Leer hoe je automatische schema’s instelt voor het crawlen van websites, sitemaps, domeinen en YouTube-kanalen om je AI Agent kennisbank up-to-date te houden.
Schedules
Crawling
AI Agent
Knowledge Base
Automation
Geautomatiseerde Website Crawls Inplannen:
Select section...
Hoe werkt het inplannen?
Schema Configuratie-opties
Basisinstellingen
Geavanceerde Crawlopties
URL-filtering
Voorbeeld: flowhunt.io crawlen met /blog overgeslagen
Voorbeeld van opnemen van overeenkomende URL’s
Hoe maak je een schema aan?
Best Practices
Creditgebruik
Problemen oplossen
Met de Schema-functie van FlowHunt kun je het crawlen en indexeren van websites, sitemaps, domeinen en YouTube-kanalen automatiseren. Zo blijft de kennisbank van je AI Agent altijd actueel met verse content, zonder handmatige tussenkomst.
Hoe werkt het inplannen?
Automatisch crawlen: Stel terugkerende crawls in die dagelijks, wekelijks, maandelijks of jaarlijks worden uitgevoerd om je kennisbank up-to-date te houden.
Meerdere crawltypen: Kies uit Domein crawl, Sitemap crawl, URL crawl of YouTube-kanaal crawl, afhankelijk van je contentbron.
Geavanceerde opties: Stel browser rendering, linkvolgen, screenshots, proxy-rotatie en URL-filtering in voor optimale resultaten.
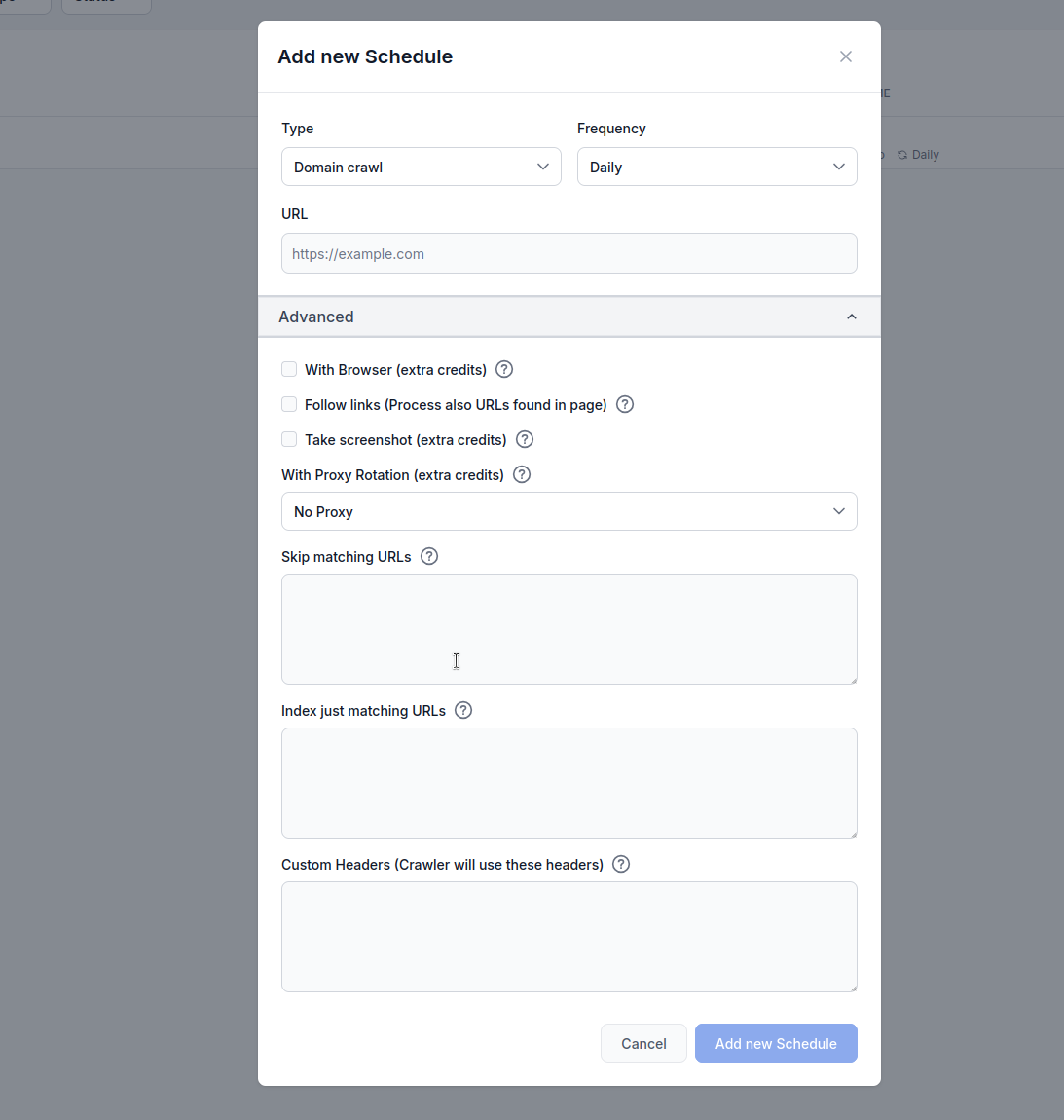
Schema Configuratie-opties
Basisinstellingen
Type: Kies je crawl-methode:
Domein crawl: Crawl een heel domein systematisch
Sitemap crawl: Gebruik de sitemap.xml van de website voor efficiënt crawlen
URL crawl: Richt je op specifieke URL’s of pagina’s
YouTube-kanaal crawl: Indexeer videocontent van YouTube-kanalen
Frequentie: Stel in hoe vaak de crawl moet lopen:
Dagelijks, Wekelijks, Maandelijks of Jaarlijks
URL: Voer de doel-URL, het domein of YouTube-kanaal in om te crawlen
Geavanceerde Crawlopties
Met Browser (extra credits):
Inschakelen bij het crawlen van JavaScript-intensieve websites die volledige browser rendering vereisen. Deze optie is langzamer en duurder, maar noodzakelijk voor sites die content dynamisch laden.
Links volgen (extra credits):
