Hvordan verifisere AI-chatboters ekthet
Lær pålitelige metoder for å verifisere AI-chatboters ekthet i 2025. Oppdag tekniske verifiseringsteknikker, sikkerhetssjekker og beste praksis for å identifise...
10 min lesing
Lær omfattende metoder for å måle nøyaktigheten til AI helpdesk chatboter i 2025. Oppdag presisjon, recall, F1-score, brukertilfredshetsmål og avanserte evalueringsteknikker med FlowHunt.
Mål nøyaktigheten til AI helpdesk chatbot ved å bruke flere metrikker, inkludert presisjon og recall-beregninger, forvirringsmatriser, brukertilfredshetsskårer, løsningsrate og avanserte LLM-baserte evalueringsmetoder. FlowHunt tilbyr omfattende verktøy for automatisert nøyaktighetsvurdering og ytelsesovervåking.
Å måle nøyaktigheten til en AI helpdesk chatbot er avgjørende for å sikre at den gir pålitelige, hjelpsomme svar på kundehenvendelser. I motsetning til enkle klassifiseringsoppgaver omfatter chatbot-nøyaktighet flere dimensjoner som må vurderes samlet for å gi et helhetlig bilde av ytelsen. Prosessen innebærer å analysere hvor godt chatboter forstår brukerens spørsmål, gir korrekt informasjon, løser problemer effektivt og opprettholder brukertilfredshet gjennom hele samtalen. En omfattende målestrategi for nøyaktighet kombinerer kvantitative metrikker med kvalitativ tilbakemelding for å identifisere styrker og områder som krever forbedring.
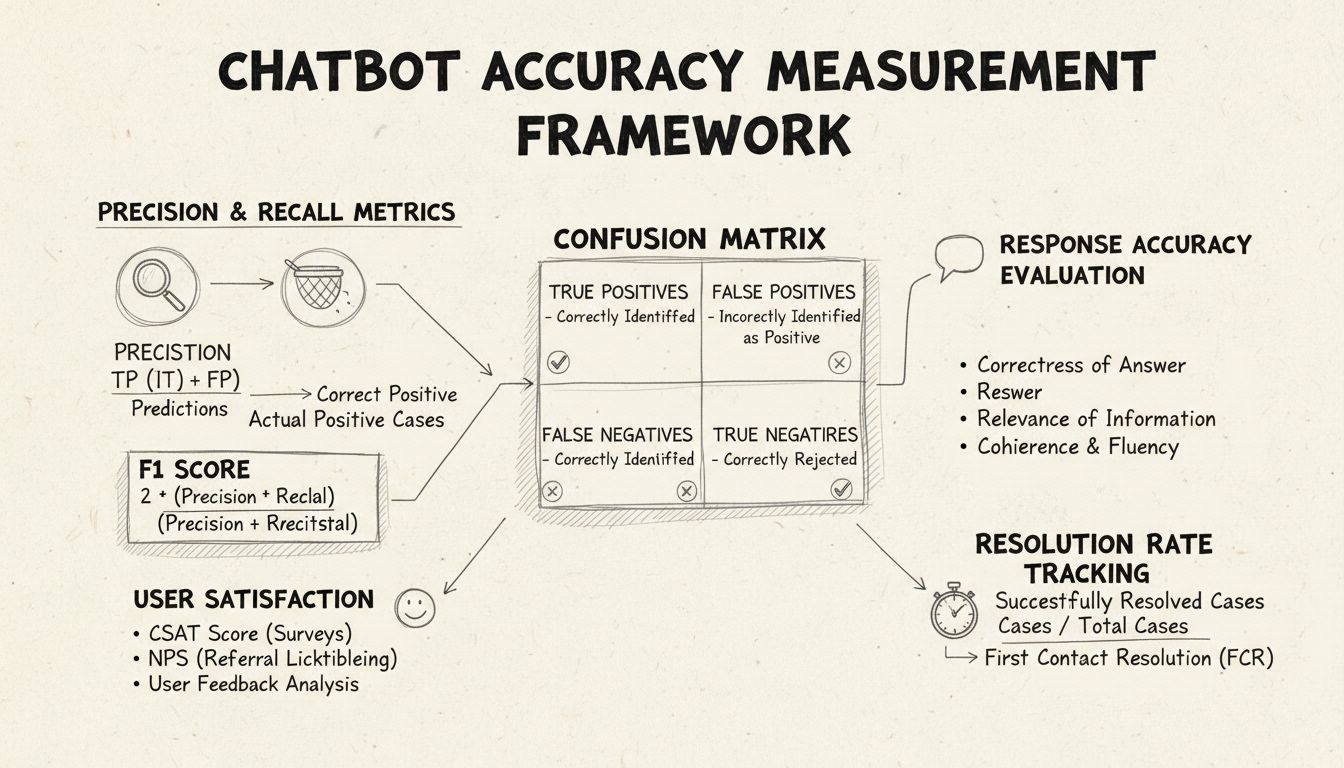
Presisjon og recall er grunnleggende metrikker hentet fra forvirringsmatrisen som måler ulike sider ved chatbotens ytelse. Presisjon viser andelen korrekte svar av alle svar chatboten har gitt, beregnet med formelen: Presisjon = Sanne Positiver / (Sanne Positiver + Falske Positiver). Denne metrikken svarer på spørsmålet: “Når chatboten gir et svar, hvor ofte er det riktig?” Høy presisjon betyr at chatboten sjelden gir feil informasjon, noe som er avgjørende for å opprettholde brukertillit i helpdesk-sammenheng.
