AI-prestaties kwantificeerbaar en vergelijkbaar.
Testen Geautomatiseerd Is: Uitgebreide testframeworks verminderen handmatig werk en vergroten betrouwbaarheid.
Transparantie de Standaard Is: Gedetailleerde redenaties en rapportages maken AI-gedrag begrijpelijk en debugbaar.
De Community Innovatie Aanstuurt: Open-source tools maken gezamenlijke verbetering en kennisdeling mogelijk.
Door de FlowHunt CLI Toolkit open source te maken, tonen we onze toewijding aan:
De FlowHunt CLI Toolkit met LLM als Rechter betekent een grote stap vooruit in AI flow evaluatie. Door geavanceerde evaluatielogica te combineren met uitgebreide rapportages en open-source toegankelijkheid, stellen we ontwikkelaars in staat om betere, betrouwbaardere AI-systemen te bouwen.
De meta-aanpak om FlowHunt te gebruiken om FlowHunt-flows te evalueren, toont de volwassenheid en flexibiliteit van ons platform, terwijl het een krachtig hulpmiddel biedt voor de bredere AI-ontwikkelgemeenschap.
Of je nu eenvoudige chatbots bouwt of complexe multi-agent systemen, de FlowHunt CLI Toolkit biedt de evaluatie-infrastructuur die je nodig hebt voor kwaliteit, betrouwbaarheid en voortdurende verbetering.
Klaar om je AI flow evaluatie naar een hoger niveau te tillen? Bezoek onze GitHub repository om vandaag nog aan de slag te gaan met de FlowHunt CLI Toolkit en ervaar zelf de kracht van LLM als Rechter.
De toekomst van AI-ontwikkeling is hier – en het is open source.
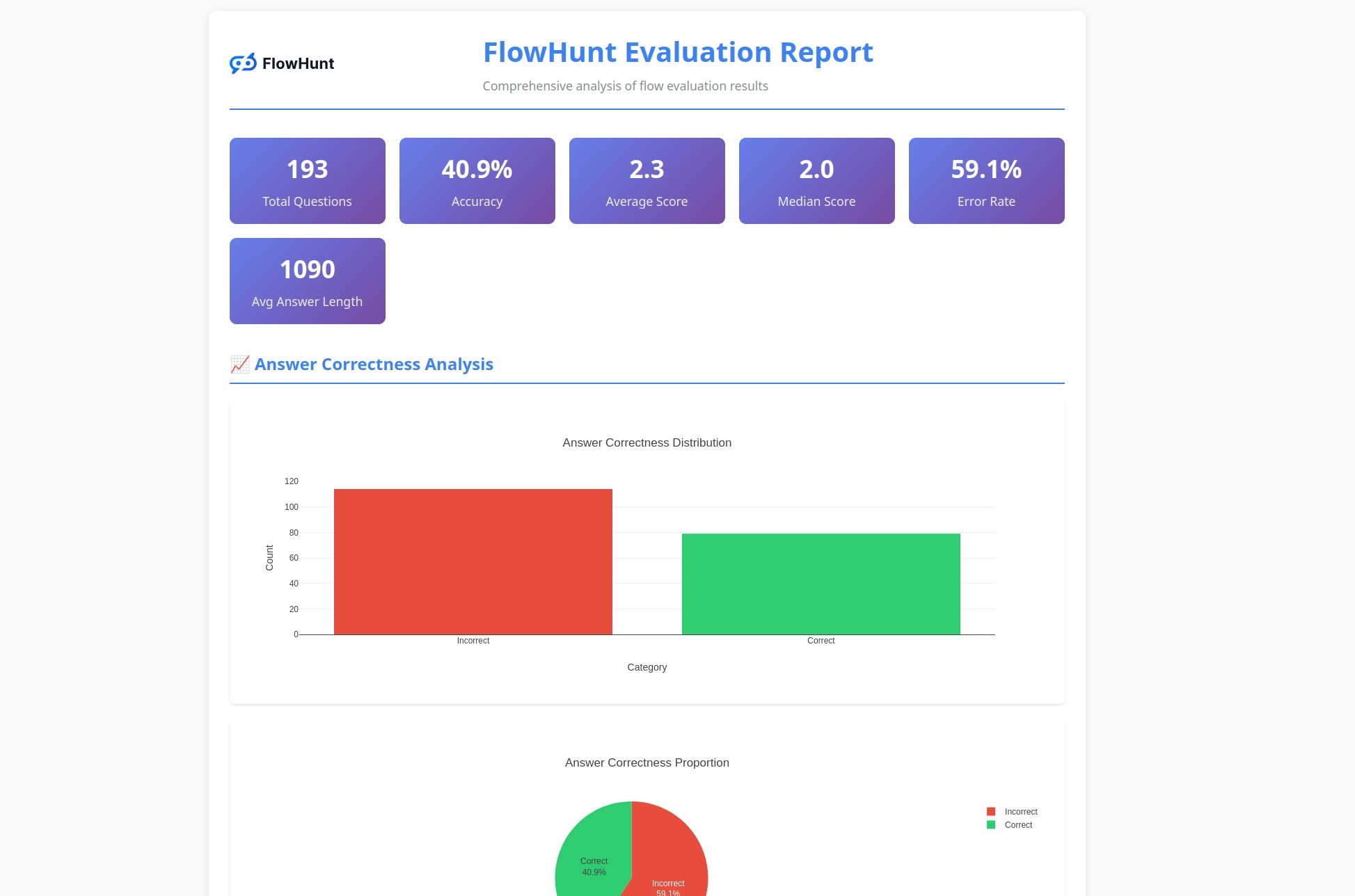
De FlowHunt CLI Toolkit is een open-source command-line tool voor het evalueren van AI-flows met uitgebreide rapportagemogelijkheden. Het bevat functies zoals LLM als Rechter evaluatie, analyse van correcte/onjuiste resultaten en gedetailleerde prestatiestatistieken.