Verwerk extra URL’s gevonden binnen pagina’s. Handig als sitemaps niet alle URL’s bevatten, maar kan veel credits kosten omdat het ontdekte links crawlt.
Screenshot maken (extra credits):
Maak tijdens het crawlen visuele screenshots. Nuttig voor websites zonder og:images of als visuele context nodig is voor AI-verwerking.
Met Proxy-rotatie (extra credits):
Wissel IP-adressen per verzoek om detectie door Web Application Firewalls (WAF) of anti-botsystemen te voorkomen.
URL-filtering
Sla overeenkomende URL’s over:
Voer strings in (één per regel) om URL’s uit te sluiten die deze patronen bevatten. Voorbeeld:
/admin/
/login
.pdf
Voorbeeld: flowhunt.io crawlen met /blog overgeslagen
Dit voorbeeld legt uit wat er gebeurt wanneer je de Schema-functie van FlowHunt gebruikt om het domein flowhunt.io te crawlen terwijl je /blog als overeenkomend URL-patroon instelt om te overslaan in de URL-filterinstellingen.
Overige instellingen: Standaard (geen browser rendering, geen link volgen, geen screenshots, geen proxy-rotatie)
Wat gebeurt er
Crawl Start:
FlowHunt start een domein crawl van flowhunt.io en richt zich op alle toegankelijke pagina’s van het domein (zoals flowhunt.io, flowhunt.io/features, flowhunt.io/pricing, etc.).
URL-filtering toegepast:
De crawler vergelijkt elke gevonden URL met het oversla-patroon /blog.
Elke URL die /blog bevat (zoals flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/category) wordt uitgesloten van de crawl.
Andere URL’s zoals flowhunt.io/about, flowhunt.io/contact of flowhunt.io/docs worden wel gecrawld omdat ze niet aan het /blog-patroon voldoen.
Crawl Uitvoering:
De crawler verwerkt systematisch de resterende URL’s op flowhunt.io en indexeert hun inhoud voor de kennisbank van je AI Agent.
Omdat browser rendering, link volgen, screenshots en proxy-rotatie uitgeschakeld zijn, is de crawl lichtgewicht en gericht op alleen statische content van niet-uitgesloten URL’s.
Resultaat:
De kennisbank van je AI Agent wordt bijgewerkt met verse content van flowhunt.io, met uitzondering van alles onder het /blog-pad.