Recall, også kjent som sensitivitet, måler andelen korrekte svar av alle de riktige svarene chatboten burde ha gitt, med formelen: Recall = Sanne Positiver / (Sanne Positiver + Falske Negativer). Denne metrikken handler om hvorvidt chatboten lykkes med å identifisere og svare på alle reelle kundehenvendelser. I helpdesk-kontekst sikrer høy recall at kunder får hjelp for sine problemer, i stedet for å bli avvist når chatboten faktisk kunne hjulpet. Forholdet mellom presisjon og recall danner en naturlig avveining: optimalisering for én reduserer ofte den andre, og krever derfor nøye balanse ut fra virksomhetens prioriteringer.
F1-score gir én samlet metrikk som balanserer både presisjon og recall, beregnet som det harmoniske gjennomsnittet: F1 = 2 × (Presisjon × Recall) / (Presisjon + Recall). Denne metrikken er spesielt nyttig når du trenger en samlet ytelsesindikator, eller når du har ubalanserte datasett der én klasse er langt større enn andre. For eksempel, hvis chatboten din håndterer 1 000 rutinehenvendelser, men bare 50 komplekse saker, hindrer F1-score at metrikken blir skjevfordelt av majoritetsklassen. F1-score varierer fra 0 til 1, der 1 representerer perfekt presisjon og recall, noe som gjør det intuitivt for interessenter å forstå den samlede ytelsen med et blikk.
Forvirringsmatrisen er et grunnleggende verktøy som bryter ned chatbotens ytelse i fire kategorier: Sanne Positiver (korrekte svar på gyldige spørsmål), Sanne Negativer (riktig avvist spørsmål utenfor chatbotens område), Falske Positiver (feilaktige svar) og Falske Negativer (tapte muligheter til å hjelpe). Denne matrisen avdekker spesifikke mønstre i chatbotens feil og muliggjør målrettede forbedringer. For eksempel, hvis matrisen viser mange falske negativer på faktureringshenvendelser, kan det tyde på at chatbotens treningsdata mangler tilstrekkelige eksempler på fakturering og må forbedres på det området.