LLM als Rechter gebruikt een geavanceerde AI-flow, gebouwd binnen FlowHunt, om andere flows te evalueren. Het vergelijkt werkelijke antwoorden met referentie-antwoorden en geeft beoordelingen, correctheidsbeoordelingen en gedetailleerde onderbouwingen bij elke evaluatie.
De FlowHunt CLI Toolkit is open-source en beschikbaar op GitHub via https://github.com/yasha-dev1/flowhunt-toolkit. Je kunt deze vrijelijk clonen, eraan bijdragen en gebruiken voor jouw AI flow evaluatiebehoeften.
De toolkit genereert uitgebreide rapportages, waaronder een overzicht van juiste/onjuiste resultaten, LLM als Rechter beoordelingen met scores en onderbouwingen, prestatiestatistieken en een gedetailleerde analyse van flow-gedrag over verschillende testcases.
Ja! De LLM als Rechter-flow is gebouwd met het FlowHunt-platform en kan worden aangepast voor verschillende evaluatiescenario's. Je kunt de prompt-template en evaluatiecriteria aanpassen aan jouw specifieke use-cases.
Yasha is een getalenteerde softwareontwikkelaar die gespecialiseerd is in Python, Java en machine learning. Yasha schrijft technische artikelen over AI, prompt engineering en chatbotontwikkeling.

Bouw en evalueer geavanceerde AI-workflows met het platform van FlowHunt. Begin vandaag nog met het creëren van flows die andere flows kunnen beoordelen.
Flows zijn het brein achter alles in FlowHunt. Leer hoe je ze bouwt met een no-code visuele builder: van het plaatsen van het eerste component tot website-integ...

Dit artikel legt uit hoe je FlowHunt met Langfuse verbindt voor uitgebreide observatie, AI-workflowprestaties traceert en Langfuse-dashboards gebruikt om je Flo...