De crawl draait wekelijks, zodat de kennisbank actueel blijft met nieuwe of bijgewerkte pagina’s (buiten /blog), zonder handmatig werk.
Indexeer alleen overeenkomende URL’s:
Voer strings in (één per regel) om alleen URL’s te crawlen die deze patronen bevatten. Voorbeeld:
/blog/
/articles/
/knowledge/
Voorbeeld van opnemen van overeenkomende URL’s
Configuratie-instellingen
Type: Domein crawl
URL:flowhunt.io
Frequentie: Wekelijks
URL-filtering (Indexeer alleen overeenkomende URL’s):
/blog/
/articles/
/knowledge/
Overige instellingen: Standaard (geen browser rendering, geen link volgen, geen screenshots, geen proxy-rotatie)
Crawl Start:
FlowHunt start een domein crawl van flowhunt.io en richt zich op alle toegankelijke pagina’s op het domein (zoals flowhunt.io, flowhunt.io/blog, flowhunt.io/articles, etc.).
URL-filtering toegepast:
De crawler vergelijkt elke gevonden URL met de indexeer-patronen /blog/, /articles/ en /knowledge/.
Alleen URL’s die deze patronen bevatten (zoals flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guide) worden opgenomen in de crawl.
Andere URL’s, zoals flowhunt.io/about, flowhunt.io/pricing of flowhunt.io/contact, worden uitgesloten omdat ze niet aan de opgegeven patronen voldoen.
Crawl Uitvoering:
De crawler verwerkt alleen de URL’s die overeenkomen met /blog/, /articles/ of /knowledge/ en indexeert hun inhoud voor de kennisbank van je AI Agent.
Omdat browser rendering, link volgen, screenshots en proxy-rotatie uitgeschakeld zijn, is de crawl lichtgewicht en gericht op alleen statische content van de opgenomen URL’s.
Resultaat:
De kennisbank van je AI Agent wordt bijgewerkt met verse content van flowhunt.io-pagina’s onder de paden /blog/, /articles/ en /knowledge/.
De crawl draait wekelijks, zodat de kennisbank actueel blijft met nieuwe of bijgewerkte pagina’s binnen deze secties, zonder handmatige tussenkomst.
Aangepaste Headers:
Voeg aangepaste HTTP-headers toe voor crawlverzoeken. Formatteer als HEADER=Value (één per regel):
Deze functie is erg handig om crawls af te stemmen op specifieke websitebehoeften. Door aangepaste headers in te schakelen, kunnen gebruikers verzoeken authentiseren om toegang te krijgen tot afgeschermde content, specifiek browsergedrag nabootsen of voldoen aan het API- of toegangsbeleid van een website. Door bijvoorbeeld een Authorization-header in te stellen, kan toegang worden verkregen tot beschermde pagina’s, terwijl een aangepaste User-Agent kan helpen om botdetectie te voorkomen of compatibiliteit te waarborgen bij sites die bepaalde crawlers weren. Deze flexibiliteit zorgt voor een nauwkeurigere en uitgebreidere dataverzameling, waardoor het eenvoudiger wordt om relevante content te indexeren voor de kennisbank van een AI Agent en tegelijkertijd te voldoen aan de beveiligings- of toegangsprotocollen van een website.
MYHEADER=Any value
Authorization=Bearer token123
User-Agent=Custom crawler
Klaar om uw bedrijf te laten groeien?
Start vandaag uw gratis proefperiode en zie binnen enkele dagen resultaten.
Hoe genereer je SEO-geoptimaliseerde verklarende woordenlijstpagina's met AI in FlowHunt
Ontdek hoe je automatisch uitgebreide, SEO-geoptimaliseerde verklarende woordenlijstpagina's genereert met AI-agents en workflowautomatisering in FlowHunt. Leer...
Zet YouTube-video's om in blogs met AI-automatisering
Leer hoe je automatisch YouTube-video's omzet in SEO-geoptimaliseerde blogposts met behulp van AI-agents, FlowHunt en intelligente workflow-automatisering. Ontd...
De Planningen-functie in FlowHunt stelt je in staat om periodiek domeinen en YouTube-kanalen te crawlen, zodat je chatbots en flows altijd up-to-date blijven me...
3 min lezen
AI
Schedules
+4
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.