| Metrikk | Definisjon | Beregning | Forretningspåvirkning |
|---|---|---|---|
| Sanne Positiver (TP) | Korrekte svar på gyldige spørsmål | Telles direkte | Bygger kundetillit |
| Sanne Negativer (TN) | Riktig avvist spørsmål utenfor område | Telles direkte | Forhindrer feilinformasjon |
| Falske Positiver (FP) | Feilaktige svar gitt | Telles direkte | Skader troverdighet |
| Falske Negativer (FN) | Tapte muligheter til å hjelpe | Telles direkte | Reduserer tilfredshet |
| Presisjon | Kvalitet på positive prediksjoner | TP / (TP + FP) | Pålitelighetsmetrikk |
| Recall | Dekning av faktiske positive | TP / (TP + FN) | Fullstendighetsmetrikk |
| Nøyaktighet | Overordnet korrekthet | (TP + TN) / Totalt | Generell ytelse |
Svarnøyaktighet måler hvor ofte chatboten gir faktuelt korrekte svar som direkte adresserer brukerens spørsmål. Dette går utover enkel mønstergjenkjenning for å vurdere om innholdet er korrekt, oppdatert og passende for konteksten. Manuelle gjennomganger innebærer at menneskelige vurderere evaluerer et tilfeldig utvalg samtaler, der chatbotens svar sammenlignes med en forhåndsdefinert kunnskapsbase av riktige svar. Automatiserte sammenligningsmetoder kan implementeres ved hjelp av naturlig språkprosessering for å matche svar mot forventede svar lagret i systemet, men disse må finjusteres for å unngå falske negativer når chatboten gir riktige svar med andre ord enn referansesvaret.
Svarrelevans vurderer om chatbotens svar faktisk adresserer det brukeren spurte om, selv om svaret ikke er helt korrekt. Denne dimensjonen fanger opp situasjoner der chatboten gir hjelpsom informasjon som, selv om det ikke er det eksakte svaret, fører samtalen mot en løsning. NLP-baserte metoder som cosinus-likhet kan måle semantisk likhet mellom brukerens spørsmål og chatbotens svar, og gi en automatisert relevansskår. Brukertilbakemeldinger, som tommel opp/ned etter hver interaksjon, gir direkte vurdering av relevans fra de som betyr mest—kundene dine. Disse tilbakemeldingene bør kontinuerlig samles inn og analyseres for å identifisere mønstre i hvilke typer spørsmål chatboten håndterer godt versus dårlig.
Kundetilfredshetsskår (CSAT) måler brukertilfredshet med chatbot-interaksjoner gjennom direkte undersøkelser, vanligvis med en 1-5-skala eller enkle tilfredshetsvurderinger. Etter hver interaksjon bes brukerne om å vurdere sin tilfredshet, og gir umiddelbar tilbakemelding på om chatboten møtte deres behov. CSAT-skårer over 80 % indikerer generelt god ytelse, mens skårer under 60 % signaliserer betydelige problemer som krever undersøkelse. Fordelen med CSAT er dens enkelhet og direktehet—brukerne sier eksplisitt om de er fornøyde—men den kan påvirkes av faktorer utenfor chatbotens nøyaktighet, som sakens kompleksitet eller brukernes forventninger.
Net Promoter Score måler sannsynligheten for at brukere vil anbefale chatboten til andre, beregnet ved å spørre “Hvor sannsynlig er det at du vil anbefale denne chatboten til en kollega?” på en skala fra 0 til 10. Respondenter som gir 9-10 er promotører, 7-8 er passive og 0-6 er kritikere. NPS = (Promotører - Kritikere) / Totalt antall respondenter × 100. Denne metrikken korrelerer sterkt med langsiktig kundelojalitet og gir innsikt i om chatboten skaper positive opplevelser brukerne ønsker å dele. En NPS over 50 regnes som utmerket, mens negativ NPS indikerer alvorlige ytelsesproblemer.
Sentimentanalyse undersøker den emosjonelle tonen i brukermeldinger før og etter chatbot-interaksjoner for å vurdere tilfredshet. Avanserte NLP-teknikker klassifiserer meldinger som positive, nøytrale eller negative, og avdekker om brukerne blir mer fornøyde eller frustrerte gjennom samtalen. Et positivt sentimentskifte indikerer at chatboten løste bekymringer, mens negative skifter tyder på at chatboten kan ha frustrert brukerne eller ikke oppfylt deres behov. Denne metrikken fanger opp emosjonelle dimensjoner som tradisjonelle nøyaktighetsmetrikker ikke måler, og gir verdifull kontekst for brukeropplevelsens kvalitet.