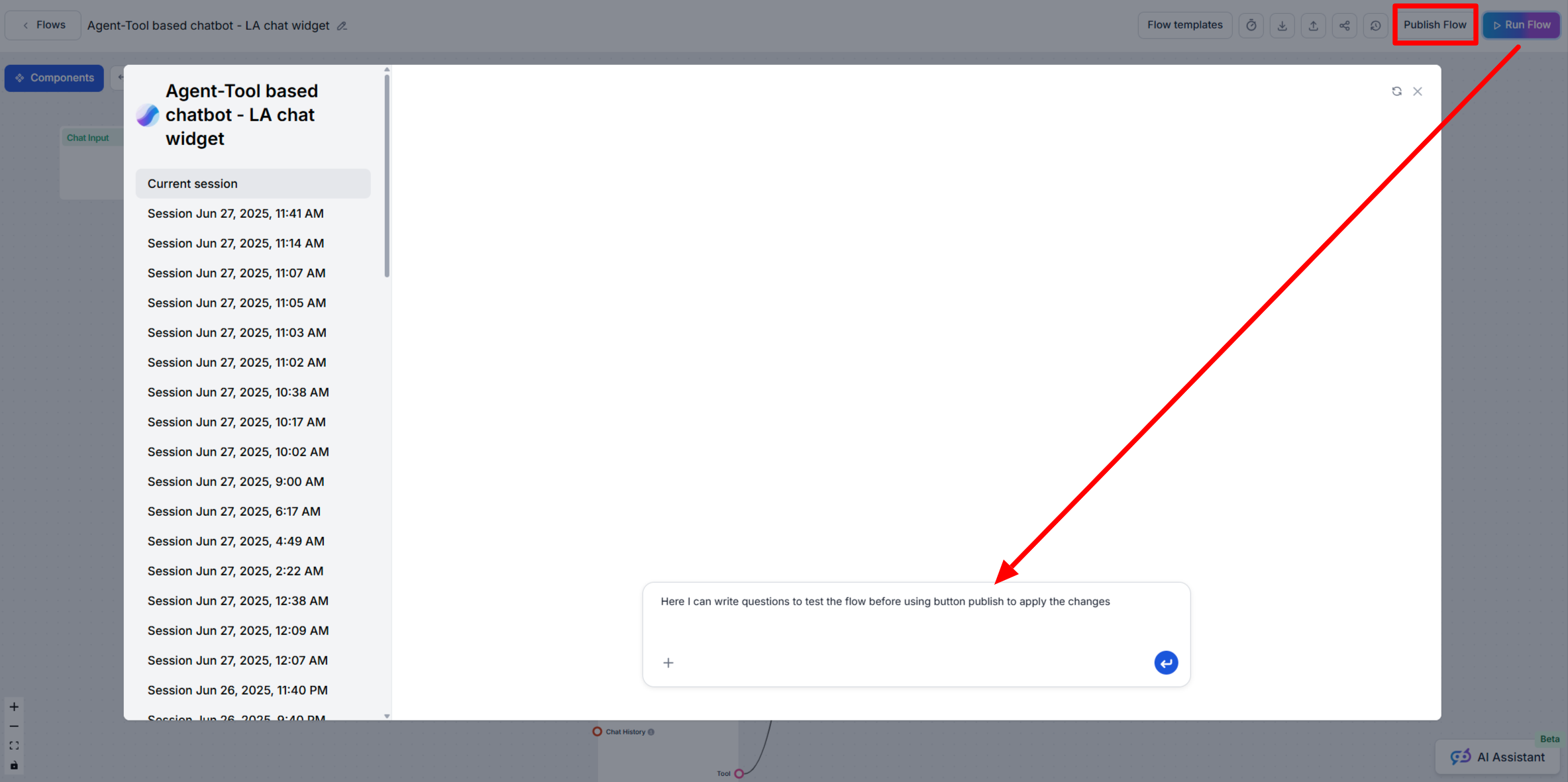
Leer wanneer je de functies Run Flow en Publish Flow in FlowHunt AIStudio gebruikt om je AI-workflows veilig te testen en uit te rollen.
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.