Førstekontakt-løsningsgrad måler prosentandelen kundehenvendelser chatboten løser uten å eskalere til menneskelige agenter. Denne metrikken påvirker direkte operasjonell effektivitet og kundetilfredshet, da kunder foretrekker å få løst saken umiddelbart fremfor å bli overført. FCR over 70 % indikerer god chatbot-ytelse, mens rater under 50 % tyder på at chatboten mangler kunnskap eller kapasitet til å håndtere vanlige spørsmål. Å spore FCR per sakskategori viser hvilke problemer chatboten håndterer godt og hvilke som krever menneskelig inngripen, og gir retning for opplæring og forbedring av kunnskapsbasen.
Eskaleringsraten måler hvor ofte chatboten overfører samtaler til menneskelige agenter, mens fallback-frekvensen måler hvor ofte chatboten gir generiske svar som “Jeg forstår ikke” eller “Vennligst omformuler spørsmålet ditt.” Høy eskaleringsrate (over 30 %) indikerer at chatboten mangler kunnskap eller selvtillit i mange situasjoner, mens høy fallback-rate tyder på dårlig intensjonsgjenkjenning eller utilstrekkelige treningsdata. Disse metrikker identifiserer spesifikke hull i chatbotens evner som kan utbedres gjennom utvidelse av kunnskapsbasen, ny trening av modellen eller forbedret naturlig språkforståelse.
Svartid måler hvor raskt chatboten svarer på brukermeldinger, vanligvis målt i millisekunder til sekunder. Brukere forventer nærmest umiddelbare svar; forsinkelser over 3-5 sekunder påvirker tilfredsheten betydelig. Håndteringstid måler total tid fra brukeren tar kontakt til saken er løst eller eskalert, og gir innsikt i chatbotens effektivitet. Kortere håndteringstid indikerer at chatboten raskt forstår og løser problemer, mens lengre tider tyder på at chatboten trenger flere avklaringsrunder eller sliter med komplekse spørsmål. Disse metrikker bør spores separat for ulike sakskategorier, da komplekse tekniske problemer naturlig krever lengre håndteringstid enn enkle FAQ-spørsmål.
LLM som dommer er en avansert evalueringsmetode der én stor språkmodell vurderer kvaliteten på en annen AI-system sitt output. Denne metodikken er spesielt effektiv for å evaluere chatbot-svar på tvers av flere kvalitetsdimensjoner samtidig, som nøyaktighet, relevans, sammenheng, flyt, sikkerhet, fullstendighet og tone. Forskning viser at LLM-dommere kan oppnå opptil 85 % samsvar med menneskelige vurderinger, noe som gjør dem til et skalerbart alternativ til manuell gjennomgang. Tilnærmingen innebærer å definere spesifikke evalueringskriterier, utarbeide detaljerte dommerprompter med eksempler, gi dommeren både brukerens opprinnelige spørsmål og chatbotens svar, og motta strukturerte skårer eller detaljert tilbakemelding.
LLM som dommer-prosessen bruker vanligvis to evalueringsmetoder: enkeltsvar-evaluering, der dommeren vurderer et individuelt svar med enten referansefri evaluering (uten fasit) eller referansebasert sammenligning (mot forventet svar), og parvis sammenligning, der dommeren sammenligner to svar for å finne det beste. Denne fleksibiliteten gjør det mulig å evaluere både absolutt ytelse og relative forbedringer når man tester ulike chatbot-versjoner eller konfigurasjoner. FlowHunt-plattformen støtter LLM som dommer-metodikk gjennom sitt dra-og-slipp-grensesnitt, integrasjon med ledende LLM-er som ChatGPT og Claude, og CLI-verktøysett for avansert rapportering og automatiserte evalueringer.
Utover grunnleggende nøyaktighetsberegninger avslører detaljert forvirringsmatriseanalyse spesifikke feilmønstre hos chatboten. Ved å undersøke hvilke typer forespørsler som gir falske positiver versus falske negativer kan du identifisere systematiske svakheter. For eksempel, hvis matrisen viser at chatboten ofte feilklassifiserer faktureringsspørsmål som teknisk støtte, avdekker dette en skjevhet i treningsdataene eller et intensjonsgjenkjenningsproblem innen fakturering. Å lage egne forvirringsmatriser for ulike sakskategorier muliggjør målrettede forbedringer fremfor generell retrening av modellen.
A/B-testing sammenligner ulike versjoner av chatboten for å avgjøre hvilken som yter best på nøkkelmetrikker. Dette kan innebære å teste ulike svartemplater, kunnskapsbaseoppsett eller underliggende språkmodeller. Ved å rute en del av trafikken til hver versjon og sammenligne metrikker som FCR, CSAT-skår og svarnøyaktighet, kan du ta datadrevne beslutninger om hvilke forbedringer som skal implementeres. A/B-testing bør vare lenge nok til å fange naturlig variasjon i brukerspørsmål og sikre statistisk signifikans i resultatene.
FlowHunt tilbyr en integrert plattform for å bygge, distribuere og evaluere AI helpdesk chatboter med avanserte målefunksjoner for nøyaktighet. Plattformens visuelle builder gjør det mulig for ikke-tekniske brukere å lage avanserte chatbot-løp, mens AI-komponentene integreres med ledende språkmodeller som ChatGPT og Claude. FlowHunt sitt evalueringsverktøy støtter implementering av LLM som dommer-metodikk, slik at du kan definere egne evalueringskriterier og automatisk vurdere chatbot-ytelse på hele konversasjonsdatasettet ditt.
For å implementere omfattende nøyaktighetsmåling med FlowHunt, start med å definere dine spesifikke evalueringskriterier i tråd med forretningsmål—enten du prioriterer nøyaktighet, hastighet, brukertilfredshet eller løsningsgrad. Konfigurer dommer-LLM-en med detaljerte prompter som beskriver hvordan svarene skal vurderes, inkludert konkrete eksempler på både gode og dårlige svar. Last opp datasettet ditt med samtaler eller koble til live-trafikk, og kjør evalueringer for å generere detaljerte rapporter som viser ytelse på alle metrikker. FlowHunt sitt dashbord gir sanntidsoversikt over chatbotens ytelse, og muliggjør rask identifisering av problemer og validering av forbedringer.
Etabler et grunnivå for måling før du implementerer forbedringer for å ha et referansepunkt for å vurdere effekten av endringer. Samle målinger kontinuerlig i stedet for periodisk, slik at du tidlig kan oppdage ytelsesforringelse på grunn av datadrift eller modellforringelse. Implementer tilbakemeldingssløyfer der brukervurderinger og korreksjoner automatisk mates tilbake til treningsprosessen for å kontinuerlig forbedre chatbotens nøyaktighet. Del metrikker opp etter sakskategori, brukertype og tidsperiode for å finne spesifikke områder som krever oppmerksomhet, i stedet for å bare stole på samlede statistikker.
Sørg for at evalueringsdatasettet ditt representerer reelle brukerspørsmål og forventede svar, og unngå kunstige testtilfeller som ikke gjenspeiler faktisk bruk. Valider jevnlig automatiserte metrikker mot menneskelig vurdering ved å la testere manuelt vurdere et utvalg samtaler, slik at målesystemet forblir kalibrert mot faktisk kvalitet. Dokumenter målemetodikken og definisjonene tydelig, slik at evalueringen blir konsistent over tid og resultatene lett kan kommuniseres til interessenter. Til slutt, sett ytelsesmål for hver metrikk i tråd med forretningsmål, og skap ansvarlighet for kontinuerlig forbedring og klare mål for optimaliseringsarbeidet.
FlowHunt sin avanserte AI-automatiseringsplattform hjelper deg å lage, distribuere og evaluere høytytende helpdesk chatboter med innebygde måleverktøy for nøyaktighet og LLM-basert evaluering.
Lær pålitelige metoder for å verifisere AI-chatboters ekthet i 2025. Oppdag tekniske verifiseringsteknikker, sikkerhetssjekker og beste praksis for å identifise...
Lær omfattende strategier for testing av AI-chatbot, inkludert funksjonell testing, ytelsestesting, sikkerhetstesting og brukervennlighetstesting. Oppdag beste ...
Lær de beste måtene å henvende seg til AI-chatbot-assistenter på i 2025. Oppdag formelle, uformelle og lekne kommunikasjonsstiler, navngivningskonvensjoner og h...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.